preface
After 108 days, he released the latest video at station B, "I turned on a light in 108 days...". So let's use the crawler to crawl the bullet screen of the video and see what the partners say
1, What is a reptile?
Baidu Encyclopedia says: a program to automatically obtain web content. In my opinion, crawlers are ~ ~ "crawling around on the Internet..." shut up~~
Then let's take a look at how to raise the "insects" carrying the bullet screen of station B
II Feeding steps
1. Request barrage
First of all, you need to know what the url of the website is. For the barrage of station B, the location of the barrage has a fixed format:
http://comment.bilibili.com/+cid+.xml
ok, so the question is, what is cid? Whatever it is, I'll tell you how to get it.
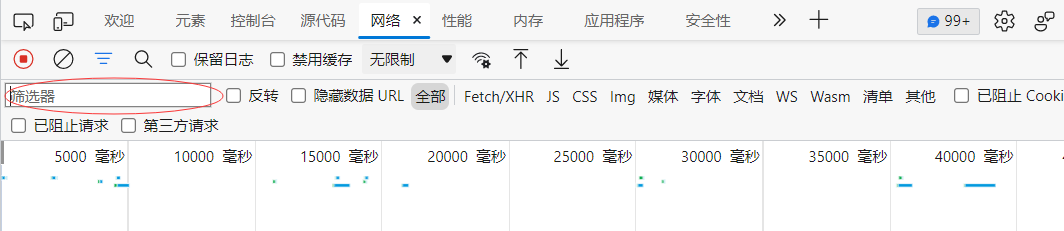
- After opening the video, click F12 to switch to "network" and fill in "cid" in the filter to filter.
- Click the filtered network information and find the cid at the Payload at the right end
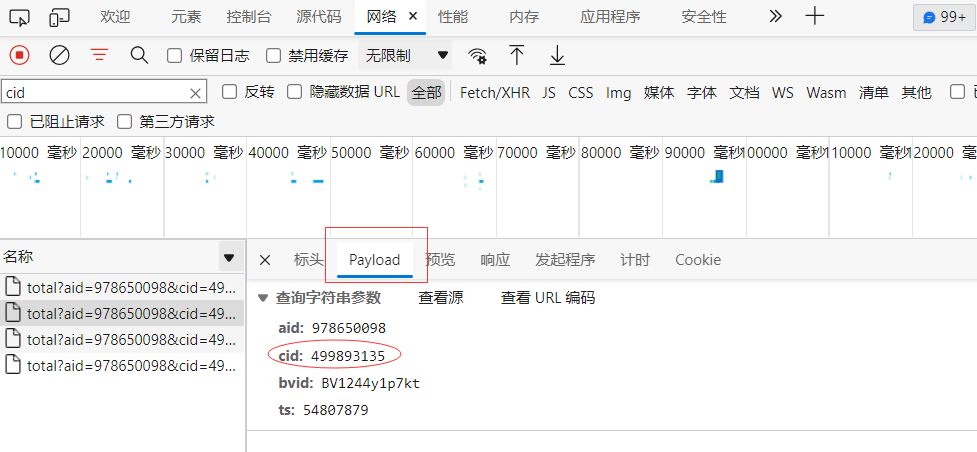
- Now we know the network link of he classmate's video barrage:
http://comment.bilibili.com/499893135.xml
- The next step is to send a network request and obtain the network page resources. Python has many libraries for sending network requests. For example:
- urllib Library
- requests Library
We use the reaquests library to demonstrate
The code for sending the request is as follows
(example):
#[classmate he] I turned on a light in 108 days cid of video: 499893135 #Barrage location url = "http://comment.bilibili.com/499893135.xml" #Send request req = requests.get(url = url) #Get the content of the content response html_byte = req.content #Convert byte to str html_str = str(html_byte,"utf-8")
It is also worth mentioning that the request header of the sending request can be added to disguise that it is accessed by the browser. You can get it through the header parameter and user agent as follows:
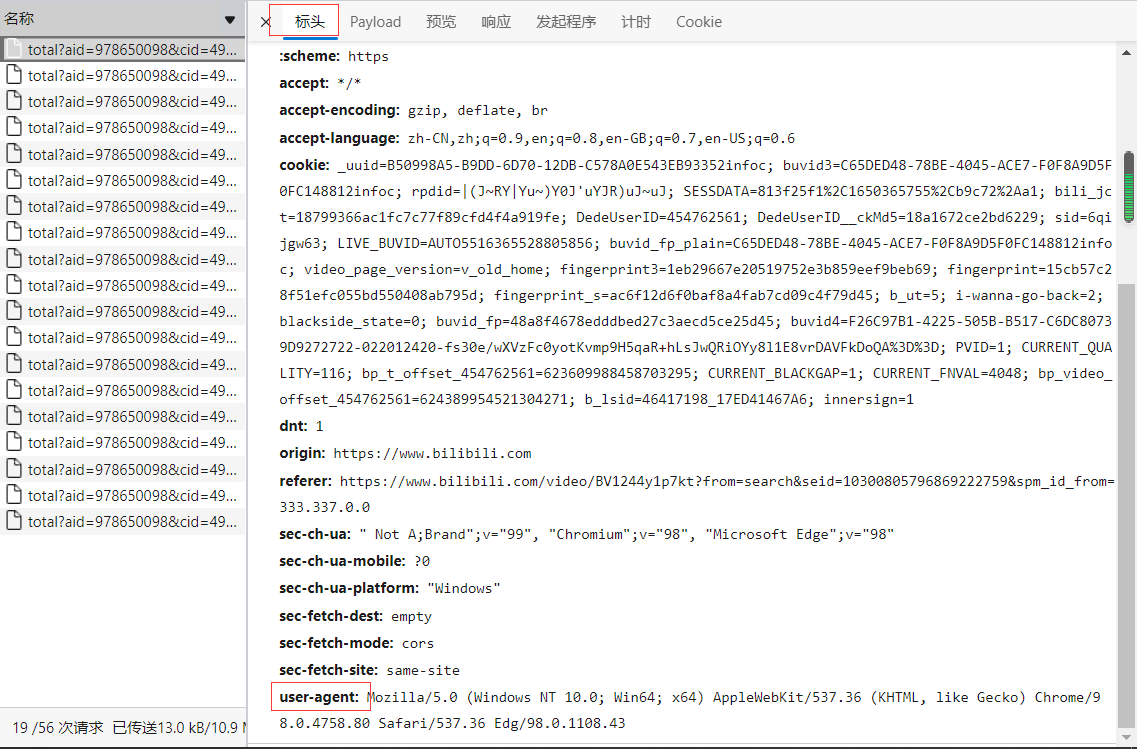
Then, the code is as follows:
#Pretend to be a browser
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#[classmate he] I turned on a light in 108 days cid of video: 499893135
#Barrage location
url = "http://comment.bilibili.com/499893135.xml"
#Send request
