The project requirement is to provide an interface to capture the video address in the web page by entering a web page address! For example, open a Web address
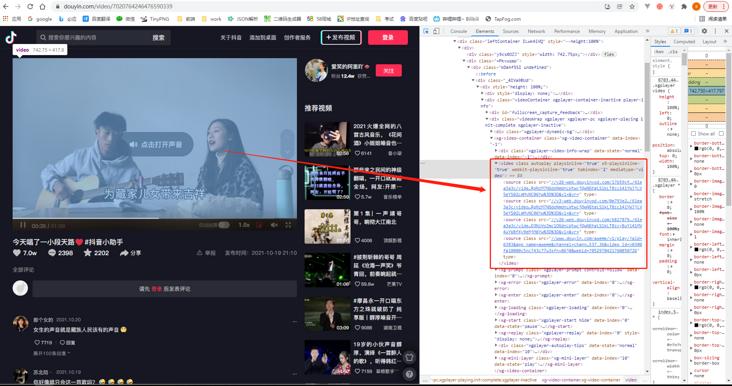
You need to extract the video address from the web page. As the inertial thinking of front-end developers, it's not very simple to see the html structure of this web page. It's done in one line of code: document querySelector('video source'). src

Hee hee, it's done. Get ready to fish~
wait! This only gets the video address in the browser console, but how to convert it into providing an interface and return this address through the interface? The preliminary guess is to use the get request to obtain the html of the web page, then analyze the dom structure and parse the video tag.
Wrong attempt
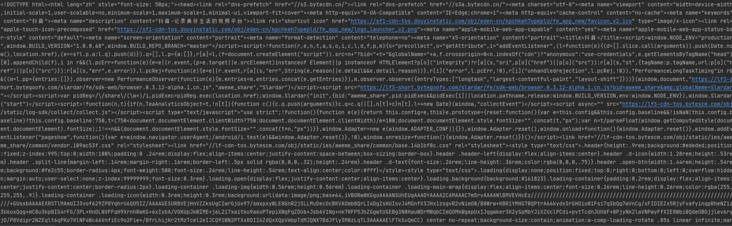
The content obtained directly through the address of the get request page is not what we see in the browser. Most of the current web pages are dynamic web pages, that is, the final content of the page is dynamically spliced by executing the script after loading js, so the video tag in the page is not spliced directly from the server.
The request screenshot of the browser loading the web page does not directly return the dom structure, but loads a pile of js and css files
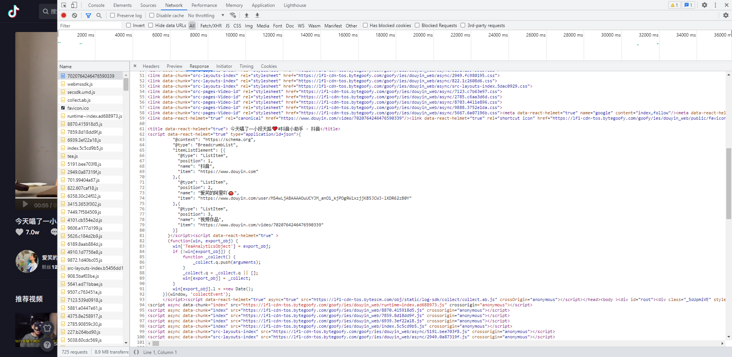
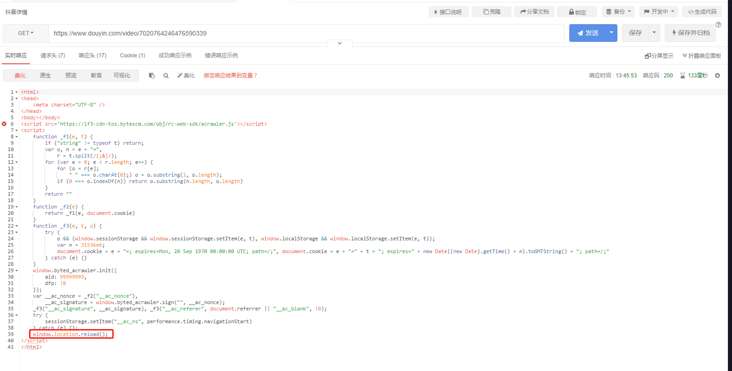
And! Many websites have done anti creeping measures. Directly asking the page's address will return to an intermediate page, such as jitter and micro-blog's video detail page, which will return a page similar to authentication. The page is initially analyzed. The transfer page should be tiktok to determine whether there is any corresponding cookie information, if there is no corresponding information. It will set cookies and other information for the browser, and finally go to a window location. reload(); Let the page refresh once (the microblog will directly go to the page of a Sina Visitor System and will not directly jump to the details page). This script will be executed automatically in the browser, so it will be reloaded to see the final details page. However, the get request only gets the html of the transit page, and does not go to the real details page.
