Recently, I participated in the learning activity of 'Coggle data science 30 Days of ML', and recorded my notes here. The activity is completely free and feels like a good opportunity for promotion. The publicity pictures of the event are as follows:

All right, let's get to the point
Import package
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
Task01 read in data
Method 1
Train_Data = pd.read_csv("D:/competition/Heaven Pool/Used car transaction price forecast/used_car_train_20200313/used_car_train_20200313.csv")
Test_Data = pd.read_csv("D:/competition/Heaven Pool/Used car transaction price forecast/used_car_testB_20200421/used_car_testB_20200421.csv")
Train_Data.head()
| SaleID name regDate model brand bodyType fuelType gearbox power kilometer notRepairedDamage regionCode seller offerType creatDate price v_0 v_1 v_2 v_3 v_4 v_5 v_6 v_7 v_8 v_9 v_10 v_11 v_12 v_13 v_14 | |
|---|---|
| 0 | 0 736 20040402 30.0 6 1.0 0.0 0.0 60 12.5 0.0 ... |
| 1 | 1 2262 20030301 40.0 1 2.0 0.0 0.0 0 15.0 - 43... |
| 2 | 2 14874 20040403 115.0 15 1.0 0.0 0.0 163 12.5... |
| 3 | 3 71865 19960908 109.0 10 0.0 0.0 1.0 193 15.0... |
| 4 | 4 111080 20120103 110.0 5 1.0 0.0 0.0 68 5.0 0... |
Test_Data.head()
| SaleID name regDate model brand bodyType fuelType gearbox power kilometer notRepairedDamage regionCode seller offerType creatDate v_0 v_1 v_2 v_3 v_4 v_5 v_6 v_7 v_8 v_9 v_10 v_11 v_12 v_13 v_14 | |
|---|---|
| 0 | 200000 133777 20000501 67.0 0 1.0 0.0 0.0 101 ... |
| 1 | 200001 61206 19950211 19.0 6 2.0 0.0 0.0 73 6.... |
| 2 | 200002 67829 20090606 5.0 5 4.0 0.0 0.0 120 5.... |
| 3 | 200003 8892 20020601 22.0 9 1.0 0.0 0.0 58 15.... |
| 4 | 200004 76998 20030301 46.0 6 0.0 0.0 116 15.0... |
Train_Data.shape
(150000, 1)
Test_Data.shape
(50000, 1)
#Clean up the data format so that each column of data corresponds to the corresponding column name one by one
columns_name = Train_Data.columns.str.split()[0]
Train_Data = Train_Data.iloc[:,0].str.split(' ',expand=True)
Train_Data.columns = columns_name
columns_name = Test_Data.columns.str.split()[0]
Test_Data = Test_Data.iloc[:,0].str.split(' ',expand=True)
Test_Data.columns = columns_name
Train_Data.head()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 736 | 20040402 | 30.0 | 6 | 1.0 | 0.0 | 0.0 | 60 | 12.5 | ... | 0.23567590669911015 | 0.10198824077953883 | 0.129548661418789 | 0.02281636740006269 | 0.09746182870576199 | -2.8818032385553165 | 2.8040967707208506 | -2.4208207926122784 | 0.7952919433118377 | 0.9147624995703408 |
| 1 | 1 | 2262 | 20030301 | 40.0 | 1 | 2.0 | 0.0 | 0.0 | 0 | 15.0 | ... | 0.2647772555037097 | 0.12100359404116512 | 0.1357307068829055 | 0.026597448118262774 | 0.020581662632484482 | -4.9004818817666775 | 2.0963376444273414 | -1.0304828371563102 | -1.7226737753851349 | 0.2455224109670493 |
| 2 | 2 | 14874 | 20040403 | 115.0 | 15 | 1.0 | 0.0 | 0.0 | 163 | 12.5 | ... | 0.25141014780875875 | 0.11491227654046415 | 0.16514749334496415 | 0.06217283730726245 | 0.02707482416830506 | -4.846749260269903 | 1.803558941229932 | 1.5653296250457633 | -0.8326873267265079 | -0.22996285613259074 |
| 3 | 3 | 71865 | 19960908 | 109.0 | 10 | 0.0 | 0.0 | 1.0 | 193 | 15.0 | ... | 0.2742931709082824 | 0.11030008468643802 | 0.12196374573186793 | 0.033394547122199615 | 0.0 | -4.5095988235247955 | 1.2859397444845837 | -0.5018679084368517 | -2.4383527366881763 | -0.4786993792688288 |
| 4 | 4 | 111080 | 20120103 | 110.0 | 5 | 1.0 | 0.0 | 0.0 | 68 | 5.0 | ... | 0.2280356217997828 | 0.0732050535564685 | 0.09188047928262777 | 0.07881938473498606 | 0.12153424142524565 | -1.8962402786050725 | 0.9107831337379366 | 0.9311095588151709 | 2.8345178203938377 | 1.9234819632780635 |
5 rows × 31 columns
