brief introduction
In addition to the advantages of the single node scheme, the victorimetrics cluster scheme can also achieve horizontal capacity expansion. When there is a large amount of data storage, the victorimetrics cluster scheme is a good choice.
The official recommendation is to capture data points below 100w/s and use the single node version. The single node version can save more CPU, memory and disk resources.
However, when you encounter the following problems, you can consider the cluster scheme:
Too high grab data point: greater than 100 w/s Data point capture(If lable Too much content,Will be lower than this value)
Massive data storage: the capacity of single disk can not meet the demand for longer-term storage and massive data storage
For higher performance: higher write and query performance is required
Native high availability: VictoriaMetrics Cluster scheme, native support, high availability
Multi tenant: want data multi tenant management
Note: there is no special statement below. Victoria metrics is abbreviated to VM.
Compared with Thanos, VictoriaMetrics is mainly a local full volume persistent storage scheme with horizontal expansion.
The following is a brief introduction to the functions of various components of the VM cluster version. Only through these components can the VM cluster scheme be completed.
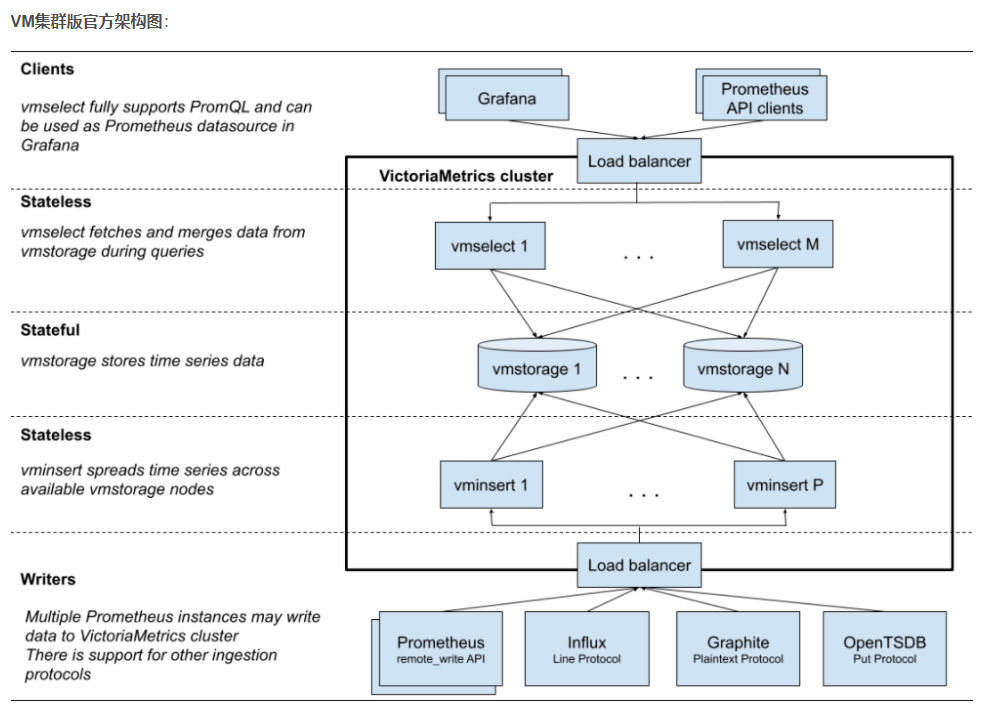
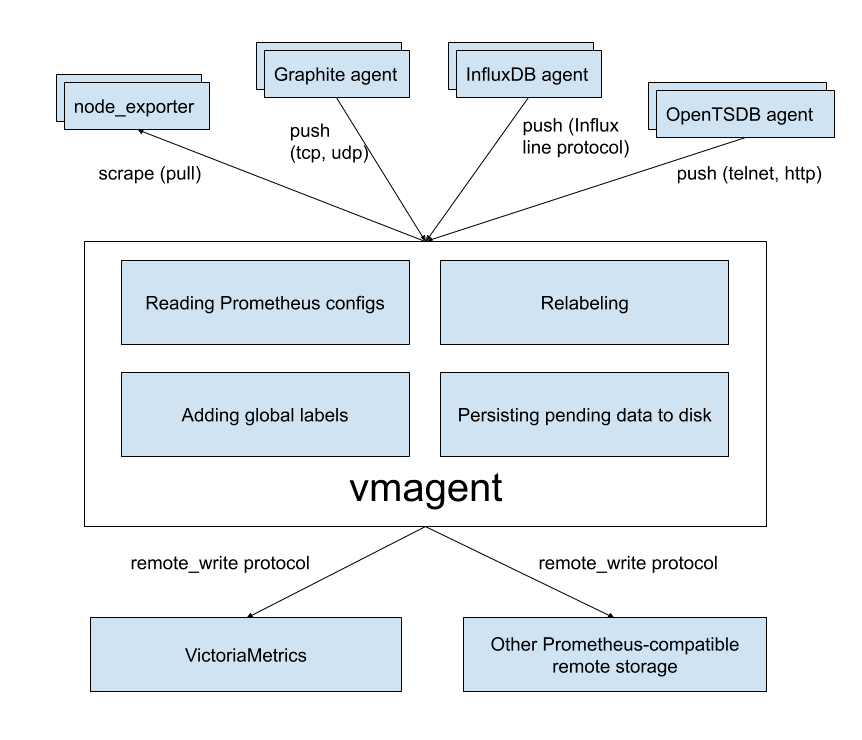
Component services and roles:
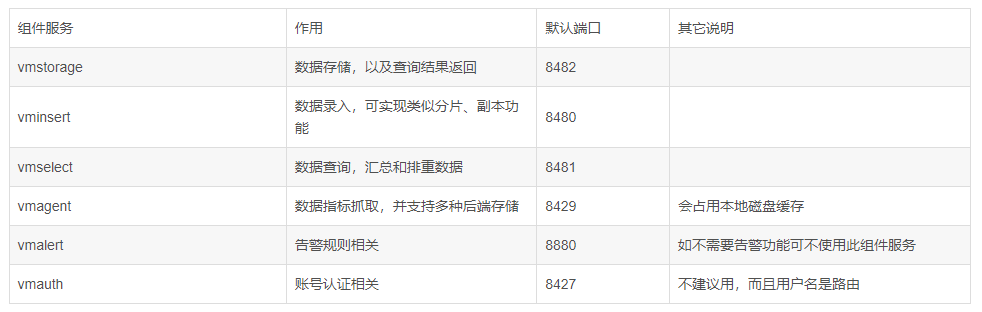
About startup parameters:
The key startup parameters of vmstorage, vminsert and vmselect components need little attention. The key parameters will be described later.
multi-tenancy
The VM cluster version supports the concept of multi tenancy. Different types of data can be put into different tenants (namespaces). Each tenant is distinguished in the requested url by {accountID or accountID:projectID. Of which:
accountID and projectID: yes[0 .. 2^32)Any integer of, projectID Can not be written. The default value is 0 Creation time: automatically created when data is entered for a tenant for the first time Performance: the number of tenants does not affect performance. It mainly depends on the total active time series of all tenants. The data of each tenant is evenly distributed in the back end vmstorage storage Isolation: cannot query across tenants
API example
The API usage method is basically the same as that of VM single node version, mainly adding {tenant and component service names,
VM Cluster version querying API Format: http://<vmselect>:8481/select/<accountID>/prometheus/<suffix> Take the host load query as an example to compare the differences: # Prometheus&VM Single node querying API http://127.0.0.1:9090/api/v1/query?query=node_load15 # Query API for VM cluster http://127.0.0.1:8481/select/6666/prometheus/api/v1/query?query=node_load15
Copy, slice and HA
4.1 implementation mode
Here is the focus of this article! Please watch it several times.
