Using python to move files under folders in batches
Preface and demand analysis
I used yolov5 to detect an aircraft. Originally, yolo should be a classifier, but I regarded it as a single kind of detector. I made a mistake, but later I used my data to run with good results (simply referring to recognition, and the accuracy effect remains to be discussed), CSDN has found that there are different opinions about using yolo to detect a single type in China, so I went to stackflow to check. It is possible to simply detect a type for training, and even have a special strategy. Is CSDN really 2?
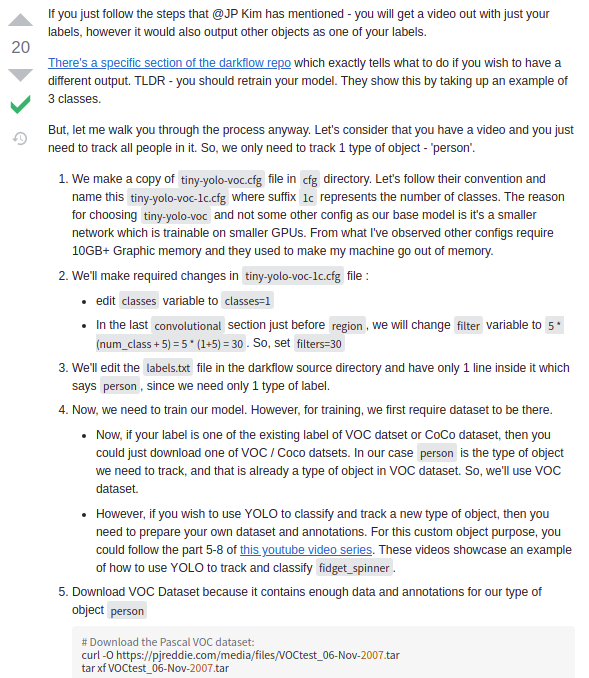
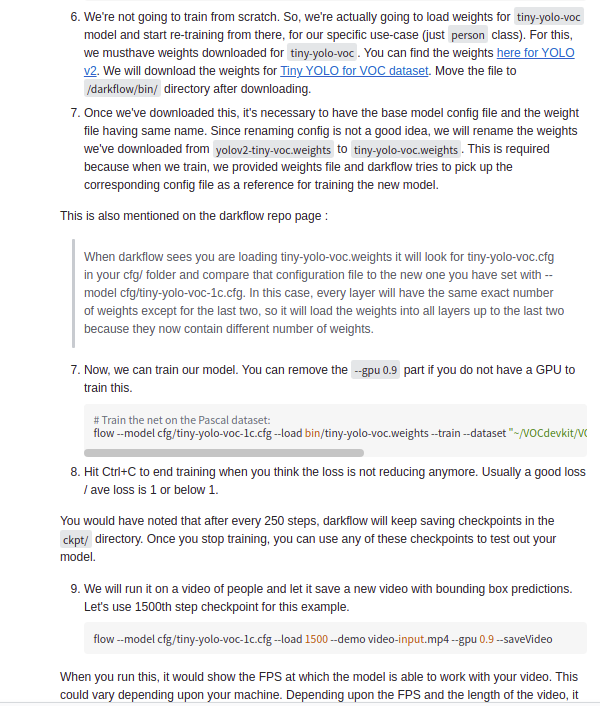

at the beginning, the idea of completing the design was to make a comparison between yolov4 and yolov3, and the water was drawn away at once. However, a great God found on B Hu said that it was useless for him to use yolov4 for DOTA data detection. Later, it was found that the size of his data cutting was 640 x 640, while yolov4 required 608 x 608, and yolov4 and yolov3 were not easy to configure, and the format of labels was different, Just yesterday, when communicating with a group friend, he used Retinanet to identify DOTA. Check again. Good guy, the format of this label is similar to the data format given by Zhihu God, so he had a whim. Can I take out and process my original yolov5 txt with the same name from another Labeltxt, and then copy it in batch to another folder
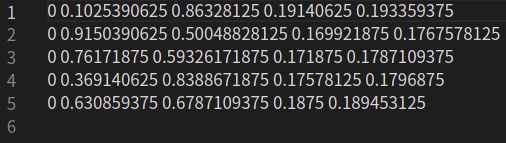
This figure is the annotation format of yolov5. If you want to train a single kind, you should start from 0, and the format of the label is the four normalized coordinates of class, while yolov4 and retinanet use image respectively_ Path, coordinate, category name, category label, image_path, coordinate, type name

This is the introduction of Retinanet's data format, and the following are some examples of specific data format

because the DOTA data set has the original annotation format, I want to copy it directly and put it in. However, in yolov5, the only type of aircraft I have is that the training data set has 1823 TXT data, while the verification set has 498 txt data, while the original dota data set has 10000 + txt data, So I can't find the txt file containing only the aircraft one by one from the DOTA dataset
so that's what I need,
/home/neverland/desktop/yolov5/coco/data/train/labels
There are 1823 txt files in this folder
And I need to be
'/home/neverland/desktop/Graduation thesis test/DOTA_split/trainsplit/labelTxt
Find folders with the same name and move them to another folder. The destination folder is
/home/neverland/desktop/Graduation thesis test/DOTA_test/trainsplit
In fact, a similar batch operation was done before. At that time, the requirement was to move the file labeled 2 and its corresponding jpg file with the same name to another folder. The main modules used were os module and shutil module
First list the overall code. If there are similar requirements, you can make similar changes. As for the aircraft data set I got, there is no open source spirit
# coding = UTF8
# Make the label conform to the VOC format, and make the normal label the same as it. Take out the picture of the aircraft
