The search engine must not default. ElasticSearch, which is often used in our project, is a search engine and is essential in our log system. ELK, as a whole, is basically standard for operation and maintenance. In addition, the bottom layer of the current search engine is based on Lucene.
Xiaobian recently encountered a demand. Because the data volume did not reach the level of using ElasticSearch, and he did not want to deploy a separate cluster, he was ready to implement a simple search service based on Lucene. Let's have a look.
background
Lucene is an open source library for full-text retrieval and search, supported and provided by the Apache Software Foundation. Lucene provides a simple but powerful application program interface, which can do full-text indexing and search. Lucene is now the most popular free Java information retrieval library.
The above explanation comes from Wikipedia. We only need to know that Lucene can carry out full-text indexing and search. The index here is a verb, which means that we can index and record data such as documents, articles or files. After indexing, we will query quickly.
Sometimes the word index is a verb, indicating that we want to index data. Sometimes it is a noun. We need to judge according to the context. The alphabet in front of Xinhua Dictionary or the catalogue in front of books are essentially indexes.
Access
Introduce dependency
First, we create a SpringBoot project, and then add the following contents to the pom file. The lucene version I use here is 7.2.1,
<properties>
<lucene.version>7.2.1</lucene.version>
</properties>
<!-- Lucene Core library -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- Lucene Parsing library -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- Lucene Additional analysis Libraries -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
Index data
Before using Lucene, we need to index some files, and then query them by keywords. Let's simulate the whole process. In order to facilitate us to simulate some data here, normal data should be loaded from the database or file. Our idea is as follows:
- Generate multiple entity data;
- Mapping entity data into Lucene document form;
- Index documents;
- Query documents according to keywords;
The first step is to create an entity as follows:
import lombok.Data;
@Data
public class ArticleModel {
private String title;
private String author;
private String content;
}
Let's write another tool class to index data. The code is as follows:
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LuceneIndexUtil {
private static String INDEX_PATH = "/opt/lucene/demo";
private static IndexWriter writer;
public static LuceneIndexUtil getInstance() {
return SingletonHolder.luceneUtil;
}
private static class SingletonHolder {
public final static LuceneIndexUtil luceneUtil = new LuceneIndexUtil();
}
private LuceneIndexUtil() {
this.initLuceneUtil();
}
private void initLuceneUtil() {
try {
Directory dir = FSDirectory.open(Paths.get(INDEX_PATH));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
writer = new IndexWriter(dir, iwc);
} catch (IOException e) {
log.error("create luceneUtil error");
if (null != writer) {
try {
writer.close();
} catch (IOException ioException) {
ioException.printStackTrace();
} finally {
writer = null;
}
}
}
}
/**
* Index a single document
*
* @param doc document information
* @throws IOException IO abnormal
*/
public void addDoc(Document doc) throws IOException {
if (null != doc) {
writer.addDocument(doc);
writer.commit();
writer.close();
}
}
/**
* Index a single entity
*
* @param model Single entity
* @throws IOException IO abnormal
*/
public void addModelDoc(Object model) throws IOException {
Document document = new Document();
List<Field> fields = luceneField(model.getClass());
fields.forEach(document::add);
writer.addDocument(document);
writer.commit();
writer.close();
}
/**
* Index entity list
*
* @param objects Instance list
* @throws IOException IO abnormal
*/
public void addModelDocs(List<?> objects) throws IOException {
if (CollectionUtils.isNotEmpty(objects)) {
List<Document> docs = new ArrayList<>();
objects.forEach(o -> {