Tiktok detail page get request
Twitter details page git request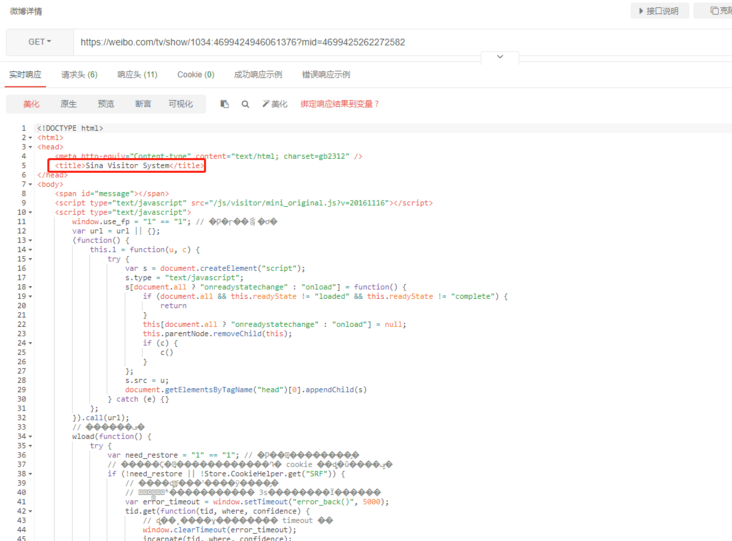
oh dear! If you can't even get the final web page information, how can you get the page video address? You can't fish happily now
After investigation, we decided to adopt node JS + puppeter to realize this function. This paper mainly records the implementation ideas of the project, the difficulties encountered in development and deployment and their solutions, which are only for learning and reference.
Puppeter is a node released by the chrome development team in 2017 JS package, used to simulate the operation of Chrome browser Mainly run Chromium to load web pages through puppeter, analyze the page dom, obtain video tags, and capture video addresses
reference material:
https://github.com/puppeteer/puppeteer
Development environment (Windows)
After deciding to use puppeteer JS, it will be developed under windows environment,
The windows environment is node V12 16.2, puppeteerjs v2. one point one
The latest version of puppeterjs is 13.1.1. But puppeterjs v3 Version 0 and above requires Node v10 and above. Because my local development environment node is v12 and the node on the server is v8, there is no problem with local development, but the deployment on the server has been unsuccessful, and many other projects on the server are based on node v8, so the node version on the server should not be upgraded. In order to keep consistent with the server version, puppeter JS in windows environment also uses version 2.1.1;
Direct code
server2.js
const puppeteer = require('puppeteer');
async function getVideoUrl () {
const browser = await puppeteer.launch();// Open browser
const page = await browser.newPage();
await page.emulate(puppeteer.devices['iPhone 6'])
await page.goto('https://www.douyin.com/video/7020764246476590339'); // Jump to the specified page
await page.waitFor(2000) // Delay 2s to load page puppeter2 1.1 use waitFor ^13.0.1 use waitForTimeout above
const pageHtml = await page.content(); // Get the full HTML contents of the page, including the DOCTYPE
console.log(pageHtml);
}
getVideoUrl()Execute node server2 JS, the output result is the html code of the details page
puppeteer. headless in launch defaults to true. If it is set to false, a Chromium loading web page will be opened and the web page can be debugged directly!
await puppeteer.launch({
headless: false, // Headless browsing
});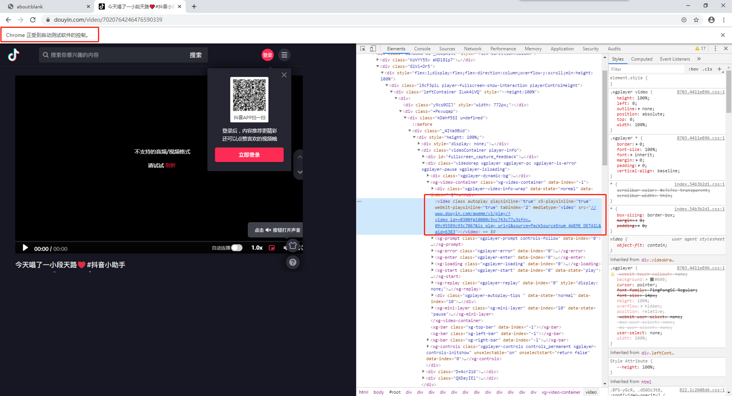
With the html code, how can we get the video tag further?
Analyze video tags directly using dom
The puppeter provides us with the corresponding api, because the browser rendering dom has requested the interface to take time, because the first time we get the web page code is not complete, so we need to delay.
await page.waitForTimeout(2000); // Delay 2s to load page puppeter2 1.1 use waitFor ^13.0.1 use waitForTimeout above
const videoSrc = await page.$eval('video source', (el) => {
let src = '';
if (el && el.src) {
src = el.src;
}
return src;
});Intercept interface
Some pages are the video addresses obtained directly through the request interface. For this kind of web page, we can use the above method to analyze the dom after the page is loaded. However, when consulting the document of puppeter, we find that we can directly intercept the interface and obtain the return information of the interface,
Therefore, if we know the request rules for the specified details, we can obtain the corresponding data directly through the interface response.
