Catalog
2. Use of Join in Relational Database MySQL
Internal connection: INNER JOIN
1. Introduction to Reduce Join
2.2 Ideas for implementation: reduce end table merge (data skew)
3. Specific method: use DistributedCache
4. Case 1: Order Information Table
5. Case 2: Student Information Table (three tables connected)
I. Introduction
First, understand the use of Join in relational databases.
Join is also used in MapReduce to connect two files.
There are two solutions to the join problem of two tables using the MR program
1. reduce end join
Encapsulating data as a Java object on the map side
join operations on the reduce side depending on the value of the object
2. map-side join
Store small files by buffering streams, and join based on different object values during map phase
2. Use of Join in Relational Database MySQL
(The usage of JOIN in MySQL is summarized in https://www.cnblogs.com/fudashi/p/7491039.html)
In relational databases, Join is mainly used to join two tables, just like the English word "join", it can be divided into inner join, outer join, left join, right join and natural join.

Cartesian product: CROSS JOIN
Cartesian product combines data from table A with data from table B. Suppose there are n records in table A and M records in table B. After combining Cartesian products, n * m records will be generated.
Internal connection: INNER JOIN
Inner Join INNER JOIN is the most common join operation (that is, finding the intersection of two tables), and from the Cartesian product point of view, it picks out the record of the ON clause from the Cartesian product. There are four writings: INNER JOIN, WHERE (equal join), STRAIGHT_JOIN, JOIN (omit INNER).
Left Connection: LEFT JOIN
The left join is the intersection of the two tables and the rest of the data in the left table. From the Cartesian product point of view, it is to jump out of the Cartesian product the record that the ON condition is valid, then add the remaining records in the left table.
Right Connection: RIGHT JOIN
Same as a left join, it is the intersection of the two tables and the rest of the data in the right table.
Outer connection: OUTER JOIN
An outer join is a union of two sets. From the Cartesian product point of view is to pick out from the Cartesian product the records that the ON clause condition is valid, then add the remaining records in the left table and the remaining records in the right table. MySQL does not support OUTER JOIN, but you can do UNION operations on the results of left and right connections.
3. Reduce Join
1. Introduction to Reduce Join

2. Cases
2.1 Requirements:
Order Data Table t_order:
| id | pid | amount |
| 1001 | 01 | 1 |
| 1002 | 02 | 2 |
| 1003 | 03 | 3 |
Commodity Information Table t_product
| pid | pname |
| 01 | millet |
| 02 | Huawei |
| 03 | GREE |
Requires that data from the commodity information table be merged into the order data table based on the commodity pid.
Final data format:
| id | pname | amount |
| 1001 | millet | 1 |
| 1004 | millet | 4 |
| 1002 | Huawei | 2 |
| 1005 | Huawei | 5 |
| 1003 | GREE | 3 |
| 1006 | GREE | 6 |
If you want to do this, you can use MySQL to make use of Select id, b.pname, a.amount from t_ Order as a left join_ Product as B on a.pid=b.pid is easy to implement. However, if you have a large amount of data, it will take a very long time to implement it using MySQL, and you will not be able to complete the requirements immediately. MapReduce can solve this problem.
2.2 Ideas for implementation: reduce end table merge (data skew)
By using the Association criteria as the key of map output, two tables of data satisfying the join criteria are sent to the same reduce task with the file information from which the data originates, and the data is concatenated in reduce.

2.3 Steps
Step 1: Writing JavaBean objects
First declare a JavaBean object, OrderBean, which is a composite JavaBean that covers all the information involved in both tables. This bean is used in the order table, and a bean is used in productions. So to distinguish between two tables, you should set a variable flag that defines whether the table is an order table or a product table. At the same time, in order to pass and output this bean as a serialized information, you also need to inherit the Writable class for custom serialization, and implement the serialization and deserialization methods within it.
Step 2: Writing the Mapper class
The Mapper class enables reading of file slice information and encapsulates different OrderBean objects depending on the file name. Based on previous lessons, in the Mapper stage, the information obtained from the slice data is passed to the JavaBean object and then to the Reducer stage through the context,write() method. Then during the Mapper phase, one question needs to be considered: How do I get the slice information from which file? How do I correspond the slice information to the file I belong to? As long as these two issues are resolved, data transfer to the Reduce phase is readily available.
