preface
As we all know, at the end of last year, jsdelivr, a well-known free CDN service provider, had no domestic CDN acceleration due to the problem of domain name filing in the mainland. At present, it can only be parsed overseas, which is not only slow, but also occasionally unable to connect to the server. Therefore, many domestic websites have been affected.
Some people say that the referenced URLs can be modified in batch and changed to unpkg COM, but actually, half of js and css on my personal website are not available on this site.
Because my personal site doesn't provide much fancy content, I just want to download all the files to be obtained from jsdelivr to the local server and no longer obtain them from the outside. Maybe one day there will be no overseas services, that's Barbie Q.
Operation steps
-
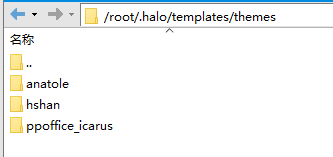
Open the blog template folder and find all the links containing jsdelivr. After de duplication, 39 links are found
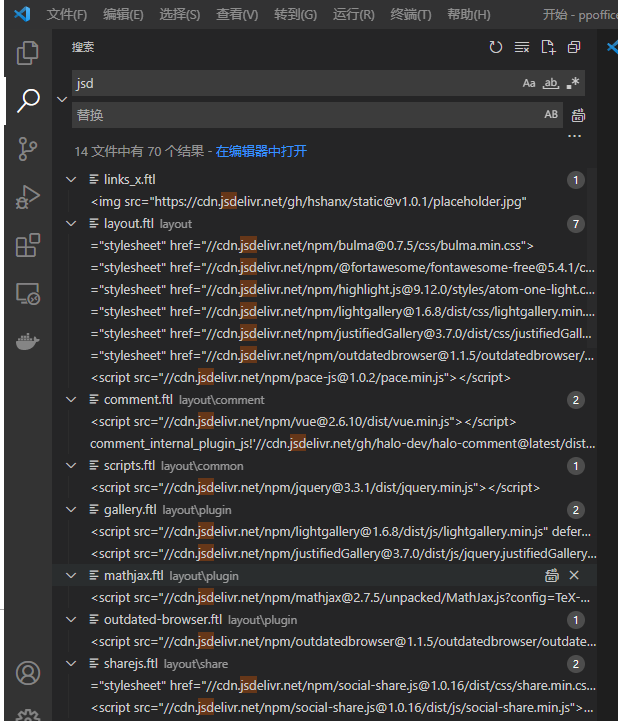
-
Then write a text file
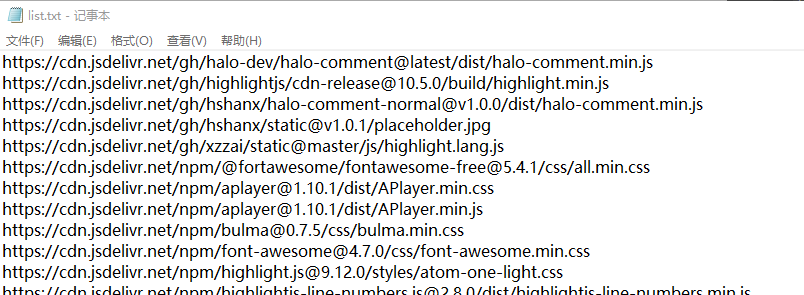
-
Write download program
You can see that the directory structure is quite complex. If you want to make the least changes, you should make the directory after downloading the file consistent with the link path. So I thought of that I used to download the whole website by Internet Express, but this thing has long been out of date and I'm too lazy to install software. Now it should be possible to use python. In order to avoid building wheels repeatedly, someone must have had this idea, so search first and easily find an article
Let Python automatically download all files of the website! https://zhuanlan.zhihu.com/p/62876301
I copied the program inside, modified the entry function, traversed the url list and passed it in
import urllib.request
import requests
import re, os
# be based on https://zhuanlan.zhihu.com/p/62876301 Modification
def get_file(url):
'''
Recursively download files from the website
:param url:
:return:
'''
if isFile(url):
print(url)
try:
download(url)
except:
pass
else:
urls = get_url(url)
for u in urls:
get_file(u)
def isFile(url):
'''
Determine whether a link is a file
:param url:
:return:
'''
if url.endswith('/'):
return False
else:
return True
def download(url):
'''
:param url:File link