// Register response listening events
page.on('response', async (response) => {
if (response.ok()) {
const request = response.request();
const reqUrl = request.url();
if (reqUrl.indexOf('/api/getHttpVideoInfo.do') > -1) { // Intercept / API / gethttpvideoinfo Do interface
const respData = await response.json();
const video = respData.video;
if (video && video.validChapterNum > 0){
const currentChapter = video[`chapters${video.validChapterNum}`];
if (currentChapter && currentChapter.length > 0 && currentChapter[0] && currentChapter[0].url) {
resolve(currentChapter[0].url)
}
}
}
}
})In this way, the pointer pair has a clear interface and can be used on the page that can get the corresponding request parameters!
Add front-end page to improve interface
The complete code has been submitted to github, and the link is given later
Open the local web page to visit: localhost:18000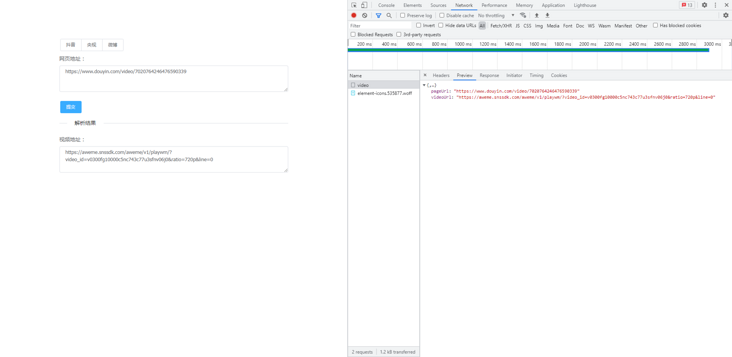
Server deployment (Linux)
The server environment is Linux, and the system is CentOS-8, node JS version is V8 11.3. There are some differences between linux environment and windows environment, especially when installing puppeter
The following error will be reported when installing the puppeter
ERROR: Failed to download Chromium r722234! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOAD" env variable to skip download. Error: EACCES: permission denied, mkdir '/opt/video-url-analysis/node_modules/puppeteer/.local-chromium'
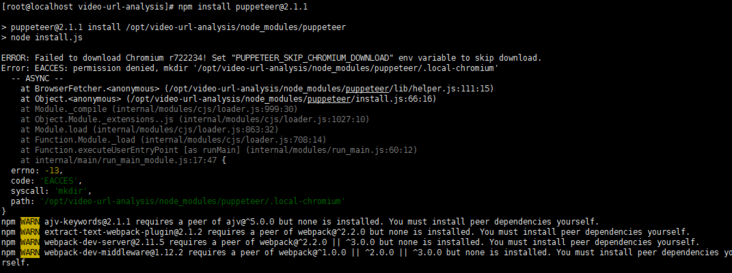
Because Chromium will be installed when installing puppeter, which requires permissions, you can use the following command to install it in linux environment
npm install puppeteer@2.1.1 --unsafe-perm=true --allow-root
After installation, start the program, run it successfully and capture the web video!
other
To start the browser headless under linux, you need to set it to true and add the args parameter
const browser = await puppeteer.launch({
headless: true, // Whether to enable headless browsing. The default is true
args: [
'--no-sandbox',
'--disable-setuid-sandbox'
]
});Other abnormal errors:
1.Failed to launch the browser process
Failed to launch the browser process ... error while loading shared libraries: libXss.so.1: cannot open shared object file: No such file or directory
There should be a lack of chromium. Solve the problem after installing chromium manually
sudo yum install -y chromium
Or (I used the latter to solve the problem)
sudo yum -y install libXScrnSaver-1.2.2-6.1.el7.x86_64
2. There is an error installing software dependency using yum. The system always prompts that the software package cannot be found
[root@localhost video-url-analysis]# sudo yum install -y chromium Last metadata expiration check: 0:00:47 It was executed at 21:35:27 on Thursday, January 20, 2022. No matching parameters found: chromium Error: no match: chromium
The reason is that the epel source is not installed in CentOS 8. After installing the epel source, the problem is solved:
yum install epel-release
code
The complete code has been uploaded https://github.com/zhaosheng808/video-grab Welcome to star, for learning reference only, do not use it in illegal ways
1. Installation dependency
npm install
2. Local development
npm run dev
Open the local web page to visit: localhost:18000
summary
The development under windows environment is relatively smooth. Because I am a front-end cutaway and have less server contact, there are many problems encountered in linux server deployment. Therefore, record the problem-solving process to facilitate subsequent developers to solve problems smoothly.
There is a lack of knowledge on the service side. If there is any shortage, please forgive me!