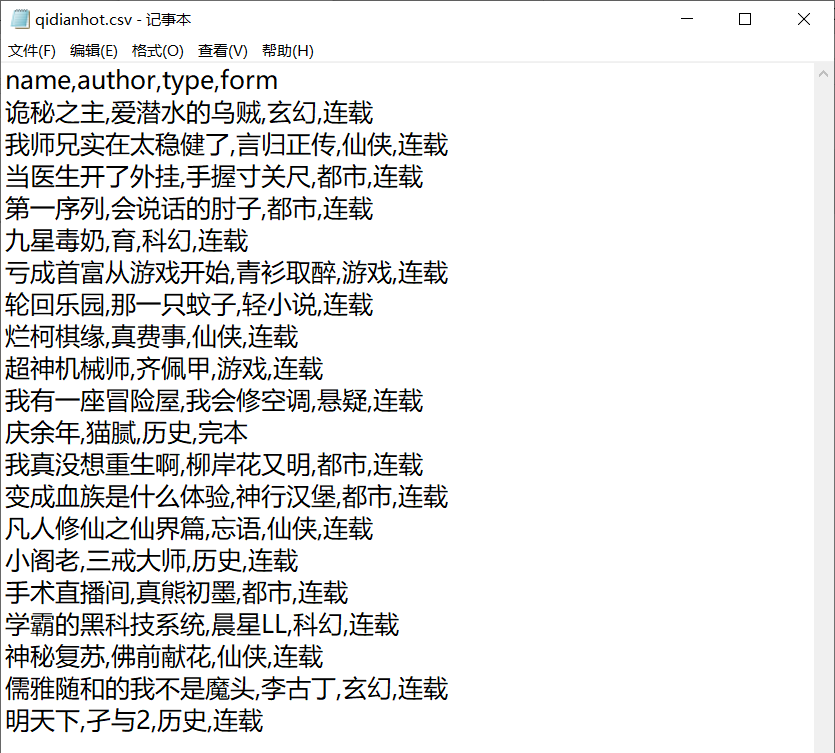
1, Demand analysis
To climb the 24-hour hot list of novels on the start of Chinanet: https://www.qidian.com/rank/hotsales?style=1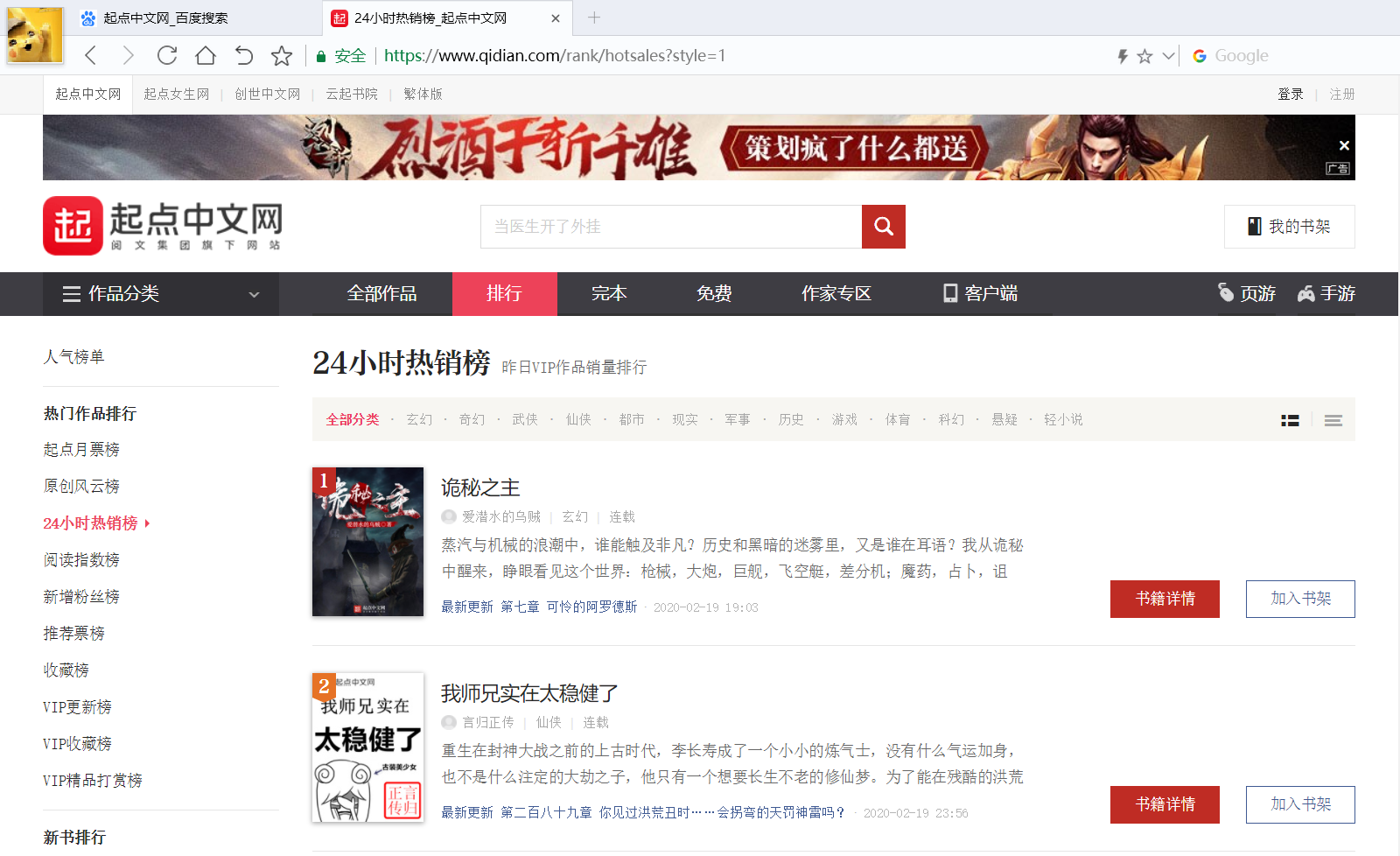
As the first crawler, we only crawl the first page of each novel's name, author, type, and whether it is serialized.
2, Create project
Open the command line, switch to the file path where you want to save the project, and enter scratch startproject Qidian? Hot to create a project project named Qidian.
