Recently, I was studying video editing. I found a lot of video materials from the Internet and found some good material websites. For example, this website: www.mazwai.com has a lot of Free HD video materials. Sometimes I want to get the information of all relevant video materials searched through a keyword. The manual click efficiency is too low. I happen to be learning python crawlers recently, so I thought of using crawlers to obtain video material information.
For example, I want to search for UAV Related videos. I enter drone in the search box, and the website is like this.

When we open the developer tool of chrome and refresh the web page, we can see the response to the first request, including a lot of video material information.
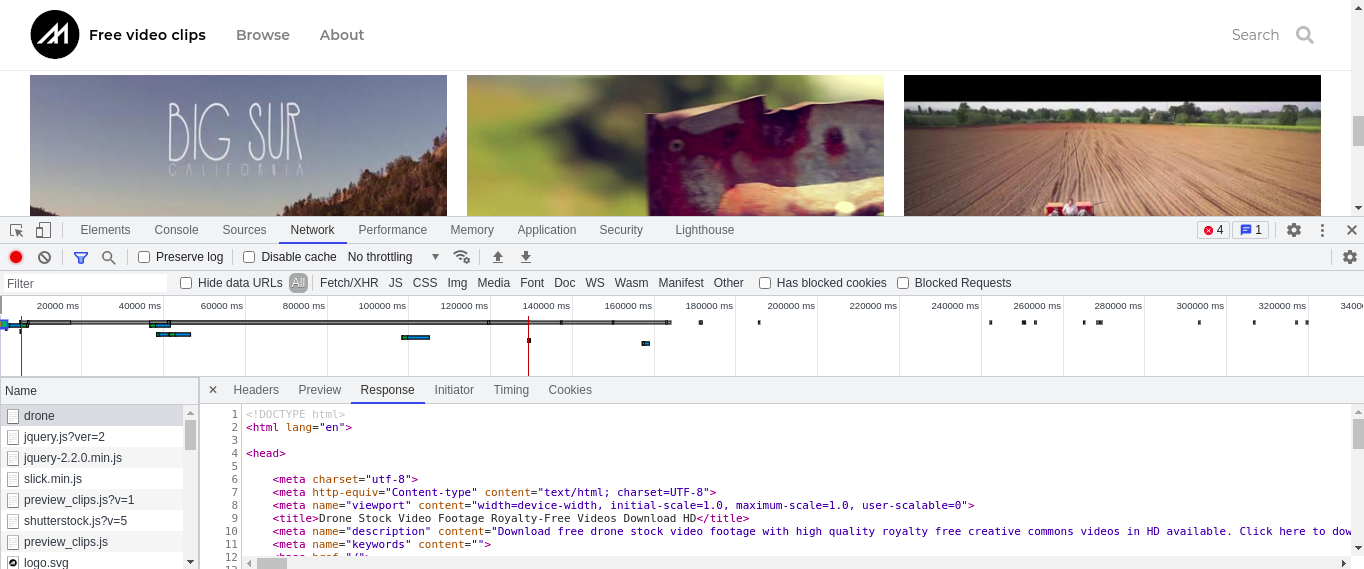
As we pull down the page, we see that new video materials are refreshed, which reminds us that the page is updated asynchronously through ajax. We choose XHR to view ajax requests.
