I shared an article about using requests library to crawl 250 Douban Movies. Today I will continue to share about using xpath to crawl the cat's Eye movie popularity list.
XPATH syntax
XPATH(XML Path Language) is a language used to find information from XML files. General purpose is to find data from HTML files. If you want to be good at your job, you have to be good at it. Let's first understand the grammatical rules commonly used in XPATH.
Common matching rules:
| attribute | Matching rule description |
|---|---|
| nodename | Match all child nodes of this node |
| / | Matches the immediate child of the current node, excluding the grandchild node |
| // | Match all descendant nodes of the current node |
| . | Match the current node |
| .. | Match the parent of the current node |
| @ | Matching attribute values |
XPATH matching function is very powerful, the above six matching rules can be used together, through the above six matching rules can crawl to all the data we want on the web page.
Use the following HTML document to describe the collocation of the six rules.
<html>
<div id="div_id1" class="div_class1">
<ul>
<li class="li_item1"><a href="www.bigdata17.com">Summer My brother's reserve</a></li>
<li class="li_item2 li"><a href="li_test.html">test li</a></li>
</ul>
<li>20</li>
<li>30</li>
<ul>
</ul>
</div>
</html>| Matching expression | Result |
|---|---|
| //* | Match all nodes in a web page |
| //div | Match all div nodes |
| //div/li | Match all li nodes of all div nodes |
| //a[@href="www.bigdata17.com"/..] | Match the parent node of the A node whose href attribute is www.bigdata17.com |
| //li[@class="li_item1"] | Match all Li elements, and the class attribute is "li_item1" |
| //li[@class] | Match all li elements with class attributes |
| //li/a/@href | Get the href attribute values of all Li element a child elements, note and //li[@class="li_item1" and |
| //li//text() | Text of all subnodes of li node in the past |
| //li[@class="li_item1"]/a/text() | Get the text of all a subnodes of the Li node whose class attribute is li_item1 |
| //li[contains(@class,"li")]/a/text() | Get the text of all a subnodes of the li node containing li in the class attribute value |
| //div[contains(@class,"div") and @id="div_id1"]/ul | Gets ul child nodes of div nodes with all class attributes containing "div" and ID attribute values of "div_id1" |
| /div/ul[li>20] | Select all ul nodes of div node, and the value of li node must be greater than 20 |
| /div/ul[1] | Match the first ul node belonging to the div node. |
| /div/ul[last()] | Match the last ul node belonging to the div subnode |
| /div/ul[last()-1] | Matching the penultimate ul node belonging to the div subnode |
| /div/ul[position() < 3] | Match the first two ul subelements that belong to the div element |
With the above matching rules, we can use XPATH to analyze the data that crawl the domestic box office of cat-eye movies.
XPATH is used in conjunction with requests. It uses requests to capture web page information, and then uses XPATH to parse web page information. XPATH is in the lxml library, so it needs to install lxml in pycharm.
1. Obtaining HTML Files for Cat Eye Movie Hot List
Following is the code to grab the cat's eye movie's popular word-of-mouth list:
