We know that redis is a very common memory database, and reading data from memory is one of the reasons why it is very efficient. However, if one day, "What if redis's allocated memory is full?" ? Don't panic when you encounter this interview question. We can answer this question from two angles:
- "What will redis do?" ?
- "What can we do?" ?
Increase redis available memory
This method is very violent and easy to use. We can directly increase the available memory of redis in two ways
- Click Configure through configuration file to set the memory size by adding the following configuration to the redis.conf configuration file under the redis installation directory. / / set the maximum memory size occupied by redis to 1000M
maxmemory 1000mb
Copy code - Modify by command: redis supports dynamic memory size modification by command at runtime. / / set the maximum memory size used by redis to 1000M
127.0.0.1:6379> config set maxmemory 1000mb
Copy code
This method is immediate. reids memory is always limited by the memory of the machine and cannot grow indefinitely. What if there is no way to increase the available memory of redis?
Memory elimination strategy
In fact, redis defines "8 memory elimination strategies" Used to handle the case that redis memory is full:
- noeviction: directly returns an error without eliminating any existing redis keys
- All keys lru: all keys are eliminated by lru algorithm
- Volatile lru: those with expiration time shall be eliminated by lru algorithm
- All keys random: randomly delete redis keys
- Volatile random: randomly delete redis keys with expiration time
- Volatile TTL: delete the redis key that is about to expire
- Volatile lfu: delete keys with expiration time according to lfu algorithm
- All keys lfu: delete all keys according to the lfu algorithm
These memory elimination strategies are well understood. Let's focus on how lru, lfu and ttl are implemented
lru best practices?
lru is the abbreviation of Least Recently Used "Rarely used recently" , It can also be understood that it has not been used for the longest time. The more recently used, the more likely it will be used later. Because memory is very expensive, the data we can store in the cache is limited. For example, we can only store 1w pieces of fixed memory. When the memory is full, every time a new piece of data is inserted into the cache, we have to discard the longest unused old data. After sorting out the above contents, we can get several requirements:
- "1. Ensure its reading and writing efficiency. For example, the complexity of reading and writing is O(1)"
- "2. When a piece of data is read, update its most recently used time"
- "3. When inserting a new piece of data, delete the longest unused data"
Therefore, we should try our best to ensure high query efficiency and high insertion efficiency. We know that if we only consider query efficiency, the hash table may be the best choice. If we only consider insertion efficiency, the linked list must have its place.
However, these two data structures have their disadvantages when used alone. So, is there a data structure that can ensure both query efficiency and insertion efficiency? So the hash + linked list structure appeared
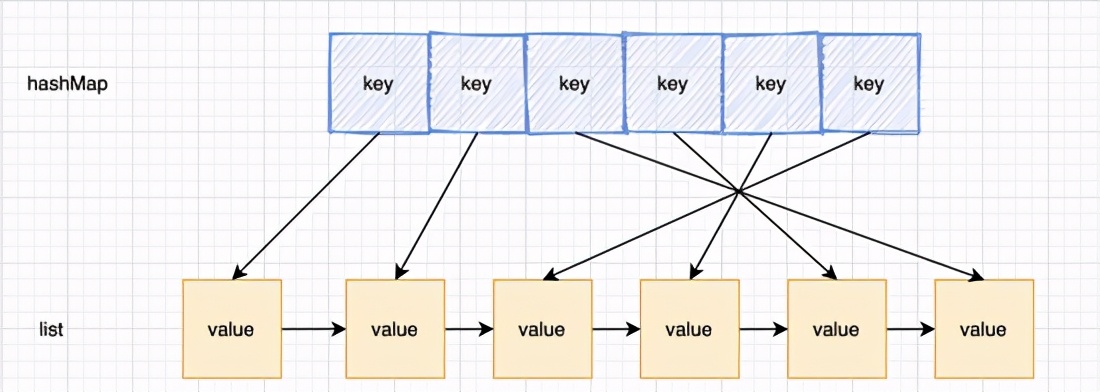
hash table is used to query the data position in the linked list. The linked list is responsible for data insertion. There are two situations when new data is inserted into the head of the linked list;
- 1. When the linked list is full, discard the data at the end of the linked list. This is relatively simple. Just erase the pointer at the end of the linked list and clear the information in the corresponding hash
- 2. Whenever the cache hits (i.e. the cache data is accessed), move the data to the head of the linked list; In this case, we find that if we hit the middle node of the linked list, what we need to do is 1). Move the node to the head node 2). Set the next node of the previous node of the node as the next node of the node. There will be a problem. We can't find the previous node of the node because it is a one-way linked list, A new model was created.