Document document = new Document();
List<Field> fields = luceneField(o);
fields.forEach(document::add);
docs.add(document);
});
writer.addDocuments(docs);
}
}
/**
* Clear all documents
*
* @throws IOException IO abnormal
*/
public void delAllDocs() throws IOException {
writer.deleteAll();
}
/**
* Index document list
*
* @param docs Document list
* @throws IOException IO abnormal
*/
public void addDocs(List<Document> docs) throws IOException {
if (CollectionUtils.isNotEmpty(docs)) {
long startTime = System.currentTimeMillis();
writer.addDocuments(docs);
writer.commit();
log.info("Co index{}individual Document,Total time{} millisecond", docs.size(), (System.currentTimeMillis() - startTime));
} else {
log.warn("Index list is empty");
}
}
/**
* Get the field type according to the entity class object and map the lucene Field field
*
* @param modelObj Entity modelObj object
* @return Field mapping list
*/
public List<Field> luceneField(Object modelObj) {
Map<String, Object> classFields = ReflectionUtils.getClassFields(modelObj.getClass());
Map<String, Object> classFieldsValues = ReflectionUtils.getClassFieldsValues(modelObj);
List<Field> fields = new ArrayList<>();
for (String key : classFields.keySet()) {
Field field;
String dataType = StringUtils.substringAfterLast(classFields.get(key).toString(), ".");
switch (dataType) {
case "Integer":
field = new IntPoint(key, (Integer) classFieldsValues.get(key));
break;
case "Long":
field = new LongPoint(key, (Long) classFieldsValues.get(key));
break;
case "Float":
field = new FloatPoint(key, (Float) classFieldsValues.get(key));
break;
case "Double":
field = new DoublePoint(key, (Double) classFieldsValues.get(key));
break;
case "String":
String string = (String) classFieldsValues.get(key);
if (StringUtils.isNotBlank(string)) {
if (string.length() <= 1024) {
field = new StringField(key, (String) classFieldsValues.get(key), Field.Store.YES);
} else {
field = new TextField(key, (String) classFieldsValues.get(key), Field.Store.NO);
}
} else {
field = new StringField(key, StringUtils.EMPTY, Field.Store.NO);
}
break;
default:
field = new TextField(key, JsonUtils.obj2Json(classFieldsValues.get(key)), Field.Store.YES);
break;
}
fields.add(field);
}
return fields;
}
public void close() {
if (null != writer) {
try {
writer.close();
} catch (IOException e) {
log.error("close writer error");
}
writer = null;
}
}
public void commit() throws IOException {
if (null != writer) {
writer.commit();
writer.close();
}
}
}
With the tool class, we will write a demo to index the data
import java.util.ArrayList;
import java.util.List;
/**
* <br>
* <b>Function: </b><br>
* <b>Author: </b>@author Silence<br>
* <b>Date: </b>2020-10-17 21:08<br>
* <b>Desc: </b>None < br >
*/
public class Demo {
public static void main(String[] args) {
LuceneIndexUtil luceneUtil = LuceneIndexUtil.getInstance();
List<ArticleModel> articles = new ArrayList<>();
try {
//Index data
ArticleModel article1 = new ArticleModel();
article1.setTitle("Java the best in all the land");
article1.setAuthor("fans");
article1.setContent("This is an introduction to you Lucene Technical articles, must like comment forwarding!!!");
ArticleModel article2 = new ArticleModel();
article2.setTitle("the best in all the land");
article2.setAuthor("fans");
article2.setContent("Two thousand words are omitted here...");
ArticleModel article3 = new ArticleModel();
article3.setTitle("Java the best in all the land");
article3.setAuthor("fans");
article3.setContent("Today is big day!");
articles.add(article1);
articles.add(article2);
articles.add(article3);
luceneUtil.addModelDocs(articles);
luceneUtil.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
}
The content above can be replaced by itself. If you avoid the suspicion of rounding up the number of words, you won't post it.
Exhibition
After running, we used Lucene's visualization tool luke to view the data content of the index. After downloading and decompressing, we can see that there are bat and sh two scripts. Just run them according to your own system. Here is the mac, and the sh script is used to run. After running, open the set index directory.
