I used c# to write last time Net code was almost more than 10 years ago. At that time, java was already king, and net was almost defeated. Therefore, at that time, the author was concerned about this Net's project attitude was rather perfunctory and did not have a deep understanding of some of the excellent mechanisms. They didn't give it when they wrote "C and Java are not so popular, who can be the king in the era of high concurrency" last year Net, but recently, by chance, I took over another project on Windows, which also gave me the opportunity to re-examine myself about Net framework.
The function to be realized by the project prototype is not complex. It mainly records the records of file copying in the mobile storage device, and needs to occupy system resources as little as possible. I am surprised by a phenomenon in the development process. When using Invoke method to record file copying, the program execution efficiency will be significantly higher.
A line of seemingly useless code greatly improves efficiency
Since the file copying information I need to record is not echoed in the UI, the problem of concurrency conflict is not considered. In the implementation of the initial version, I directly handle the callback events of filesystemwatcher, as follows:
private void DeleteFileHandler(object sender, FileSystemEventArgs e)
{
if(files.Contains(e.FullPath))
{
files.Remove(e.FullPath);
//Some other operations
}
}The processing efficiency of this program is on an ordinary office PC. if 20 files are copied at the same time, the CPU utilization of the USB flash disk monitoring program is about 0.7% in the copy process.

But by chance, I used the Invoke mechanism of Event/Delegate and found that such a seemingly useless operation reduced the CPU utilization of the program to about 0.2%
private void UdiskWather_Deleted(object sender, FileSystemEventArgs e)
{
if(this.InvokeRequired)
{
this.Invoke(new DeleteDelegate(DeleteFileHandler), new object[] { sender,e }); }
else
{
DeleteFileHandler(sender, e);
}
}In my initial understanding net, so it's good not to slow down the operation, but the actual verification results are the opposite. The reason behind this has aroused my curiosity.
Why does the seemingly useless Invoke improve efficiency?
Here is a conclusion. Invoke can improve the execution efficiency of the program. The key is that the consumption of thread switching between multiple cores is much higher than that of unpacking and boxing. We know that the core of our program is to operate the shared variable files. Every time there is a file change in the detected U SB flash disk directory, its callback notification function may run in different threads, As follows:

Behind the Invoke mechanism is to ensure that all operations on the shared variable files are performed by one thread.

