preface
Many friends may encounter a large amount of data, and your interface query is particularly slow. If so, there are many processing schemes, such as changing your serial query to parallel query, optimizing sql and indexing. Finally, there is no way to add cache. Because caching will cause the cached data to be different from the data in the database. So don't cache everything. It depends.
Cache introduction
In fact, there are many ways to add cache, such as using redis as cache, using spring's own cache mechanism for cache, and secondary cache. Now I'll talk all about how to use these things.
Cache usage:
- Use redis to cache and view redis integrates with springboot to use cache
- Using hutool tool for caching requires jdk1 8+
Import maven dependencies
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.2</version>
</dependency>
Use code
@Service
@Slf4j
public class SyjkServiceImpl implements SyjkService {
public static final String hyyc = "HYYCQK";
public static final String paramcheck = "PARAM_CHECK";
@Resource
private SyjkMapper syjkMapper;
@Resource
private CommonMapper commonMapper;
private static Cache<String, List<HyycqkVo>> cache = CacheUtil.newTimedCache(600000);
@Override
public List<HyycqkVo> getHyycqk(BaseDto baseDto) {
//Get data in cache
List<HyycqkVo> hyycqkVos = cache.get(hyyc);
BaseDto baseDto1 = paraCache.get(paramcheck);
if (hyycqkVos == null && baseDto1 == null) {
return getHyycqkBySjk(baseDto);
}else if(!StringUtils.equals(baseDto1.getSwjgId(), baseDto.getSwjgId()) || !StringUtils.equals(baseDto1.getSsnd(), baseDto.getSsnd())) {
return getHyycqkBySjk(baseDto);
}
return hyycqkVos;
}
}
- The above efficiency is not the highest. The highest is the L2 cache. This is a memory based cache. At present, the memory cache frameworks that are widely used include guava, Ehcache, caffeine, etc.
We take the cafe officially provided by spring as an example.
Import jar package
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.0</version>
</dependency>
Configure the CacheManager and enable EnableCaching
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
//Caffeine configuration
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
//Expires after a fixed time after the last write
.expireAfterWrite(10, TimeUnit.SECONDS)
//Maximum number of cache entries
.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