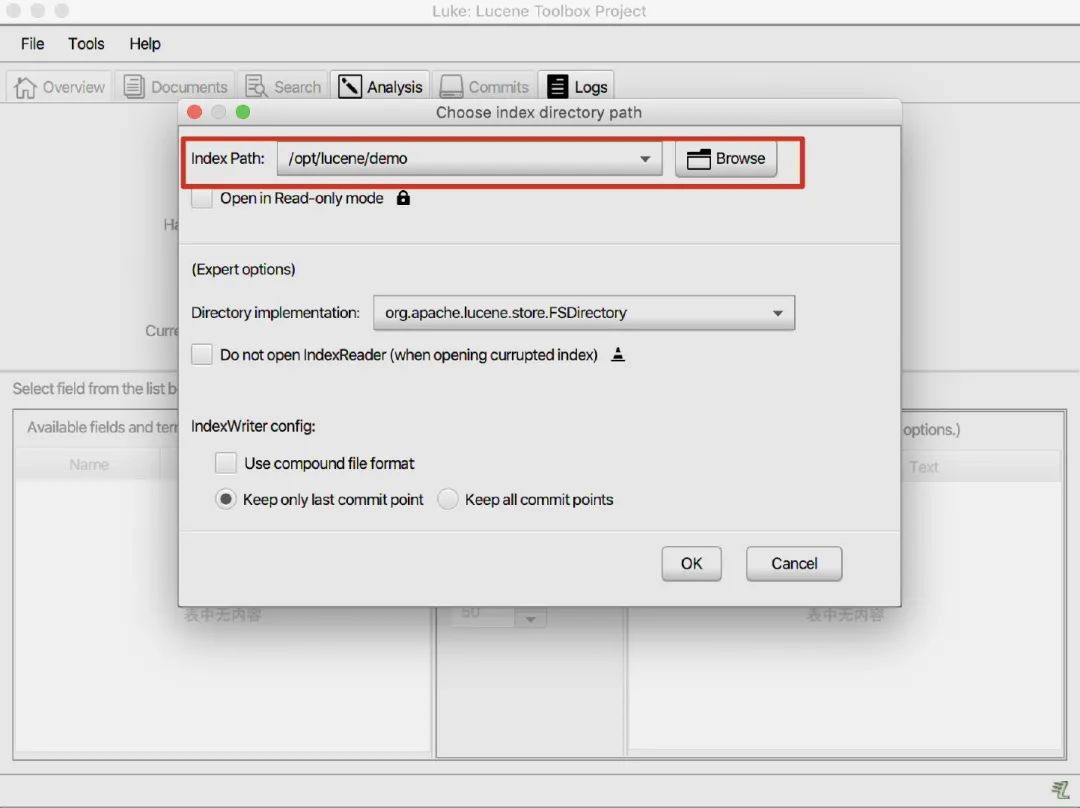
After entering, we can see the content shown in the figure below. Select content and click show top items to see the index data on the right. Here, the index results are different according to different word splitters. The word splitter used here is a standard word splitter. Partners can choose a word splitter suitable for themselves according to their own requirements.
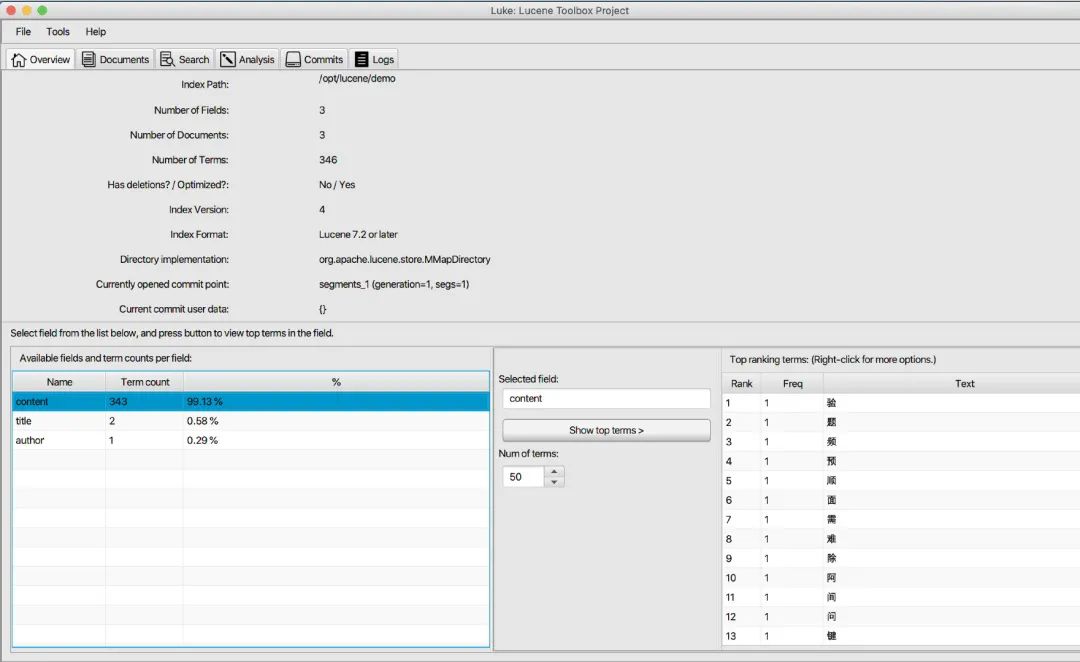
Search data
The data has been indexed successfully. Next, we need to search the data according to the conditions. We create a Lucene searchutil Java to manipulate data.
