Mainly learn the http module requests, which is mainly used to send requests and obtain responses. There are many alternative modules in this module, such as urlib module, but the requests module is most used in work. The code of requests is simple and easy to understand. Compared with the bloated urlib module, there will be less crawler code written with requests, And it will be simple to implement a function. Therefore, the requests module is very important in python. It is recommended that you master the use of this module.
requests module
Let's learn how to implement our crawler in code
1. Introduction to requests module
requests file http://docs.python-requests.org/zh_CN/latest/index.html
**1.1 functions of requests module:**
send out http Request, get response data
1.2 requests module is a third-party module that needs to be installed in your python (virtual) environment
pip/pip3 install requests
1.3 requests module sends get requests
Requirements: through requests Send a request to Baidu home page to obtain the source code of the page
Run the following code and observe the printout
# 1.2. 1 - simple code implementation import requests # Destination url url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content print(response.text)
Knowledge points: master the get request sent by the requests module
2. response object
Observe the running results of the above code and find that there are a lot of random codes; This is because the character sets used in encoding and decoding are different; We try to use the following methods to solve the problem of Chinese garbled code
# 1.2.2-response.content import requests # Destination url url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content # print(response.text) print(response.content.decode()) # Pay attention here!
1.response.text yes requests Module according to chardet The result of decoding the encoded character set inferred by the module
2.The strings transmitted over the network are bytes Type, so response.text = response.content.decode('Inferred coded character set')
3.We can search in the web source code charset,Try to refer to the coded character set and note that there are inaccuracies
2.1 response.text and response The difference between content:
response.text
Type: str
Decoding type: requests Module automatically according to HTTP The header makes an informed guess about the encoding of the response, which is the inferred text encoding
response.content
Type: bytes
Decoding type: not specified
2.2 through response Content is decode d to solve Chinese garbled code
response.content.decode() default utf-8
response.content.decode("GBK")
Common coded character sets
- utf-8
- gbk
- gb2312
- ascii (pronunciation: ask code)
- iso-8859-1
2.3 other common properties or methods of response object
response = requests. In get (URL), response is the response object obtained by sending the request; In the response response object, there are other common properties or methods besides text and content to obtain the response content:
response.url Responsive url;Sometimes it's responsive url And requested url Inconsistent response.status_code Response status code response.request.headers Response corresponding request header response.headers Response header response.request._cookies Response to corresponding request cookie;return cookieJar type response.cookies Responsive cookie(Yes set-cookie Action; return cookieJar type response.json()Automatically json The response content of string type is converted to python Object( dict or list)
# 1.2.3-response other common attributes import requests # Destination url url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content # print(response.text) # print(response.content.decode()) # Pay attention here! print(response.url) # Print the url of the response print(response.status_code) # Print the status code of the response print(response.request.headers) # Print the request header of the response object print(response.headers) # Print response header print(response.request._cookies) # Print the cookies carried by the request print(response.cookies) # Print the cookies carried in the response
3. The requests module sends a request
3.1 send request with header
We first write a code to get Baidu home page
import requests url = 'https://www.baidu.com' response = requests.get(url) print(response.content.decode()) # Print the request header information corresponding to the response request print(response.request.headers)
3.1. 1 thinking
What is the difference between the web source code of Baidu home page on the browser and the source code of Baidu home page in the code?
How to view the web source code:
Right click-View web page source code or
Right click-inspect
Contrast correspondence url What is the difference between the response content and the source code of Baidu home page in the code?
View corresponding url Method of response content:
Right click-inspect
click Net work
Tick Preserve log
Refresh page
see Name The same as the browser address bar url of Response
The source code of Baidu home page in the code is very few. Why?
We need to bring the request header
Review the concept of crawler, simulate browser, cheat server, and obtain content consistent with browser
There are many fields in the request header, including User-Agent Field is necessary to represent the operating system of the client and the information of the browser
3.1. 2 method of carrying request and sending request
requests.get(url, headers=headers)
headers Parameter receives the request header in dictionary form Request header field name as key,Field as value
3.1. 3 complete code implementation
Copy from browser User-Agent,structure headers Dictionaries; After completing the following code, run the code to see the results
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# Bring the user agent in the request header to simulate the browser to send the request
response = requests.get(url, headers=headers)
print(response.content)
# Print request header information
print(response.request.headers)
3.2 sending requests with parameters
We often find when using Baidu search url There will be one in the address ?,After the question mark is the request parameter, also known as the query string
3.2. 1 carry parameters in url
Make a request directly to the url with parameters
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
response = requests.get(url, headers=headers)
3.2. 2 carry parameter dictionary through params
1. Build request parameter dictionary
2. Bring the parameter dictionary when sending the request to the interface, and set the parameter dictionary to params
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# This is the target url
# url = 'https://www.baidu.com/s?wd=python'
# Is there a question mark in the end? The results are the same
url = 'https://www.baidu.com/s?'