VM cluster version can realize the functions of replica and fragmentation to ensure data redundancy and horizontal expansion. It is mainly realized by the cooperation of several component services of VM cluster version.
vmagent: target sharing and self redundant fetching
1)vmagent: target Sharing and self redundant grab function promscrape.cluster.membersCount,appoint target cover vmagent How many grab groups are divided into promscrape.cluster.memberNum,Specify current vmagent,Grab assignment target grouping promscrape.cluster.replicationFactor,single target How many vmagent Grab. Redundant data will be generated here. This parameter is mainly used to ensure vmagent High availability of 2)vminsert: Select back-end storage (fragmentation) and control the number of copies (copies) for fixed time series by algorithm replicationFactor,Open copies and control the number of copies, i.e. how many copies to send vmstorage Insert the same sample data 3)vmstorage: Data storage, vmstorage There is no interaction between nodes. They are independent individuals and only rely on the upper layer vminsert,Generate copies and shards dedup.minScrapeInterval,vmagent Will produce replicationFactor This parameter is required to remove redundant data 4)vmselect: Data summary and return, when vminsert After opening the copy, vmselect Must be set dedup.minScrapeInterval dedup.minScrapeInterval,Remove duplicate data at a specified time, replicationFactor,When replicationFactor=N,Appear most in N-1 individual vmstorage When unavailable or slow response, vmselect The query is ignored directly, which improves the query efficiency
be careful:
After opening replicas or modifying the number of replicas (replication factor, RF for short), some data may be lost.
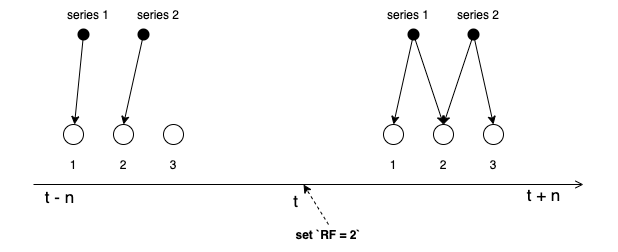
The following shows that the data has been collected before the replica is opened, after the replica is opened (RF=2), and vmselect specifies the replicationFactor parameter,
vmselect will treat all data as having a copy, but RF=2 has not opened a copy to collect data for some time.
When checking the series1 data before t, node 1 suddenly fails or the response is slow. vmselect will think that node 2 has replica data. In fact, there is no replica before t, so series1 will lose the data of node 1. As shown below:
4.2 grouping and slicing principle
1) Slice
If there are multiple vmstorage nodes behind vminsert, vminsert will fragment (or scatter) the data. Vminsert mainly selects the vmstorage node through consistent hash. The specific implementation is as follows:
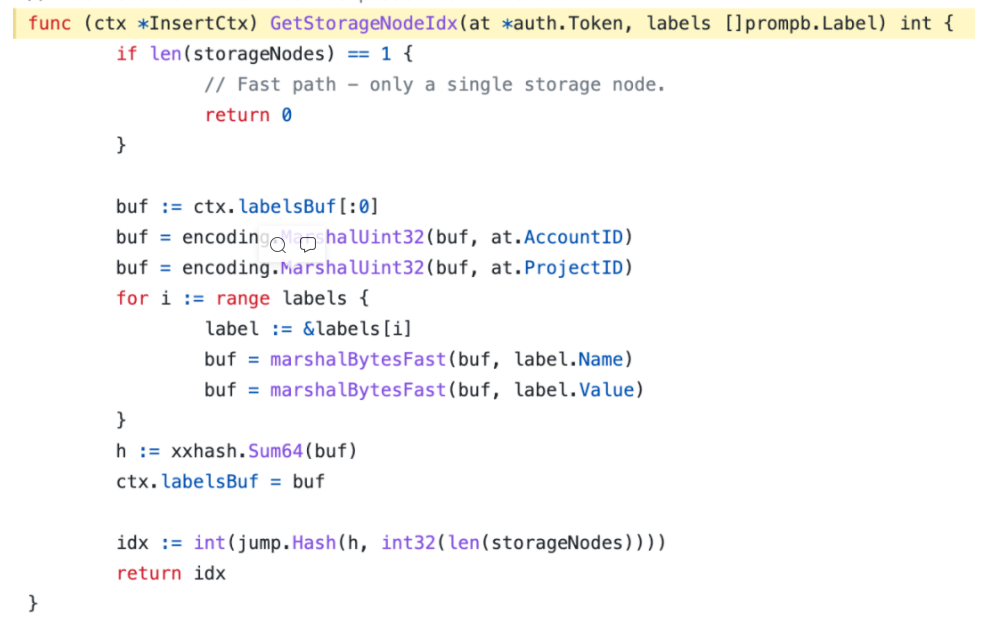
https://github.com/VictoriaMetrics/VictoriaMetrics/blob/38065bec7b1f7d5880f9e0080093cdee6778013b/app/vminsert/netstorage/insert_ctx.go#L158
2) Grouping
Vmagent grouping method: judge whether it is the target to be captured by the current vmagent through the four parameter identification sets, total number of group members, current member number and number of copies passed in by vmagent. The specific implementation method is as follows:
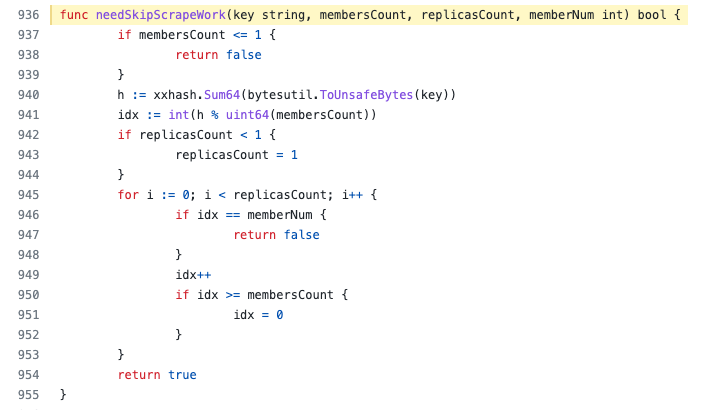
https://github.com/VictoriaMetrics/VictoriaMetrics/blob/f77dde837a043da1e628dd4390da43f769d7621a/lib/promscrape/config.go#L936
Safety certification