from lxml import etree
import requests
url = 'http://maoyan.com/board/1'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text2. Extracting Film Names
Now the browser developer tools support extracting xpath rules, the specific steps are as follows:
First, open the web site in the browser, press F12, ctrl+f to find the movie name, right-click the menu, click Copy option, click Copy Xpath. So we can extract the xpath matching rules of movie names: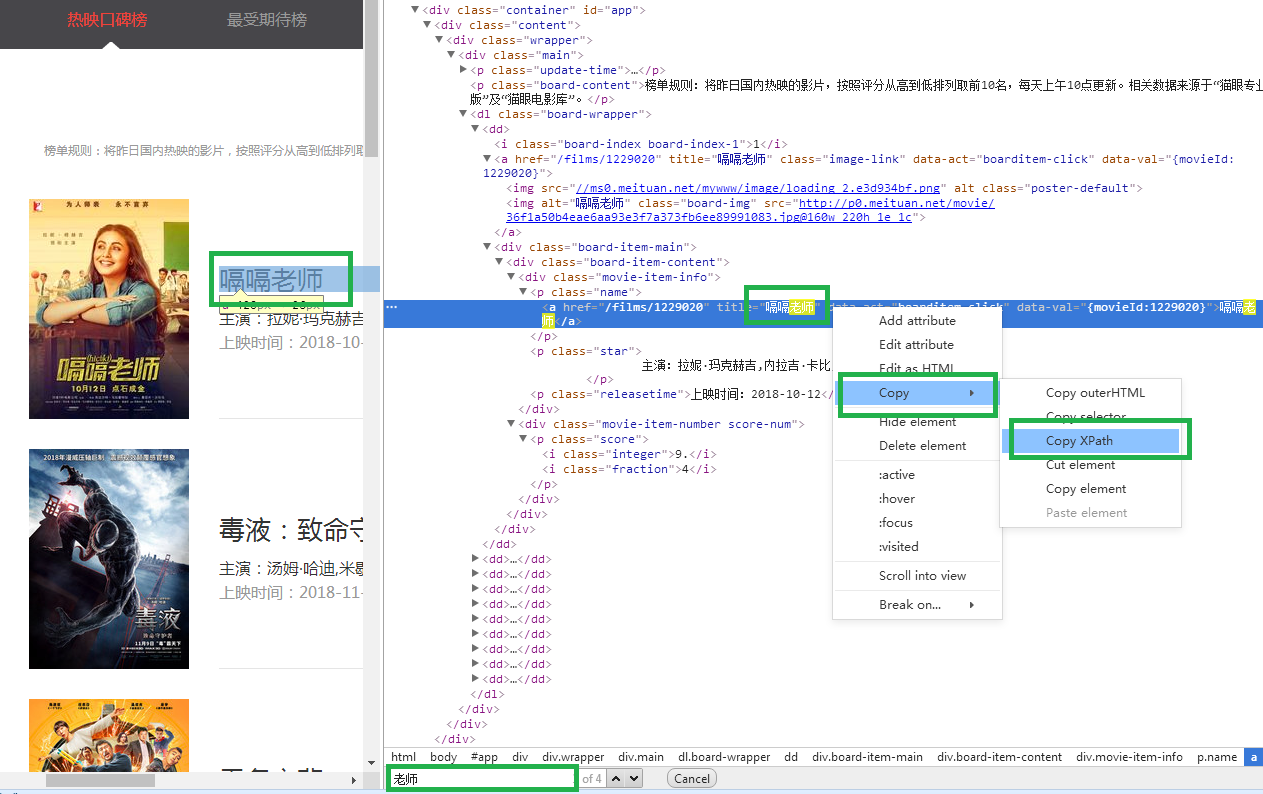
The rules for extracting movie titles are as follows:
//*[@id="app"]/div/div/div/dl/dd[1]/div/div/div[1]/p[1]/a
We use this rule to see if we can extract the name of the movie. The code is as follows:
from lxml import etree
import requests
url = 'http://maoyan.com/board/7'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
movie_name_xpath = '//*[@id="app"]/div/div/div/dl/dd[1]/div/div/div[1]/p[1]/a/text()'
s = etree.HTML(html)
movie_name = s.xpath(movie_name_xpath)
print(movie_name)Operation results: [<Elementa at 0x35f5248>]
The results above show that the captured element is a tag in html. To get the text value of the element, it is necessary to append / text() to the xpath matching rule. The following is the code and running results after appending / text():
from lxml import etree
import requests
url = 'http://maoyan.com/board/1'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
movie_name_xpath = '//*[@id="app"]/div/div/div/dl/dd[1]/div/div/div[1]/p[1]/a/text()'
s = etree.HTML(html)
movie_name = s.xpath(movie_name_xpath)
print(movie_name)
//Running results ['Teacher hiccup']Here we just extract the name of a movie. We want to extract the name of all movies on the current web page. How do we write the matching rules?
Here are the xpath matching rules for 10 movies on the current page
//*[@id="app"]/div/div/div/dl/dd[1]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[2]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[3]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[4]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[5]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[6]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[7]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[8]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[9]/div/div/div[1]/p[1]/a //*[@id="app"]/div/div/div/dl/dd[10]/div/div/div[1]/p[1]/a
It is found that the number of dd will change and the others will remain unchanged. Therefore, the wildcard character "*" is used to replace the number in dd node, and the xpath rule for extracting all movie names on the current page is as follows:
//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[1]/a
See what the final result is.
from lxml import etree
import requests
url = 'http://maoyan.com/board/1'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
movie_name_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[1]/a/text()'
s = etree.HTML(html)
movie_name = s.xpath(movie_name_xpath)
print(movie_name)
//Running results: ['Teacher hiccup','Venom: Deadly Guardian','Unknown Generation','King Dinosaur','Bob the Vagrant Cat','Unmatched','Detective Conan: Executor of Zero','Hurricane Wonderful Robbery','Shadow','Hello, Zhihua']Visible use of wildcard * to extract all the movie names.