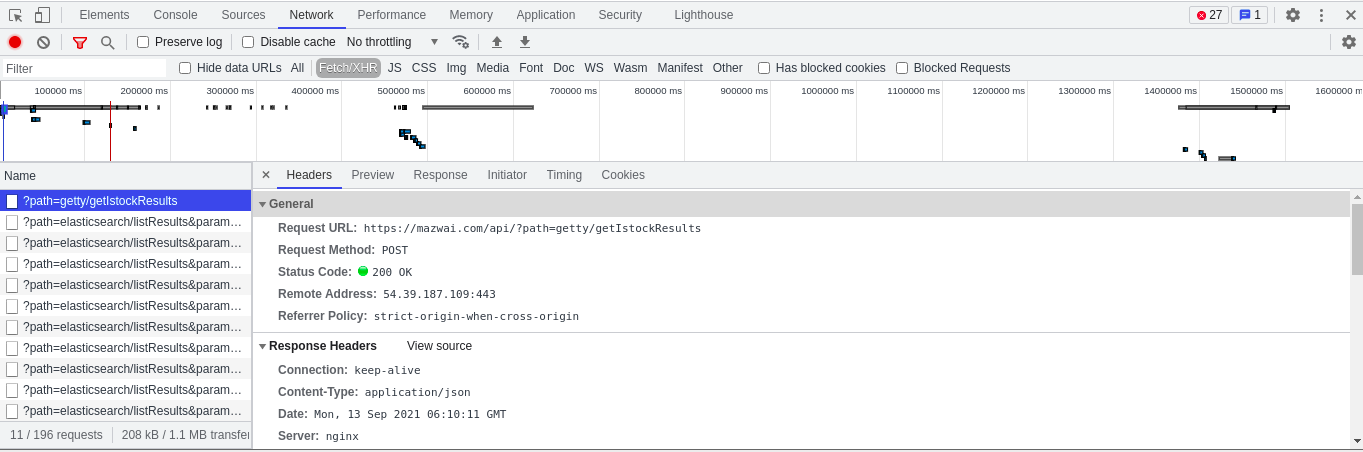
First of all, we analyzed that without the video information on our web page, it should be an external chain information. We can't use it. We can directly look at the following requests. The format of each subsequent request looks the same. Let's take the first one for analysis.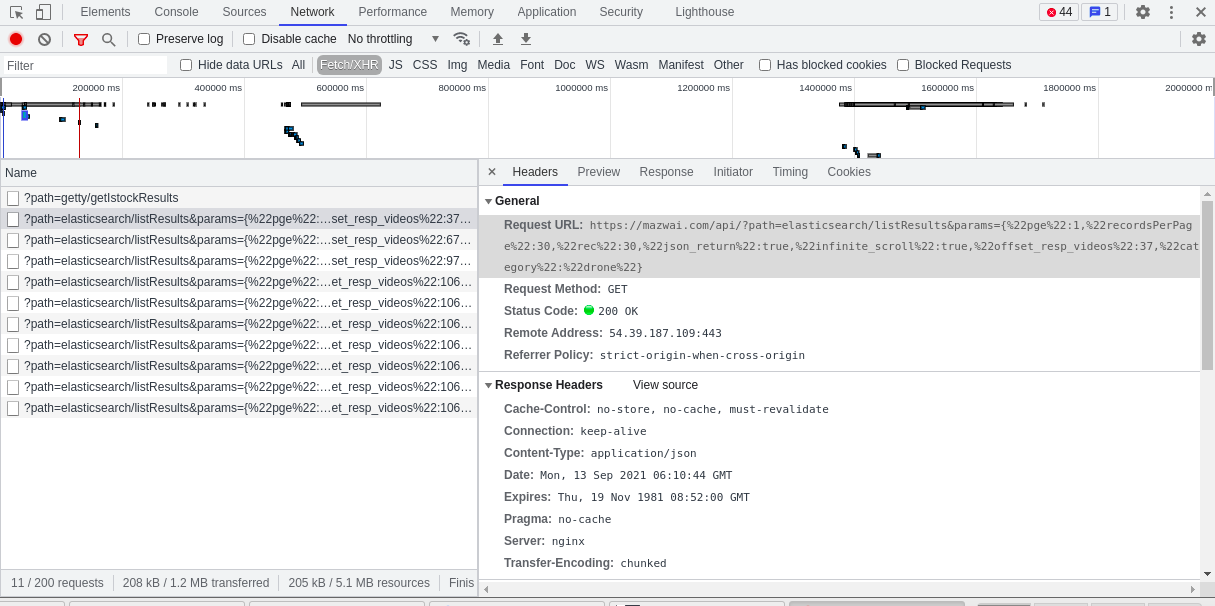
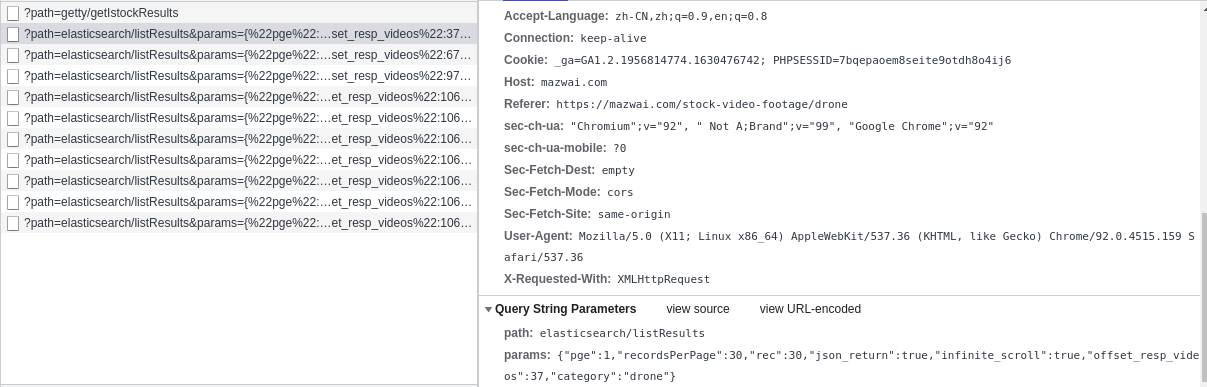
We can see that this is a GET type request with two parameters: path and params. The value of params is a dictionary, which contains many other parameters. When we compare the parameters of other requests, we can find that the contents of the path parameter are exactly the same, and there are only pge