# Author: Neverland!
# Date:Apr 11th
# version 1.0
import os
import shutil
import os.path
#Files in training set
tran_file_dir = '/home/neverland/desktop/yolov5/coco/data/train/labels'
train_file_name = os.listdir(tran_file_dir)
#Files in validation set
val_file_dir = '/home/neverland/desktop/yolov5/coco/data/val/labels'
val_file_name = os.listdir(val_file_dir)
move_file_dir = '/home/neverland/desktop/Graduation thesis test/DOTA_split/trainsplit/labelTxt' #Folder of train
move_file_dir2 = '/home/neverland/desktop/Graduation thesis test/DOTA_split/valsplit/labelTxt' #val folder
dst_trainfile_dir = '/home/neverland/desktop/Graduation thesis test/DOTA_test/trainsplit' #train destination folder
dst_valfile_dir = '/home/neverland/desktop/Graduation thesis test/DOTA_test/valsplit' #val destination folder
for i in range(len(train_file_name)):
files = train_file_name.pop()
#Split path
pre_name,aft_name = os.path.splitext(files)
#Path to source file
source_file_name = os.path.join(move_file_dir,files)
#Path to destination file
dst_file_name = os.path.join(dst_trainfile_dir,files)
shutil.copy(source_file_name,dst_file_name)
print('The text file of training data is copied successfully')
for j in range(len(val_file_name)):
files1 = val_file_name.pop()
#Split path name
pre_name1,aft_name1 = os.path.split(files1)
#Folder of source files
source_file_name1 = os.path.join(move_file_dir2 ,files1)
#Folder of destination file
dst_file_name1 = os.path.join(dst_valfile_dir,files1)
shutil.copy(source_file_name1,dst_file_name1)
print('Verify that the data text file is copied successfully')
- The first few lines list the address of my source file and the sub file under its folder, train_file_name = os.listdir(tran_file_dir) will return a list, put the file names of all the files in the folder under the list, and then I can use len(train_file_name) to return a total of several files
- You can also pop them out one by one, that is, what I do below, pop them out one by one