Due to the current situation Net code is open-source. Let's briefly explain the calling process of Invoke. Both BeginInvoke and Invoke are actually called MarshaledInvoke Method, as follows:
public IAsyncResult BeginInvoke(Delegate method, params Object[] args) {
using (new MultithreadSafeCallScope()) {
Control marshaler = FindMarshalingControl();
return(IAsyncResult)marshaler.MarshaledInvoke(this, method, args, false);
}
}
The main task of MarshaledInvoke is to create ThreadMethodEntry objects and put them in a linked list for management, then call PostMessage to send relevant information to the threads to communicate.
private Object MarshaledInvoke(Control caller, Delegate method, Object[] args, bool synchronous) {
if (!IsHandleCreated) {
throw new InvalidOperationException(SR.GetString(SR.ErrorNoMarshalingThread));
}
ActiveXImpl activeXImpl = (ActiveXImpl)Properties.GetObject(PropActiveXImpl);
if (activeXImpl != null) {
IntSecurity.UnmanagedCode.Demand();
}
// We don't want to wait if we're on the same thread, or else we'll deadlock.
// It is important that syncSameThread always be false for asynchronous calls.
//
bool syncSameThread = false;
int pid; // ignored
if (SafeNativeMethods.GetWindowThreadProcessId(new HandleRef(this, Handle), out pid) == SafeNativeMethods.GetCurrentThreadId()) {
if (synchronous)
syncSameThread = true;
}
// Store the compressed stack information from the thread that is calling the Invoke()
// so we can assign the same security context to the thread that will actually execute
// the delegate being passed.
//
ExecutionContext executionContext = null;
if (!syncSameThread) {
executionContext = ExecutionContext.Capture();
}
ThreadMethodEntry tme = new ThreadMethodEntry(caller, this, method, args, synchronous, executionContext);
lock (this) {
if (threadCallbackList == null) {
threadCallbackList = new Queue();
}
}
lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}
if (syncSameThread) {
InvokeMarshaledCallbacks();
} else {
//
UnsafeNativeMethods.PostMessage(new HandleRef(this, Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
}
if (synchronous) {
if (!tme.IsCompleted) {
WaitForWaitHandle(tme.AsyncWaitHandle);
}
if (tme.exception != null) {
throw tme.exception;
}
return tme.retVal;
}
else {
return(IAsyncResult)tme;
}
}
The Invoke mechanism ensures that a shared variable can only be maintained by one thread, which is similar to The design of GO language using communication to replace shared memory is coincident. Their idea is to "let the same piece of memory be operated by only one thread at the same time". This is closely related to the multi-core CPU (SMP) of modern computing architecture,
Here, let'S talk about the communication between CPUs and the content of MESI protocol. We know that modern CPUs are equipped with cache. According to the MESI protocol of multi-core cache synchronization, each cache line has four states, namely E (exclusive), M (modified), S (shared) and I (invalid), among which:
M: It means that the content in the cache line is modified, and the cache line is only cached in the CPU. This state indicates that the data in the cache row is different from the data in memory.
E: Represents that the content in the memory corresponding to the cache line is only cached by the CPU, and other CPUs do not cache the content in the memory corresponding to the cache line. The data in the cache line in this state is consistent with the data in memory.
1: I ndicates that the content in the cache row is invalid.
S: This state means that the data is not only stored in the local CPU cache, but also in the cache of other CPUs. The data in this state is also consistent with the data in memory. However, as long as the CPU modifies the cache line, the state of the line will become I.
The state transition diagram of the four states is as follows:
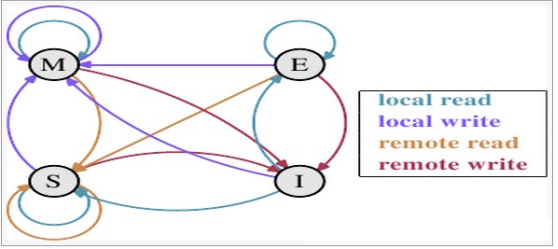
As mentioned above, different threads are likely to run on different CPU cores. When different CPUs operate the same block of memory, from the perspective of CPU0, CPU1 will continue to initiate remote write, which will always make the state of the cache migrate between S and I, Once the state changes to I, it will take more time to synchronize the state.
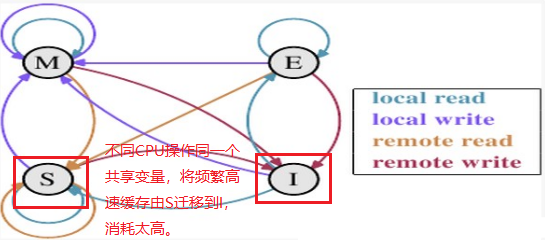
So we can basically get this Invoke(new DeleteDelegate(DeleteFileHandler), new object[] { sender,e }); ; After this seemingly insignificant line of code, the maintenance operation of files shared variables is inadvertently changed from multi-core and multi-threaded operation to multiple sub threads communicating with the main thread. All maintenance operations are carried out by the main thread, which also improves the final execution efficiency.
In depth interpretation, why use two locks
Under the current tide of using communication to replace shared memory, lock is actually the most important design.
We saw it in the Net, two lock s are used( this )And lock( threadCallbackList).
lock (this) {
if (threadCallbackList == null) {
threadCallbackList = new Queue();
}
}
lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}Yes NET can be understood as providing a lock similar to CAS (Compare And Swap). The principle of CAS constantly compares the "expected value" with the "actual value". When they are equal, it indicates that the CPU holding the lock has released the lock. Then the CPU trying to obtain the lock will try to write the value (0) of "new" to "p" (exchange) to indicate that it is a new owner of spinlock. The pseudo code is demonstrated as follows:
void CAS(int p, int old,int new)
{
if *p != old
do nothing
else
*p ← new
}CAS based lock efficiency is no problem, especially in the absence of multi-core competition, CAS is particularly outstanding, but CAS's biggest problem is unfair, because if there are multiple CPU at the same time apply for a lock, then just released the lock CPU is likely to gain the advantage in the next round of competition, get the lock again, this result is a CPU busy death, and other CPU is idle. We often criticize multi-core SOC that "one core is difficult and eight cores are onlookers". In fact, it is often caused by this injustice.
In order to solve the unfair problem of CAS, the great gods in the industry have introduced the TAS (Test And Set Lock) mechanism. Personally, I think it is better to understand T in TAS as a Ticket. The TAS scheme maintains a head and tail index value requesting the lock, which is composed of "head" and "tail".
struct lockStruct{
int32 head;
int32 tail;
} ;"Head" represents the head of the request queue, "tail" represents the tail of the request queue, and its initial value is 0.
At the beginning, the CPU of the first application finds that the tail value of the queue is 0, then the CPU will directly obtain the lock, update the tail value to 1, and update the head value to 1 when releasing the lock.
In general, when the CPU holding the lock releases it, the head value of the queue will be increased by 1. When other CPUs are trying to obtain the lock, the tail value of the lock will be obtained, and then the tail value will be increased by 1 and stored in their own exclusive register, and then the updated tail value will be updated to the tail of the queue. The next step is to continuously cycle comparison to determine whether the current "head" value of the lock is equal to the "tail" value stored in the register. If it is equal, it means that the lock is successfully obtained.
TAS is similar to that when users go to the government hall to do business, they first take the number from the number calling machine. When the number called by the staff is consistent with the number in your hand, you will obtain the ownership of the service counter.
However, TAS has some efficiency problems. According to the MESI protocol introduced above, the head and tail indexes of this lock are actually shared among CPU s. Therefore, frequent updates of tail and head will still lead to constant invalidation of cache adjustment, which will greatly affect the efficiency.
So we see in Net is simply introduced directly into the implementation of threadCallbackList Queue and keep TME( ThreadMethodEntry )Join the tail of the queue, and the process receiving messages keeps getting messages from the head of the queue

lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}When the head of the queue points to this tme, the message is sent. In fact, it is an implementation similar to MAS. Of course, MAS actually establishes an exclusive queue for each CPU, which is slightly different from the design of Invoke, but the basic idea is the same.
Many times when I was young, I couldn't taste the taste behind many things, which also made me miss a lot of technical points worth summarizing. Therefore, during the Spring Festival holiday, summarize the recent experience of using C# for the readers. I wish you a happy New Year!