Hello, I'm Charlie
Today we share a gadget, which is mainly used for downloading videos from station B. you can download them locally by entering the web address of the corresponding video.
catalog:
- Principle introduction
- Web page analysis
- Video crawling
- Deposit locally
- GUI tool making
- Complete code
1. Principle introduction
The principle is very simple, that is to obtain the source address of video resources, then crawl the binary content of video, and then write it to the local.
2. Web page analysis
Open the web page, then F12 to enter the developer mode, and then click the network - > all. Because the video resources are generally large, I sorted them from large to small according to the size, and found the first one, which may be related to the video source address.
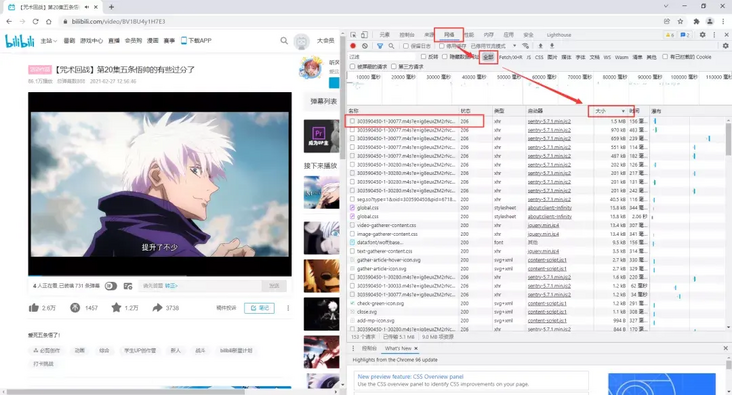
Then, we copy the unchanged part of the url in the found one, go back to the element and search with ctrl+F to find the node that may be related to the video source address.
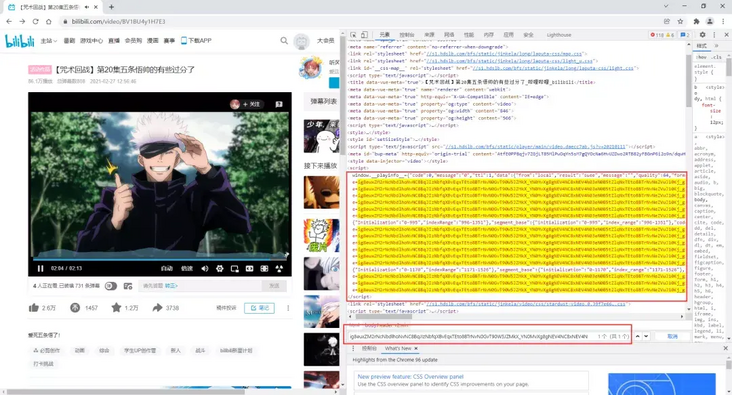
Sure enough, we copied this part of the content and found that there was really the address of the seemingly video file we needed with the json online parsing tool.
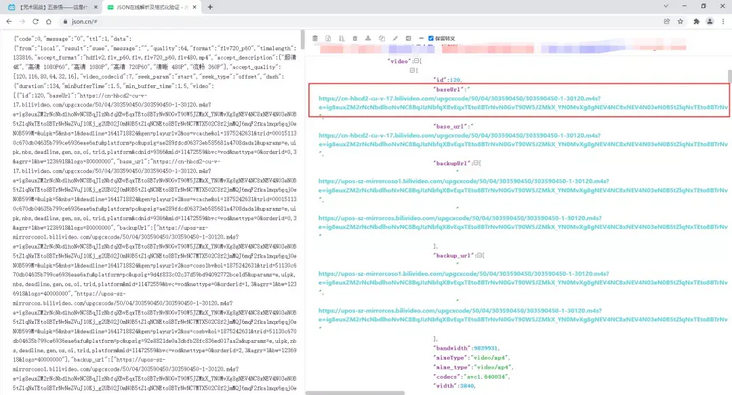
Then, I copied the address and opened it with a browser and found prompt 403..
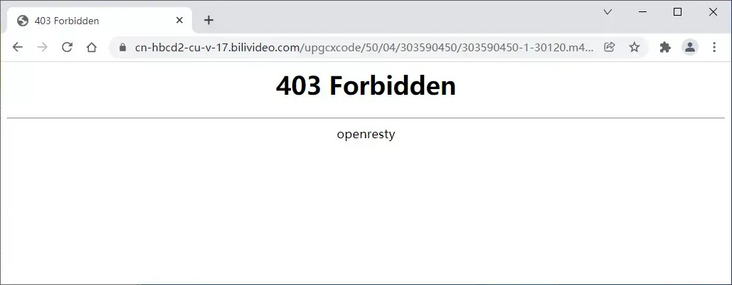
But it doesn't matter.. Let's see the next operation!