Test_Data.head()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 200000 | 133777 | 20000501 | 67.0 | 0 | 1.0 | 0.0 | 0.0 | 101 | 15.0 | ... | 0.23651953807463394 | 0.00024077965516603838 | 0.10531899027928028 | 0.04623333858358547 | 0.09452231271103513 | 3.619512125855613 | -0.2806066537539741 | -2.019761143295854 | 0.9788277260800712 | 0.8033215020878566 |
| 1 | 200001 | 61206 | 19950211 | 19.0 | 6 | 2.0 | 0.0 | 0.0 | 73 | 6.0 | ... | 0.26151841976421497 | 0.0 | 0.12032345361861815 | 0.0467842378305852 | 0.035385262671275085 | 2.9973763596922285 | -1.4067050523440334 | -1.0208835817916766 | -1.3499898633435856 | -0.20054163936348302 |
| 2 | 200002 | 67829 | 20090606 | 5.0 | 5 | 4.0 | 0.0 | 0.0 | 120 | 5.0 | ... | 0.26169061811955624 | 0.09083648656092408 | 0.0 | 0.07965532570737711 | 0.0735862207476284 | -3.951083771010004 | -0.4334673285213749 | 0.9189638428560336 | 1.6346039890078308 | 1.027172758680927 |
| 3 | 200003 | 8892 | 20020601 | 22.0 | 9 | 1.0 | 0.0 | 0.0 | 58 | 15.0 | ... | 0.2360495075063573 | 0.10177689524069478 | 0.09894989511106032 | 0.026829627502826414 | 0.09661365556957097 | -2.8467877718832733 | 2.8002670817288 | -2.5246103235495783 | 1.0768192298469703 | 0.4616102367935517 |
| 4 | 200004 | 76998 | 20030301 | 46.0 | 6 | 0.0 | 0.0 | 116 | 15.0 | ... | 0.2569995358233025 | 0.0 | 0.06673175734217886 | 0.05777117201467578 | 0.06885246978026283 | 2.839010006118193 | -1.6598006754576482 | -0.9241417494176124 | 0.19942261240833112 | 0.4510139980592859 |
5 rows × 30 columns
Method 2
Train_Data = pd.read_csv("D:/competition/Heaven Pool/Used car transaction price forecast/used_car_train_20200313/used_car_train_20200313.csv", sep=' ')
Test_Data = pd.read_csv("D:/competition/Heaven Pool/Used car transaction price forecast/used_car_testB_20200421/used_car_testB_20200421.csv",sep=' ')
Train_Data.head()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 736 | 20040402 | 30.0 | 6 | 1.0 | 0.0 | 0.0 | 60 | 12.5 | ... | 0.235676 | 0.101988 | 0.129549 | 0.022816 | 0.097462 | -2.881803 | 2.804097 | -2.420821 | 0.795292 | 0.914762 |
| 1 | 1 | 2262 | 20030301 | 40.0 | 1 | 2.0 | 0.0 | 0.0 | 0 | 15.0 | ... | 0.264777 | 0.121004 | 0.135731 | 0.026597 | 0.020582 | -4.900482 | 2.096338 | -1.030483 | -1.722674 | 0.245522 |
| 2 | 2 | 14874 | 20040403 | 115.0 | 15 | 1.0 | 0.0 | 0.0 | 163 | 12.5 | ... | 0.251410 | 0.114912 | 0.165147 | 0.062173 | 0.027075 | -4.846749 | 1.803559 | 1.565330 | -0.832687 | -0.229963 |
| 3 | 3 | 71865 | 19960908 | 109.0 | 10 | 0.0 | 0.0 | 1.0 | 193 | 15.0 | ... | 0.274293 | 0.110300 | 0.121964 | 0.033395 | 0.000000 | -4.509599 | 1.285940 | -0.501868 | -2.438353 | -0.478699 |
| 4 | 4 | 111080 | 20120103 | 110.0 | 5 | 1.0 | 0.0 | 0.0 | 68 | 5.0 | ... | 0.228036 | 0.073205 | 0.091880 | 0.078819 | 0.121534 | -1.896240 | 0.910783 | 0.931110 | 2.834518 | 1.923482 |
5 rows × 31 columns
Test_Data.head()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 200000 | 133777 | 20000501 | 67.0 | 0 | 1.0 | 0.0 | 0.0 | 101 | 15.0 | ... | 0.236520 | 0.000241 | 0.105319 | 0.046233 | 0.094522 | 3.619512 | -0.280607 | -2.019761 | 0.978828 | 0.803322 |
| 1 | 200001 | 61206 | 19950211 | 19.0 | 6 | 2.0 | 0.0 | 0.0 | 73 | 6.0 | ... | 0.261518 | 0.000000 | 0.120323 | 0.046784 | 0.035385 | 2.997376 | -1.406705 | -1.020884 | -1.349990 | -0.200542 |
| 2 | 200002 | 67829 | 20090606 | 5.0 | 5 | 4.0 | 0.0 | 0.0 | 120 | 5.0 | ... | 0.261691 | 0.090836 | 0.000000 | 0.079655 | 0.073586 | -3.951084 | -0.433467 | 0.918964 | 1.634604 | 1.027173 |
| 3 | 200003 | 8892 | 20020601 | 22.0 | 9 | 1.0 | 0.0 | 0.0 | 58 | 15.0 | ... | 0.236050 | 0.101777 | 0.098950 | 0.026830 | 0.096614 | -2.846788 | 2.800267 | -2.524610 | 1.076819 | 0.461610 |
| 4 | 200004 | 76998 | 20030301 | 46.0 | 6 | 0.0 | NaN | 0.0 | 116 | 15.0 | ... | 0.257000 | 0.000000 | 0.066732 | 0.057771 | 0.068852 | 2.839010 | -1.659801 | -0.924142 | 0.199423 | 0.451014 |
