Chapter 12 loop detection
Word bag model (BoW)
- Determine the words of BoW to form a dictionary.
- Identify what concepts are defined in a dictionary in an image, thus converting an image into a vector description.
- Compare the similarities described in the previous step.
Dictionaries
Dictionary structure
- Dictionary generation problem is similar to a clustering problem. K-means method is commonly used in clustering problem. According to K-means, we can cluster a large number of feature points extracted into a dictionary containing k words.
- The storage structure of the dictionary:
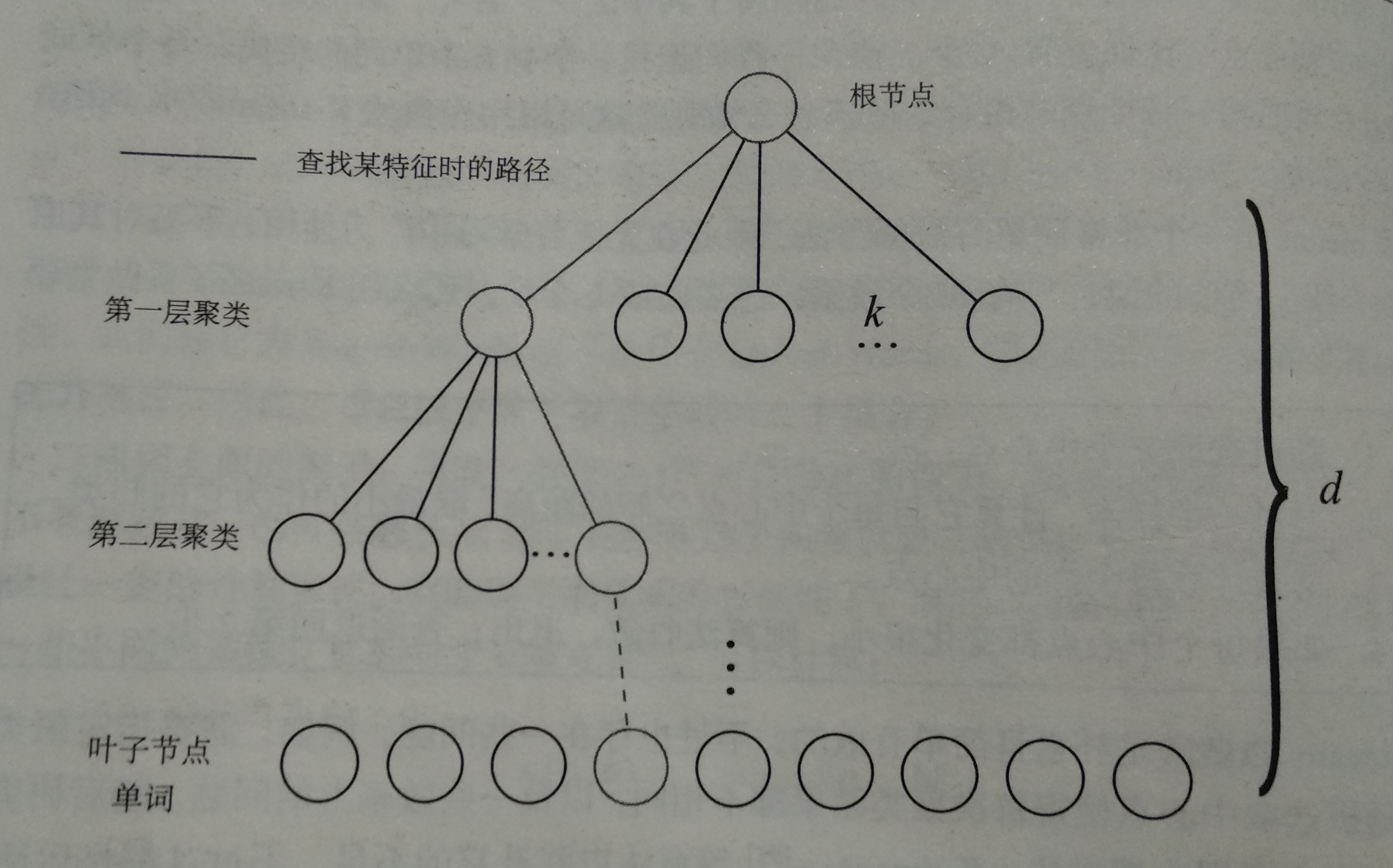
A k-tree is used to express dictionary. Suppose we have N feature points and want to construct a tree with a depth of d and a bifurcation of K at a time. Then we do the following:
- At the root node, all samples are grouped into k-classes by K-means, and the first layer is obtained.