3. Video crawling
In the web page analysis part, we can obtain the source address of the video file through various data analysis methods in the web page source code of the address of station B of the video. Here I use regular expressions.
import requests
import re
import json
url = 'https://www.bilibili.com/video/BV1BU4y1H7E3'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
"referer": "https://www.bilibili.com"
}
resp = requests.get(url, headers=headers)
palyinfo = re.findall(r'<script>window.__playinfo__=(.*?)</script>', resp.text)[0]
palyinfo_data = json.loads(palyinfo)Since the result of the expression being obtained is a string, but it is actually a json (Dictionary), it is necessary to introduce the json library for conversion.
After analyzing the data, we can find the information of the final video file and directly operate the key value. Interestingly, video and audio files are separated. We need to crawl them separately and then merge them.
#Video and audio file addresses video_url = json_data['data']['dash']['video'][0]['base_url'] audio_url = json_data['data']['dash']['audio'][0]['base_url']
A friend may find out, base_ There seem to be many URLs. Yes, because there are many kinds of video definition. Here I choose the first ultraclear 4K, you can choose according to your own needs!
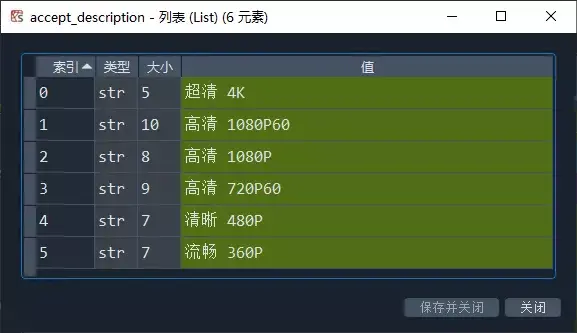
Of course, when we save the video locally, we also need to name it. Here, just find a node to parse the file name.
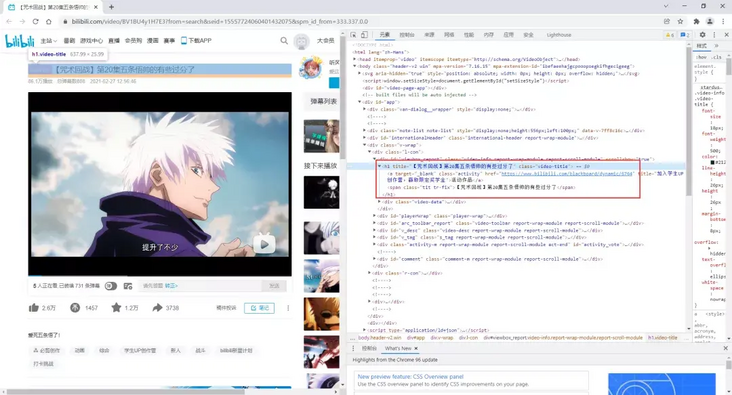
#Video title title = re.findall(r'<h1 title="(.*?)" class="video-title">', resp.text)[0]
4. Deposit locally
Now that we have obtained the file address, audio address and file name of the video, we can arrange the download directly!
However, when we analyze the web page, we find that when we directly open the video and audio file address, we will prompt 403. Therefore, due to the unclear source of the jump, we only need to adjust the request header as follows:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
#Just add a referer
"referer": "https://www.bilibili.com"
}After these things are done, let's start writing files and local functions!