Open the file path, and you can see that a folder of "Qi Dian" has been generated, in which the relevant files of the plot are saved.
3, Analysis page
Use Google browser or other browsers with developer tools to open the 24-hour hot sales list of the start Chinese website https://www.qidian.com/rank/hotsales?style=1
Then open the developer tool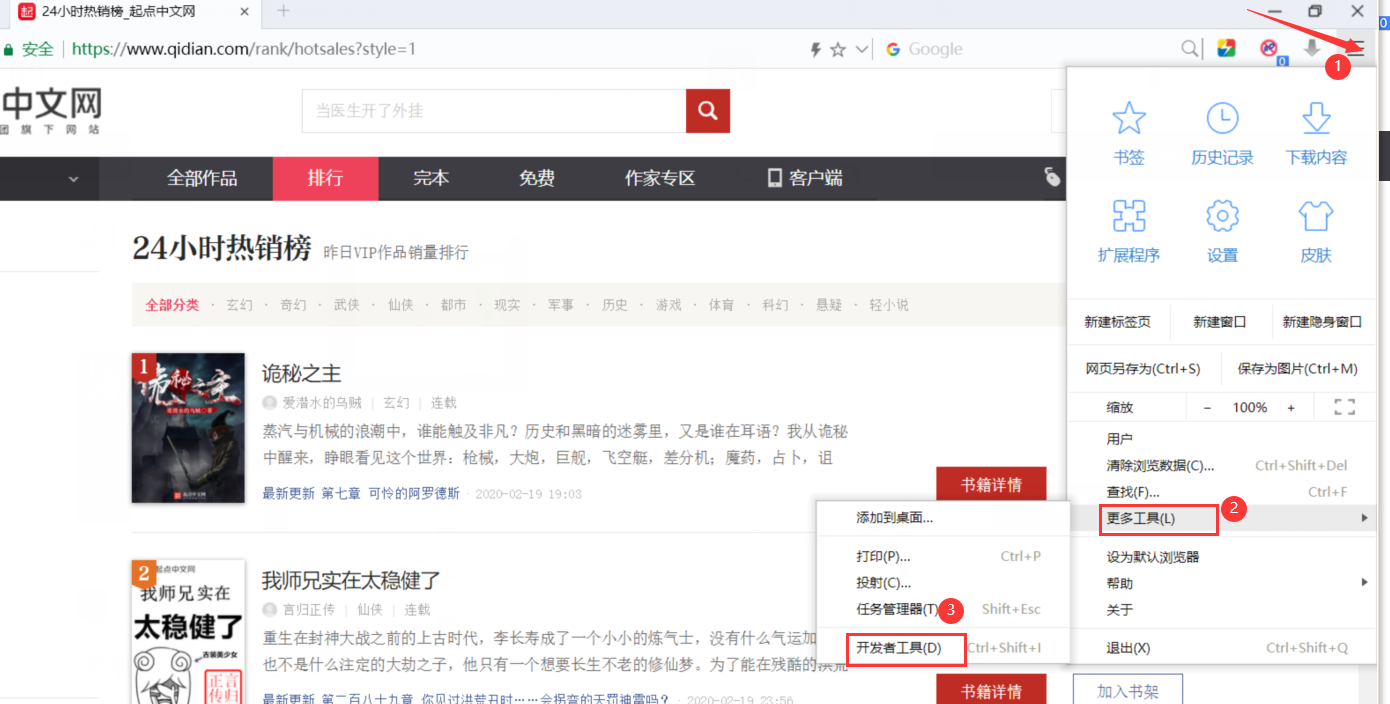
Click refresh page to find the html code of the page response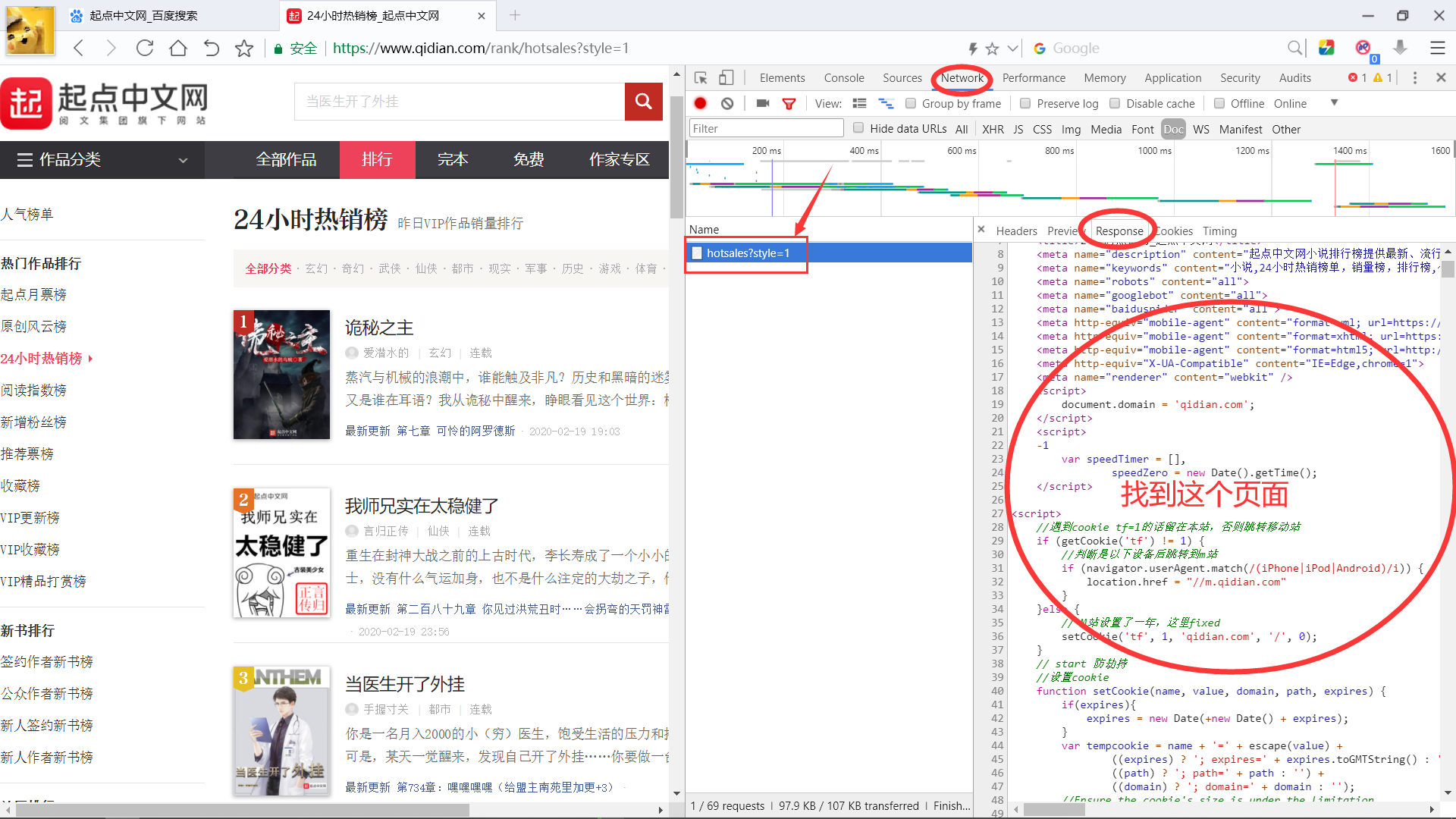