- For each node in the first layer, the samples belonging to the node are clustered into N classes to get the next layer.
- By analogy, the leaf layer is finally obtained. The leaf layer is called Words.
- After the above steps, a k-branch tree with a depth of d is constructed, which can contain kd words. When searching for a particular word, only comparing it with the clustering center of each intermediate node (a total of d times), the final word can be found, which ensures the efficiency of logarithmic search.
Practice: Creating Dictionaries
- Install BoW library, download address: https://github.com/rmsalinas/DBow3
It's a cmake project, compile and install it. - Complete code:
feature_training.cpp
//2019.08.18
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main(int argc,char **argv)
{
//read the image
cout << "reading images..." << endl;
vector<Mat> images;
for(int i=0;i<10;i++)
{
string path = "../data/" + to_string(i+1) + ".png";
images.push_back(imread(path));
}
//detect ORB features
cout <<"detecting ORB features..."<<endl;
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;
for(Mat& image:images)
{
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute(image,Mat(),keypoints,descriptor);
descriptors.push_back(descriptor);
}
//create vocabulary
cout<<"creating vocabulary..."<<endl;
DBoW3::Vocabulary vocab;//Construct dictionary generator objects, default k=10,d=5, or programmer specifies
vocab.create(descriptors);
cout<<"vocabulary info:"<<vocab<<endl;
vocab.save("vocabulary.yml.gz");
cout<<"done"<<endl;
return 0;
}
CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++11 -O3" )
# opencv
find_package( OpenCV REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
Operation results:
Computation of Similarity
Theoretic part
We hope to assess the distinctiveness or importance of words and give them different weights to achieve better results. In text retrieval, a common method is called TF-IDF(Term Frequency-Inverse Document Frequency).
The idea of the TF part is that a word often appears in an image, and its discrimination is high.
The idea of IDF is that the lower the frequency of a word appearing in a dictionary, the higher the degree of discrimination when classifying images.
In the lexical bag model, the IDF part can be considered when building dictionaries. We count the proportion of the number of features in a leaf node wi to the number of features as part of the IDF. Assuming that the number of all features is n and the number of features in wi is ni, the IDF of the word is: IDFi=log(n/ni)
The smaller the number of feature points used to describe a word, the more pure the word is, the better the distinction is.
On the other hand, the TF part refers to the frequency of a feature appearing in a single image. Suppose the word wi appears ni times in image A, and the total number of words is n, then TF is: TFi=ni/n.
In an image, the greater the number of times a word appears in comparison with the number of times it appears in all images, the higher the word discrimination.
The weight of a word is defined as the product of TF and IDF:
etai = TFi×IDFi
Considering the weight, for an image A, its feature points can correspond to many words, which make up its Bag-of-Words:
A = {(w1,etai),(w2,etai),...,(wN,etaN)} = vA
Because similar features may fall into the same class, there will be a large number of zeros in actual ** vA. This vector vA** is a sparse vector whose non-zero parts indicate which words are contained in image A and whose values are TF-IDF.
Given vA and vB, the difference between them is calculated by L1 norm:
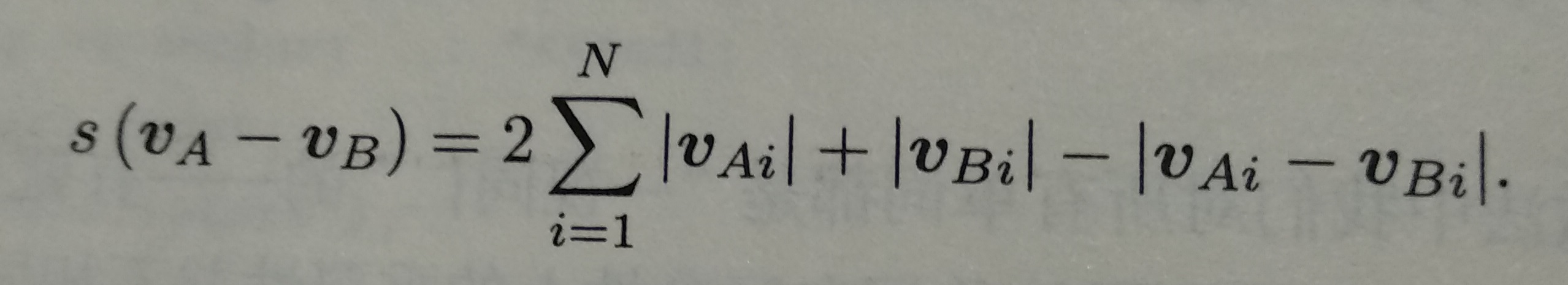
Practice: Similarity Computation
loop_closure.cpp
//2019.08.18
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main(int argc,char **argv)
{
//read the images and database
cout << "reading database"<<endl;
DBoW3::Vocabulary vocab("../vocabulary.yml.gz");
if(vocab.empty())
{
cerr <<"Vocabulary does not exist."<<endl;
return 1;
}
cout << "reading images..." << endl;
vector<Mat> images;
for(int i=0;i<10;i++)
{
string path = "../data/" + to_string(i+1) + ".png";
images.push_back(imread(path));
}
//NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may leed to overfitting.