5 rows × 30 columns
Task 2 data analysis

Analyze the value, range and type of each field
Train_Data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150000 entries, 0 to 149999 Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 SaleID 150000 non-null int64 1 name 150000 non-null int64 2 regDate 150000 non-null int64 3 model 149999 non-null float64 4 brand 150000 non-null int64 5 bodyType 145494 non-null float64 6 fuelType 141320 non-null float64 7 gearbox 144019 non-null float64 8 power 150000 non-null int64 9 kilometer 150000 non-null float64 10 notRepairedDamage 150000 non-null object 11 regionCode 150000 non-null int64 12 seller 150000 non-null int64 13 offerType 150000 non-null int64 14 creatDate 150000 non-null int64 15 price 150000 non-null int64 16 v_0 150000 non-null float64 17 v_1 150000 non-null float64 18 v_2 150000 non-null float64 19 v_3 150000 non-null float64 20 v_4 150000 non-null float64 21 v_5 150000 non-null float64 22 v_6 150000 non-null float64 23 v_7 150000 non-null float64 24 v_8 150000 non-null float64 25 v_9 150000 non-null float64 26 v_10 150000 non-null float64 27 v_11 150000 non-null float64 28 v_12 150000 non-null float64 29 v_13 150000 non-null float64 30 v_14 150000 non-null float64 dtypes: float64(20), int64(10), object(1) memory usage: 35.5+ MB
Test_Data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50000 entries, 0 to 49999 Data columns (total 30 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 SaleID 50000 non-null int64 1 name 50000 non-null int64 2 regDate 50000 non-null int64 3 model 50000 non-null float64 4 brand 50000 non-null int64 5 bodyType 48496 non-null float64 6 fuelType 47076 non-null float64 7 gearbox 48032 non-null float64 8 power 50000 non-null int64 9 kilometer 50000 non-null float64 10 notRepairedDamage 50000 non-null object 11 regionCode 50000 non-null int64 12 seller 50000 non-null int64 13 offerType 50000 non-null int64 14 creatDate 50000 non-null int64 15 v_0 50000 non-null float64 16 v_1 50000 non-null float64 17 v_2 50000 non-null float64 18 v_3 50000 non-null float64 19 v_4 50000 non-null float64 20 v_5 50000 non-null float64 21 v_6 50000 non-null float64 22 v_7 50000 non-null float64 23 v_8 50000 non-null float64 24 v_9 50000 non-null float64 25 v_10 50000 non-null float64 26 v_11 50000 non-null float64 27 v_12 50000 non-null float64 28 v_13 50000 non-null float64 29 v_14 50000 non-null float64 dtypes: float64(20), int64(9), object(1) memory usage: 11.4+ MB
Train_Data.describe().iloc[:,:15]
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | regionCode | seller | offerType | creatDate | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 150000.000000 | 150000.000000 | 1.500000e+05 | 149999.000000 | 150000.000000 | 145494.000000 | 141320.000000 | 144019.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.0 | 1.500000e+05 | 150000.000000 |
| mean | 74999.500000 | 68349.172873 | 2.003417e+07 | 47.129021 | 8.052733 | 1.792369 | 0.375842 | 0.224943 | 119.316547 | 12.597160 | 2583.077267 | 0.000007 | 0.0 | 2.016033e+07 | 5923.327333 |
| std | 43301.414527 | 61103.875095 | 5.364988e+04 | 49.536040 | 7.864956 | 1.760640 | 0.548677 | 0.417546 | 177.168419 | 3.919576 | 1885.363218 | 0.002582 | 0.0 | 1.067328e+02 | 7501.998477 |
| min | 0.000000 | 0.000000 | 1.991000e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | 0.000000 | 0.000000 | 0.0 | 2.015062e+07 | 11.000000 |
| 25% | 37499.750000 | 11156.000000 | 1.999091e+07 | 10.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | 1018.000000 | 0.000000 | 0.0 | 2.016031e+07 | 1300.000000 |
| 50% | 74999.500000 | 51638.000000 | 2.003091e+07 | 30.000000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 110.000000 | 15.000000 | 2196.000000 | 0.000000 | 0.0 | 2.016032e+07 | 3250.000000 |