Click the arrow in the upper right corner, and then move the mouse to the information column of the novel. Click, and you will see that the code box on the right will automatically locate the corresponding code of the information.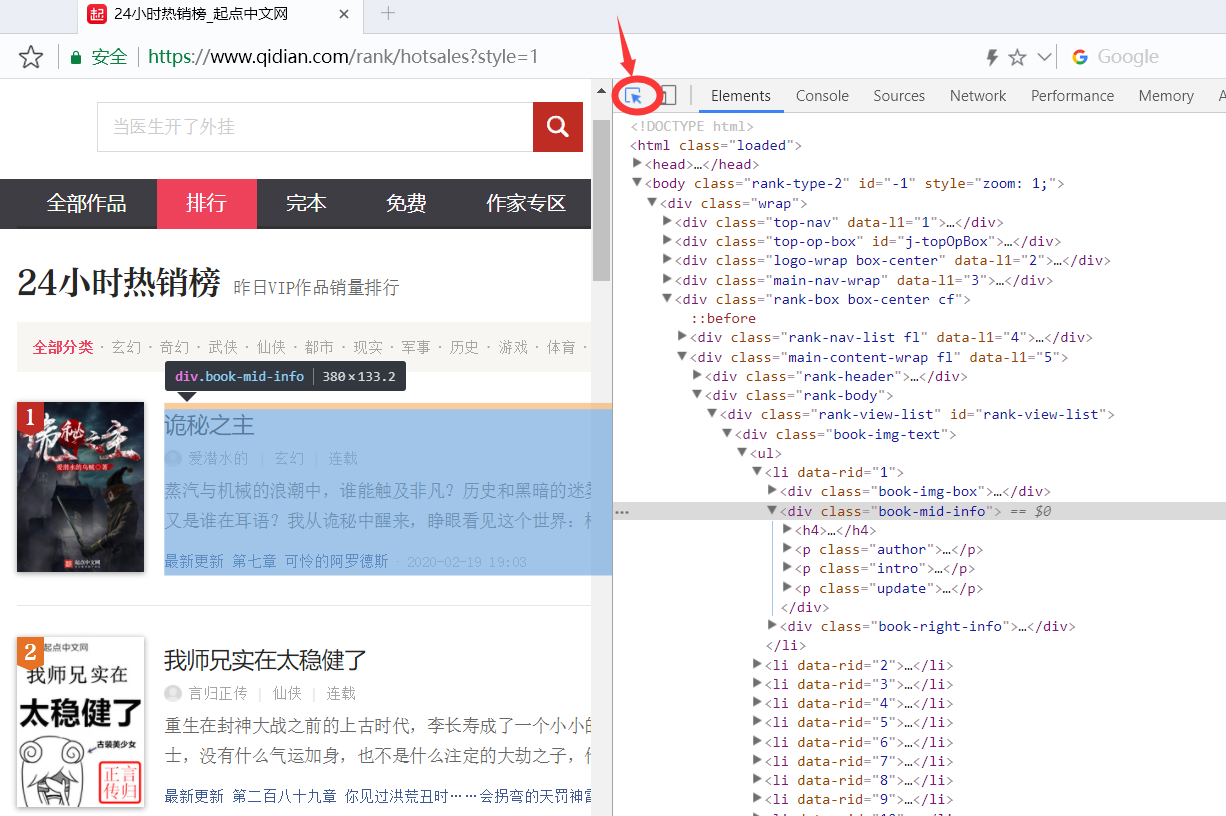
We can see that there are four labels corresponding to the information of this novel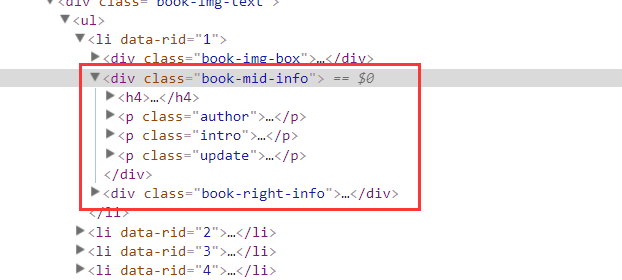 Expand the tag to see the contents. Next, we just need to create a crawler to get the response and extract the information we want
