1. Chat preparation
1. Turn off your computer's firewall

2. Turn off unnecessary virtual networks and other unnecessary Ethernet, leaving only a network chat channel
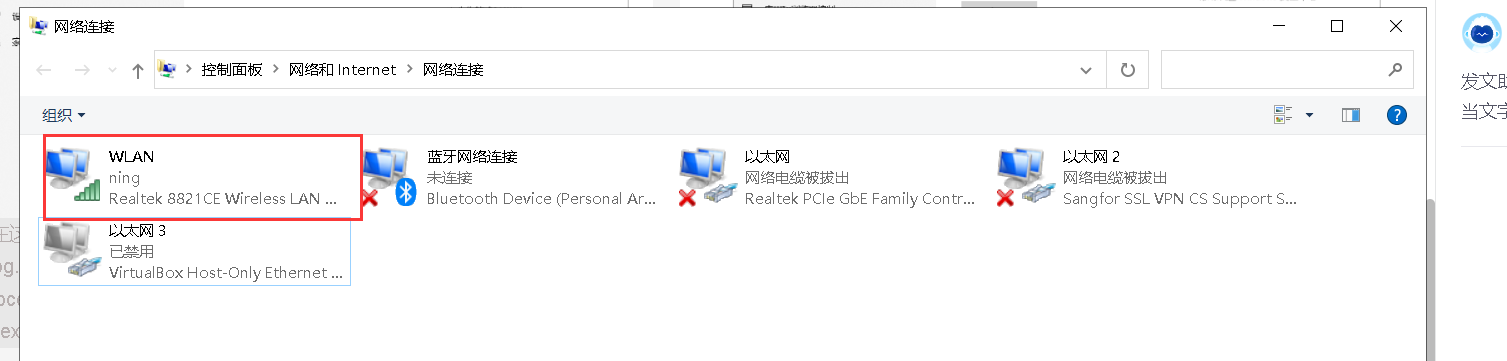
3. Connect two computers to the same mobile hotspot and open the crazy chat program
2 chat and capture packets
2.1. Crazy chat
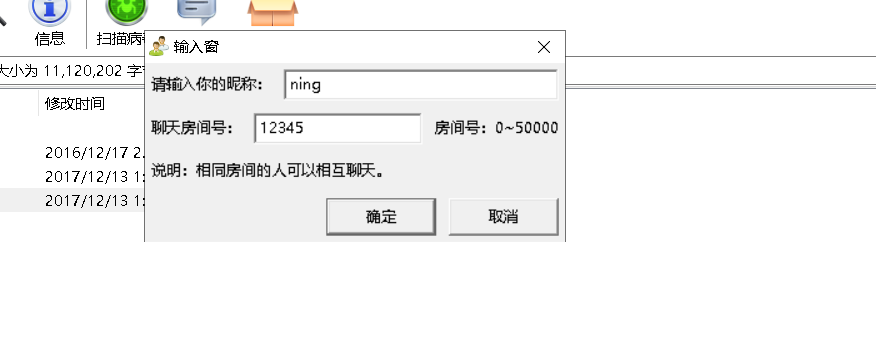