| 75% | 112499.250000 | 118841.250000 | 2.007111e+07 | 66.000000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | 3843.000000 | 0.000000 | 0.0 | 2.016033e+07 | 7700.000000 |
| max | 149999.000000 | 196812.000000 | 2.015121e+07 | 247.000000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 19312.000000 | 15.000000 | 8120.000000 | 1.000000 | 0.0 | 2.016041e+07 | 99999.000000 |
Train_Data.describe().iloc[:,15:]
| v_0 | v_1 | v_2 | v_3 | v_4 | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 |
| mean | 44.406268 | -0.044809 | 0.080765 | 0.078833 | 0.017875 | 0.248204 | 0.044923 | 0.124692 | 0.058144 | 0.061996 | -0.001000 | 0.009035 | 0.004813 | 0.000313 | -0.000688 |
| std | 2.457548 | 3.641893 | 2.929618 | 2.026514 | 1.193661 | 0.045804 | 0.051743 | 0.201410 | 0.029186 | 0.035692 | 3.772386 | 3.286071 | 2.517478 | 1.288988 | 1.038685 |
| min | 30.451976 | -4.295589 | -4.470671 | -7.275037 | -4.364565 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.168192 | -5.558207 | -9.639552 | -4.153899 | -6.546556 |
| 25% | 43.135799 | -3.192349 | -0.970671 | -1.462580 | -0.921191 | 0.243615 | 0.000038 | 0.062474 | 0.035334 | 0.033930 | -3.722303 | -1.951543 | -1.871846 | -1.057789 | -0.437034 |
| 50% | 44.610266 | -3.052671 | -0.382947 | 0.099722 | -0.075910 | 0.257798 | 0.000812 | 0.095866 | 0.057014 | 0.058484 | 1.624076 | -0.358053 | -0.130753 | -0.036245 | 0.141246 |
| 75% | 46.004721 | 4.000670 | 0.241335 | 1.565838 | 0.868758 | 0.265297 | 0.102009 | 0.125243 | 0.079382 | 0.087491 | 2.844357 | 1.255022 | 1.776933 | 0.942813 | 0.680378 |
| max | 52.304178 | 7.320308 | 19.035496 | 9.854702 | 6.829352 | 0.291838 | 0.151420 | 1.404936 | 0.160791 | 0.222787 | 12.357011 | 18.819042 | 13.847792 | 11.147669 | 8.658418 |
Test_Data.describe().iloc[:,:15]
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | regionCode | seller | offerType | creatDate | v_0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 5.000000e+04 | 50000.00000 | 50000.000000 | 48496.000000 | 47076.000000 | 48032.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.0 | 50000.0 | 5.000000e+04 | 50000.000000 |
| mean | 224999.500000 | 68505.606100 | 2.003401e+07 | 47.64948 | 8.087140 | 1.793736 | 0.376498 | 0.226953 | 119.766960 | 12.598260 | 2581.080680 | 0.0 | 0.0 | 2.016033e+07 | 44.400023 |
| std | 14433.901067 | 61032.124271 | 5.351615e+04 | 49.90741 | 7.899648 | 1.764970 | 0.549281 | 0.418866 | 206.313348 | 3.912519 | 1889.248559 | 0.0 | 0.0 | 1.113395e+02 | 2.459920 |
| min | 200000.000000 | 1.000000 | 1.991000e+07 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | 0.000000 | 0.0 | 0.0 | 2.014031e+07 | 31.122325 |
| 25% | 212499.750000 | 11315.000000 | 1.999100e+07 | 11.00000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | 1006.000000 | 0.0 | 0.0 | 2.016031e+07 | 43.120935 |
| 50% | 224999.500000 | 52215.000000 | 2.003091e+07 | 30.00000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 110.000000 | 15.000000 | 2204.500000 | 0.0 | 0.0 | 2.016032e+07 | 44.601493 |
| 75% | 237499.250000 | 118710.750000 | 2.007110e+07 | 66.00000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | 3842.000000 | 0.0 | 0.0 | 2.016033e+07 | 45.987018 |
| max | 249999.000000 | 196808.000000 | 2.015121e+07 | 246.00000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 19211.000000 | 15.000000 | 8120.000000 | 0.0 | 0.0 | 2.016041e+07 | 51.676686 |
Test_Data.describe().iloc[:,15:]
| v_1 | v_2 | v_3 | v_4 | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 |
| mean | -0.065525 | 0.079706 | 0.078381 | 0.022361 | 0.248147 | 0.044624 | 0.124693 | 0.058198 | 0.062113 | 0.019633 | 0.002759 | 0.004342 | 0.004570 | -0.007209 |