req = requests.get(url = url, headers=header)
#Get the content of the content response
html_byte = req.content
#Convert byte to str
html_str = str(html_byte,"utf-8")
2. Analyze the barrage
html_str is the format of HTML file. We need to process it to get the information we want. At this time, Beautiful soup Library It's going to shine. We use it to process the resulting html file
The code is as follows (example):
#analysis
soup = BeautifulSoup(html,'html.parser')
#Find the < d > tag in the html file
results = soup.find_all('d')
#Extract the text from the label
contents = [x.text for x in results]
#Save as dictionary
dic ={"contents" : contents}
contents is the bullet screen string list. It is saved as a dictionary for the next step
Storage barrage
The barrage information is stored in excel, and there are many libraries that can be used. For example:
- xlwt Library
- pandas Library
We'll use the pandas library to
The code is as follows (example):
Create the dictionary obtained in step 2 dataFrame , and then save it with an API of pandas library
#Created a spreadsheet with a dictionary
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
Total code
import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
html = askUrl()
dic =analyse(html)
writeExcel(dic)
def askUrl():
#Pretend to be a browser
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#[classmate he] I turned on a light in 108 days cid of video: 499893135
#Barrage location
url = "http://comment.bilibili.com/499893135.xml"
req = requests.get(url = url, headers=header)
html_byte = req.content#byte
html_str = str(html_byte,"utf-8")
return html_str
def analyse(html):
soup = BeautifulSoup(html,'html.parser')
results = soup.find_all('d')
#x.text indicates the value to put in contents
contents = [x.text for x in results]
#Save results
dic ={"contents" : contents}
return dic
def writeExcel(dic):
#Created a spreadsheet with a dictionary
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
if __name__ == '__main__':
main()
summary
To put it simply, there are three steps:- Send network request and obtain resources
- Search and other operations to obtain useful information
- Store information
Have you learned? If you learn it, just praise it before you go