In fact, if you don't want to write like this, you can write like this
<bean id="cacheManager" class="org.springframework.cache.guava.GuavaCacheManager">
<property name="cacheSpecification" value="initialCapacity=512,maximumSize=4096,concurrencyLevel=16,expireAfterAccess=120s" />
</bean>
<!-- Enable cache annotation -->
<cache:annotation-driven order="1" cache-manager="cacheManager" proxy-target-class="true" />
Use code
@Cacheable(value="myCache",key = "#baseDto+'getSssr'")
public List<SssrVo> getSssr(BaseDto baseDto) {
String cjBySwjg = commonMapper.getCjBySwjg(baseDto.getSwjgId());
//Set query parameters
QueryParam queryParam = ParamsDealUtil.setQueryParam(baseDto);
queryParam.setSwjgcj(cjBySwjg);
List<SssrVo> sssr = qjzsMapper.getSssr(queryParam);
if(sssr!=null){
for (SssrVo sssrVo1 : sssr) {
//Processing month
SssrVo sssrVo = DealYfUtil.dealYf(sssrVo1);
if(sssrVo.getQnss()!=null&&sssrVo.getBnss()!=null){
sssrVo.setSstb(DoubleUtil.round(((sssrVo.getBnss()- sssrVo.getQnss())/(double)sssrVo.getQnss())*100,1));
}
}
}
return sssr;
}
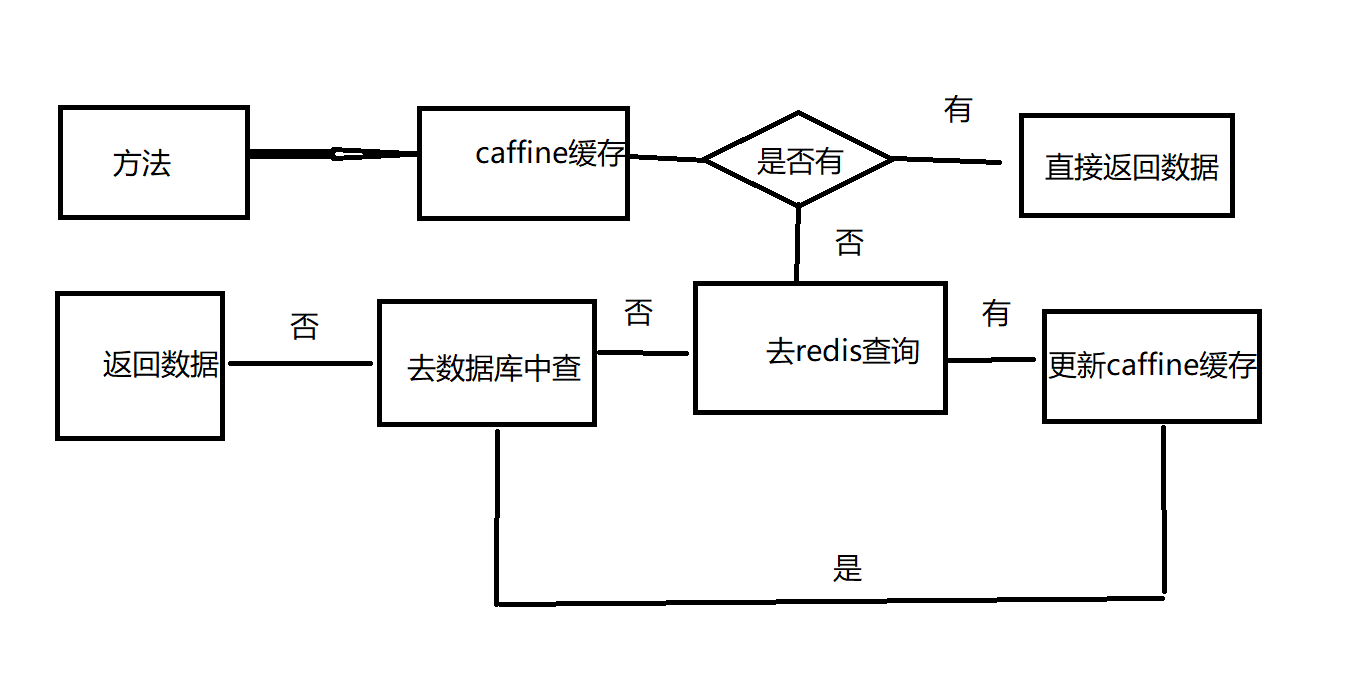
Explain the flow of this Code: first, when calling our method, it will first get the data from the cafe cache. If it can get it, it will get it, and then it will directly return the data. If it can't get it, it will go through the query language of the method body. After finding the data, it will be automatically put back into the cache.
@Introduction to Cacheable:
Value refers to the name you put in the cache and where it is put. Key refers to the key you get in the cache area according to this key, which corresponds to the value one by one. Do not repeat it. If the value key is different when calling this method, the cache will not be used. If it is the same, the cache will be used.
In fact, this scheme is the most basic. Usually we can do this (pseudo code)
@Cacheable(value="myCache",key = "#baseDto+'getSssr'")
public List<SssrVo> getSssr(BaseDto baseDto) {
//Get data from redis cache
Object name = redisTemplate.boundValueOps("name").get();
if(name==null){
//Get from database
List<SssrVo> sss=mapper.select(baseDto);
//Put in cache
redisTemplate.boundValueOps("name").set(sss);
}
}
summary
As mentioned earlier, caching will lead to different data. It is usually used in data insensitive queries. In order to solve this inconsistency, we usually add scheduled tasks to get the data we need in real time.