1. First, name yourself a chat nickname, and enter the same chat room number for two computers (or multiple computers together)
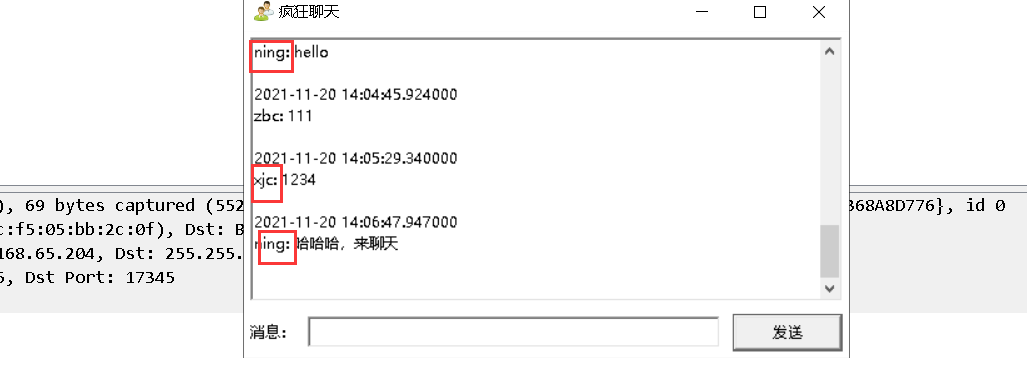
2. Send messages, that is, chat
2.2. Use wireshark to capture chat information
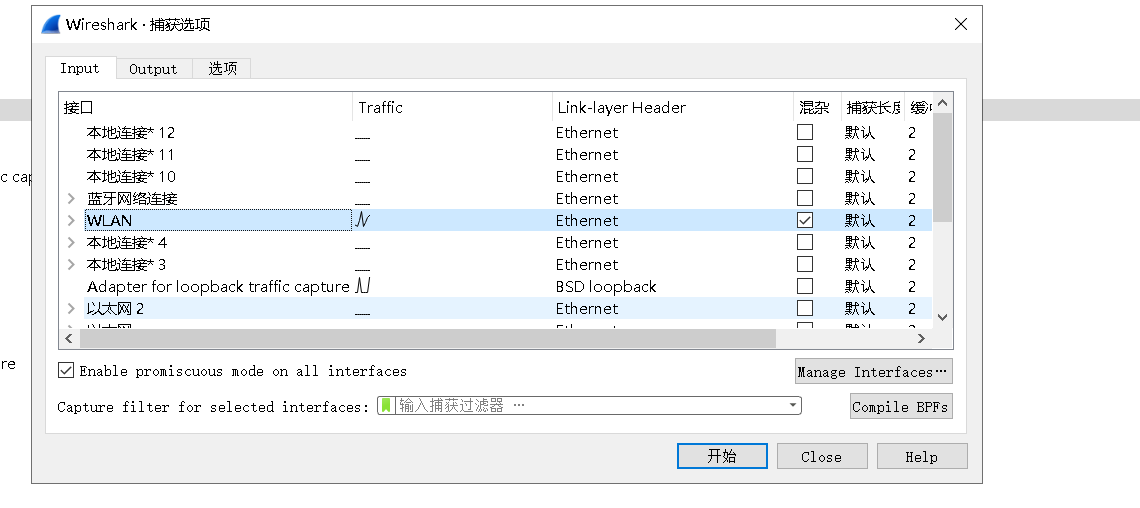
1. Open wireshark to capture chat information under wlan (wireless network). You can