At this time, the function of two-way linked list is also reflected. You can navigate directly to the parent node. This is very efficient. And because the two-way linked list has tail pointers, it is also very convenient and fast to remove the last tail node
So the final solution is to use "Hash table + bidirectional linked list" Structure of
Best practices for lfu?
LFU:Least Frequently Used. In a period of time, data is "Least frequent use" Yes, priority is given to elimination. Least use (LFU) is a caching algorithm used to manage computer memory. It mainly records and tracks the usage times of memory blocks. When the cache is full and more space is needed, the system will clear the memory with the lowest memory block usage frequency. The simplest way to adopt LFU algorithm is to allocate a counter for each block loaded into the cache. Each time the block is referenced, the counter is incremented by one. When the cache reaches its capacity and there is a new memory block waiting to be inserted, the system will search for the block with the lowest counter and delete it from the cache.
Here we propose an implementation scheme of LFU with O(1) time complexity, which supports operations including insert, access and delete
As shown in the figure:
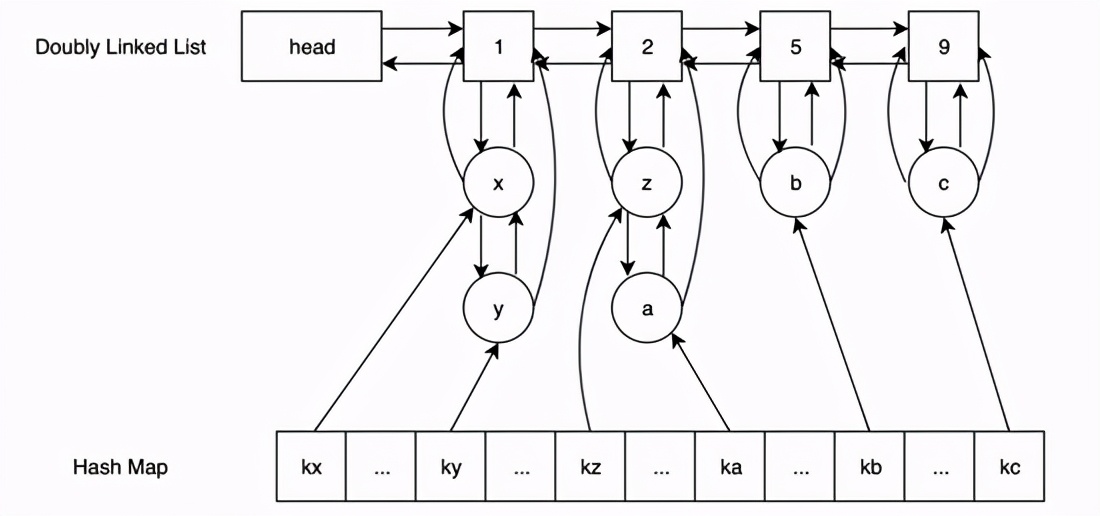
It consists of two bidirectional linked lists + hash tables. The upper bidirectional linked list is used to count, and the lower bidirectional linked list is used to record the stored data. The head node of the linked list stores numbers, and the value object of the hash table records the data of the lower bidirectional linked list. Here, we follow the insertion process:
- Insert the data to be stored into the
- In the hash table "Existence" , Find the corresponding lower two-way linked list, connect the previous node of the node with the next node of the node (there may be only yourself, just remove it directly), and then judge whether the count of the upper two-way linked list is 1 "if yes" greater than the current count , Move yourself to the top of the two-way linked list, and Judge whether the two-way linked list contains elements. If not, delete the node. If not, or there is no next node in the two-way list above Then add a new node and set the count to the current count + 1
- In the hash table "Does not exist" , Store the data in the hash table and connect the data with the head node of the two-way linked list (the linked list may not be initialized here)
In this way, when searching and inserting, the efficiency is O(1)
How is redis TTL implemented?
Data structure of TTL storage
redis has a special dict for TTL time storage, which is the dict *expires field in redisDb. Dict, as its name implies, is a hashtable, key is the corresponding rediskey, and value is the corresponding TTL time. the data structure of dict contains two dictht objects, which are mainly used to re use hash data during hash conflict.