:return: Download files and automatically create directories
'''
full_name = url.split('//')[-1]
filename = full_name.split('/')[-1]
dirname = "/".join(full_name.split('/')[:-1])
if os.path.exists(dirname):
pass
else:
os.makedirs(dirname, exist_ok=True)
urllib.request.urlretrieve(url, full_name)
def get_url(base_url):
'''
:param base_url:Give a URL
:return: Get all links in a given URL
'''
text = ''
try:
text = requests.get(base_url).text
except Exception as e:
print("error - > ",base_url,e)
pass
reg = '<a href="(.*)">.*</a>'
urls = [base_url + url for url in re.findall(reg, text) if url != '../']
return urls
if __name__ == '__main__':
with open('list.txt', 'r') as f:
lines = f.readlines()
url_list = []
for line in lines:
get_file(line.strip('\n'))
-
implement
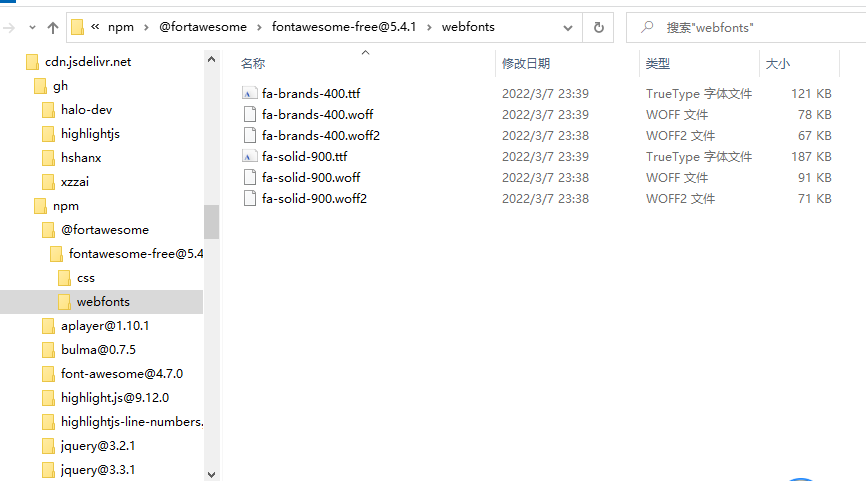
After the above code is saved as py file and executed, CDN will be generated in the current directory jsdelivr. Net home directory and its subdirectories and files
-
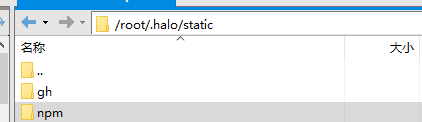
Upload folder to server
Since I am using the halo blog, I can add static resources by definition, and directly drag the downloaded gh and npm folders to / root / Halo / static directory is enough
-
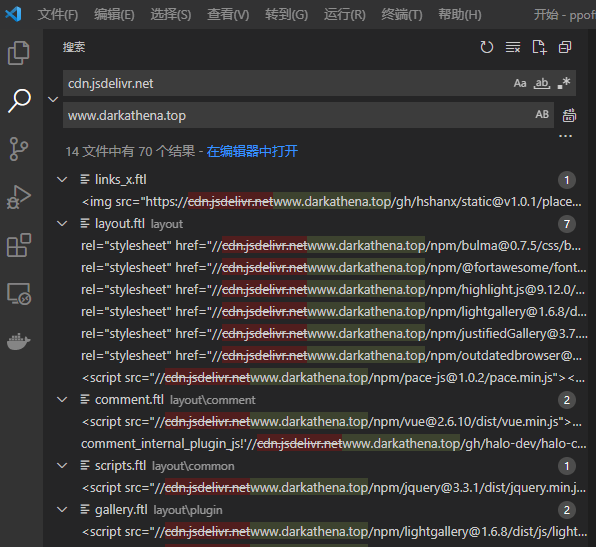
Modify links in blog templates
This is easy. Directly open all files in the template and batch CDN jsdelivr. Net replace it with the domain name of my website, save it and overwrite it on the server
-
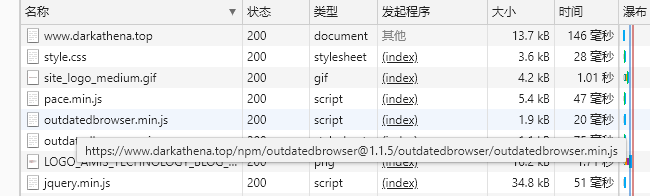
Final effect
Say something out of the question
Many programmers are used to using foreign free services, such as github and jsdelivr mentioned in this article. You should have found that these two things are intermittent in China.
At present, the international situation is becoming more and more tense, and the risk of putting things on foreign servers is becoming greater and greater. We should also consider migrating things on foreign servers back to our country. Otherwise, one day there will be a sanction, ranging from disconnection to account blackout, or directly deleting your data.
- Author: DarkAthena
- Link to this article: https://www.darkathena.top/archives/jsdelivr-byebye
- Copyright notice: all articles on this blog are in English unless otherwise stated CC BY-NC-SA 3.0 License agreement. Reprint please indicate the source!