refer to: https://blog.csdn.net/qq_46689721/article/details/121167497
2. The Dst address for viewing chat information is 255.255.255.255
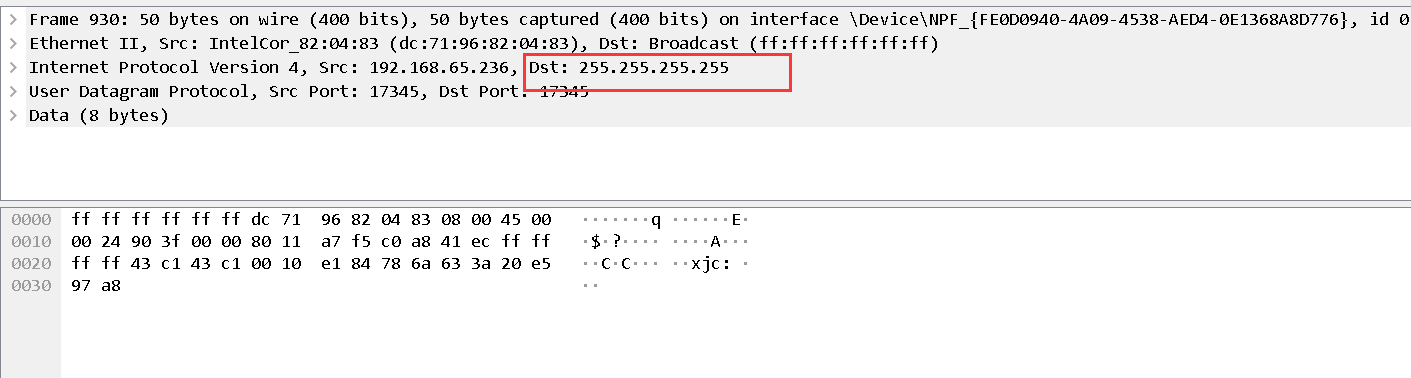
3. Find a record with Destination 255.255.255.255
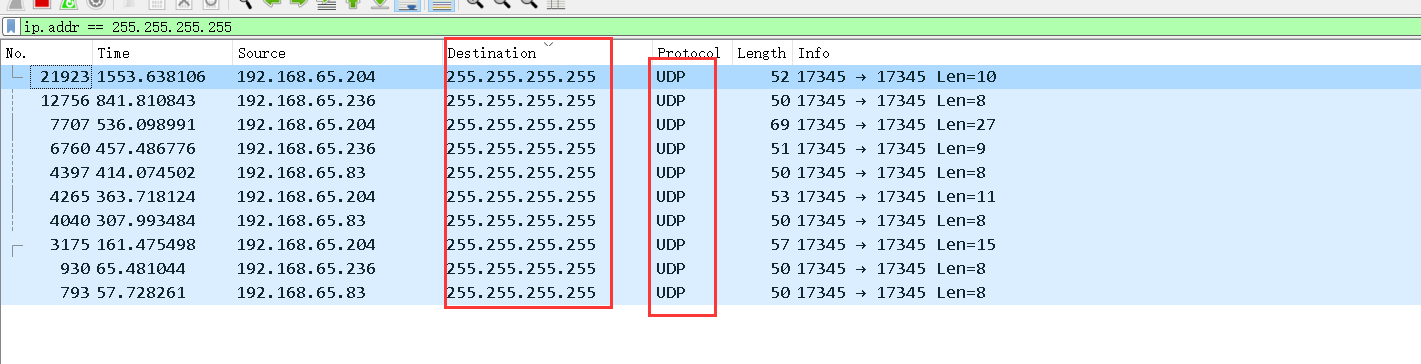
It can be seen that the network is connected through the UDp protocol
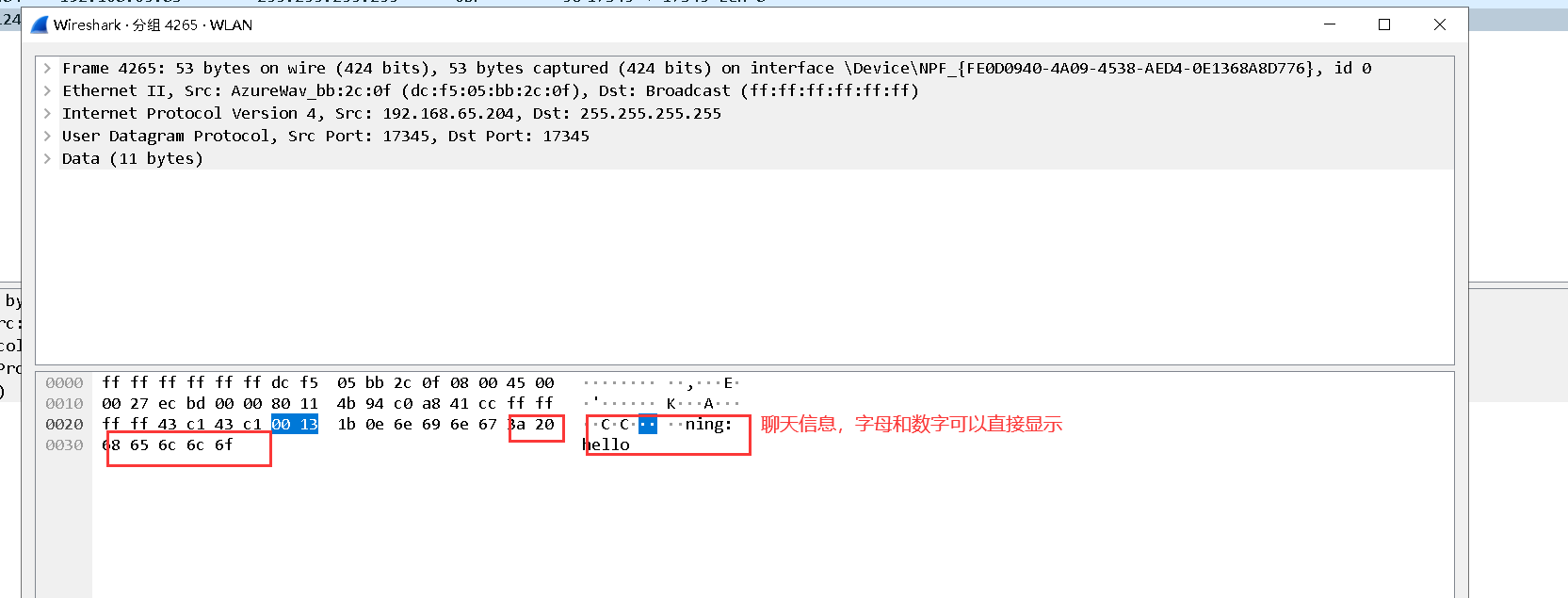