TTL set expiration time
There are four methods to set key expiration time in TTL:
- expire the expiration policy in seconds based on relative time
- Expire is an expiration policy based on absolute time and in seconds
- pexpire expires in milliseconds in relative time
- Pexpirat expires in milliseconds in absolute time
{"expire",expireCommand,3,"w",0,NULL,1,1,1,0,0},
{"expireat",expireatCommand,3,"w",0,NULL,1,1,1,0,0},
{"pexpire",pexpireCommand,3,"w",0,NULL,1,1,1,0,0},
{"pexpireat",pexpireatCommand,3,"w",0,NULL,1,1,1,0,0},
Copy codeexpire expireat pexpire pexpireat
From the implementation function of actually setting the expiration time, the relative time policy will have a current time as the base time, and the absolute time policy will "Take 0 as a base time" .
void expireCommand(redisClient *c) {
expireGenericCommand(c,mstime(),UNIT_SECONDS);
}
void expireatCommand(redisClient *c) {
expireGenericCommand(c,0,UNIT_SECONDS);
}
void pexpireCommand(redisClient *c) {
expireGenericCommand(c,mstime(),UNIT_MILLISECONDS);
}
void pexpireatCommand(redisClient *c) {
expireGenericCommand(c,0,UNIT_MILLISECONDS);
}
Copy codeThe whole expiration time is finally converted to absolute time for storage and calculated by the formula base time + expiration time. for relative time, the reference time is the current time, and for absolute time, the relative time is 0. consider whether the set expiration time has expired. If it has expired, the data will be deleted on the master and the deletion action will be synchronized to the slave. the normal set expiration time is saved to the dict *expires object through the setExpire method.
/*
*
* This function is the underlying implementation of the express, PEXPIRE, express, and PEXPIREAT commands.
*
* The second parameter of the command may be absolute or relative.
* When the * AT command is executed, the basetime is 0. In other cases, it saves the current absolute time.
*
* unit Format used to specify argv[2] (incoming expiration time),
* It can be a UNIT_SECONDS or UNIT_MILLISECONDS ,
* basetime Parameters are always in millisecond format.
*/
void expireGenericCommand(redisClient *c, long long basetime, int unit) {
robj *key = c->argv[1], *param = c->argv[2];
long long when; /* unix time in milliseconds when the key will expire. */
// Take out the when parameter
if (getLongLongFromObjectOrReply(c, param, &when, NULL) != REDIS_OK)
return;
// If the incoming expiration time is in seconds, convert it to milliseconds
if (unit == UNIT_SECONDS) when *= 1000;
when += basetime;
/* No key, return zero. */
// Remove key
if (lookupKeyRead(c->db,key) == NULL) {
addReply(c,shared.czero);
return;
}
/*
* When loading data, or when the server is an affiliated node,
* Even if the TTL of exhibit is negative or the timestamp provided by exhibit has expired,
* The server will not actively delete this key, but wait for the master node to send an explicit DEL command.
*
* The program will continue to set (a TTL that may have expired) as the expiration time of the key,
* And wait for the DEL command from the master node.
*/
if (when <= mstime() && !server.loading && !server.masterhost) {
// The time provided by when has expired. The server is the primary node and is not loading data
robj *aux;
redisAssertWithInfo(c,key,dbDelete(c->db,key));
server.dirty++;
/* Replicate/AOF this as an explicit DEL. */
// Propagate DEL command
aux = createStringObject("DEL",3);
rewriteClientCommandVector(c,2,aux,key);
decrRefCount(aux);
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_GENERIC,"del",key,c->db->id);
addReply(c, shared.cone);
return;
} else {
// Set the expiration time of the key
// If the server is a dependent node or the server is loading,
// Then this when may have expired
setExpire(c->db,key,when);
addReply(c,shared.cone);
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_GENERIC,"expire",key,c->db->id);
server.dirty++;
return;
}
}
setExpire Functions are mainly for db->expires Medium key Corresponding dictEntry Set the expiration time.
/*
* Set the expiration time of the key to when
*/
void setExpire(redisDb *db, robj *key, long long when) {
dictEntry *kde, *de;
/* Reuse the sds from the main dict in the expire dict */
// Remove key
kde = dictFind(db->dict,key->ptr);
redisAssertWithInfo(NULL,key,kde != NULL);
// Remove the expiration time of the key according to the key
de = dictReplaceRaw(db->expires,dictGetKey(kde));
// Set the expiration time of the key
// In this case, integer values are used directly to save the expiration time, not INT encoded String objects
dictSetSignedIntegerVal(de,when);
}
Copy codeWhen does redis implement the elimination strategy?
There are three deletion operations in redis. This policy
- Scheduled deletion: for keys without expiration time, the timer task will delete them immediately when the time comes. Because a timer needs to be maintained, it will occupy cpu resources, especially the more and more redis keys with expiration time, and the lost performance will increase linearly
- Lazy delete: the expiration time of the key is checked only when accessing the key. If it has expired, delete it. This situation can only be deleted when accessing, so it is possible that some expired redis keys will not be accessed and will always occupy redis memory
- Periodically delete: every once in a while, the expired keys will be checked and deleted. This scheme is equivalent to the compromise between the above two schemes. The key is deleted by controlling the deletion time interval most reasonably, reducing the occupation and consumption of cpu resources and rationalizing the deletion operation.
