26 data analysis cases -- the fourth station: web server log data collection based on Flume and Kafka
Experimental environment
- Python: Python 3.x;
- Hadoop2.7.2 environment;
- Kafka_2.11;
- Flume-1.9.0.
Data package
Link: https://pan.baidu.com/s/1oZcqAx0EIRF7Aj1xxm3WNw
Extraction code: kohe
Experimental steps
Step 1: install and start the httpd server
[root@master ~]# yum -y install httpd [root@master ~]# cd /var/www/html/ [root@master html]# vi index.html #Enter the following Hello Flume [root@master html]# service httpd start
The result is accessed through the browser. Indicates successful startup.
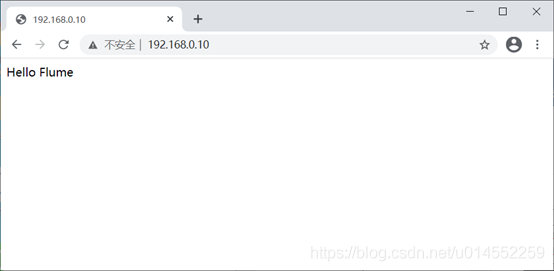
Check whether there is log generation.
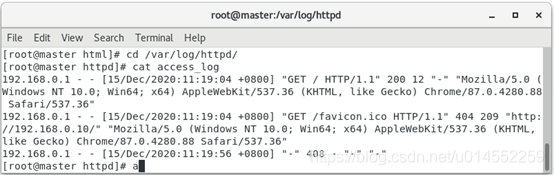
[root@master html]# cd /var/log/httpd/ [root@master httpd]#cat access_log
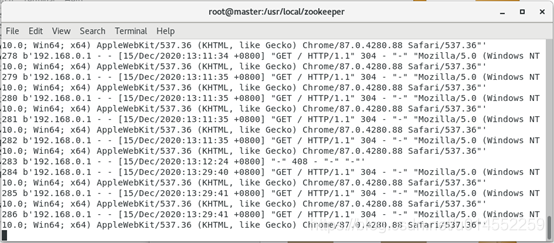
The result is.
Step 2: configure Flume.
Enter the / usr/local/flume/conf directory and create a directory named access_log-HDFS.properties. Set access under the monitoring / var/log/httpd / directory_ Log file and send the contents to kafka through port 9092.
[root@master httpd]# cd /usr/local/flume/conf/ [root@master conf]# vi access_log-HDFS.properties #The contents of the configuration file are as follows. a1.sources = s1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.s1.type = exec a1.sources.s1.command = tail -f /var/log/httpd/access_log a1.sources.s1.channels=c1 a1.sources.s1.fileHeader = false a1.sources.s1.interceptors = i1 a1.sources.s1.interceptors.i1.type = timestamp #Kafka sink configuration a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = cmcc a1.sinks.k1.brokerList = master:9092 a1.sinks.k1.requiredAcks = 1 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
Step 3: configure kafka
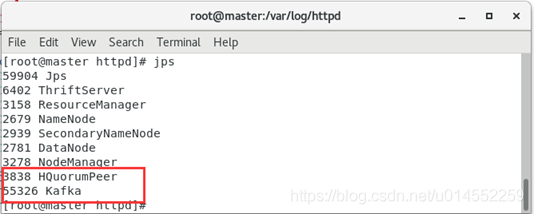
First, ensure that the zookeeper and kafka processes are in normal state. If they are closed, you can start them with the following command.
[root@master ~]# /usr/local/zookeeper/bin/zkServer.sh start [root@master ~]# cd /usr/local/kafka/bin/ [root@master bin]# ./kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
Step 4: write code to consume kafka data using Python
The PyKafkafka module is used here to create a customer named kafkacustomer Py file is used to consume kafka data from port 9092. topic needs to be formulated when consuming data. The code is as follows.
[root@master ~]# vim kafkacustomer.py
from pykafka import KafkaClient
client = KafkaClient(hosts="192.168.0.10:9092")
topic = client.topics['cmcc'] //Specify the consumption data from the topic cmcc
consumer = topic.get_simple_consumer(
consumer_group="tpic",
reset_offset_on_start=True
)
for message in consumer: //Traverse the received content
if message is not None: //If the information is not empty
print(message.offset, message.value) //Data results
Step 5: start the project
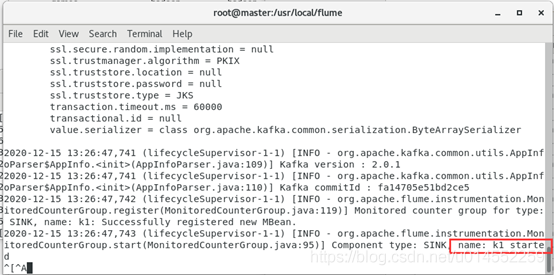
Start Flume root directory and use access_ log-HDFS. The properties configuration file starts data collection. After data collection is started, kafka's topic name is cmcc automatically created.
[root@master ~]# cd /usr/local/flume/ [root@master flume]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/access_log-HDFS.properties -Dflume.root.logger=INFO,console
Run kafkacustomer. Com using Python 3 Py file. Whenever the page is refreshed, the log file will be generated in real time, and collected by flume and sent to kafka.
[root@master ~]python customerkafka.py
Follow up cases are continuously updated
01 HBase crown size query system based on Python
02 civil aviation customer value analysis based on Hive
03 analysis of pharmacy sales data based on python
04 web server log data collection based on Flume and Kafka
05 Muke network data acquisition and processing
06 Linux operating system real-time log collection and processing
07 medical industry case - Analysis of dialectical association rules of TCM diseases
08 education industry case - Analysis of College Students' life data
10 entertainment industry case - advertising revenue regression prediction model
11 network industry case - website access behavior analysis
12 retail industry case - real time statistics of popular goods in stores
13 visualization of turnover data
14 financial industry case - financial data analysis based on stock information of listed companies and its derivative variables
15 visualization of bank credit card risk data
Operation analysis of 16 didi cities
17 happiness index visualization
18 employee active resignation warning model
19 singer recommendation model
202020 novel coronavirus pneumonia data analysis
Data analysis of 21 Taobao shopping Carnival
22 shared single vehicle data analysis
23 face detection system
24 garment sorting system
25 mask wearing identification system
26 imdb movie data analysis