| std | 3.636631 | 2.930829 | 2.019136 | 1.194215 | 0.045836 | 0.051664 | 0.201440 | 0.029171 | 0.035723 | 3.764095 | 3.289523 | 2.515912 | 1.287194 | 1.044718 |
| min | -4.231855 | -4.032142 | -5.801254 | -4.233626 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.119719 | -5.662163 | -8.291868 | -4.157649 | -6.098192 |
| 25% | -3.193169 | -0.967832 | -1.456793 | -0.922153 | 0.243436 | 0.000035 | 0.062519 | 0.035413 | 0.033880 | -3.675196 | -1.963928 | -1.865406 | -1.048722 | -0.440706 |
| 50% | -3.053506 | -0.384910 | 0.118448 | -0.068187 | 0.257818 | 0.000801 | 0.095880 | 0.056804 | 0.058749 | 1.632134 | -0.375537 | -0.138943 | -0.036352 | 0.136849 |
| 75% | 3.978703 | 0.239689 | 1.563490 | 0.871565 | 0.265263 | 0.101654 | 0.125470 | 0.079387 | 0.087624 | 2.846205 | 1.263451 | 1.775632 | 0.945239 | 0.685555 |
| max | 7.190759 | 18.865988 | 9.386558 | 4.959106 | 0.291176 | 0.153403 | 1.411559 | 0.157458 | 0.211304 | 12.177864 | 18.789496 | 13.384828 | 5.635374 | 2.649768 |
It can be found that except that notrepairedamage is of object type, others are numbers. Here we can show several different values
Train_Data['notRepairedDamage'].value_counts()
0.0 111361 - 24324 1.0 14315 Name: notRepairedDamage, dtype: int64
Train_Data['notRepairedDamage'].replace('-',np.nan,inplace=True)
Test_Data['notRepairedDamage'].value_counts()
0.0 37224 - 8069 1.0 4707 Name: notRepairedDamage, dtype: int64
Test_Data['notRepairedDamage'].replace('-',np.nan,inplace=True)
View missing values
missing = Train_Data.isnull().sum() missing = missing[missing>0] missing.sort_values(inplace=True) missing.plot.bar()
<AxesSubplot:>

missing = Test_Data.isnull().sum() missing = missing[missing>0] missing.sort_values(inplace=True) missing.plot.bar()
<AxesSubplot:>

Delete highly unevenly distributed columns
del Train_Data["seller"] del Train_Data["offerType"] del Test_Data["seller"] del Test_Data["offerType"]
Observe the skewness and kurtosis of the data
sns.distplot(Train_Data.skew(),color='blue',axlabel ='Skewness')

sns.distplot(Test_Data.skew(),color='blue',axlabel ='Skewness')

sns.distplot(Train_Data.kurt(),color='orange',axlabel ='Kurtness')

sns.distplot(Test_Data.kurt(),color='orange',axlabel ='Kurtness')

It is found that there are large values of skewness and kurtosis
See the specific frequency of the predicted value
plt.hist(Train_Data['price'], orientation = 'vertical',histtype = 'bar', color ='red') plt.show()
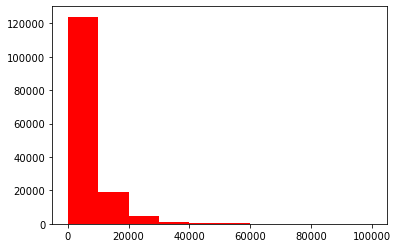
The viewing frequency is very few values greater than 20000. In fact, these can also be regarded as special values (outliers) and directly filled in or deleted, and then carried out in the front
The distribution z after log transformation is more uniform, so log transformation can be used for prediction, which is also a commonly used trick in prediction problems
plt.hist(np.log(Train_Data['price']), orientation = 'vertical',histtype = 'bar', color ='red') plt.show()

Features are divided into category features and digital features
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ] categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
Category characteristics
Characteristic nunique distribution
for cat_fea in categorical_features:
print(cat_fea + "The characteristic distribution of is as follows:")
print("{}The feature has a{}Different values".format(cat_fea, Train_Data[cat_fea].nunique()))
print(Train_Data[cat_fea].value_counts())
name The characteristic distribution of is as follows:
name The feature has a 99662 different value
708 282
387 282
55 280
1541 263
203 233
...
119983 1
63443 1
104410 1
154956 1
177672 1
Name: name, Length: 99662, dtype: int64
model The characteristic distribution of is as follows:
model The feature has 248 different values
0.0 11762
19.0 9573
4.0 8445
1.0 6038
29.0 5186
...