import org.apache.commons.collections.MapUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.beans.factory.annotation.Value;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.Map;
public class LuceneSearchUtil {
private static String INDEX_PATH = "/opt/lucene/demo";
private static IndexSearcher searcher;
public static LuceneSearchUtil getInstance() {
return LuceneSearchUtil.SingletonHolder.searchUtil;
}
private static class SingletonHolder {
public final static LuceneSearchUtil searchUtil = new LuceneSearchUtil();
}
private LuceneSearchUtil() {
this.initSearcher();
}
private void initSearcher() {
Directory directory;
try {
directory = FSDirectory.open(Paths.get(INDEX_PATH));
DirectoryReader reader = DirectoryReader.open(directory);
searcher = new IndexSearcher(reader);
} catch (IOException e) {
e.printStackTrace();
}
}
public TopDocs searchByMap(Map<String, Object> queryMap) throws Exception {
if (null == searcher) {
this.initSearcher();
}
if (MapUtils.isNotEmpty(queryMap)) {
BooleanQuery.Builder builder = new BooleanQuery.Builder();
queryMap.forEach((key, value) -> {
if (value instanceof String) {
Query queryString = new PhraseQuery(key, (String) value);
// Query queryString = new TermQuery(new Term(key, (String) value));
builder.add(queryString, BooleanClause.Occur.MUST);
}
});
return searcher.search(builder.build(), 10);
}
return null;
}
}
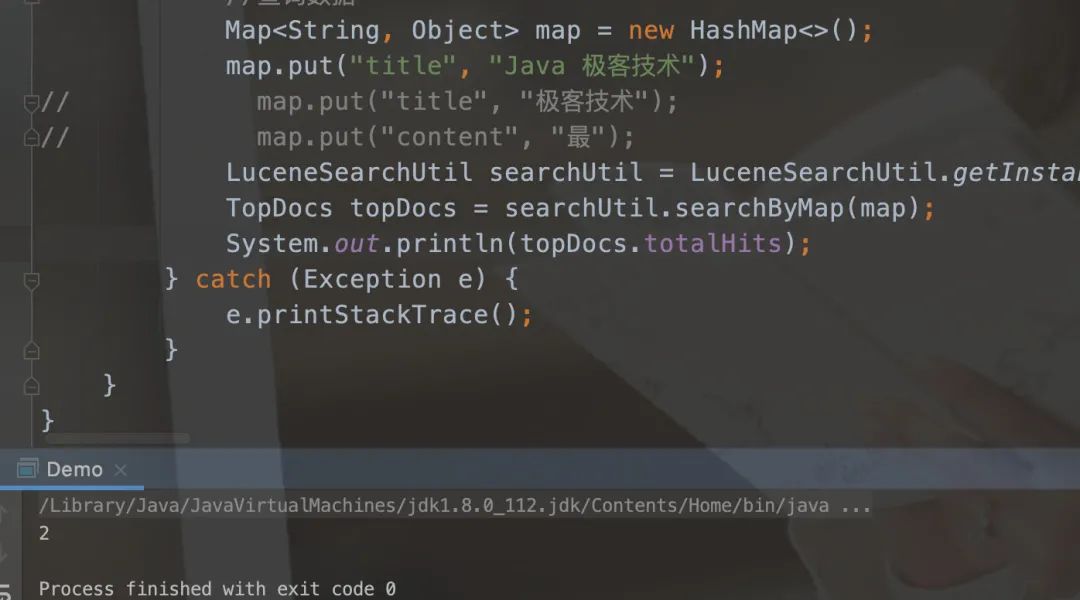
In demo The search code added in Java is as follows:
