1: Input plug-in (input)
Enter the official documentation of the plug-in: https://www.elastic.co/guide/en/logstash/current/input-plugins.html
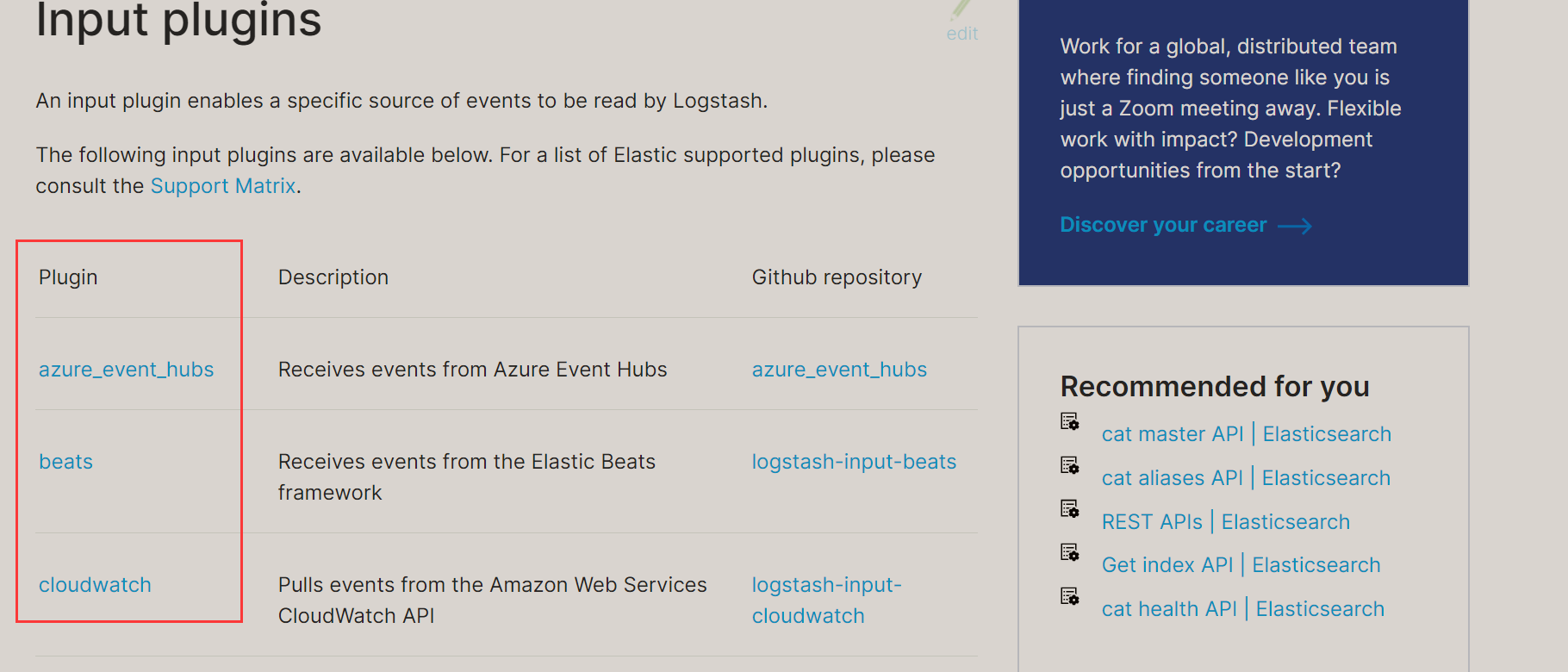
The following is an example:
- Standard input
- read file
- Read TCP network data
1 standard input (stdin)
Type Hello World (stdin {}) on the console, and press enter to output on the current console (codec = > Ruby debug)
input{
stdin{
}
}
output {
stdout{
codec=>rubydebug
}
}
Test:
[root@localhost config]# ls
java_pid12011.hprof jvm.options logstash-sample.conf my-app.conf startup.options
java_pid21521.hprof log4j2.properties logstash.yml pipelines.yml
[root@localhost config]# vim test1.conf
input{
stdin{
}
}
output {
stdout{
codec=>rubydebug
}
}
~
~
~
~
~
~
"test1.conf" [new] 17L, 167C Written
[root@localhost config]# ls
java_pid12011.hprof jvm.options logstash-sample.conf my-app.conf startup.options
java_pid21521.hprof log4j2.properties logstash.yml pipelines.yml test1.conf
[root@localhost config]#
[root@localhost config]# ../bin/logstash -f test1.conf
Using JAVA_HOME defined java: /opt/elasticsearch-7.6.1/jdk
WARNING: Using JAVA_HOME while Logstash distribution comes with a bundled JDK.