240.0 2
209.0 2
245.0 2
242.0 2
247.0 1
Name: model, Length: 248, dtype: int64
brand The characteristic distribution of is as follows:
brand The feature has 40 different values
0 31480
4 16737
14 16089
10 14249
1 13794
6 10217
9 7306
5 4665
13 3817
11 2945
3 2461
7 2361
16 2223
8 2077
25 2064
27 2053
21 1547
15 1458
19 1388
20 1236
12 1109
22 1085
26 966
30 940
17 913
24 772
28 649
32 592
29 406
37 333
2 321
31 318
18 316
36 228
34 227
33 218
23 186
35 180
38 65
39 9
Name: brand, dtype: int64
bodyType The characteristic distribution of is as follows:
bodyType The feature has 8 different values
0.0 41420
1.0 35272
2.0 30324
3.0 13491
4.0 9609
5.0 7607
6.0 6482
7.0 1289
Name: bodyType, dtype: int64
fuelType The characteristic distribution of is as follows:
fuelType The feature has 7 different values
0.0 91656
1.0 46991
2.0 2212
3.0 262
4.0 118
5.0 45
6.0 36
Name: fuelType, dtype: int64
gearbox The characteristic distribution of is as follows:
gearbox The feature has 2 different values
0.0 111623
1.0 32396
Name: gearbox, dtype: int64
notRepairedDamage The characteristic distribution of is as follows:
notRepairedDamage The feature has 3 different values
0.0 111361
- 24324
1.0 14315
Name: notRepairedDamage, dtype: int64
regionCode The characteristic distribution of is as follows:
regionCode The characteristic has a 7905 different value
419 369
764 258
125 137
176 136
462 134
...
6377 1
7994 1
7973 1
7975 1
8117 1
Name: regionCode, Length: 7905, dtype: int64
visualization
def count_plot(x, **kwargs):
sns.countplot(x=x)
x=plt.xticks(rotation=90)
f = pd.melt(Train_Data, value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(count_plot, "value")
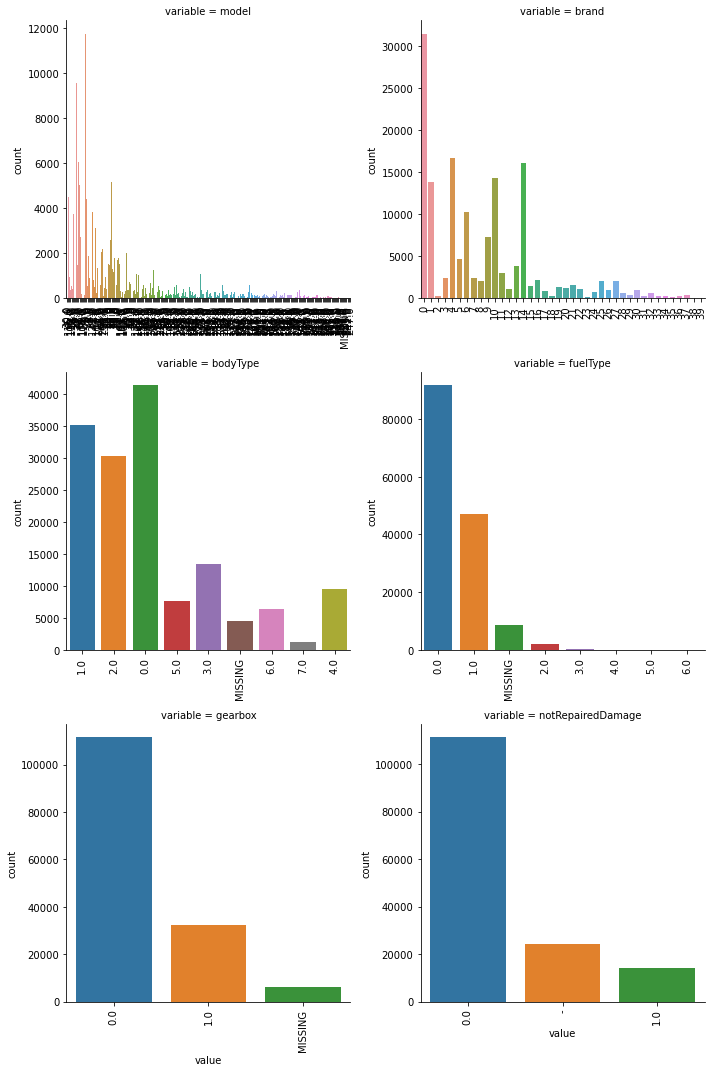
for cat_fea in categorical_features:
print(cat_fea + "The characteristic distribution of is as follows:")
print("{}The feature has a{}Different values".format(cat_fea, Test_Data[cat_fea].nunique()))
print(Test_Data[cat_fea].value_counts())
name The characteristic distribution of is as follows:
name The feature has a 37536 different value
387 94
55 93
1541 86
708 85
203 78
..
69206 1
125326 1
82297 1
168470 1
78202 1
Name: name, Length: 37536, dtype: int64
model The characteristic distribution of is as follows:
model The feature has 245 different values
0.0 3772
19.0 3226
4.0 2790
1.0 1981
29.0 1778
...
