paper
1 Abstract
The article puts forward that UNet mainly has the following two defects:
① the optimal depth of the network is unknown, which requires a large number of experiments and integration of networks with different depths, resulting in low efficiency;
② skip connection introduces unnecessary restrictions, that is, it restricts feature fusion only at the same scale.
In this regard, UNet + + has made the following optimization:
① use the effective integration of unets with different depths (these unets share one encoder) to search the optimal depth through supervised learning;
② redesign the skip connection so that the sub network of the decoder can aggregate the characteristics of different scales and be more flexible;
③ use paper cutting technology to improve the reasoning speed of UNet + +.

2 Introduction
The traditional encoder decoder structure + skip connection structure can be well applied to the task of semantic segmentation. The reason is that it combines the shallow fine-grained information in the encoder subnet with the deep coarse-grained information in the decoder subnet.
Five contributions of the article:
① UNet + + is embedded with unets of different depths, so it is no longer a fixed depth structure;
② more flexible skip connection structure, which no longer only integrates the characteristics of the same scale;
③ a pruning operation is designed to speed up the reasoning speed;
④ at the same time, training unets embedded in different depths leads to collaborative training between unets, which brings better performance;
⑤ it shows scalability.
3 Backbone
3.1 Motivation
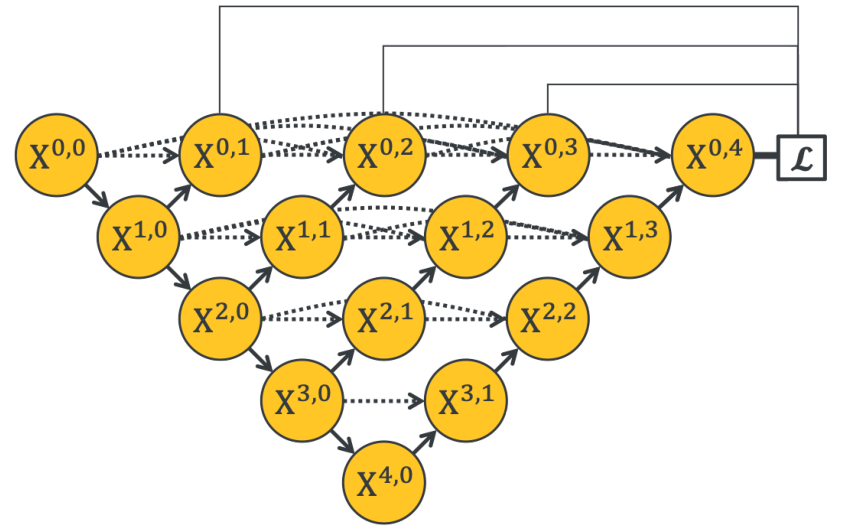
It was found that deeper UNet was not necessarily better, so multiple groups of ablation experiments were carried out.
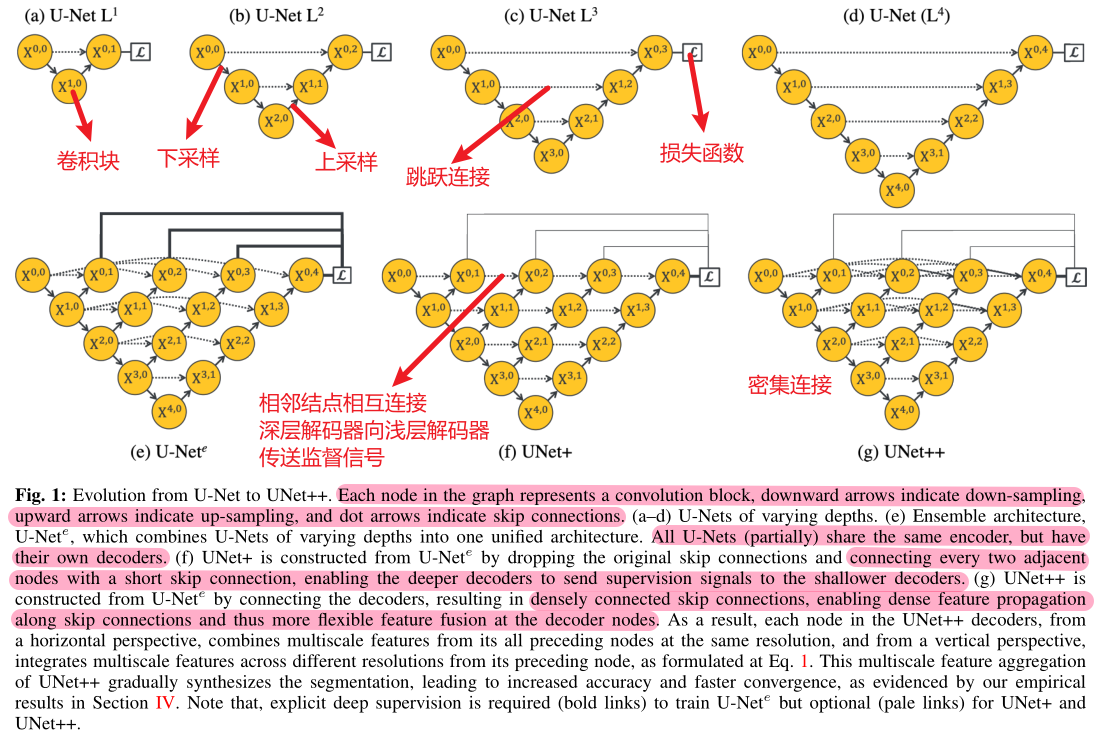
In UNete, it is necessary to assign loss functions to X01, X02, X03 and X04 at the same time, so that the embedded UNet can return the gradient. In the process from UNet + to UNet + +, from short connection to long connection, a variety of features are used more effectively.
3.2 Structure
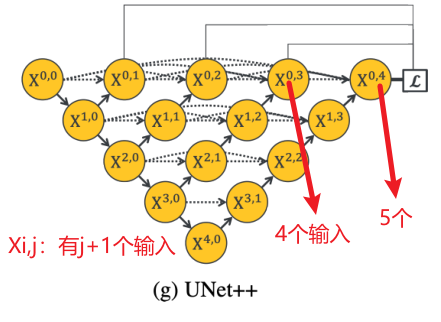
3.3 Deep supervision