- Then continue the operation. That is, first, I divide its file name into prefix and suffix, and use OS path. Split divides the file name into prefix and suffix, but it should be noted that since the operating system does not automatically give it as an absolute path when processing, I need to combine the directory and file name, namely OS path. Join (DIR, filename) allows the operating system to find the file. Otherwise, the system will report an error, and it is likely to lose your file to the operation. Because it is written by yourself, it is very familiar, and it will OS every time path. Exists () checks whether the path exists, so try catch syntax is not used
- When I find the file, I can use shutil to copy it
The absolute path and relative path are explained here. The so-called absolute path is the location of the folder plus the file name, while the relative path usually only needs the file name, such as the following two examples
/home/neverland/desktop/yolov5/coco/data/val/labels/read.md #Absolute path read.md #Relative path
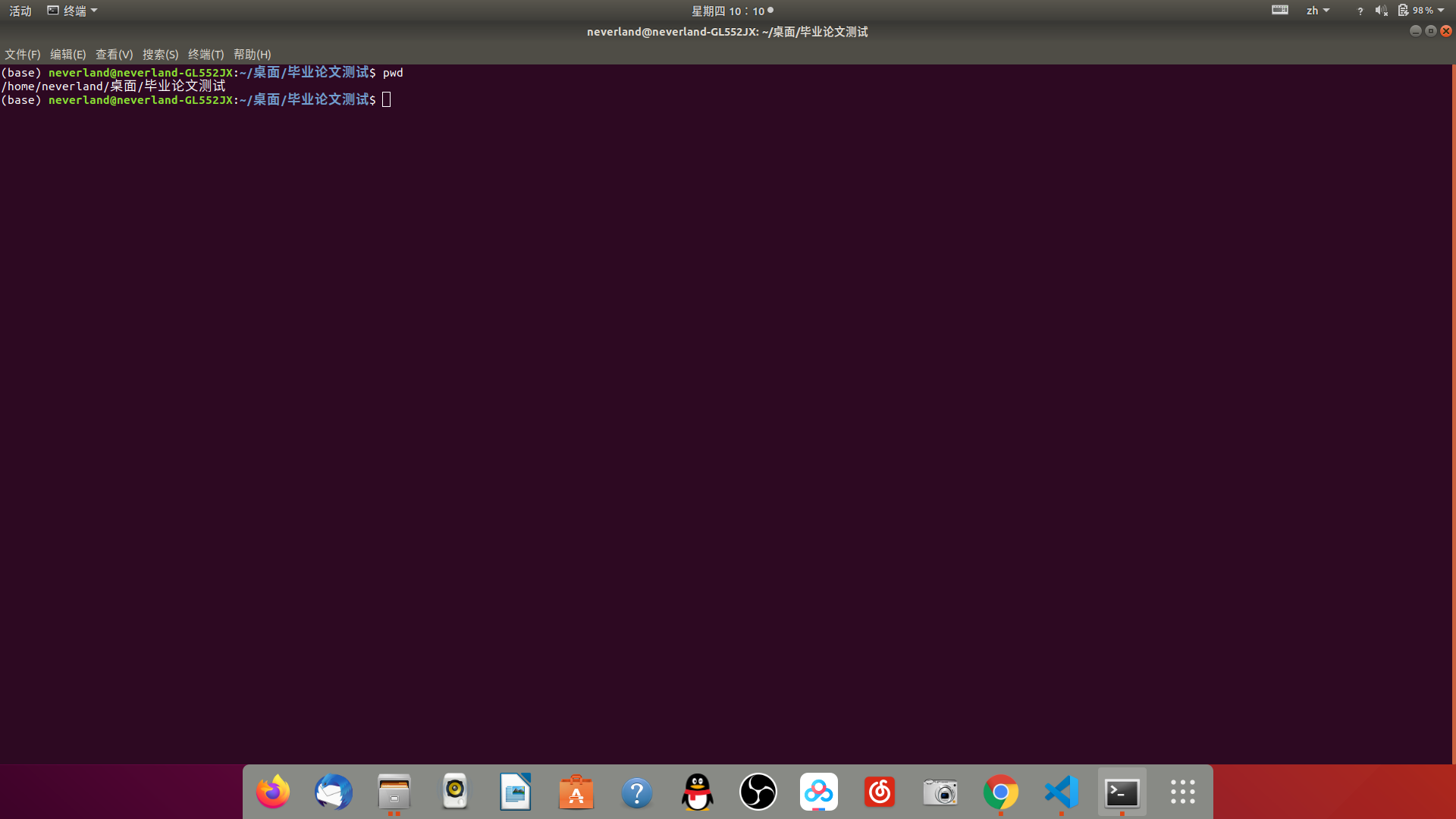
For mac and Linux systems, after opening the terminal at the location where the folder is located, enter pwd command at the terminal to tell you your location, that is, the so-called path of the folder. At this time, your directory is the path name of the folder. You can operate all files under the folder later without adding the path of the folder, As shown in the figure below:
Of course, when writing code, you can use the function of opening the folder, and then it will be in the folder, for example:
You can directly manipulate the file name at this time. When I write a blog, I will cut it off and upload it to CSDN, then turn it to the WeChat official account with the rich text tool.
this code is relatively simple. Looking back, it is mainly to take out the file name and then copy. For people who do in-depth learning, the amount of data often starts with 10k +, so you can't name it one by one, so the batch operation will be much simpler