4. View English chat information
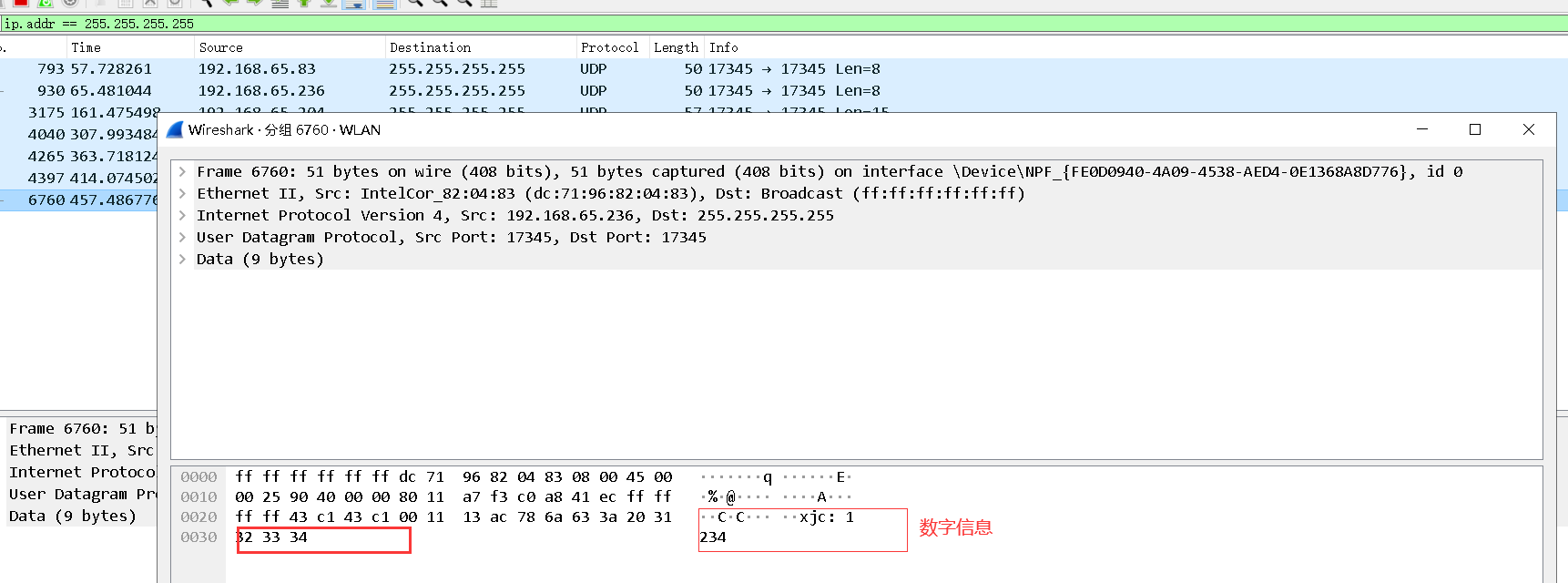
5. View digital chat messages
6. View text chat messages
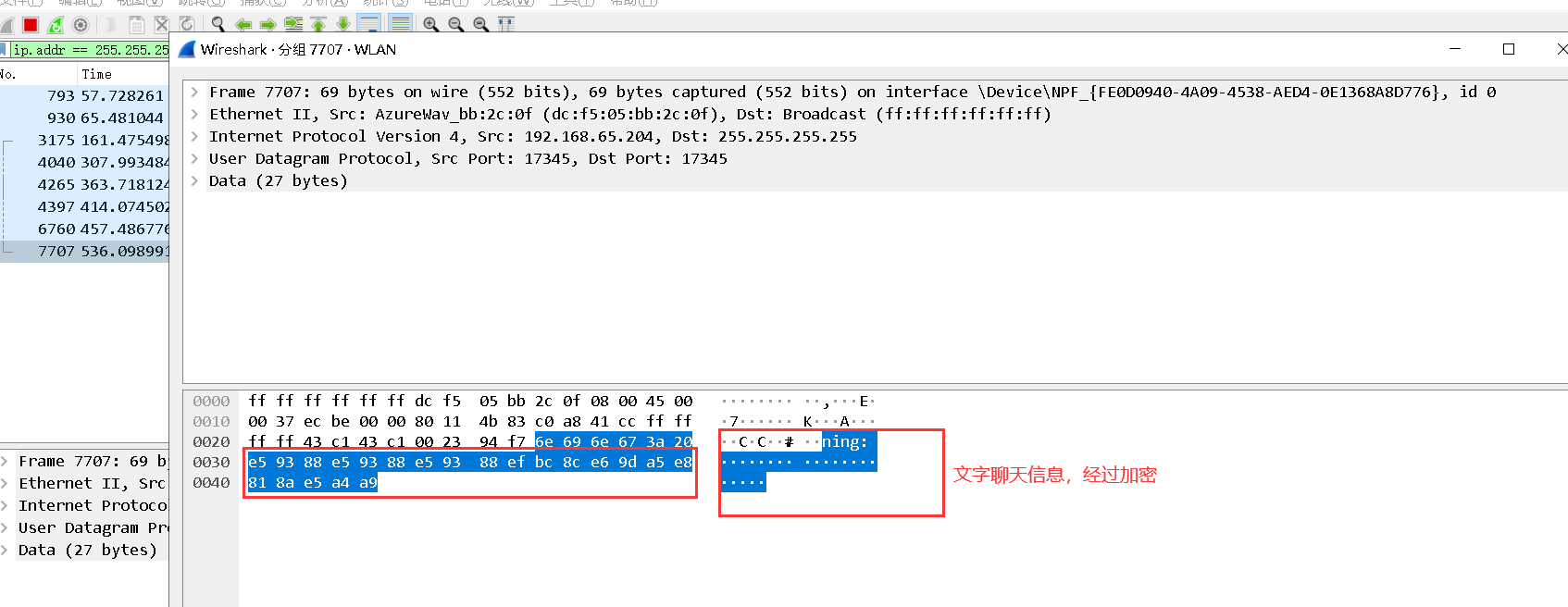
7. According to the above capture results, the port used for chat is 17345 and the protocol used is UDP
2. New web crawler
2.1. What is a reptile
1. Introduction: Web Crawler is also called Web Spider, web ant and web robot. Its English name is Web Crawler or Web Spider. It can automatically browse the information in the network. Of course, when browsing the information, we need to browse according to the rules we make. These rules are called Web Crawler algorithm. Using Python, we can easily write crawler programs for automatic retrieval of Internet information.
