Original address: http://blog.csdn.net/Dreamcode/article/details/50401858
Full article download address: http://download.csdn.net/detail/dreamcode/9383516
Simply put, we can understand the horizontal segmentation of data as the segmentation of data rows, that is to say, some rows in the table are divided into one database, while some other rows are divided into other databases. It is very important to select appropriate segmentation rules, because it determines the difficulty of subsequent data aggregation.
Several typical fragmentation rules include:
(1) According to the user's primary key ID, the data is dispersed into different databases, and the data of the same data user is dispersed into one database.
(2) According to the date, the data of different months or even days are dispersed into different libraries.
(3) According to a specific field, or according to a specific range of segments scattered into different libraries.
I. Fragmentation rules commonly used in MYCAT
The commonly used fragmentation rules of MYCAT are as follows. There are also some other fragmentation methods which are not listed here.
(1) Piecewise enumeration: sharding-by-intfile
(2) Primary key range: auto-sharding-long
(3) Consistency hash: sharding-by-murmur
(4) String hash parsing: sharding-by-stringhash
(5) By date: sharding-by-date
(6) split by one-month hour: sharding-by-hour
(6) Natural monthly fragmentation: sharding-by-month
2. MYCAT Piecewise Configuration Instructions
Following is an example of fragmentation using fragmentation enumeration rules and primary key range rules:
1. Sharding-by-int file
(1) Rules of Use: / src/main/resources/schema.xml
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
- 1
- 2
- 3
(2) Defining rules: / src/main/resources/rule.xml
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(3) Rule file: / src/main/resources/autopartition-long.txt
10000=0 10010=1
- 1
- 2
- 3
2. Primary Key Range Rule (auto-sharding-long)
(1) Rules of Use: / src/main/resources/schema.xml
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
- 1
- 2
- 3
- 4
(2) Defining rules: / src/main/resources/rule.xml
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(3) Rule file: / src/main/resources/autopartition-long.txt
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
- 1
- 2
- 3
- 4
- 5
- 6
3. MYCAT Piecewise Testing
Following is an example of fragmentation using fragmentation enumeration rules and primary key range rules:
1. Sharding-by-int file
(1) Insert two sharding_id=10000 data into the dn1 node.
1) statement 1: explain insert into employee(id,name,sharding_id) values(1,'test1', 10000);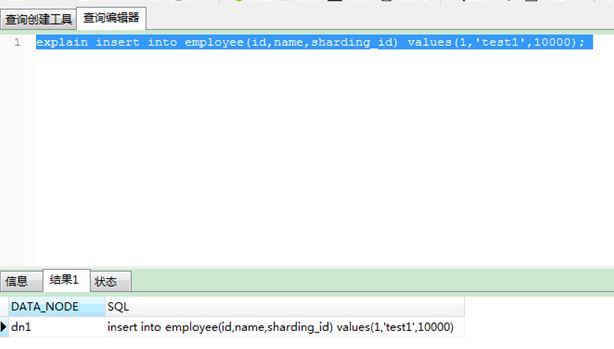
2) statement 2: explain insert into employee(id,name,sharding_id) values(1,'test 2', 10000);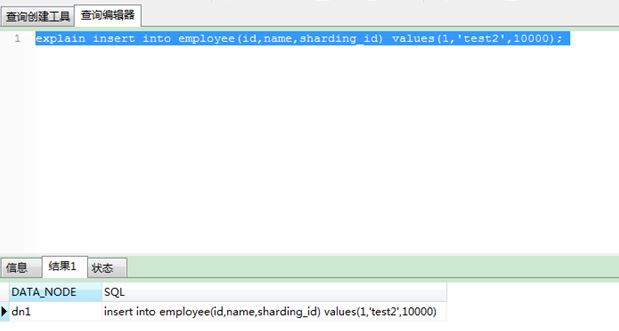
(2) Insert two IDs of data ranging from 500M to 1000M, and the data is inserted into the dn2 node.
1) statement 1: explain insert into travelrecord (id,user_id,traveldate,fee,days) values(5000001,'zhao','2015-12-10', 510.5,3);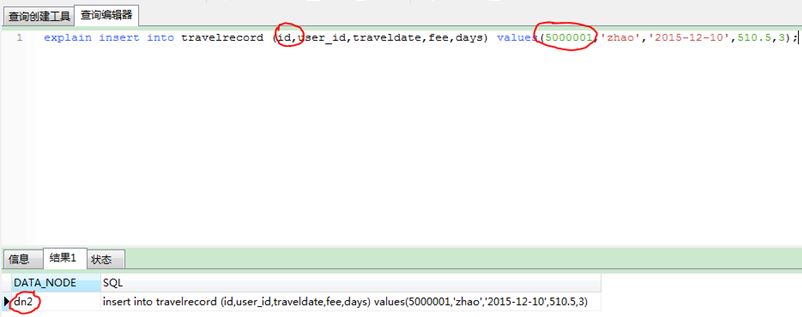
2) statement 2: explain insert into travelrecord (id,user_id,traveldate,fee,days) values(6000001,'zhao','2015-12-10', 510.5,3);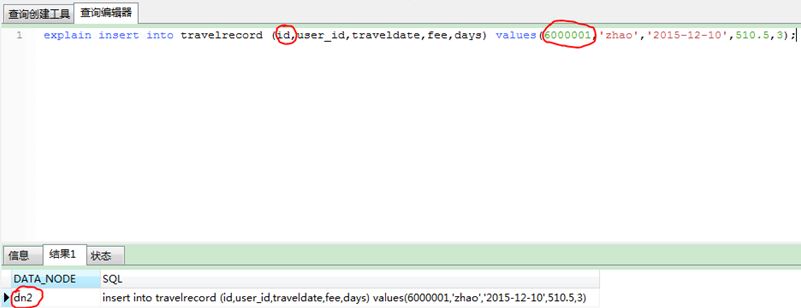
4. Piecewise Global Sequence Number (Database Mode)
Since MySQL's self-increasing primary key can't be used after sublibrary, we can put the SEQUENCE generating functional stored procedure into a database fragment, and query the current SEQUENCE before inserting the data, and then perform the operation.