//Query data
Map<String, Object> map = new HashMap<>();
map.put("title", "Java the best in all the land");
// map.put("title", "No. 1 in the world");
// map.put("content");
LuceneSearchUtil searchUtil = LuceneSearchUtil.getInstance();
TopDocs topDocs = searchUtil.searchByMap(map);
System.out.println(topDocs.totalHits);
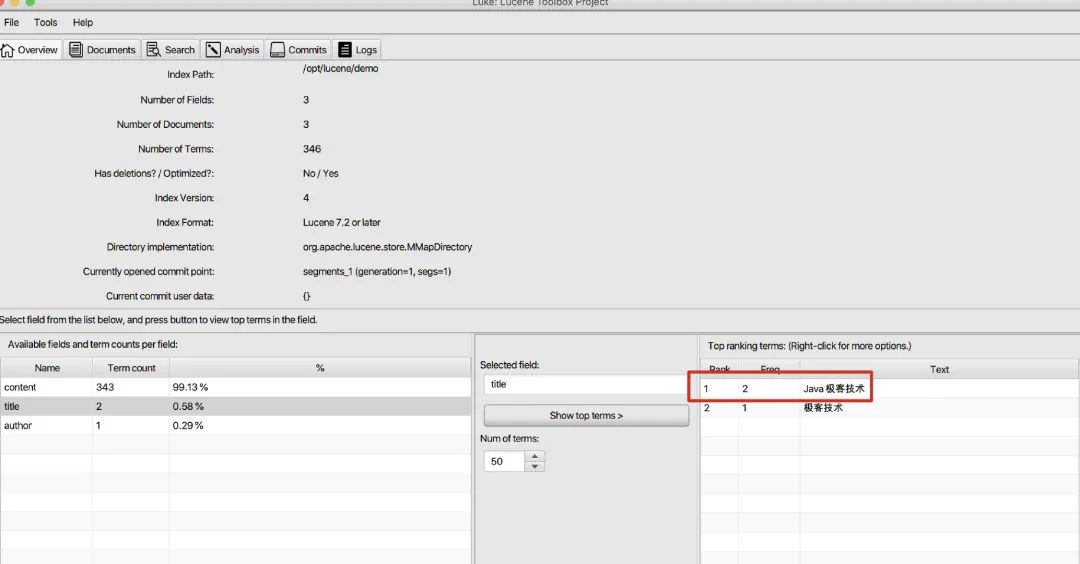
The running results are as follows, indicating that two items have been searched.
Through the visualization tool, we can see that there are indeed two records with the title of "Java is the first in the world", and we also confirm that only two pieces of data are inserted. Note that if you query according to other characters here, you may not find it, because the word splitter here is the default word splitter, and small partners can use the corresponding word splitter according to their own situation.
So far, we can index and search data, but this is still a simple introductory operation. We need to use different query methods for different types of fields, and we need to use a specific word splitter according to the characteristics of the system. The default standard word splitter does not necessarily meet our use scenarios. We need to set the Field index according to the Field type. The above case is only a demo and cannot be used in production. Search engine is the leader in the Internet industry. Many advanced Internet technologies began to develop from search engine.