#General video is mp4 and audio is mp3
def down_file(file_url, file_type):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
"referer": "https://www.bilibili.com"
}
resp = requests.get(url = file_url, headers=headers)
print(resp.status_code)
print(f'File name:{title}')
#Sets the block size for a single write of data
chunk_size = 1024
#Get file size
file_size = int(resp.headers['content-length'])
#Used to record the file size that has been downloaded
done_size = 0
#Convert file size to MB
file_size_MB = file_size / 1024 / 1024
print(f'File size:{file_size_MB:0.2f} MB')
start_time = time.time()
with open(title + '.' + file_type, mode='wb') as f:
for chunk in resp.iter_content(chunk_size=chunk_size):
f.write(chunk)
done_size += len(chunk)
print(f'\r Download progress:{done_size/file_size*100:0.2f}%',end='')
end_time = time.time()
cost_time = end_time-start_time
print(f'\n Cumulative time:{cost_time:0.2f} second')
print(f'Download speed:{file_size_MB/cost_time:0.2f}M/s')Operation results:
# Video download >>>down_file(video_url, 'mp4') 200 File name: [spell return to war] Episode 20 Article 5 Wushuai is a little too much File size: 42.10 MB Download progress: 100.00% Cumulative time: 5.72 second Download speed: 7.36M/s # Audio download >>>down_file(audio_url, 'mp3') 200 File name: [spell return to war] Episode 20 Article 5 Wushuai is a little too much File size: 5.13 MB Download progress: 100.00% Cumulative time: 0.80 second Download speed: 6.42M/s
We can see the successfully downloaded video files locally:
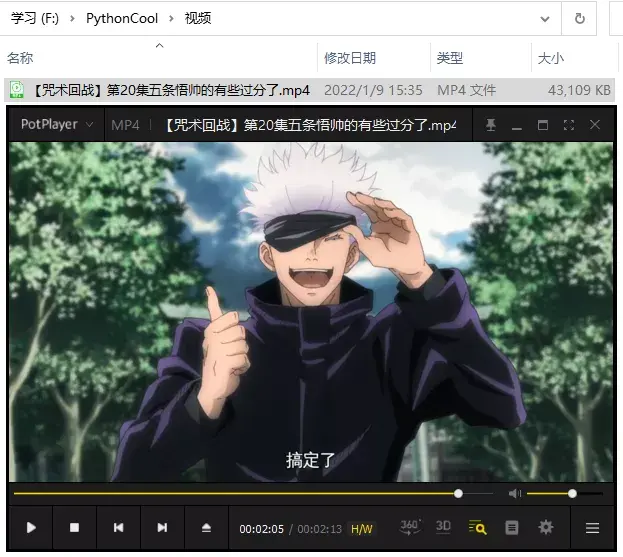
Since the video and audio are separated, there is no sound when the video is opened separately. We need to merge.
The merging operation requires the moviepy library. We will also introduce more applications of this library later. Please look forward to it~
from moviepy import *
from moviepy.editor import *
video_path = title + '.mp4'
audio_path = title + '.mp3'
#Read in video
video = VideoFileClip(video_path)
#Extract track
audio = AudioFileClip(audio_path)
#Merge tracks into video
video = video.set_audio(audio)
#Output
video.write_videofile(f"{title}(Including audio).mp4")That's it:
Moviepy - Building video [[spell back to war] Episode 20 Article 5 Wushuai is a little too much(Including audio).mp4. MoviePy - Writing audio in [[spell back to war] Episode 20 Article 5 Wushuai is a little too much(Including audio)TEMP_MPY_wvf_snd.mp3 MoviePy - Done. Moviepy - Writing video [[spell back to war] Episode 20 Article 5 Wushuai is a little too much(Including audio).mp4 Moviepy - Done ! Moviepy - video ready [[spell back to war] Episode 20 Article 5 Wushuai is a little too much(Including audio).mp4

5. GUI tool production
Well, it's easy to operate with my commonly used pysimplegui.
import PySimpleGUI as sg
#Theme settings
sg.theme('SystemDefaultForReal')
#Layout settings
layout = [[sg.Text('choice B Station video address:',font=("Microsoft YaHei ", 12)),sg.InputText(key='url',size=(50,1),font=("Microsoft YaHei ", 10),enable_events=True) ],
#[sg.Output(size=(66, 8),font = ("Microsoft YaHei", 10))]
[sg.Button('Start downloading',font=("Microsoft YaHei ", 10),button_color ='Orange'),
sg.Button('close program',font=("Microsoft YaHei ", 10),button_color ='red'),]
]
#Create window
window = sg.Window('B Station video download tool', layout,font=("Microsoft YaHei ", 12),default_element_size=(50,1))
#Event cycle
while True:
event, values = window.read()
if event in (None, 'close program'):
break
if event == 'Start downloading':
url = values['url']
print('Get video information')
title, video_url, audio_url = get_file_info(url)
print('Download Video Resources')
down_file(title, video_url, 'mp4')
print('Download Audio Resources')
down_file(title, audio_url, 'mp3')
print('Merge video and audio')
merge(title)
print('Audio and video processing completed')
window.close() 
6. Complete code
Not elegant enough, you can optimize yourself!