Expand the tag to see the contents. Next, we just need to create a crawler to get the response and extract the information we want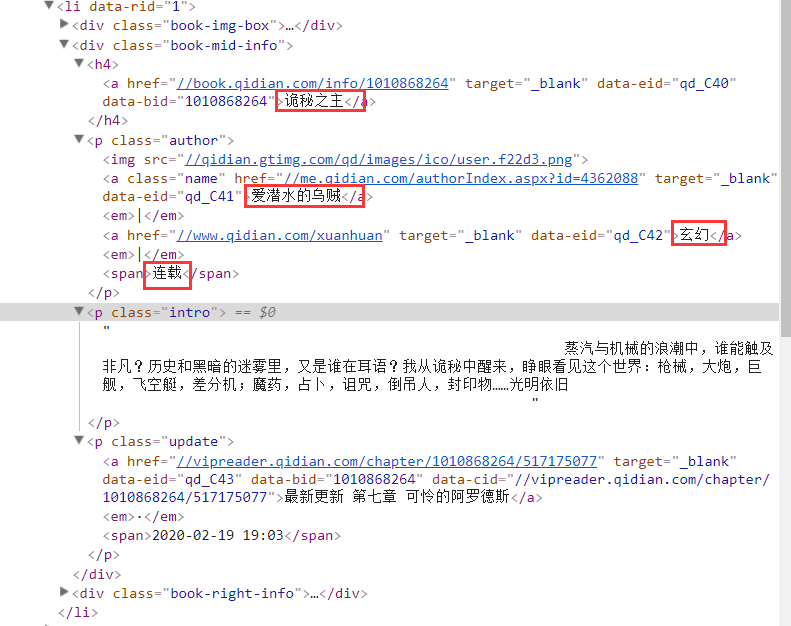
4, Implement crawler
Open the crawler project we created earlier, and create the crawler file in the spider directory, which is required for importing
from scrapy import Request from scrapy.spiders import Spider
Create a crawler class that inherits from Spider, including crawler name, target page, resolution method
class HotSaleSpider(Spider): name = "hot" #Reptile name start_urls = ["https://www.qidian.com/rank/hotsales?style=1"]#Destination website address def parse(self, response):#For data analysis pass
Notice that the parameter of the parse method is response. This is because we can get the response of the web page automatically by using the crawler framework. We don't need to write another code to send a request to the web page. We have already sent a request and returned the response directly in the inside of the summary.