//detect ORB features
cout <<"detecting ORB features..."<<endl;
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;
for(Mat& image:images)
{
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute(image,Mat(),keypoints,descriptor);
descriptors.push_back(descriptor);
}
//we can compare the images directly or we can compare one image to a database
//images
cout<<"comparing images with images"<<endl;
for(int i=0;i<images.size();i++)
{
DBoW3::BowVector v1;
vocab.transform(descriptors[i],v1);
for(int j=i;j<images.size();j++)
{
DBoW3::BowVector v2;
vocab.transform(descriptors[j],v2);
double score = vocab.score(v1,v2);
cout<<"image "<<i<<" vs image "<<j<<" : "<< score<<endl;
}
cout<<endl;
}
//or with database
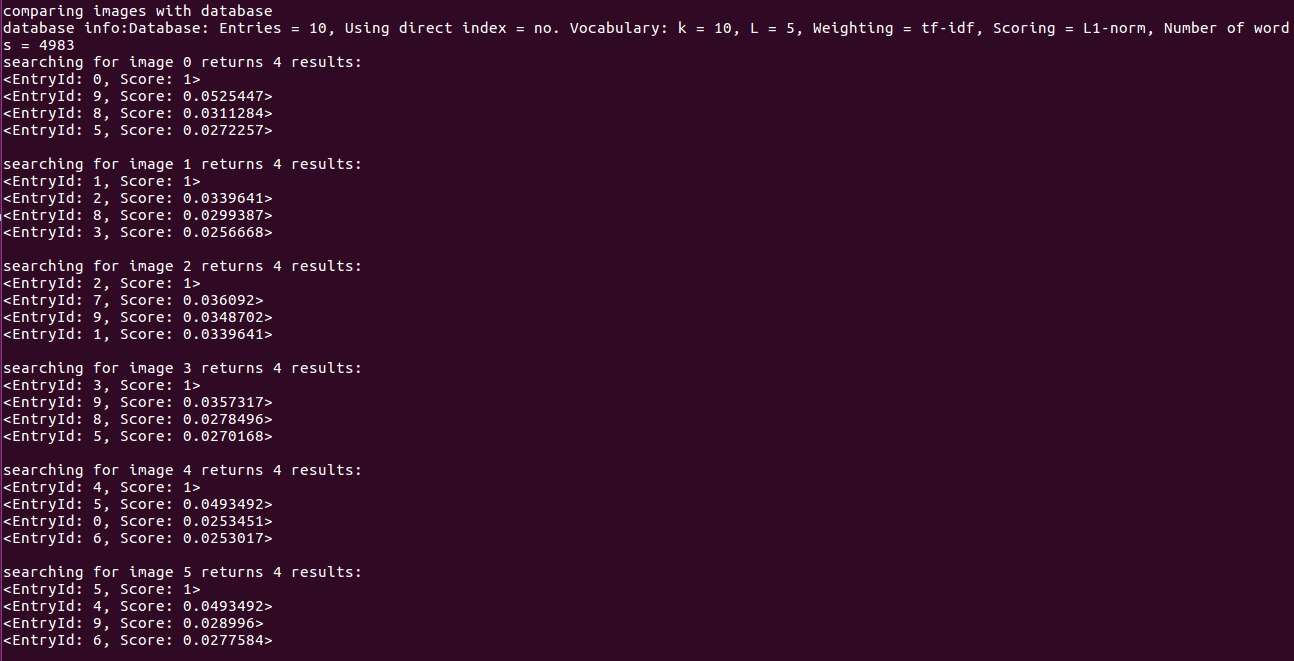
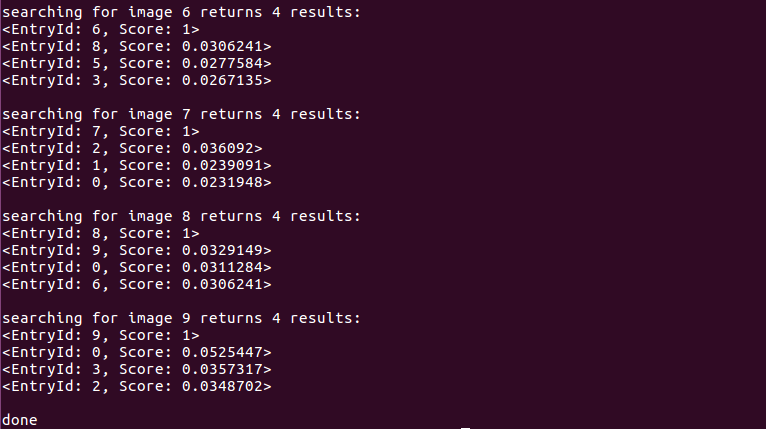
cout<<"comparing images with database"<<endl;
DBoW3::Database db(vocab,false,0);
for(int i=0;i<descriptors.size();i++)
{
db.add(descriptors[i]);
}
cout<<"database info:"<<db<<endl;
for(int i=0;i<descriptors.size();i++)
{
DBoW3::QueryResults ret;
db.query(descriptors[i],ret,4);//max result=4
cout<<"searching for image "<<i<<" returns "<<ret<<endl<<endl;
}
cout<<"done"<<endl;
return 0;
}
CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++11 -O3" )
# opencv
find_package( OpenCV REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
Operation results:
Processing of similarity score
The robustness of absolute similarity score is not very good. We take a prior similarity s(vt,vt-deltat), which represents the similarity between the key frame image of a certain time and the key frame of the previous time. Then, other scores are normalized according to this value: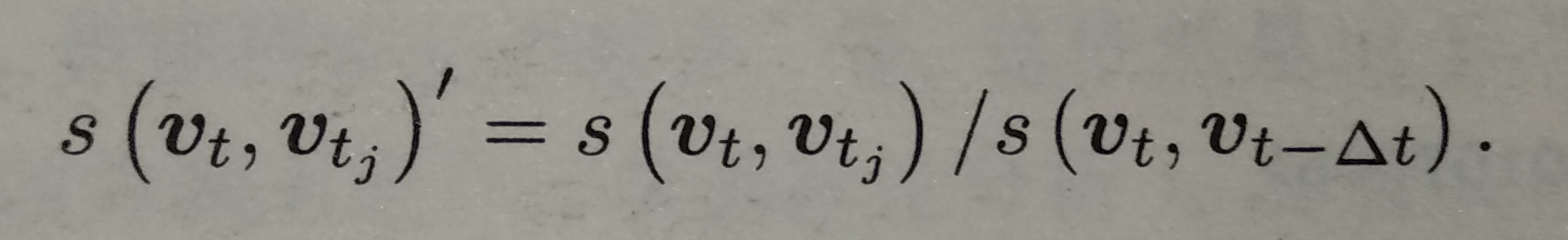
If the similarity between the current frame and a previous key frame is more than three times the similarity between the current frame and the previous key frame, it is considered that there may be loops.
Key Frame Processing