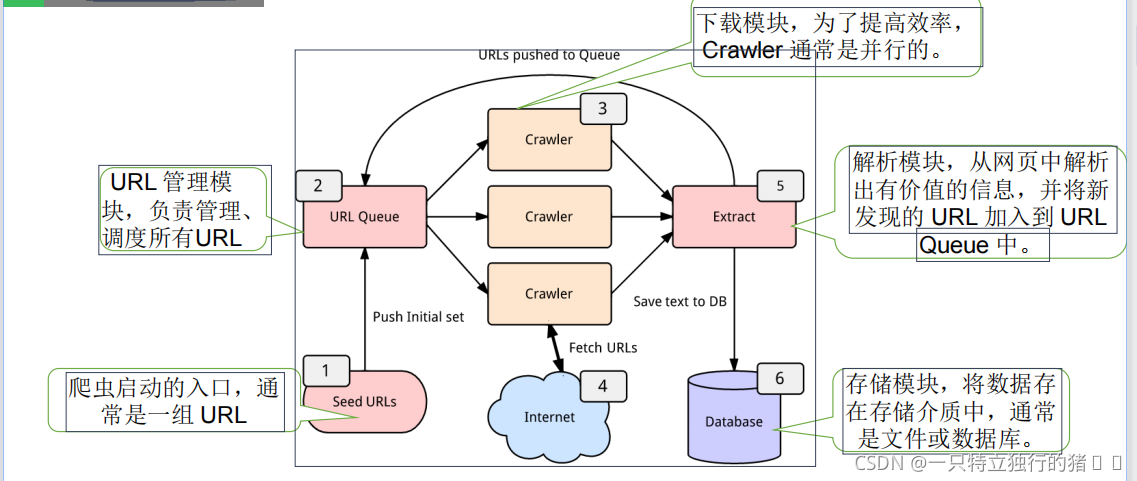
2. Basic process of crawler: initiate request: initiate a request to the server through url. The request can contain additional header information. Get the response content: if the server responds normally, we will receive a response, which is the web page content we requested, perhaps including HTML, Json string or binary data (video, picture), etc.
3. URL management module: initiate a request. Generally, requests are made to the target site through the HTTP library. It is equivalent to opening the browser and entering the web address.
Download module: get the response. If the requested content exists on the server, the server will return the requested content, generally HTML, binary files (video, audio), documents, Json strings, etc.
Parsing module: parsing content. For users, it is to find the information they need. For Python crawlers, it is to extract target information using regular expressions or other libraries.
Enclosure: save data. The parsed data can be saved locally in many forms, such as text, audio and video.
2.2. Access the ACM topic website of Nanyang Institute of technology
1. Open the ACM topic website of Nanyang Institute of Technology http://www.51mxd.cn/ , then press F12 to enter the working mode, click source, and you can see the source code of the web page. At this time, you can see that the topic information we need is in the TD tag, that is, we want to crawl the content in the TD tag

2. I use Jupiter. Open it and use python for programming
import requests# Import web request Library
from bs4 import BeautifulSoup# Import web page parsing library
import csv
from tqdm import tqdm
# Simulate browser access
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# Header
csvHeaders = ['Question number', 'difficulty', 'title', 'Passing rate', 'Number of passes/Total submissions']
# Topic data
subjects = []
# Crawling problem
print('Topic information crawling:\n')
for pages in tqdm(range(1, 11 + 1)):
# Incoming URL
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
# Resolve URL
soup = BeautifulSoup(r.text, 'html5lib')
#Find and crawl everything related to td
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# Storage topic
with open('D:\word\protice.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Topic information crawling completed!!!')