First, you need to understand that the default slicing mechanism for the MapReduce program is TextInputFormat, whereas in case requirements you can see that there is no need to customize the slicing mechanism here. So according to the slicing mechanism of TextInputFormat: cut data by file, that is, each file has at least one slice, it is easy to see that each slice data corresponds to a fixed file, and there is no slice of data from two files. So you can get the path to the file based on the slice, and then map the path to the information of the slice.
With this in mind, add one more method: the setup() method, which can be understood as an initialization method similar to @Before for Junit unit tests, and used in the Mapper phase to indicate that the setup() method must be executed once before each map() method is executed. So you can use the setup() method to query the path of the file corresponding to the slice in the setup() method so that maps can mark which file they are in each time they slice.
Once you know which file the slice information is in, the question to consider is how to match the slice information with the data information of the file to which it belongs. Each row of sliced data is cut by the split() method and an array file is generated. The array file can have three items. Then it is either the data in the order table or two items. Then it is the data in the product table. So how can I decide if there are three or two items in the array? You can get the filename of the slice information based on the action defined in the setup, and then pass out the corresponding value based on the filename. At this point, you will recall the flag defined in the JavaBean object. You can distinguish between the two file data based on the flag value.
In summary, the map phase can be divided into the following steps:
1. The MR program reads in two files: order.txt, product.txt. After reading data through InputFormat, perform different data encapsulation according to different files
2. Read the file slice information and encapsulate different OrderBean objects depending on the file name (mainly by labeling the data of the table you are in the Mapper phase)
3. After data encapsulation is completed, if join logic is used, the join fields of the two tables need to be used as key s and the objects as value s to be sent to Reducer.
The data format for the Map phase processing is:
| key | value |
| 1 | OrderBean(1001 1 1 order) |
| 1 | OrderBean(1 millet product) |
| 1 | OrderBean(1002 1 3 order) |
That is, pid (product id) is used as the key value, and other information about the corresponding key values of the two tables is passed to the Reduce stage as the value value.
Step 3: Writing the Reducer class
Through the Map phase, you can get the key-value pairs as above, and through the analysis of the tables, you can get the relationship between two tables: one product can correspond to multiple orders, and one order can only correspond to one product. The task of the Reduce phase is to combine the data from the Map phase and output the pname (product name) in the product table and the oid (order number) and count (order number) in the order table as result values to the result file.
At this point, you can read the pid-like OrderBean's collection data with pid as the key. There is no doubt that there is only one OrderBean with product information in the pid-like OrderBean collection, but there will be many OrderBeans with orders. An OrderBean object can be set to store data in the product table obtained during the Map phase, and a collection of OrderBean objects can be set to store data in the order table obtained during the Map phase, which can be used to distinguish when and what values should be stored by the flag value defined in the Map phase. Finally, the case requirements can be completed by traversing the product id in the order to the name in the product information and outputting it to the result file.
Step 4: Writing the Driver class
The Driver class is written as usual, but it is important to note that the file passed in here is two files.
2.4 Source Code
a) OrderBean.java
@Data
public class OrderBean implements Writable {
private String orderId = "";
private String pid = "";
private int amount;
private String pname = "";
/**
* Used to distinguish encapsulated object of order table from encapsulated object of product table
*/
private String flag = "";
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderId);
dataOutput.writeUTF(pid);
dataOutput.writeInt(amount);
dataOutput.writeUTF(pname);
dataOutput.writeUTF(flag);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.orderId = dataInput.readUTF();
this.pid = dataInput.readUTF();
this.amount = dataInput.readInt();
this.pname = dataInput.readUTF();
this.flag = dataInput.readUTF();
}
@Override
public String toString() {
return orderId + " " + pname + " " + amount;
}
}b) OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, Text, OrderBean> {
/**
* The name of the file where the current slice is located
*/
String fileName;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// Get Slices
FileSplit fileSplit = (FileSplit) context.getInputSplit();
// Get the file path where the slice data is located
Path path = fileSplit.getPath();
// Get File Name
fileName = path.getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] array = line.split("\t");
OrderBean ob = new OrderBean();
String file = "order";
if (fileName.contains(file)) {
// If it is an order table, you only need to encapsulate it in the OrderBean object: orderId, pid, amount, flag
ob.setOrderId(array[0]);
ob.setPid(array[1]);
ob.setAmount(Integer.parseInt(array[2]));
ob.setFlag("order");
} else {
// If it's a product table, you just need to encapsulate it in an OrderBean object: pid, flag
ob.setPid(array[0]);
ob.setPname(array[1]);
ob.setFlag("product");
}
context.write(new Text(ob.getPid()), ob);
}
}c) OrderReduce.java
public class OrderReducer extends Reducer<Text, OrderBean, NullWritable, OrderBean> {
/**
* @param key product id
* @param values Order information and product information with the same product id
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException {
// There are multiple orders
List<OrderBean> orders = new ArrayList<>();
// There is only one product information
OrderBean product = new OrderBean();
/**
* When using an enhanced for loop, the preceding variables are always the same object, but point to different addresses.
