Using NatureDQN to play and make bricks
target
Playing brick is a relatively complex game in gym game. Unlike CartPole game, there is less state space. Basically, you can play the highest score in about 10 minutes. Playing brick takes a very long time, so it is very helpful to further understand and optimize DQN.
Try the first edition
The foundation of building bricks
The reward setting for hitting bricks is to hit bricks: reward = 1
Five missed shots or all the bricks done = 1
state is all the pixels in the game
Preprocessing
Image preprocessing
First, the image can be converted to a single channel, and the pixel only needs the specific part of the game area, and the resolution can be reduced, so the preprocessing is as follows:
def preprocess(img): img_temp = img[31:195] img_temp = img_temp.mean(axis = 2) img_temp = cv2.resize(img_temp,(IMG_SIZE,IMG_SIZE)) img_temp = (img_temp - 127.5) / 127.5 return img_temp
State preprocessing
It's difficult to describe the direction of the ball movement in a single picture. In order to better show the state of the game, we need to have several consecutive pictures. Here I take four consecutive pictures.
Network design
The code is posted here. First, use the three-layer convolution network to reduce the dimension
def create_Q_network(self): # network weights input_layer = Input(shape=(IMG_SIZE,IMG_SIZE,4), name="unet_input") #converlution cnn1 = Convolution2D(nb_filter=32, nb_row=8, nb_col=8, border_mode='same', subsample=(4, 4))(input_layer) cnn1 = ReLU()(cnn1) cnn2 = Convolution2D(nb_filter=64, nb_row=4, nb_col=4, border_mode='same', subsample=(2, 2))(cnn1) cnn2 = ReLU()(cnn2) cnn2 = Convolution2D(nb_filter=64, nb_row=3, nb_col=3, border_mode='same', subsample=(1, 1))(cnn1) cnn2 = ReLU()(cnn2) #full connect fc0 = Flatten()(cnn2) fc1 = Dense(512)(fc0) #get Q_value q_value= Dense(self.action_dim)(fc1) self.model = Model(input=[input_layer], output=[q_value], name='Q_net') self.model.compile(loss='mse',optimizer=Adam(lr=self.learning_rate))
Second version attempt
Because the first version reads the whole picture and needs four consecutive frames, it takes a lot of time in the picture processing process. In fact, the information obtained is only related to the coordinates of the ball and the position of the board, and only two frames are needed to express the required state. Therefore, I improved the state variable, which uses four dimensions.
def preprocess(img): img_temp = img.mean(axis = 2) # img_temp = cv2.resize(img_temp,(IMG_SIZE,IMG_SIZE)) x = -1 y = -1 flag = 0 if len(np.where((img_temp[100:189,8:152])!= 0)[0]) != 0: x = np.where((img_temp[100:189,8:152])!= 0)[0][0] y = np.where((img_temp[100:189,8:152])!= 0)[1][0] if len(np.where((img_temp[193:,8:152])!= 0)[0]) != 0: x = np.where((img_temp[193:,8:152])!= 0)[0][0] + 93 y = np.where((img_temp[193:,8:152])!= 0)[1][0] flag = 1 # x = -2 # y = -2 p = int(np.where(img_temp[191:193,8:152])[1].mean() - 7.5) #return img_temp return (x,y,p,flag)
for step in range(STEP): print("episode:%d step:%d" % (episode,step)) action = agent.egreedy_action(state_shadow) next_state,reward,done,_ = env.step(action) (x2,y2,p2,flag) = preprocess(next_state) next_state_shadow = np.array([x1,y1,x2,y2,p2]) # Define reward for agent #reward_agent = -1 if done else 0.1 #Increase the penalty of falling if flag == 1: reward = -10 done = True else: reward = 0.1 agent.perceive(state_shadow,action,reward,next_state_shadow,done) # if cur_loss is not None: # total_loss += cur_loss total_reward += reward state_shadow = next_state_shadow x1,y1,p1 = x2,y2,p2 if done: break
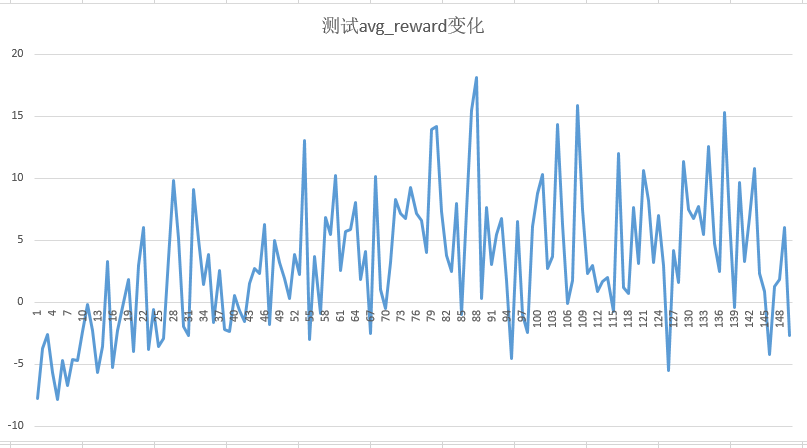
The effect of the 14000 epiride iteration is as follows:
The tested Reward has an overall upward trend, but:
- Too obvious fluctuation on the test set
- The overall reward fails to meet the expectation (the better effect is that the step I set meets more than 20, that is, the basic ball can't be dropped)
Third version attempt
The weight of training samples is changed by introducing prioritised.
Code directory:
https://github.com/hlzy/operator_dnn

