1. Preface
Google has launched the flow api for a long time, commonly known as data flow.
Let's look at the definition according to the old rule. The data Flow is built on the basis of collaborative process and can provide multiple values. Conceptually, a data stream is a set of data sequences that can be calculated and processed asynchronously. For example, Flow is a data stream that emits integer values.
The data flow is very similar to the Iterator that generates a set of sequence values, but it uses suspend functions to generate and use values asynchronously. That is, for example, a data stream can safely issue a network request to generate the next value without blocking the main thread. In fact, flow is like a flow, which can generate values and can be used in collaboration. Ouch, the official really loves Coroutine.
Based on the characteristics of flow api, we can use it in many data communication scenarios. At the same time, because flow is used in collaborative process scenarios, it can be used to encapsulate many interesting things. This paper brings a bus library encapsulated by this api.
- Rehearsal
We talked about a lot of concepts before, so we should take a look at the specific code performance. The first is Flow
public interface Flow<out T> {
@InternalCoroutinesApi
public suspend fun collect(collector: FlowCollector<T>)
}
The FlowCollector interface defines the sending specification of the flow api. Note that it is also a suspend method, which belongs to the sender of the message.
Now we have clarified that the specification of a receiver and sender is defined. Here we can see why ordinary flow is a cold flow (note that ordinary flow can realize hot flow, such as StateFlow). You see, the collect in the flow interface actually accepts a FlowCollector and calls the emit in it to send data. Another small detail is that the generic type in flow is out decoration, while the FlowCollector is in decoration. Here, readers can think about why it is designed like this.
3. Different from existing data types
StateFlow, Flow and LiveData
Because we will use SharedFlow next, let's talk about the difference first
StateFlow and LiveData have similarities. Both are observable data container classes, and both follow similar patterns when used in application architecture.
Note, however, that StateFlow and LiveData do behave differently:
- StateFlow needs to pass the initial state to the constructor, while LiveData does not.
- When the View enters the STOPPED state, livedata Observe() automatically unregisters the user, and collecting data from StateFlow or any other data stream does not stop automatically.
[from the official website of Android developers]
What's the difference between StateFlow and SharedFlow
public interface StateFlow<out T> : SharedFlow<T> {
public val value: T
}
It's clear from the above code that SharedFlow is a higher-level abstraction of StateFlow, and SharedFlow is
public interface SharedFlow<out T> : Flow<T> {
/**
* A snapshot of the replay cache.
*/
public val replayCache: List<T>
}
You can see that there is a list object in it, which shows the source of data flow. In fact, the most essential data structure is a list. Seeing this, do you really want to the internal core of our bus based framework? Let's start encapsulating our bus data flow
4. Start doing things
What do we need to achieve:
1. Bus type data flow can be realized internally with flow api, and SharedFlow can be adopted here.
2. Compared with the need to register and deregister EventBus, I believe you guys must be very tired, so we need the function of automatic registration and deregistration.
3. You can send sticky events and non sticky events
4. Switch thread subscription
5. Enough streamlining
6. Realize the core functions of sending and receiving
Based on the above problems, we start to realize step by step:
Q1: according to the above source code analysis, SharedFlow maintains a list, which meets the data structure of our message storage, so it's no problem
Q2: automatic registration and deregistration. Hey, you don't have to look at it. You'll think of the interface LifecycleEventObserver. After all, monitoring the life cycle is an old routine. So where can we implement this interface? flow? In the incident? nonono, we have always ignored an important point, which is the collaborative process. It says a lot of things. In fact, flow runs in the collaborative process, right? We can make an article in the collaborative process! In other words, we control the life cycle of the collaborative process, that is, we control the life cycle of the flow!