The following figure shows the structure of the summary framework. What we need to do is to complete the spider part: extract the information after getting the response of the web page. Completed 1-6 work inside the reptile.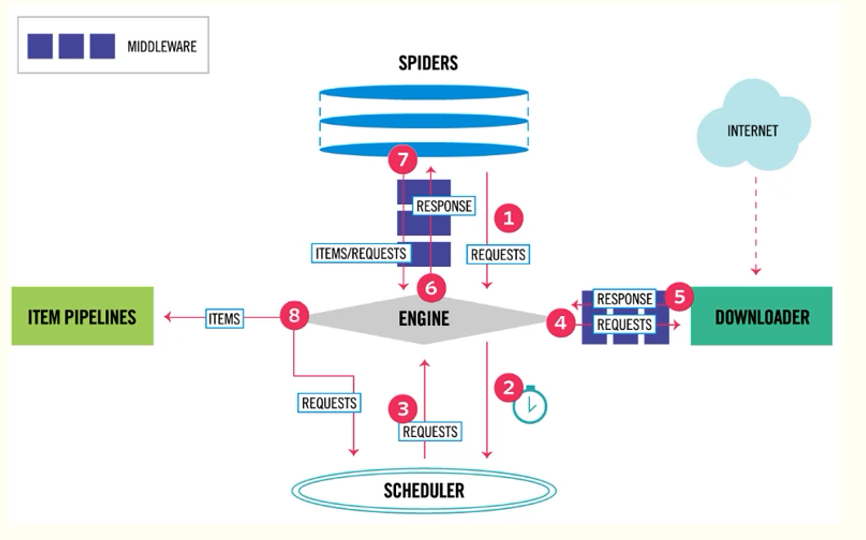
So we focus on the parse method. Based on our previous web page analysis, we use the xpath method to extract information.
First, we navigate to class = "Book mid info", where the information of each novel is saved under the "Book mid info" class.
list_selector = response.xpath("//div[@class='book-mid-info']")
Then traverse each novel to get all kinds of information. The same way to locate is to check the label where the information is located. The title of the novel "master of mysteries" is saved in the a tag under the h4 tag in the "Book mid info" class, and the author of the novel "squid loving diving" is saved in the a tag under the p tag in the "Book mid info" class.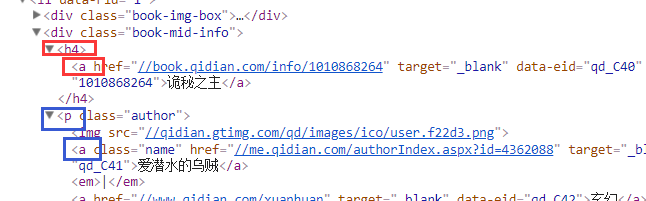
for one_selector in list_selector: # Access to novel information name = one_selector.xpath("h4/a/text()").extract()[0] #Extract the text under the current positioning author = one_selector.xpath("p[1]/a[1]/text()").extract()[0] type = one_selector.xpath("p[1]/a[2]/text()").extract()[0] form = one_selector.xpath("p[1]/span/text()").extract()[0]
Finally, a dictionary is defined to save the information of each novel and return it through the generator:
# Keep the novel information as a dictionary hot_dict = { "name":name, "author":author, "type":type, "form":form } yield hot_dict # Generator returns information of each novel
For the meaning of yield keyword, please refer to: Python keyword: yield generator
Full code:
#!/usr/bin/env python # -*- coding:utf-8 -*- #@Time : 2020/2/20 11:45 #@Author: bz #@File : qidian_spider.py from scrapy import Request from scrapy.spiders import Spider class HotSaleSpider(Spider): name = "hot" #Reptile name start_urls = ["https://www.qidian.com/rank/hotsales?style=1"]#Destination website address def parse(self, response):#For data analysis #Using xpath to locate list_selector = response.xpath("//div[@class='book-mid-info']") for one_selector in list_selector: # Access to novel information name = one_selector.xpath("h4/a/text()").extract()[0] #Extract the text under the current positioning author = one_selector.xpath("p[1]/a[1]/text()").extract()[0] type = one_selector.xpath("p[1]/a[2]/text()").extract()[0] form = one_selector.xpath("p[1]/span/text()").extract()[0] # Keep the novel information as a dictionary hot_dict = { "name":name, "author":author, "type":type, "form":form } yield hot_dict # Generator returns information of each novel
5, Run crawler
Go to the folder where you created the project before, and run the crawler and save the information to the qidianhot.csv file in the folder by entering the crawler hot - O qidianhot.csv
After running the crawler, open qidianhot.csv to see the crawling information