If the key frames are selected too close, the similarity between the two key frames will be too high, and it is not easy to detect the loops in historical data. For example, the detection results are often n frames and n-2 frames, and n-3 frames are the most similar. This kind of result seems too trivial and meaningless. In practice, it is better to use sparse frames for loopback detection, which are different from each other and can cover the whole environment.
On the other hand, if loops are successfully detected, for example, in frames 1 and n. It is very likely that frame n+1, frame n+2 will form a loop between frame 1 and frame n+1. However, it is helpful for trajectory optimization to confirm that there are loops between the first frame and the n frame, while the next N + 1 frame and N + 2 frame will form loops with the first frame. Therefore, we will aggregate "similar" loops into a class, so that the algorithm does not repeatedly detect the same kind of loops.
Verification after detection
The loop detection algorithm of word bags relies entirely on the appearance without using any geometric information, which makes images with similar appearance easy to be regarded as loops. And because word bags don't care about word order, they only care about the expression of words, which is more likely to cause perception bias. So, after loop detection, we usually have another verification step.
There are many validation methods. One is to set up a caching mechanism for loops, which considers that single detected loops are not enough to constitute good constraints, and only those loops that have been detected for a period of time are considered correct loops. This can be regarded as time consistency detection.
Another method is consistency detection in space, i.e. feature matching of two frames detected by loopback to estimate camera motion. Then, the motion is put into the previous pose map to check whether there is a big discrepancy with the previous estimates. In short, the verification part is usually necessary, but how to implement it is a matter of opinion.