* If you assign a value directly to another variable, then the value of the value's address changes, and so does the variable assigned to it.
*/
for (OrderBean value: values) {
// If it is order data, add order data to the collection
if ("order".equals(value.getFlag())) {
OrderBean orderBean = new OrderBean();
// copy data from value into orderBean. Each object fetched in the enhanced for loop is copied to the same value, and if only one is added to the set, it is necessary to separate the two objects in this way
orderBean.setOrderId(value.getOrderId());
orderBean.setPid(value.getPid());
orderBean.setAmount(value.getAmount());
orderBean.setFlag(value.getFlag());
orders.add(orderBean);
} else {
// If it is product information, assign the product information data to the product object
product.setPid(value.getPid());
product.setPname(value.getPname());
product.setFlag(value.getFlag());
}
}
// Change the product name in the order to the name in the product information
for (OrderBean order: orders) {
order.setPname(product.getPname());
context.write(NullWritable.get(), order);
}
}
}d) OrderDriver.java
public class OrderDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderBean.class);
job.setReducerClass(OrderReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(OrderBean.class);
FileInputFormat.setInputPaths(job, new Path("/school/join/*"));
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root");
Path output = new Path("/school/join/test_reduce");
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}2.5 Run Screenshot

3. Reduce Join drawbacks
In this way, there may be hundreds of M data in the product table, but there may be several T data in the order table. The merge operation is completed in the reduce phase, the processing pressure at the reduce side is too high, the processing logic of map node is simple, the operation load is low, the resource utilization is not complete, and the data skew is easy to occur in the reduce phase.
Solution: Map Join
4. Map Join
1. Use scenarios
Map Join works for scenes where a table is very small and a table is large.
2. Advantages
Think about it: Processing too many tables on the Reduce side makes it very easy to skew data. What should I do?
Caching multiple tables on the Map side increases Map side business, reduces data pressure on the Reduce side, and minimizes data skewing.
3. Specific method: use DistributedCache
(1) Read the file into the cache collection during the Mapper setup phase.
(2) Load the cache in the driver function.
//Cache normal files to the Task Run Node.
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
join in in Map phase is mainly used for one technology: MR caching technology for small files - to process small cached files in Mapper's setup
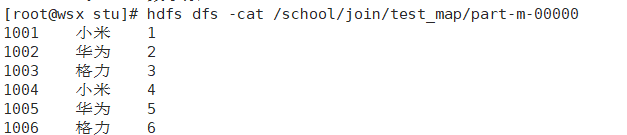
4. Case 1: Order Information Table
4.1 Requirements
Same Reduce Join Case
4.2 Ideas
Small tables can be distributed to all map nodes, so that map nodes can merge large table data they read locally and output the final results, which can greatly improve the concurrency of merge operations and speed up processing.
This requires that all data be processed on the Map side with the following logic:
1. Reads small cached data into a collection of memory during the setup() phase, caching backup
2. Read the large file (large table order.txt) in the map() phase and join based on the small table data we cached

4.3 Source Code
1) OrderDriver.java
public class OrderDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
// Small files need to be cached ahead of time -- you need to read the cache in the map phase setup method for data processing
job.addCacheFile(new URI("/school/join/product.txt"));
// The input file only needs to specify a large file, that is, the input path of the order file.