and offset in the params parameter_ resp_ Videos is updating. And the pge value will not change after it is updated from 1 to 4, but offset_resp_videos will not change after being updated to 106.
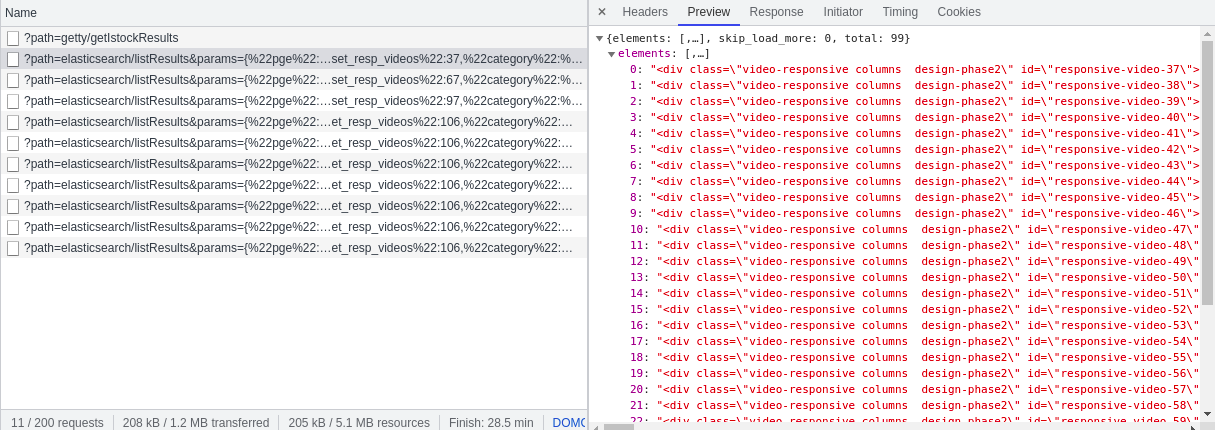
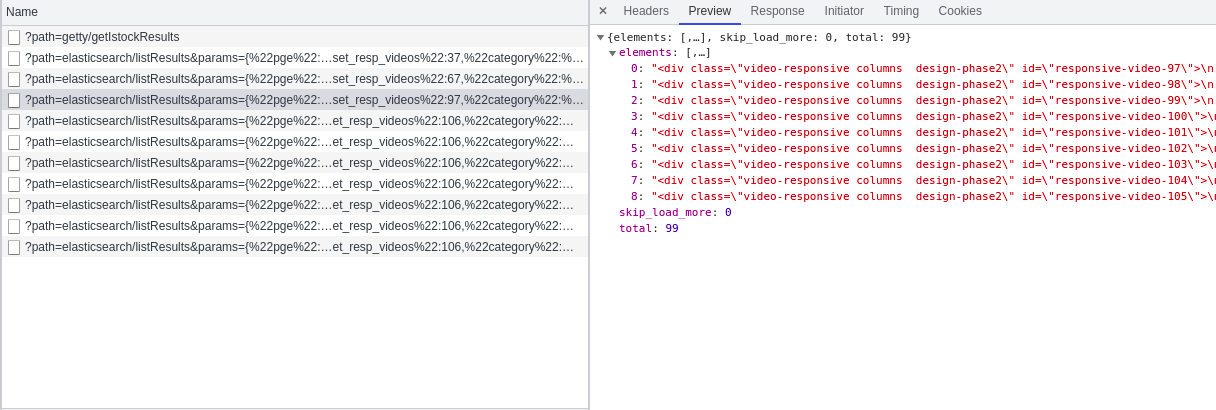
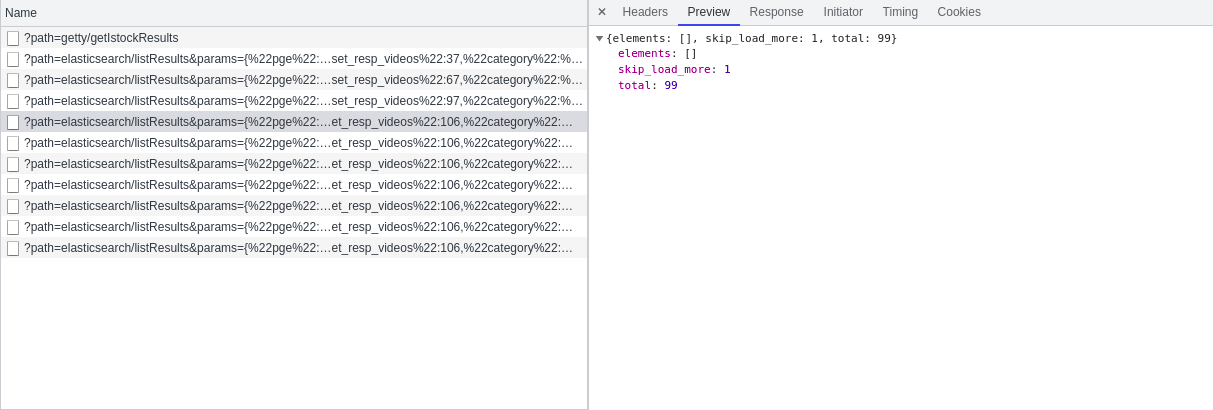 We further analyzed the responses. When PGE is 1 and 2, each response contains 30 video information. When PGE is 3, there are only 9 video information. When PGE is 4, there is no video information. This shows that when pge=3, all video information has been obtained. Therefore, when we simulate ajax to obtain video information, the range of PGE is 1-3, and through analysis, we can also get: offset_resp_videos=(pge-1) * 30 + 37, then we can construct the url when simulating ajax requests through python.
We further analyzed the responses. When PGE is 1 and 2, each response contains 30 video information. When PGE is 3, there are only 9 video information. When PGE is 4, there is no video information. This shows that when pge=3, all video information has been obtained. Therefore, when we simulate ajax to obtain video information, the range of PGE is 1-3, and through analysis, we can also get: offset_resp_videos=(pge-1) * 30 + 37, then we can construct the url when simulating ajax requests through python.
We can see the html information of each video by viewing the Elements information.