3. Extracting Links of Film Pictures
The xpath matching rule of the image obtained by the previous step is as follows:
//*[@id="app"]/div/div/div/dl/dd[1]/a/img[2]
Developer tools know that img nodes have three attributes, alt,class and src.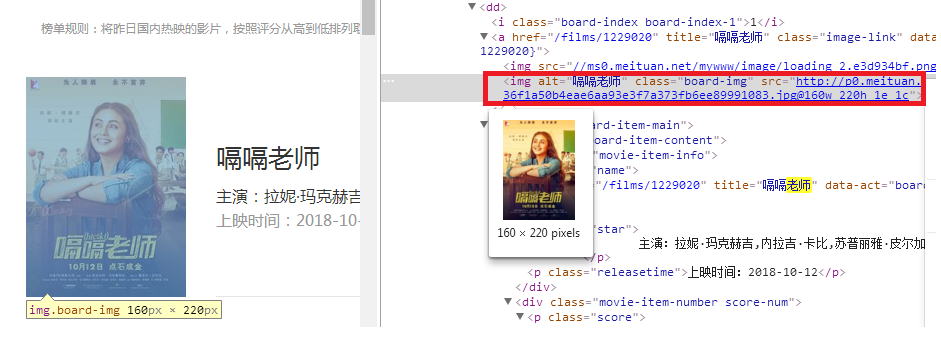
Where SRC is the address of the picture, add @src to the xpath extraction rule to change it to:
//*[@id="app"]/div/div/div/dl/dd[1]/a/img[2]/@src
See if this xpath rule can extract the link address of the picture:
from lxml import etree
import requests
url = 'http://maoyan.com/board/7'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
movie_img_xpath = '//*[@id="app"]/div/div/div/dl/dd[1]/a/img[2]/@src'
s = etree.HTML(html)
movie_img = s.xpath(movie_img_xpath)
print(movie_img)The result of the operation is: []
How can we not get the value of the src attribute? Does the src attribute not exist?
View the source files of the web page by right mouse button:
The original SRC became data-src. After modifying the xpath rule, see if you can extract the links of movie pictures:
from lxml import etree
import requests
url = 'http://maoyan.com/board/7'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
movie_img_xpath = '//*[@id="app"]/div/div/div/dl/dd[1]/a/img[2]/@data-src'
s = etree.HTML(html)
movie_img = s.xpath(movie_img_xpath)
print(movie_img)Operation results:
['http://p0.meituan.net/movie/36f1a50b4eae6aa93e3f7a373fb6ee89991083.jpg@160w_220h_1e_1c']
Movie picture link extraction was successful.
This is the xpath rule for extracting a movie. Here are the rules for extracting 10 movie pictures on the current page:
//*[@id="app"]/div/div/div/dl/dd[1]/a/img[2]/@data-src //*[@id="app"]/div/div/div/dl/dd[2]/a/img[2]/@data-src //*[@id="app"]/div/div/div/dl/dd[3]/a/img[2]/@data-src ... ... ... //*[@id="app"]/div/div/div/dl/dd[9]/a/img[2]/@data-src //*[@id="app"]/div/div/div/dl/dd[10]/a/img[2]/@data-src
The observation shows that the number of dd will change, and the others will not change. Therefore, the wildcard character "*" is used to replace the number of dd nodes, and the xpath rule of extracting all the links of movie pictures on the current page is as follows:
//*[@id="app"]/div/div/div/dl/dd[*]/a/img[2]/@data-src
By analogy, the xpath matching rules of all movie names, picture addresses, stars, release times and ratings on the current page are extracted through the above way:
movie_name_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[1]/a/text()' movie_img_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/a/img[2]/@data-src' movie_actor_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[2]/text()' movie_release_time_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[3]/text()' movie_score_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[2]/p/i/text()'
The complete code to crawl the cat's Eye movie hit list in China is as follows:
# coding:utf-8
from lxml import etree
import requests
#Get web pages
def getHtml(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
html = response.text
return html
#
# movie_img_xpath = '//*[@id="app"]/div/div/div/dl/dd[1]/div/div/div[2]/p/i/text()'
# s = etree.HTML(html)
# movie_img = s.xpath(movie_img_xpath)
# print(movie_img)
#Analytic web page
def parseHtml(html):
s = etree.HTML(html)
movie_name_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[1]/a/text()'
movie_img_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/a/img[2]/@data-src'
movie_actor_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[2]/text()'
movie_release_time_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[1]/p[3]/text()'
movie_score_xpath = '//*[@id="app"]/div/div/div/dl/dd[*]/div/div/div[2]/p/i/text()'
movie_name = s.xpath(movie_name_xpath)
movie_img = s.xpath(movie_img_xpath)
movie_actor = s.xpath(movie_actor_xpath)
movie_score = s.xpath(movie_score_xpath)
movie_release_time = s.xpath(movie_release_time_xpath)
for i in range(len(movie_name)):
print('Film title:' + movie_name[i])
print('To star:' + movie_actor[i].strip())
print('Picture Links:' + movie_img[i].strip())
print('Score:' + movie_score[2*i] + movie_score[2*i + 1])
print(movie_release_time[i])
print('-------------------------------------------Strong dividing line-------------------------------------------')
def main():
url = 'http://maoyan.com/board/7'
html = getHtml(url)
parseHtml(html)
if __name__ == '__main__':
main()Conclusion:
When using developer tools to extract xpath rules to obtain the corresponding data, we should pay attention to the accuracy of xpath rules. Some browsers will add some redundant labels, or change the attribute name of the node. For example, in the example above, the SRC attribute of img node will be changed to data-src. The correct xpath rules can be obtained by viewing the source files together.