I Environmental Science:
1.Ubuntu20
2.Hadoop3.1.4
3.Jdk1.8_301
II Specific steps
- Pull the latest version of ubuntu image
- Use mount to transfer jdk,hadoop and other installation packages to the mount directory through xftp or using the command line scp command.
- Enter the ubuntu image container docker exec -it container id /bin/bash
- Update apt get system source
- After the update, you can download some necessary tools, such as vim
- Install sshd
When starting distributed Hadoop, you need to use ssh to connect the slave node apt get install ssh
Then run the following script to start the sshd server: / etc / init d/ssh start
In this way, when opening the image, you need to manually start the sshd service. You can write this command into ~ / bashrc file. After saving, the sshd service will be automatically started every time you enter the container (this sentence must be put at the end, or an exception will be started later!) - Configure password free login (I tried it here. It will be easier to enter the password using ssh localhost in the container
Login denied) Cd ~ / ssh
SSH keygen - t RSA press enter all the way
Finally, enter cat/ id_ rsa. pub >> ./ authorized_ keys
Next, you can directly enter ssh localhost to log in to the machine - Configure jdk, which is the same as the previous stand-alone configuration.
- Install hadoop and unzip hadoop to the directory specified by yourself
- Configure hadoop cluster
(1) Open hadoop_env.sh, modify JAVA_HOME
(2) Open core site XML, input
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
(3) Open HDFS site XML input
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/namenode_dir</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/datanode_dir</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
(4) Open mapred site XML input
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name>//The path here is the path where you install hadoop <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> </configuration>
(5) Open yarn site XML input
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration>
After configuration, the basic environment of hadoop cluster has been configured! Save the modified image
docker commit save image enter docker images to view the saved image.

3, Configure cluster:
I use one node as the master and three nodes as the slave. namenode is the same as secondnamenode
Node.
1. Open four terminals respectively, and each terminal interface runs the image just modified. Represents Hadoop respectively
Master in cluster, S01, s02 and s03
docker run -it -h Master --name Master...

2. Enter cat /etc/hosts to view the ip of the current container. For example, the master IP is 172.17.0.3
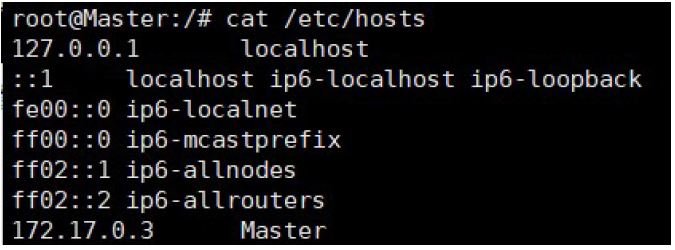
3. Edit the hosts of four containers and save each host and ip

4. Input ssh s01, etc. in the master host to test whether the master can connect to the slave normally (it is recommended to use all of them here)
(enter yes or give a warning when starting hadoop later)
5. At this point, the last configuration is needed to complete the hadoop cluster configuration. Open the on the master
workers file (under etc/hadoop in hadoop installation directory), hadoop version 2 file
It is called slave s. Delete the original default value localhost and enter the host names of the three slaves: s03
s02,s03.

4, Start cluster
Enter start-all at the master terminal SH start the cluster (the first time you start, you must format the namenode, and then you don't need format)
Format namenode

Start cluster
Starting the cluster directly here may report an error

In Hadoop env SH add the following
export HDFS NAMENODE USER=root export HDFS DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN NODEMANAGER USER=root
After adding: start the cluster again

Enter jps in the master node

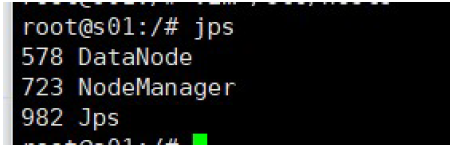
Enter jps in the slave node
An example of running the word frequency statistics provided by hadoop
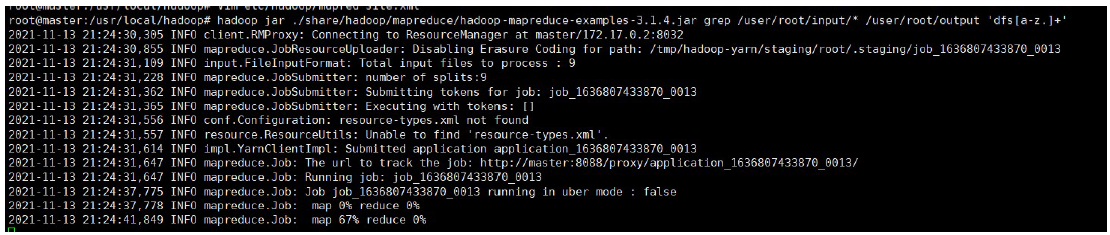
View results

So far, the docker based hadoop cluster has been successfully built.