3. Then run the program
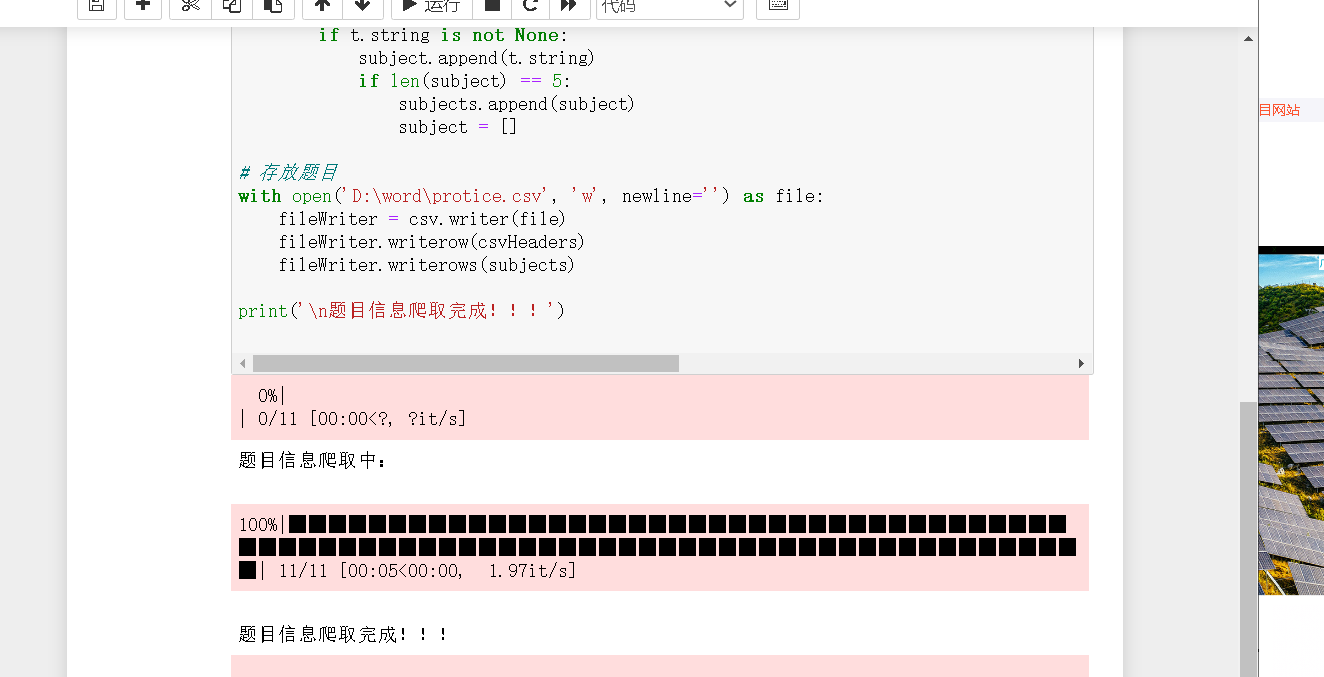
4. View the generated crawl data


2.3. Climb all the information notices in the news website of Chongqing Jiaotong University in recent years
1. Open the information notification website of Chongqing Jiaotong University: http://news.cqjtu.edu.cn/xxtz.htm
2. Similarly, open F12 to enter the developer mode. You can find the web page source code under emelets, and you can see that the information we need to crawl is in the div tag

3. Then find the number of pages of data to crawl
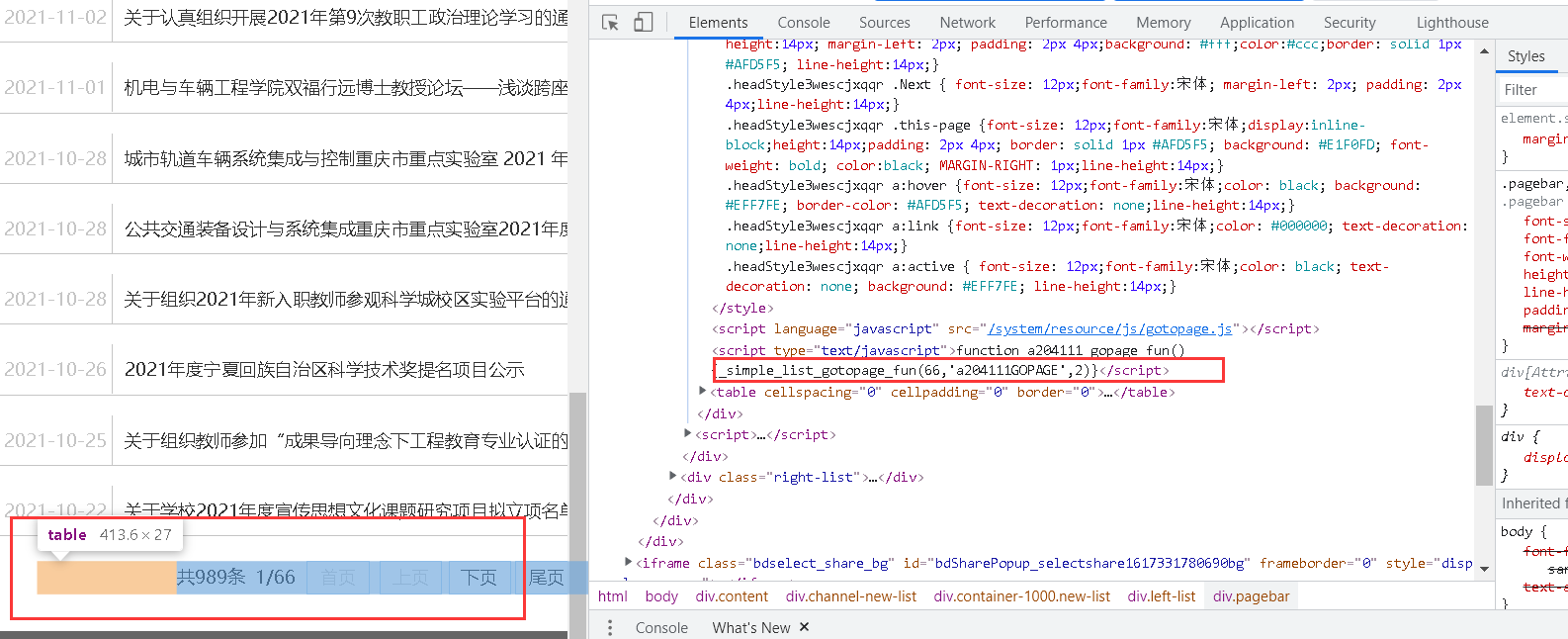
4. Next, write the code in jupyter
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # Make URL to get web page data
# All news
subjects = []
# Simulate browser access
Headers = { # Simulate browser header information
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# Header
csvHeaders = ['time', 'title']
print('Information crawling:\n')
for pages in tqdm(range(1, 65 + 1)):
# Make a request
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# If the request is successful, get the web page content
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# Parsing web pages
soup = BeautifulSoup(html, 'html5lib')
# Store a news item
subject = []
# Find all li Tags
li = soup.find_all('li')
for l in li:
# Find div tags that meet the criteria
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# Time, crawling tag
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# title
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# Save data
with open('D:/word/new.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Information crawling completed!!!')
5. Run code

6. Crawled data

3. Summary
I'm not very familiar with crawlers just now, but I can still crawl some simple information with reference to the materials on the Internet. The information crawling of the website first needs to analyze the source code of the website, analyze the crawling information, find the label content, and then crawl. Through this practical operation, I realized that crawlers are still very helpful to us and can help us with random information.
reference resources:
https://zhuanlan.zhihu.com/p/77560712
https://www.php.cn/python-tutorials-373310.html
https://blog.csdn.net/weixin_56102526/article/details/121366806?spm=1001.2014.3001.5501