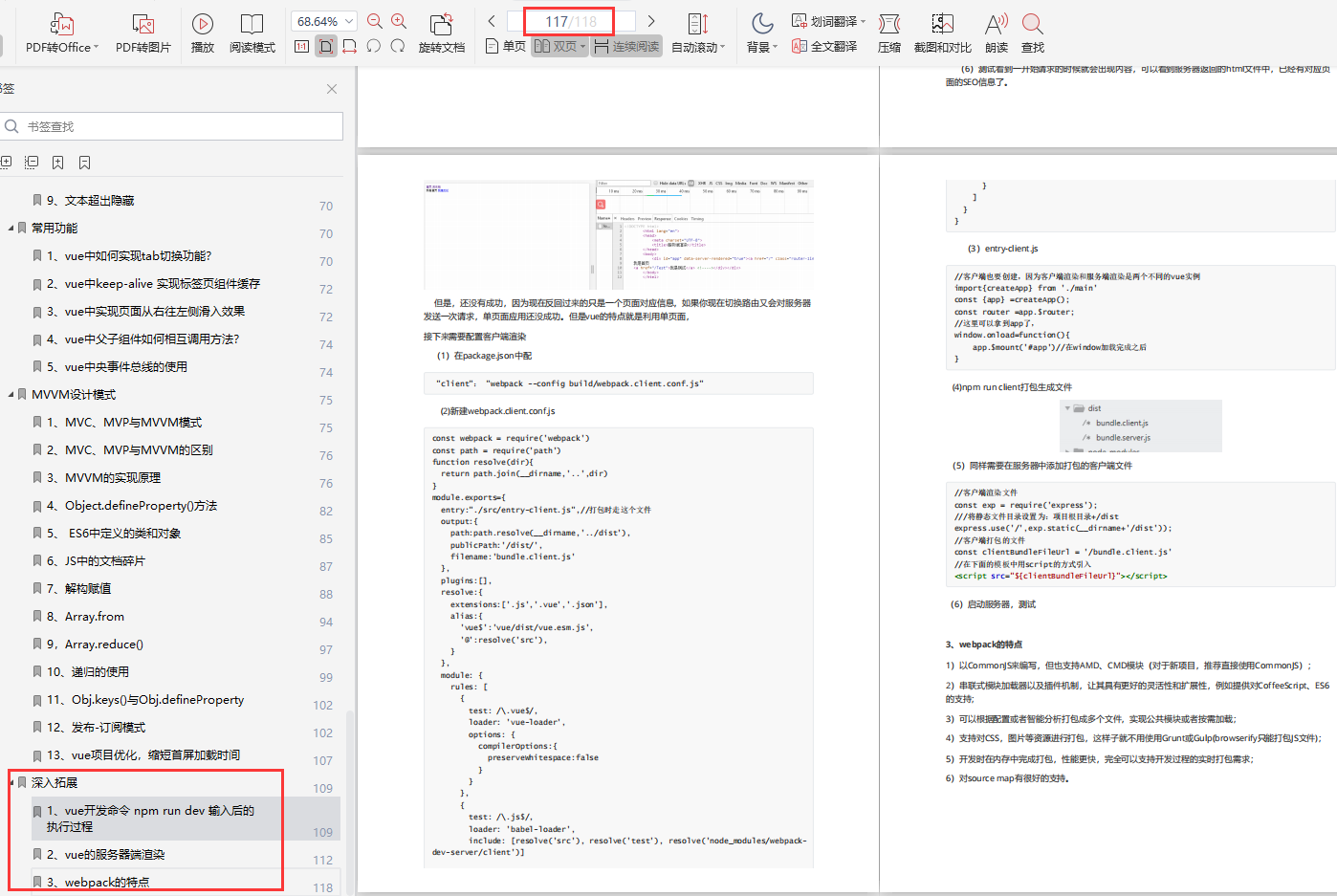
In depth development
1. Execution process of vue Development Command npm run dev after input
2. Server side rendering of vue
3. Write an npm installation package from zero
4. Loaders commonly used in Vue cli
5. Characteristics of webpack
**Conclusion: * * little partners who need front-end learning materials or want to learn front-end You can click here to communicate together Learning, CSS interview question document, JavaScript interview question document, Vue interview question document and large factory interview question summary can be obtained for free!
Scene. Moreover, when indexing data, we also need to set different fields according to the Field type. The above case is only a demo and cannot be used in production. Search engine is the leader in the Internet industry. Many advanced Internet technologies began to develop from search engine.
In depth development
1. Execution process of vue Development Command npm run dev after input
2. Server side rendering of vue
3. Write an npm installation package from zero
4. Loaders commonly used in Vue cli
5. Characteristics of webpack
[external chain picture transferring... (img-f2oQmB4s-1626946022410)]
**Conclusion: * * little partners who need front-end learning materials or want to learn front-end You can click here to communicate together Learning, CSS interview question document, JavaScript interview question document, Vue interview question document and large factory interview question summary can be obtained for free!