1. Configure server.xml:
sequnceHandlerType is configured as 1 to represent the use of database libraries to generate sequence s
<system><property name="sequnceHandlerType">1</property></system>- 1
2. Create MYCAT_SEQUENCE table
DROP TABLE
IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR (50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY (NAME)
) ENGINE = INNODB;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Create function
(1) Create mycat_seq_currval to get the current sequence value
DROP FUNCTION
IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE DEFINER = `root`@`%` FUNCTION `mycat_seq_currval` (seq_name VARCHAR(50)) RETURNS VARCHAR (64) CHARSET latin1 DETERMINISTIC
BEGIN
DECLARE retval VARCHAR (64) ;
SET retval = "-999999999,null" ; SELECT
concat(
CAST(current_value AS CHAR),
",",
CAST(increment AS CHAR)
) INTO retval
FROM
MYCAT_SEQUENCE
WHERE
NAME = seq_name ; RETURN retval ;
END
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2) Create mycat_seq_currval to get the next sequence value
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE DEFINER = `root`@`%` FUNCTION `mycat_seq_nextval` (seq_name VARCHAR(50)) RETURNS VARCHAR (64) CHARSET latin1 DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE
NAME = seq_name ; RETURN mycat_seq_currval (seq_name) ;
END;;
DELIMITER ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(3) Create mycat_seq_currval and set sequence value
DROP FUNCTION
IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE DEFINER = `root`@`%` FUNCTION `mycat_seq_setval` (
seq_name VARCHAR (50),
VALUE
INTEGER
) RETURNS VARCHAR (64) CHARSET latin1 DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value =
VALUE
WHERE
NAME = seq_name ; RETURN mycat_seq_currval (seq_name) ;
END;;
DELIMITER ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
(4) Increase authority, otherwise it cannot be executed
mysql > GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY ".";
QUERY OK,
0 rows affected (0.00 sec) mysql > FLUSH PRIVILEGES;
QUERY OK,
0 rows affected (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(5) Insert the initial value and test the function
INSERT INTO MYCAT_SEQUENCE VALUES ('article_seq', 1, 1);- 1
Perform the following query tests:
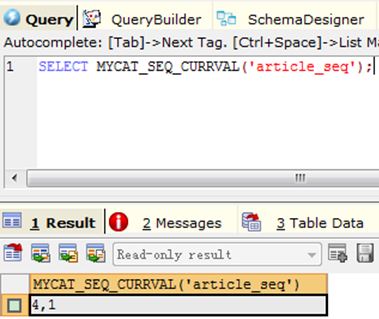
1) Query 1: SELECT MYCAT_SEQ_CURRVAL('article_seq');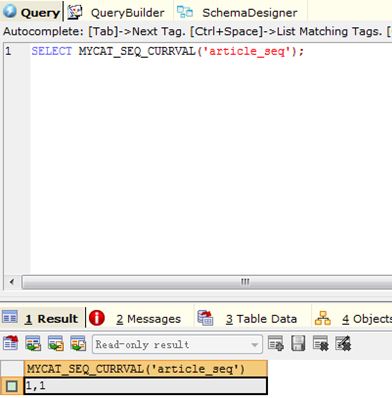
2) Query 2: SELECT MYCAT_SEQ_SETVAL('article_seq', 2);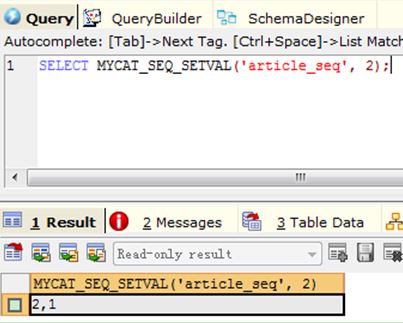
3) Query 3: SELECT MYCAT_SEQ_CURRVAL('article_seq');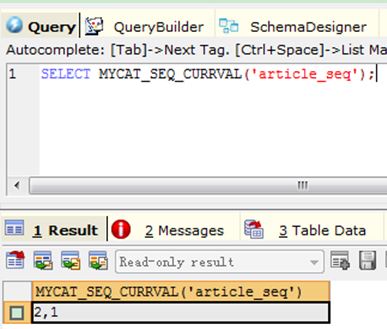
4) Query 4: SELECT MYCAT_SEQ_NEXTVAL('article_seq');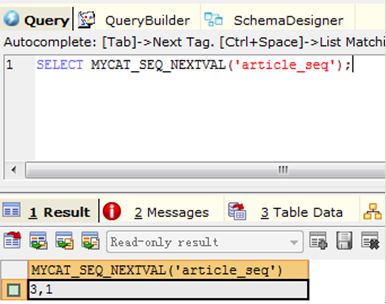
5) Query 5: SELECT MYCAT_SEQ_NEXTVAL('article_seq');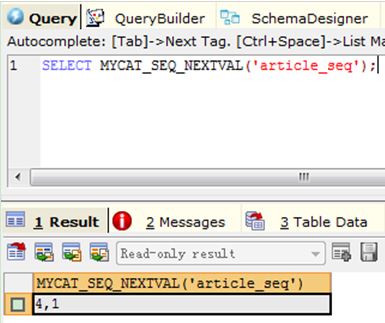
6) Query 6: SELECT MYCAT_SEQ_CURRVAL('article_seq');