DEPRECATION: The use of JAVA_HOME is now deprecated and will be removed starting from 8.0. Please configure LS_JAVA_HOME instead.
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties
[2022-01-11T15:49:40,297][INFO ][logstash.runner ] Log4j configuration path used is: /usr/local/logstash/config/log4j2.properties
[2022-01-11T15:49:40,315][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 13.0.2+8 on 13.0.2+8 +indy +jit [linux-x86_64]"}
[2022-01-11T15:49:40,652][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2022-01-11T15:49:42,009][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[2022-01-11T15:49:42,568][INFO ][org.reflections.Reflections] Reflections took 84 ms to scan 1 urls, producing 119 keys and 417 values
[2022-01-11T15:49:43,491][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/usr/local/logstash/config/test1.conf"], :thread=>"#<Thread:0x772c1831 run>"}
[2022-01-11T15:49:44,165][INFO ][logstash.javapipeline ][main] Pipeline Java execution initialization time {"seconds"=>0.67}
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.jrubystdinchannel.StdinChannelLibrary$Reader (file:/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/jruby-stdin-channel-0.2.0-java/lib/jruby_stdin_channel/jruby_stdin_channel.jar) to field java.io.FilterInputStream.in
WARNING: Please consider reporting this to the maintainers of com.jrubystdinchannel.StdinChannelLibrary$Reader
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
[2022-01-11T15:49:44,268][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2022-01-11T15:49:44,327][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
sss
{
"message" => "sss",
"host" => "localhost.localdomain",
"@timestamp" => 2022-01-11T07:49:47.049Z,
"@version" => "1"
}
hello world
{
"message" => "hello world",
"host" => "localhost.localdomain",
"@timestamp" => 2022-01-11T07:49:57.473Z,
"@version" => "1"
}
2 read file
You can view the specific contents as follows:


logstash uses a ruby gem library called filewatch to listen for file changes and pass a call sincedb database file to record the reading progress (timestamp) of the monitored log file
- The default path of sincedb data file is < path Under data > / plugins / inputs / file, the file name is similar to sincedb_ one hundred and twenty-three thousand four hundred and fifty-six
- <path. Data > indicates the logstash plug-in storage directory. The default is LOGSTASH_HOME/data.
give an example:
- path: location of log; After starting the configuration file, logstash can read the contents of the log in the current location
- start_position: the starting position, which tells logstash where to start reading when reading files (in the configuration below, it starts reading from the beginning)
- It will be read with the data of each row
- It will always take screenshots if it is not turned off
input {
file {
path => ["/var/*/*"]
start_position => "beginning"
}
}
output {
stdout{
codec=>rubydebug
}
}
By default, logstash will read data from the end of the file, that is, the logstash process will get data line by line in the form of tail -f command.
3 read TCP network data
Read network data, as demonstrated earlier, not here.