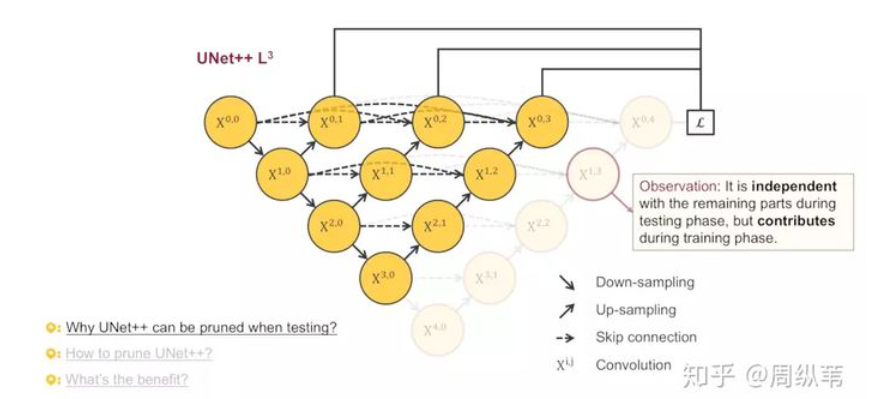
3.4 Model pruning
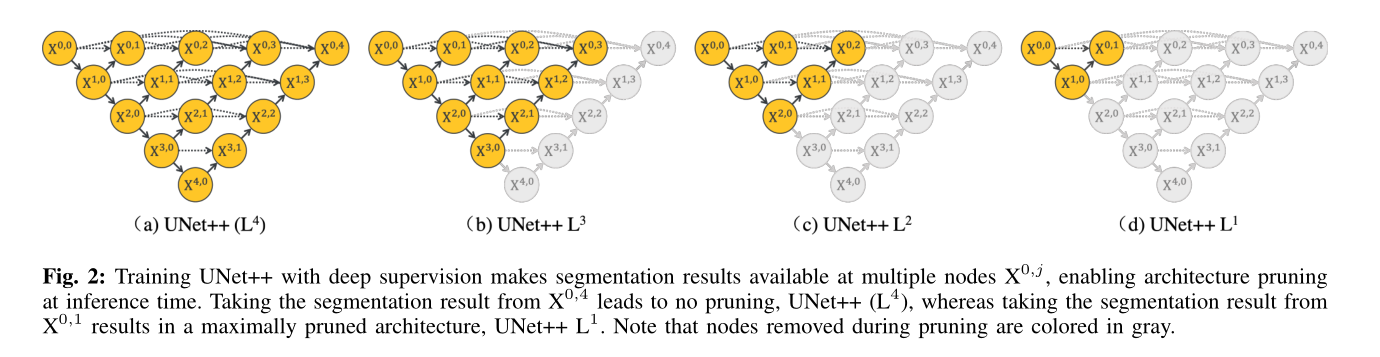
- Integration mode, in which the segmentation results of all segmented branches are collected and then averaged;
- Pruning mode, which divides branches, determines the degree and speed gain of model pruning, such as the above figure.
The following references: Study U-Net - Zhihu (zhihu.com)


code
# The basic block network is used to stack each convolution block
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
# UNet + + backbone network
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# First slash (top left to bottom right)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
# Second slash
self.conv0_1 = VGGBlock(nb_filter[0] * 1 + nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1] * 1 + nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2] * 1 + nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3] * 1 + nb_filter[4], nb_filter[3], nb_filter[3])
# Third slash
self.conv0_2 = VGGBlock(nb_filter[0] * 2 + nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1] * 2 + nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2] * 2 + nb_filter[3], nb_filter[2], nb_filter[2])
# Fourth slash
self.conv0_3 = VGGBlock(nb_filter[0] * 3 + nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1] * 3 + nb_filter[2], nb_filter[1], nb_filter[1])
# Fifth slash
self.conv0_4 = VGGBlock(nb_filter[0] * 4 + nb_filter[1], nb_filter[0], nb_filter[0])
# one × 1 convolution kernel
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, x):
x0_0 = self.conv0_0(x)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4] # Deep supervision, there are four loss functions trained together
else:
output = self.final(x0_4)
return output