# The request parameter is a dictionary, namely wd=python
kw = {'wd': 'python'}
# Initiate a request with request parameters and obtain a response
response = requests.get(url, headers=headers, params=kw)
print(response.content)
3.3 carrying cookie s in the headers parameter
Websites often take advantage of the in the request header Cookie Field to maintain the user access status, so we can headers Add to parameter Cookie,Simulate the request of ordinary users. We take github Take login as an example:
3.3.1 github login packet capture analysis
Open the browser and right-click-Check, click Net work,Tick Preserve log visit github Logged in url address https://github.com/login Enter the account password and click log in to access a user who needs to log in to get the correct content url,For example, click the in the upper right corner Your profile visit https://github.com/USER_NAME determine url After that, the number in the request header information required to send the request is determined User-Agent and Cookie
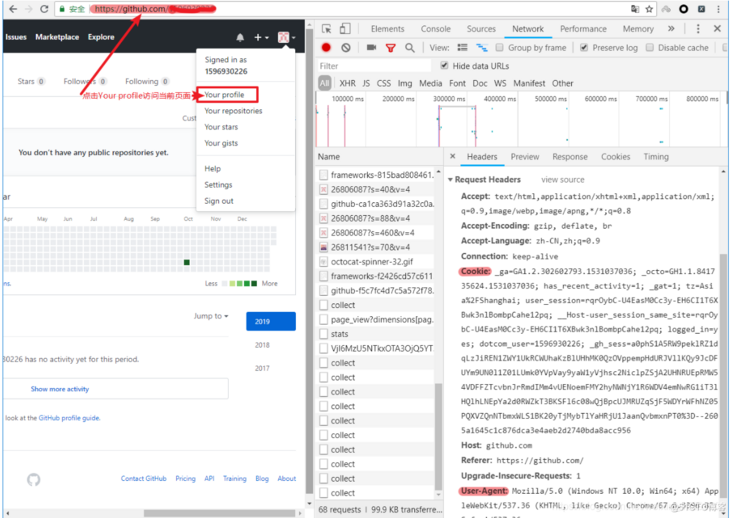
3.3. 2 completion code
Copy from browser User-Agent and Cookie The request header fields and values in the browser are the same as headers Must be consistent in parameters headers In the request parameter dictionary Cookie The value corresponding to the key is a string
import requests
url = 'https://github.com/USER_NAME'
# Construct request header dictionary
headers = {
# User agent copied from browser
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# Cookie s copied from the browser
'Cookie': 'xxx Here is a copy cookie character string'
}
# The cookie string is carried in the request header parameter dictionary
resp = requests.get(url, headers=headers)
print(resp.text)
3.3. 3 run code verification results
Search in the printed output title,html If the title text content in is yours github Account number, then it is successfully used headers Parameter carrying cookie,Get the page that can only be accessed after login
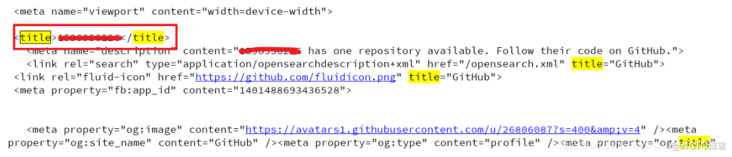
Knowledge points: master the cookie s carried in headers
3.4 use of cookie parameters
In the last section, we were headers Carried in parameter cookie,Special can also be used cookies parameter
cookies Parameter form: Dictionary
cookies = {"cookie of name":"cookie of value"}
The dictionary corresponds to the request header Cookie String, dividing each pair of dictionary key value pairs with semicolons and spaces
To the left of the equal sign is a cookie of name,corresponding cookies Dictionary key
Corresponding to the right of the equal sign cookies Dictionary value
cookies How to use parameters
response = requests.get(url, cookies)
take cookie Convert string to cookies Dictionary required for parameter:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
be careful: cookie Generally, there is an expiration time. Once it expires, it needs to be obtained again
import requests
url = 'https://github.com/USER_NAME'
# Construct request header dictionary
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# Construct cookie dictionary
cookies_str = 'From browser copy Come here cookies character string'
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# The cookie string is carried in the request header parameter dictionary
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
Knowledge points: master the use of cookie parameters
3.5 method of converting Cookie Jar object into cookie dictionary
use requests Acquired resposne Object with cookies Properties. The attribute value is a cookieJar Type, including the local settings of the opposite server cookie. How do we convert it to cookies What about the dictionary? Conversion method cookies_dict = requests.utils.dict_from_cookiejar(response.cookies) among response.cookies What is returned is cookieJar Object of type requests.utils.dict_from_cookiejar Function return cookies Dictionaries
Knowledge points: master the conversion method of cookieJar
last
If the article is helpful to you, please praise the author\
Refuse white whoring, start with me