input {
tcp {
port => "1234"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
}
output {
stdout{
codec=>rubydebug
}
}
2: Filter plug-in
See official documents for details: https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
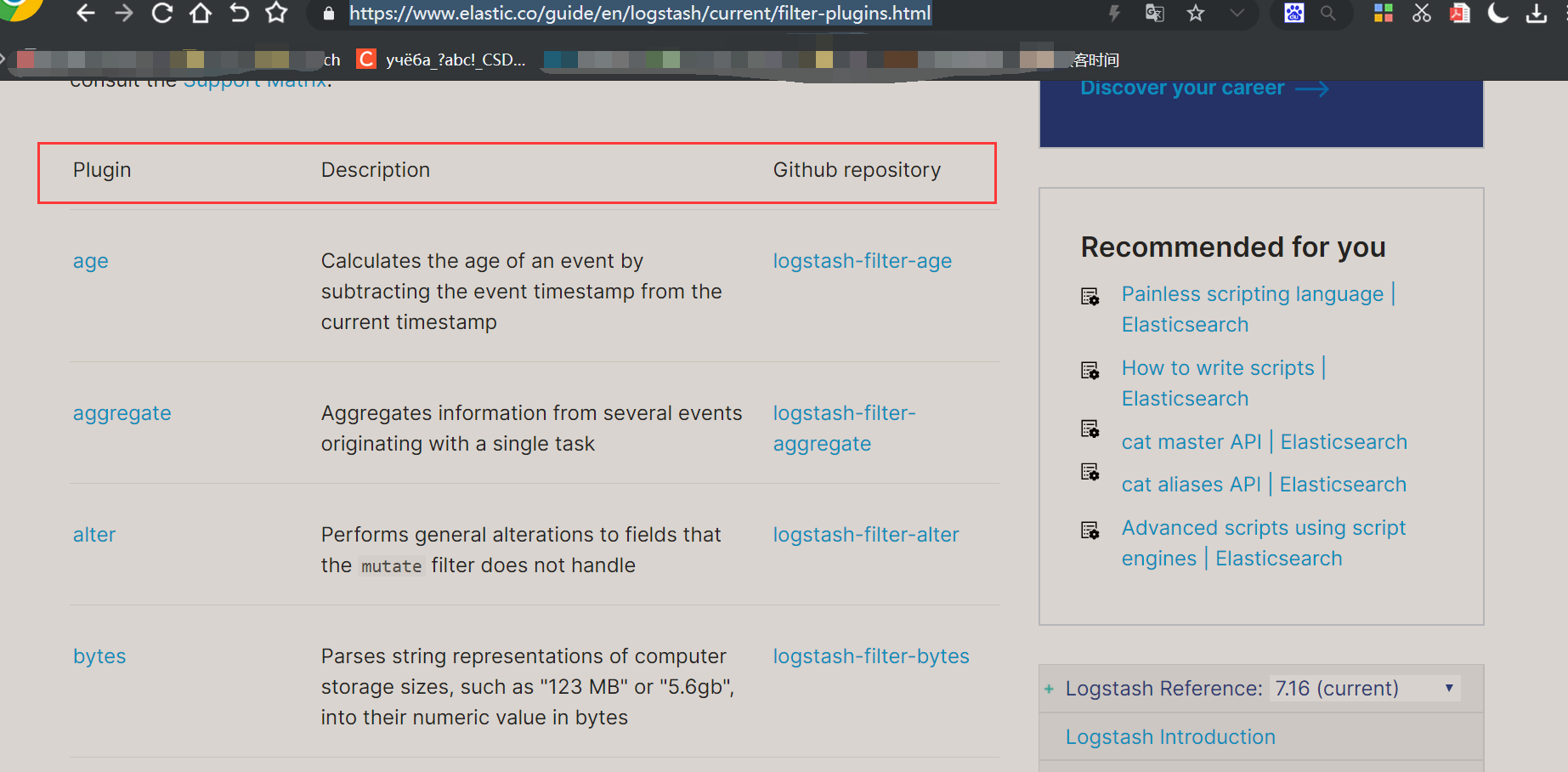
1 Grok regular capture
Through regular parsing of arbitrary text, unstructured log data is made into a structured and convenient query structure. It is the best way to parse unstructured log data in logstash.
Match a row of data with something. For example, after logstash reads the data, it will read a line of data into a message. To know exactly what each field is and facilitate query, Grok can divide this row of data into multiple fields.
Grok's syntax rules are:
%{grammar: semantics}
give an example:
-
For example, the input content is:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
- %The result of {IP:clientip} matching pattern is: clientip: 172.16.213.132
- %The result of {HTTPDATE:timestamp} matching pattern is: timestamp: 07/Feb/2018:16:24:19 +0800
- %{QS:referrer} the result of matching the pattern will be: referrer: "GET / HTTP/1.1"
-
The following is a combined matching pattern, which can get all the contents entered above:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}Through the above combined matching pattern, we divide the input content into five parts, namely five fields, and divide the input content into different data fields, which is very useful for parsing and querying log data in the future, which is the purpose of using grok.