FileInputFormat.setInputPaths(job, new Path("/school/join/order.txt"));
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root");
Path output = new Path("/school/join/test_map");
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}2) OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
Map<String, String> products = new HashMap<>();
/**
* Cached small file data is read and stored as a collection standby.
* The small file is the product table, one field is pid, and one field is pname
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// Get small cached files
URI[] cacheFiles = context.getCacheFiles();
URI cacheFile = cacheFiles[0];
// Get the path to the cache file
String path = cacheFile.getPath();
try {
// Create a file system to get the io stream of cached files
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), context.getConfiguration(), "root");
// Get io stream of cache file
FSDataInputStream open = fs.open(new Path(path));
// Converting io stream to character buffer stream allows one line of data to be read from a file at a time
BufferedReader br = new BufferedReader(new InputStreamReader(open));
String line = null;
while ((line = br.readLine()) != null) {
// Cut a row of data to get [1, millet]
String[] array = line.split("\t");
// Transfer data to a collection
products.put(array[0], array[1]);
}
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
/**
* map All you need to do is process the data from the order form
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Order. One row of data in TXT [1001, 01, 5]
String[] array = value.toString().split("\t");
String orderId = array[0];
String pid = array[1];
String amount = array[2];
// Get Product Name - Get the value from the product collection just cached based on the pid of the order file
String pname = products.get(pid);
String line = orderId + "\t" + pname + "\t" + amount;
context.write(NullWritable.get(), new Text(line));
}
}4.4 Run Screenshot
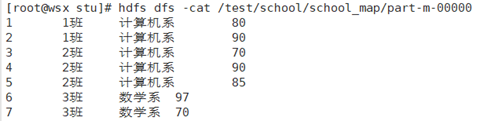
5. Case 2: Student Information Table (three tables connected)
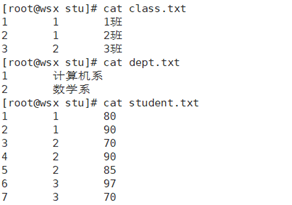
5.1 Requirements
There are three tables in total: one is the student table, which stores the student id, the class ID of the student, and the student's score; A table is a class table, which records the class id, the ID of the Department in which the class is located, and the class name. One table is the dept table, which stores the system ID and name.
Finally, it is required to output to the result file in the format "Student id", "Class name", "Department name", "Score".
5.2 Ideas
As in case one, the analysis requirements can treat the class and dept tables as small scales, store them in two Map collections through buffer streams, with key values being their id s, then read the student table information in the map() method, match the IDS and Map collections stored in the student table, get the corresponding values, and output them to the result file.
5.3 Source Code
1) SchoolDriver.java
public class SchoolDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(SchoolDriver.class);
job.setMapperClass(SchoolMapper.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.addCacheFile(new URI("/school/stu/class.txt"));
job.addCacheFile(new URI("/school/stu/dept.txt"));
FileInputFormat.setInputPaths(job, new Path("/school/stu/student.txt"));
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root");
Path path = new Path("/test/school/school_map");
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}2) SchoolMapper.java
public class SchoolMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
Map<String, String> dept = new HashMap<>();
Map<String, String[]> cla = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
URI file1 = cacheFiles[0];
URI file2 = cacheFiles[1];
String path1 = file1.getPath();
String path2 = file2.getPath();
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataInputStream open1 = fs.open(new Path(path1));
FSDataInputStream open2 = fs.open(new Path(path2));
BufferedReader br1 = new BufferedReader(new InputStreamReader(open1));
BufferedReader br2 = new BufferedReader(new InputStreamReader(open2));
String line = null;
while ((line = br1.readLine()) != null) {
String[] split = line.split("\t");
cla.put(split[0], new String[]{split[1], split[2]});
}
while ((line = br2.readLine()) != null) {
String[] split = line.split("\t");
dept.put(split[0], split[1]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
String[] classInfo = cla.get(split[1]);
String sid = split[0];
String className = classInfo[1];
String deptName = dept.get(classInfo[0]);
String score = split[2];
String result = sid + "\t" + className + "\t" + deptName + "\t" + score;
context.write(NullWritable.get(), new Text(result));
}
}5.4 Run Screenshot