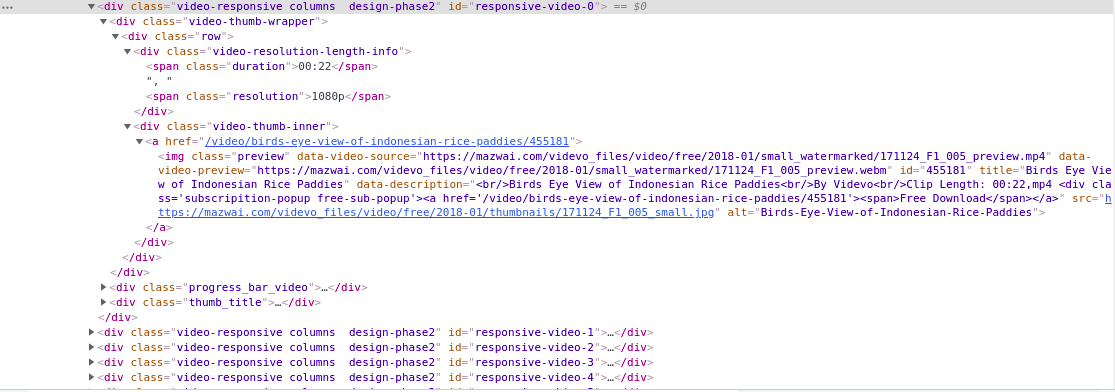
Among them, the first 30 videos are obtained through static requests, and the rest are obtained through ajax asynchronous requests. The html format is obtained statically, and we can parse it directly; The response obtained through ajax is in json format. We need to process it with json library to obtain the html text of video information.

You can see that in the ajax response, the elements element is a list, and each element is the html text of the video information, which is in the same format as that in the static web page, so we need to use the json library to obtain the video information elements in the ajax response.
For video materials, we are more concerned about id, duration, resolution, title, preview link and video link. We can get relevant information through xpath.
Here are the relevant codes:
from urllib.parse import urlencode
import requests
import json
from lxml import etree
import time
import csv
items = []
headers = {
'Host': 'mazwai.com',
'Referer': 'https://mazwai.com/stock-video-footage/drone',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# Get static web page
def get_first_page():
base_url = "https://mazwai.com/stock-video-footage/drone"
try:
rsp = requests.get(base_url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# Parsing static web pages
def parse_html_result(result):
html = etree.HTML(result)
elements = html.xpath('//div[contains(@class, "video-responsive")]')
print(len(elements))
for element in elements:
element = etree.HTML(etree.tostring(element))
parse_html_element(element)
# Simulate ajax request to get dynamic web page
def get_follow_page(page, start_idx):
base_url = "https://mazwai.com/api/?"
params = '{' + '"pge":{},"recordsPerPage":30,"recordsPerPage":30,"rec":30,"json_return":true,"infinite_scroll": true,"offset_resp_videos":{},"category": "drone"'.format(page, start_idx + (page-1)*30) + '}'
total = {
'path': 'elasticsearch/listResults',
'params': params
}
url = base_url + urlencode(total)
print(url)
try:
rsp = requests.get(url, headers=headers)
if rsp.status_code == 200:
return rsp.text
except requests.ConnectionError as e:
print('Error:', e.args)
# Parsing ajax responses
def parse_json_result(result):
rsp = json.loads(result)
for element in rsp['elements']:
element = etree.HTML(element)
parse_html_element(element)
# Parsing a single element containing video information
def parse_html_element(element):
item = []
id = element.xpath('//div[contains(@class, "video-responsive")]/@id')
imgsrc = element.xpath('//img/@src')
videosrc = element.xpath('//img/@data-video-source')
title = element.xpath('//img/@title')
duration = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="duration"]/text()')
resolution = element.xpath('//div[@class="video-resolution-length-info"]/span[@class="resolution"]/text()')
item.append(id[0])
item.append(title[0])
item.append(duration[0])
item.append(resolution[0])
item.append(imgsrc[0])
item.append(videosrc[0])
items.append(item)
def write_csv():
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'title', 'duration', 'resolution', 'img_url', 'video_url'])
writer.writerows(items)
# Main function
def main():
# Get the first page and parse it
result = get_first_page()
if result is not None:
parse_html_result(result)
time.sleep(2)
# Get subsequent pages and parse
for page in range(1, 4):
result = get_follow_page(page, 37)
parse_json_result(result)
time.sleep(2)
# Save as csv file
write_csv()
if __name__ == '__main__':
main()Execution results:

Finally, the extracted information is saved as a csv file. Later, you can automatically download pictures and video files through links to save them.
We can modify the program to support the input of keyword information to crawl other search information, and automatically calculate the number of pages to crawl through the total number of entries, which will not be repeated here.