-
Complete example
input{ stdin{} } filter{ grok{ match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"] } } output{ stdout{ codec => "rubydebug" } }Enter log content:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
-
Execution process
[root@localhost config]# ls java_pid12011.hprof logstash-sample.conf startup.options java_pid21521.hprof logstash.yml test1.conf jvm.options my-app.conf log4j2.properties pipelines.yml [root@localhost config]# vim test2.conf input { stdin { } } filter{ grok{ match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"] } } output { stdout { codec=>rubydebug } } ~ ~ ~ ~ "test2.conf" [new] 17L, 237C Written [root@localhost config]# ../bin/logstash -f test2.conf Using JAVA_HOME defined java: /opt/elasticsearch-7.6.1/jdk WARNING: Using JAVA_HOME while Logstash distribution comes with a bundled JDK. DEPRECATION: The use of JAVA_HOME is now deprecated and will be removed starting from 8.0. Please configure LS_JAVA_HOME instead. OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties [2022-01-11T16:31:45,624][INFO ][logstash.runner ] Log4j configuration path used is: /usr/local/logstash/config/log4j2.properties [2022-01-11T16:31:45,636][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 13.0.2+8 on 13.0.2+8 +indy +jit [linux-x86_64]"} [2022-01-11T16:31:45,919][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified [2022-01-11T16:31:47,168][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false} [2022-01-11T16:31:47,858][INFO ][org.reflections.Reflections] Reflections took 70 ms to scan 1 urls, producing 119 keys and 417 values [2022-01-11T16:31:49,066][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/usr/local/logstash/config/test2.conf"], :thread=>"#<Thread:0xfabd406 run>"} [2022-01-11T16:31:49,824][INFO ][logstash.javapipeline ][main] Pipeline Java execution initialization time {"seconds"=>0.75} WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by com.jrubystdinchannel.StdinChannelLibrary$Reader (file:/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/jruby-stdin-channel-0.2.0-java/lib/jruby_stdin_channel/jruby_stdin_channel.jar) to field java.io.FilterInputStream.in WARNING: Please consider reporting this to the maintainers of com.jrubystdinchannel.StdinChannelLibrary$Reader WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [2022-01-11T16:31:49,910][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"} [2022-01-11T16:31:49,985][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} The stdin plugin is now waiting for input: 172.16.213.132 [07/Feb/2022:16:24:19 +0800] "GET / HTTP/1.1" 403 5039 { "response" => "403", "clientip" => "172.16.213.132", "@timestamp" => 2022-01-11T08:32:38.109Z, "bytes" => "5039", "referrer" => "\"GET / HTTP/1.1\"", "message" => "172.16.213.132 [07/Feb/2022:16:24:19 +0800] \"GET / HTTP/1.1\" 403 5039", "timestamp" => "07/Feb/2022:16:24:19 +0800", "host" => "localhost.localdomain", "@version" => "1" }
2 time processing (Date)
The date plug-in is especially important for sorting events and backfilling old data. It can be used to convert the time field in the log record into a logstack:: timestamp object, and then transfer it to the @ timestamp field
Example (only the filter part is listed):
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
3 data modification (Mutate)
3.1 regular expression replacement matching field (gsub)
gsub can replace the matched value in the field with a regular expression, which is only valid for string fields
give an example:
- This example indicates that the file will be_ name_ Replace all "/" characters in the 1 field with ""
filter { mutate { gsub => ["filed_name_1", "/" , "_"] } }
3.2 delimiter split string into array (split)
Split can split the string in the field into an array by the specified delimiter
give an example:
- Set filed_name_2 fields are separated into arrays with "|" as interval.
filter { mutate { split => ["filed_name_2", "|"] } }
3.3 rename field
Rename can rename a field
give an example:
- Set field old_ Rename field to new_field.
filter { mutate { rename => { "old_field" => "new_field" } } }
3.4 remove_field
remove_field can delete a field
give an example:
- Delete the timestamp field.