class LifeCycleJob(private val job: Job) : Job by job, LifecycleEventObserver {
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (event == Lifecycle.Event.ON_DESTROY) {
this.cancel()
}
}
override fun cancel(cause: CancellationException?) {
if (!job.isCancelled) {
job.cancel()
}
}
}
Q3: how to distinguish between sticky events and non sticky events is also very easy to handle. For sticky data, let the receiver send the data in the list again when receiving the data. For non sticky subscription, we don't send it. Because we want to subscribe to a single event now, we can use MutableSharedFlow
@Suppress("FunctionName", "UNCHECKED_CAST")
public fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T> {
require(replay >= 0) { "replay cannot be negative, but was $replay" }
require(extraBufferCapacity >= 0) { "extraBufferCapacity cannot be negative, but was $extraBufferCapacity" }
require(replay > 0 || extraBufferCapacity > 0 || onBufferOverflow == BufferOverflow.SUSPEND) {
"replay or extraBufferCapacity must be positive with non-default onBufferOverflow strategy $onBufferOverflow"
}
val bufferCapacity0 = replay + extraBufferCapacity
val bufferCapacity = if (bufferCapacity0 < 0) Int.MAX_VALUE else bufferCapacity0 // coerce to MAX_VALUE on overflow
return SharedFlowImpl(replay, bufferCapacity, onBufferOverflow)
}
I see that MutableSharedFlow implements MutableSharedFlow interface, and MutableSharedFlow interface implements SharedFlow and FlowCollector, so it can act as sender and collector!
interface MutableSharedFlow<T> : SharedFlow<T>, FlowCollector<T>
Seeing MutableSharedFlow parameter, we can directly use its features: for event collection, we can define message data collection as follows:
Non viscous
var events = ConcurrentHashMap<Any, MutableSharedFlow<Any>>()
private set
viscosity
var stickyEvents = ConcurrentHashMap<Any, MutableSharedFlow<Any>>()
private set
Q4: switch threads. This is what coprocessors are best at. You can use Dispatch to switch the specified response thread
Q5: if it is concise enough, the extension function can be used here to facilitate the expansion of the original function.
Q6: as mentioned earlier, MutableSharedFlow implements the interface of flow sending and receiving, so we can use this feature
inline fun <reified T> post(event: T, isStick: Boolean) {
val cls = T::class.java
if (!isStick) {
stickyEvents.getOrElse(cls) {
MutableSharedFlow(0, 1, BufferOverflow.DROP_OLDEST)
}.tryEmit(event as Any)
} else {
stickyEvents.getOrElse(cls) {
MutableSharedFlow(1, 1, BufferOverflow.DROP_OLDEST)
}.tryEmit(event as Any)
}
}
As for the reception, the reception is a little troublesome, because we use the post method to send, so how to distinguish between sticky messages and non sticky messages? Here, we all use the method of monitoring, so are we monitoring in the same collaboration domain or different? There is another small problem involved here. The collect function will suspend the current collaboration, so it is obviously not feasible to monitor in the same collaboration domain, because the operation is serial in the same collaboration domain (regardless of the existence of child collaboration domains), so we need to open two collaboration domains and call the collect function in them respectively, Listening for sticky and non sticky events
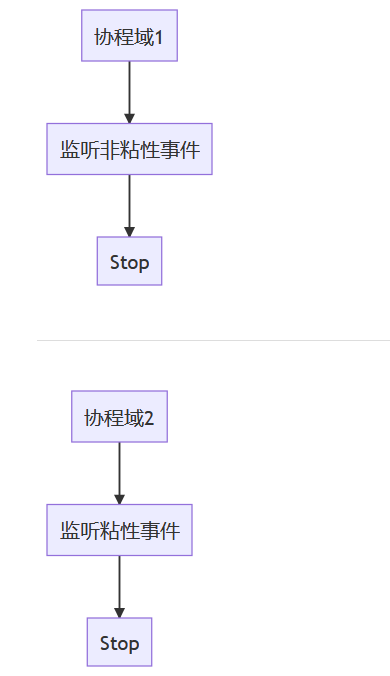
inline fun <reified T> onEvent(
event: Class<T>,
crossinline dos: (T) -> Unit,
owner: LifecycleOwner,
env: SubscribeEnv
) {
if (!events.containsKey(event)) {
events[event] = MutableSharedFlow(0, 1, BufferOverflow.DROP_OLDEST)
}
if (!stickyEvents.containsKey(event)) {
stickyEvents[event] = MutableSharedFlow(1, 1, BufferOverflow.DROP_OLDEST)
}
val coroutineScope: CoroutineScope = when (env) {
SubscribeEnv.IO -> CoroutineScope(Dispatchers.IO)
SubscribeEnv.DEFAULT -> CoroutineScope(Dispatchers.Default)
else -> CoroutineScope(Dispatchers.Main)
}
coroutineScope.launch {
events[event]?.collect {
if (it is T) {
dos.invoke(it)
}
}
}.setLifeCycle(owner.lifecycle)
coroutineScope.launch {
stickyEvents[event]?.collect {
if (it is T) {
dos.invoke(it)
}
}
}.setLifeCycle(owner.lifecycle)
}