At present, only vmagent has its own httpauth username,httpAuth.password is the basic authentication method, but vmselect, vminsert and vmstorage, which need authentication function most, do not, especially vmselect with vmui.
The official explanation is that vmselect, vminsert and vmstorage generally solve the authority authentication at the upper level. Moreover, because of multiple tenants, each tenant should have its own account password, so there is no global basic account authentication, and there is no plan to develop it.
There is an official vmauth. The authentication mode is relatively simple, and the account name needs to be used as the routing identification. It is impossible to access multiple component services with the same account. At present, it is recommended to use nginx as the basic account authentication.
Refer to issues:
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/456
Installation steps
The following is a brief demonstration of the steps to build a VM cluster version:
# Configuration variable VM_HOME='/data/victoria-metrics' MEM_LIMIT='128MB' #Memory usage limit VMSOTRAGE_PORT='8482' #vmstorage listening port VMSOTRAGE_INSERT_PORT='8400' #vmstorage is the listening port for vminsert VMSOTRAGE_SELECT_PORT='8401' #vmstorage is the listening port for vmselect VMINSERT_PORT='8480' #vminsert listening port VMSELECT_PORT='8481' #vmselect listening port VMAGENT_PORT='8429' #vmagent listening port REPLICATION_COUNT='2' #Number of copies SELECT_STORAGE_NODE_LIST='' INSERT_STORAGE_NODE_LIST='' NODE_LIST='192.168.1.100,192.168.1.101,192.168.1.102,192.168.1.103' for NODE_IP in $(echo ${NODE_LIST} | awk '{split($0,arr,",");for(i in arr) print arr[i]}') do INSERT_STORAGE_NODE_LIST="${INSERT_STORAGE_NODE_LIST}\"${NODE_IP}:${VMSOTRAGE_INSERT_PORT}\"," SELECT_STORAGE_NODE_LIST="${SELECT_STORAGE_NODE_LIST}\"${NODE_IP}:${VMSOTRAGE_SELECT_PORT}\"," done # Create program directory mkdir -p ${VM_HOME}/{bin,logs,data,config} # Start vmstorage service (all nodes running) nohup ${VM_HOME}/bin/vmstorage -retentionPeriod=365d \ -storageDataPath=${VM_HOME}/data/vmstorage \ -memory.allowedBytes=${MEM_LIMIT} \ -httpListenAddr=":${VMSOTRAGE_PORT}" \ -vminsertAddr=":${VMSOTRAGE_INSERT_PORT}" \ -vmselectAddr=":${VMSOTRAGE_SELECT_PORT}" \ -dedup.minScrapeInterval=30s \ > ${VM_HOME}/logs/vmstorage.log 2>&1 & # Start vminsert service (all nodes are running) nohup ${VM_HOME}/bin/vminsert -replicationFactor=2 \ -storageNode=${INSERT_STORAGE_NODE_LIST} \ -memory.allowedBytes=${MEM_LIMIT} \ -httpListenAddr=":${VMINSERT_PORT}" \ > ${VM_HOME}/logs/vminsert.log 2>&1 & # Start vmselect service (all nodes are running) nohup ${VM_HOME}/bin/vmselect -dedup.minScrapeInterval=30s \ -replicationFactor=${REPLICATION_COUNT} \ -storageNode=${SELECT_STORAGE_NODE_LIST} \ -memory.allowedBytes=${MEM_LIMIT} \ -httpListenAddr=":${VMSELECT_PORT}" \ > ${VM_HOME}/logs/vmselect.log 2>&1 & # Start vmagent service (all nodes are running) VM_INSERT_URL="http://localhost:${VMINSERT_PORT}" ACCOUNT_ID='6666' #Tenant ID MEMBER_NUM=0~3 #Each node is different. The value range is 0~(membersCount)-1) nohup ${VM_HOME}/bin/vmagent -promscrape.cluster.membersCount=4 \ -promscrape.cluster.memberNum=${MEMBER_NUM} \ -promscrape.cluster.replicationFactor=${REPLICATION_COUNT} \ -promscrape.suppressScrapeErrors \ -remoteWrite.tmpDataPath=${VM_HOME}/data/vmagent \ -remoteWrite.maxDiskUsagePerURL=1GB \ -memory.allowedBytes=${MEM_LIMIT} \ -httpListenAddr=":${VMAGENT_PORT}" \ -promscrape.config=${VM_HOME}/config/prometheus.yml \ -remoteWrite.url=${VM_INSERT_URL}/insert/${ACCOUNT_ID}/prometheus/api/v1/write \ > ${VM_HOME}/logs/vmagent.log 2>&1 &
You can access the following address to enter the vmui interface:
http://192.168.1.100:8481/select/6666/vmui
So far, the VM cluster has been built, and simple performance data can be viewed through the vmui.
Capacity expansion scheme
When a VM cluster encounters a bottleneck, it can be expanded according to the following scenarios:
Query speed is too slow: vmselect It is a stateless service with the same configuration information. This problem can be solved by directly expanding the capacity. Slow data entry: vminsert and vmselect Just expand the capacity directly. Insufficient capacity: vmstorage Horizontal expansion to solve this problem because vmstorage It is a state-of-the-art service, and capacity expansion should be combined with upstream component services. vmstorage The configuration of each node is the same, and the capacity can be expanded directly. At the same time, the upstream vmselect and vminsert Storage list for(-storageNode)Update and restart all. Too large grab sample size: capacity expansion vmagent Yes, but you need to reassign all vmagent yes target Grouping parameters of,-promscrape.cluster.membersCount=N Increase the total number of components,-promscrape.cluster.memberNum=(0~N-1) current vmagent The group number of the node. Restart all after modification vmagent. VM The advantage of the cluster version is flexibility, where the performance cannot be expanded, what kind of host the component service runs on, and make full use of system resources.
failover processing
In the VM cluster version, how can you handle the failure of various component services? The following is an analysis of key components one by one:

resource planning
Each component of VM cluster can be put on the appropriate hardware device according to its own characteristics to give full play to the hardware capability.
According to the business monitoring volume, you can simply estimate the CPU and memory resources required:

Note: the above is only an estimate. It is recommended to test according to your own business type and expand resources before going online until the cluster becomes stable.
summary
This article mainly introduces you to the VictoriaMetrics cluster scheme, which can be easily built and used. Compared with the VictoriaMetrics single node scheme, the cluster scheme has higher architecture complexity, but it can bring more flexible usage, better expansion, accommodate a larger amount of data and higher resource utilization.
Generally speaking, when the business encounters problems such as performance, capacity and cost with VictoriaMetrics/Prometheus single node, VictoriaMetrics cluster solution may solve your pain point and bring more efficient and stable data display to the business.
reference material:
Original link: https://blog.csdn.net/ZVAyIVqt0UFji/article/details/122422129
https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/1207
https://www.joyk.com/dig/detail/1558605608214852?page=3