209.0 2
229.0 2
241.0 1
242.0 1
244.0 1
Name: model, Length: 245, dtype: int64
brand The characteristic distribution of is as follows:
brand The feature has 40 different values
0 10473
4 5532
14 5345
10 4713
1 4627
6 3500
9 2360
5 1485
13 1386
11 942
3 820
16 770
25 728
7 727
8 708
27 623
21 543
15 476
19 473
20 411
12 399
22 358
26 328
30 321
17 312
24 248
28 216
32 183
29 139
37 117
2 115
31 113
18 107
33 84
35 75
34 75
36 72
23 60
38 31
39 5
Name: brand, dtype: int64
bodyType The characteristic distribution of is as follows:
bodyType The feature has 8 different values
0.0 13765
1.0 11960
2.0 9886
3.0 4491
4.0 3258
5.0 2494
6.0 2212
7.0 430
Name: bodyType, dtype: int64
fuelType The characteristic distribution of is as follows:
fuelType The feature has 7 different values
0.0 30489
1.0 15708
2.0 736
3.0 78
4.0 31
5.0 18
6.0 16
Name: fuelType, dtype: int64
gearbox The characteristic distribution of is as follows:
gearbox The feature has 2 different values
0.0 37131
1.0 10901
Name: gearbox, dtype: int64
notRepairedDamage The characteristic distribution of is as follows:
notRepairedDamage The feature has 2 different values
0.0 37224
1.0 4707
Name: notRepairedDamage, dtype: int64
regionCode The characteristic distribution of is as follows:
regionCode The feature has a 6998 different value
419 120
764 98
176 48
85 45
3304 45
...
5365 1
6353 1
7077 1
1317 1
2214 1
Name: regionCode, Length: 6998, dtype: int64
def count_plot(x, **kwargs):
sns.countplot(x=x)
x=plt.xticks(rotation=90)
f = pd.melt(Test_Data, value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(count_plot, "value")

- Category feature box diagram visualization
pd.melt(Train_Data, id_vars=['price'], value_vars=categorical_features)
| price | variable | value | |
|---|---|---|---|
| 0 | 1850 | name | 736 |
| 1 | 3600 | name | 2262 |
| 2 | 6222 | name | 14874 |
| 3 | 2400 | name | 71865 |
| 4 | 5200 | name | 111080 |
| ... | ... | ... | ... |
| 1199995 | 5900 | regionCode | 4576 |
| 1199996 | 9500 | regionCode | 2826 |
| 1199997 | 7500 | regionCode | 3302 |
| 1199998 | 4999 | regionCode | 1877 |
| 1199999 | 4700 | regionCode | 235 |
1200000 rows × 3 columns
# Because the categories of name and regionCode are too sparse, let's draw some non sparse categories here
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
for c in categorical_features:
Train_Data[c] = Train_Data[c].astype('category')
if Train_Data[c].isnull().any():
Train_Data[c] = Train_Data[c].cat.add_categories(['MISSING'])
Train_Data[c] = Train_Data[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_Data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "price")

- Violin graph visualization of category features
## 3) Violin graph visualization of category features
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_Data)
plt.show()






- Column chart visualization of category features
Digital features