filter { mutate { remove_field => ["timestamp"] } }
3.5 GeoIP address query classification
filter {
geoip {
source => "ip_field"
}
}
3.6 comprehensive examples
Profile content:
- Convert = > ["response", "float]: convert the response to the float type (originally resolved by the NUMBER type)
- Rename = > {"response" = > "response_new"}: Rename response to response_ new
-
input { stdin {} } filter { grok { match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" } remove_field => [ "message" ] } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } mutate { convert => [ "response","float" ] rename => { "response" => "response_new" } gsub => ["referrer","\"",""] split => ["clientip", "."] } } output { stdout { codec => "rubydebug" } } - Test log
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
- Operation process
[root@localhost config]# ls java_pid12011.hprof log4j2.properties my-app.conf test1.conf java_pid21521.hprof logstash-sample.conf pipelines.yml test2.conf jvm.options logstash.yml startup.options [root@localhost config]# [root@localhost config]# vim test3.conf input { stdin {} } filter { grok { match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" } remove_field => [ "message" ] } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } mutate { convert => [ "response","float" ] rename => { "response" => "response_new" } gsub => ["referrer","\"",""] split => ["clientip", "."] } } output { stdout { codec => "rubydebug" } } "test3.conf" [new] 23L, 556C Written [root@localhost config]# ../bin/logstash -f test3.conf Using JAVA_HOME defined java: /opt/elasticsearch-7.6.1/jdk WARNING: Using JAVA_HOME while Logstash distribution comes with a bundled JDK. DEPRECATION: The use of JAVA_HOME is now deprecated and will be removed starting from 8.0. Please configure LS_JAVA_HOME instead. OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties [2022-01-11T17:57:16,417][INFO ][logstash.runner ] Log4j configuration path used is: /usr/local/logstash/config/log4j2.properties [2022-01-11T17:57:16,430][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 13.0.2+8 on 13.0.2+8 +indy +jit [linux-x86_64]"} [2022-01-11T17:57:16,693][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified [2022-01-11T17:57:17,938][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false} [2022-01-11T17:57:18,676][INFO ][org.reflections.Reflections] Reflections took 86 ms to scan 1 urls, producing 119 keys and 417 values [2022-01-11T17:57:19,987][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/usr/local/logstash/config/test3.conf"], :thread=>"#<Thread:0x73426cc8 run>"} [2022-01-11T17:57:20,809][INFO ][logstash.javapipeline ][main] Pipeline Java execution initialization time {"seconds"=>0.81} WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by com.jrubystdinchannel.StdinChannelLibrary$Reader (file:/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/jruby-stdin-channel-0.2.0-java/lib/jruby_stdin_channel/jruby_stdin_channel.jar) to field java.io.FilterInputStream.in WARNING: Please consider reporting this to the maintainers of com.jrubystdinchannel.StdinChannelLibrary$Reader WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [2022-01-11T17:57:20,882][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"} The stdin plugin is now waiting for input: [2022-01-11T17:57:20,933][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} 172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039 { "referrer" => "GET / HTTP/1.1", "response_new" => "403", "bytes" => "5039", "timestamp" => "07/Feb/2019:16:24:19 +0800", "clientip" => [ [0] "172", [1] "16", [2] "213", [3] "132" ], "@timestamp" => 2019-02-07T08:24:19.000Z, "host" => "localhost.localdomain", "@version" => "1" }
3: Output plug-in (output)
Official documentation of this plug-in: https://www.elastic.co/guide/en/logstash/current/output-plugins.html
output is the last stage of Logstash. An event can go through multiple outputs. Once all outputs are processed, the whole event will be executed. Some common outputs include:
- File: indicates that log data is written to a file on disk.
- Elasticsearch: indicates to send log data to elasticsearch. Elasticsearch can save data efficiently, conveniently and easily.
3.1 output to standard output (stdout)
Output on console
output {
stdout {
codec => rubydebug
}
}
3.2 save as file
Store the output data in a file
output {
file {
path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}
3.3 output to elasticsearch
Output data to es
output {
elasticsearch {
host => ["192.168.1.1:9200","172.16.213.77:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
- host: is an array type value, followed by the address and port of the elasticsearch node. The default port is 9200. Multiple addresses can be added.
- Index: the name of the index written to elasticsearch. Variables can be used here. Logstash provides% {+ YYYY.MM.dd}. When parsing the syntax, if you see a string beginning with a + sign, you will automatically think that it is followed by a time format, and try to parse the subsequent string with a time format. This split writing method in days can easily delete old data or search data within a specified time range. Also, note that the index name cannot contain uppercase letters.
- manage_template: used to set whether to turn on the logstash automatic template management function. If it is set to false, the automatic template management function will be turned off. If we have customized the template, it should be set to false.
- template_name: this configuration item is used to set the name of the template in Elasticsearch.
Comprehensive test
Monitor the nginx unit log, obtain data from the nginx log file, and finally output it to the corresponding index in es through filter conversion
input {
file {
path => ["D:/ES/logstash-7.3.0/nginx.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
host => ["localhost:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}