- Correlation (view the correlation of individual variables and predictive variables)
numeric_features.append("price")
price_numeric = Train_Data[numeric_features]
correlation = price_numeric.corr()
print(correlation['price'].sort_values(ascending = False),'\n')
price 1.000000 v_12 0.692823 v_8 0.685798 v_0 0.628397 power 0.219834 v_5 0.164317 v_2 0.085322 v_6 0.068970 v_1 0.060914 v_14 0.035911 v_13 -0.013993 v_7 -0.053024 v_4 -0.147085 v_9 -0.206205 v_10 -0.246175 v_11 -0.275320 kilometer -0.440519 v_3 -0.730946 Name: price, dtype: float64
(view the correlation between variables)
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)

del price_numeric['price']
- Look at the skewness and peaks of several features
Variables with large skewness and kurtosis can be found
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Train_Data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Train_Data[col].kurt())
)
power Skewness: 65.86 Kurtosis: 5733.45 kilometer Skewness: -1.53 Kurtosis: 001.14 v_0 Skewness: -1.32 Kurtosis: 003.99 v_1 Skewness: 00.36 Kurtosis: -01.75 v_2 Skewness: 04.84 Kurtosis: 023.86 v_3 Skewness: 00.11 Kurtosis: -00.42 v_4 Skewness: 00.37 Kurtosis: -00.20 v_5 Skewness: -4.74 Kurtosis: 022.93 v_6 Skewness: 00.37 Kurtosis: -01.74 v_7 Skewness: 05.13 Kurtosis: 025.85 v_8 Skewness: 00.20 Kurtosis: -00.64 v_9 Skewness: 00.42 Kurtosis: -00.32 v_10 Skewness: 00.03 Kurtosis: -00.58 v_11 Skewness: 03.03 Kurtosis: 012.57 v_12 Skewness: 00.37 Kurtosis: 000.27 v_13 Skewness: 00.27 Kurtosis: -00.44 v_14 Skewness: -1.19 Kurtosis: 002.39 price Skewness: 03.35 Kurtosis: 019.00
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Test_Data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Test_Data[col].kurt())
)
power Skewness: 60.02 Kurtosis: 4533.77 kilometer Skewness: -1.52 Kurtosis: 001.13 v_0 Skewness: -1.31 Kurtosis: 003.98 v_1 Skewness: 00.37 Kurtosis: -01.74 v_2 Skewness: 04.84 Kurtosis: 023.85 v_3 Skewness: 00.09 Kurtosis: -00.44 v_4 Skewness: 00.38 Kurtosis: -00.22 v_5 Skewness: -4.73 Kurtosis: 022.87 v_6 Skewness: 00.38 Kurtosis: -01.73 v_7 Skewness: 05.13 Kurtosis: 025.83 v_8 Skewness: 00.22 Kurtosis: -00.62 v_9 Skewness: 00.42 Kurtosis: -00.33 v_10 Skewness: 00.02 Kurtosis: -00.56 v_11 Skewness: 03.02 Kurtosis: 012.48 v_12 Skewness: 00.38 Kurtosis: 000.32 v_13 Skewness: 00.26 Kurtosis: -00.49 v_14 Skewness: -1.21 Kurtosis: 002.40
- Visualization of the distribution of each digital feature
a) Observe for abnormal distribution
b) Observe whether there are variables with different distribution between train and test
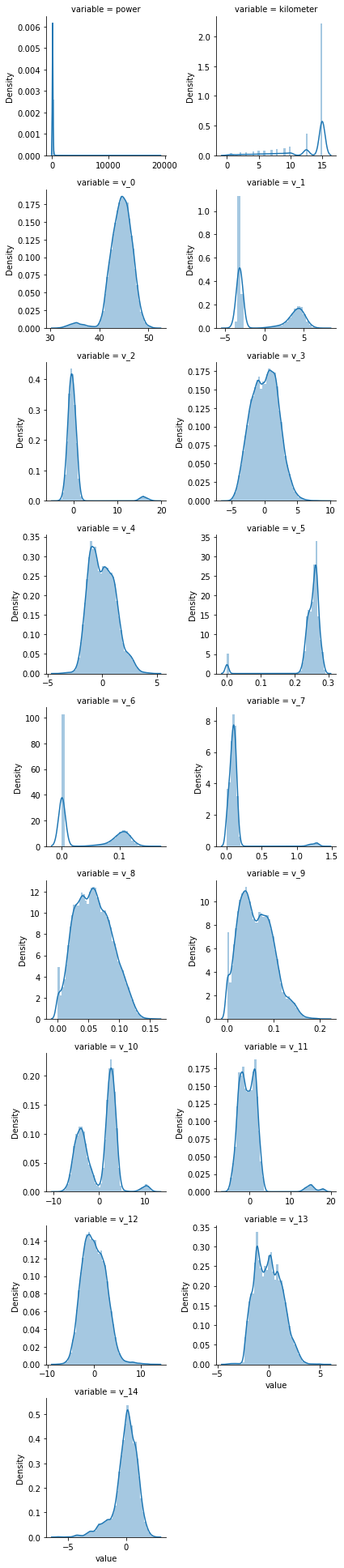
f = pd.melt(Train_Data, value_vars=numeric_features) g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False) g = g.map(sns.distplot, "value")
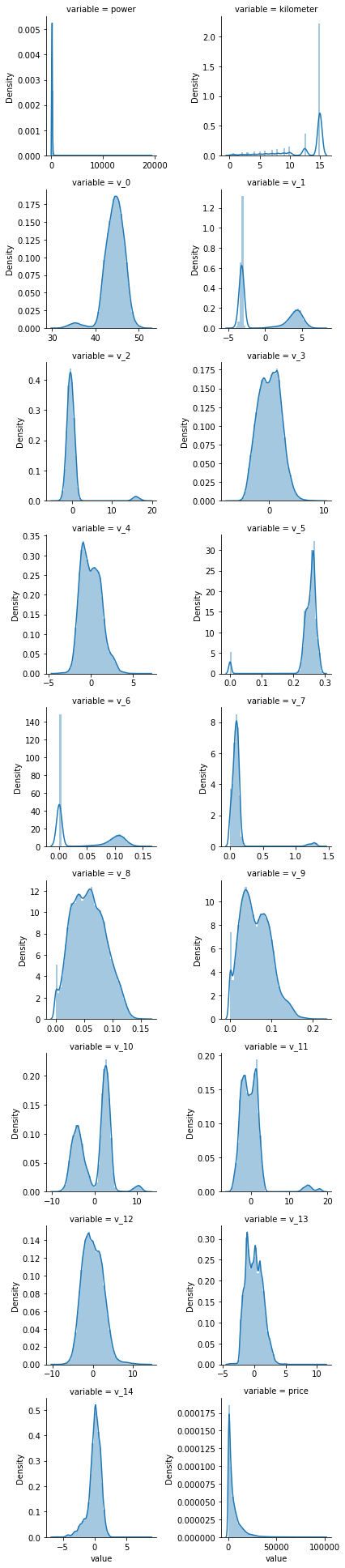
numeric_features.remove("price")
f = pd.melt(Test_Data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")