In this series, I translated a series of articles written by the developers of collaborative process and Flow, in order to understand the reasons for the current design of collaborative process, Flow and LiveData, find their problems from the perspective of designers and how to solve them. pls enjoy it.
Kotlin Coroutines recently introduced two Flow types, SharedFlow and StateFlow. The Android community began to think about the possibility and significance of replacing LiveData with one or two of these new types. Two main reasons for this are:
- LiveData is closely linked to the UI
- LiveData is closely connected to the Android platform
We can draw a conclusion from these two facts. From the perspective of Clean Architecture, although LiveData runs well in the presentation layer, it is not suitable for the domain layer, because the domain layer is preferably platform independent (referring to pure Kotlin/Java modules); Moreover, it is not suitable for the data layer (Repositories implementation and data source), because we should usually hand over the data access work to the worker thread.

img
However, we can't just replace LiveData with pure Flow. The main problems of using pure Flow as an alternative to LiveData on all application layers are:
- Flow is stateless (not accessible through. value)
- Flow is declarative (cold): a flow builder only describes what flow is and is materialized only when collecting. However, a new flow is run (materialized) efficiently for each collector, which means that upstream (expensive) database access is run repeatedly for each collector.
- Flow itself does not understand the Android life cycle, nor does it provide automatic pause and recovery of the collector when the Android life cycle state changes.
❝ these can't be regarded as the inherent defects of pure Flow: these just make it can't well replace the characteristics of LiveData, but it can be powerful in other cases. For (3), we can already use the extension of LifecycleCoroutineScope, such as launchWhenStarted, to start coroutine to collect our Flow -- these collectors will automatically pause and recover synchronously with the Lifecycle of the component.
Note: in this article, we treat collect and observation as synonymous concepts. Collect is the preferred term for Kotlin Flow (we collect a Flow), and observation is the preferred term for Android LiveData (we observe a LiveData).
However, (1) -- get the current state, and (2) -- materialize only once for n > = 1 collectors, but not for 0 collectors. What's the matter?
Now, SharedFlow and StateFlow provide a solution to these two problems.
A practical example
Let's illustrate with a practical use case. Our use case is to get a nearby location. We assume that the Firebase real-time database is used with the GeoFire library, which allows querying nearby locations.
Using LiveData end-to-end

img
Let's first show the use of LiveData from the data source to the view. The data source is responsible for connecting to the Firebase real-time database through GeoQuery. When we receive onGeoQueryReady() or ongeoqueryrerror(), we update the LiveData value with the total number of places entered, exited or moved since the last onGeoQueryReady().
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
// Listener for receiving GeoLocations
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
_locations.value = State.Ready(map.toMap())
}
override fun onGeoQueryError(e: DatabaseError) {
_locations.value = State.Error(map.toMap(), e.toException())
}
}
// Listen for changes only while observed
private val _locations = object : MutableLiveData<State>() {
override fun onActive() {
geoQuery.addGeoQueryEventListener(listener)
}
override fun onInactive() {
geoQuery.removeGeoQueryEventListener(listener)
}
}
// Expose read-only LiveData
val locations: LiveData<State> by this::_locations
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
Our Repository, ViewModel and Activity should be as simple as this.
@Singleton
class NearbyUsersRepository @Inject constructor(
nearbyUsersDataSource: NearbyUsersDataSource
) {
val locations get() = nearbyUsersDataSource.locations
}
class NearbyUsersViewModel @ViewModelInject constructor(
nearbyUsersRepository: NearbyUsersRepository
) : ViewModel() {
val locations get() = nearbyUsersRepository.locations
}
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
viewModel.locations.observe(this) { state: State ->
// Update views with the data.
}
}
}
This approach may work well until you decide to make the domain layer containing the repository interface platform independent (because it should be). In addition, once you need to unload the work to the worker thread of the data source, you will find that using LiveData is not easy and there is no written method.
Using flows on Data Source and Repository
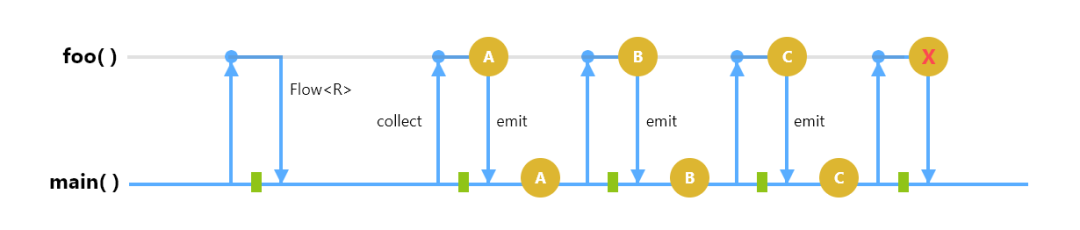
img
Let's convert our data source to use Flow. We have a flow builder, callbackFlow {}, which converts a callback into a cold Flow. When the Flow is collected, it runs the code block passed to the flow builder, adds the GeoQuery listener and reaches awaitClose {}, where it pauses until the Flow is closed (that is, until no one is collecting, or until it is cancelled due to any uncapped exceptions). When turned off, it deletes the listener and the traffic is cancelled.
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
private fun GeoQuery.asFlow() = callbackFlow {
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
emit(State.Ready(map.toMap()))
}
override fun onGeoQueryError(e: DatabaseError) {
emit(State.Error(map.toMap(), e.toException()))
}
}
addGeoQueryEventListener(listener)
awaitClose { removeGeoQueryEventListener(listener) }
}
val locations: Flow<State> = geoQuery.asFlow()
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
There are no changes in our Repository and ViewModel, but our Activity now receives Flow instead of LiveData, so it needs to be adjusted: instead of observing LiveData, it collects Flow.
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
lifecycleScope.launchWhenStarted {
viewModel.locations.collect {
// Update views with the data.
}
}
}
}
We use launchWhenStarted {} to collect Flow, so coroutine will start automatically only when the Activity reaches the onStart() Lifecycle state, and will pause automatically when it reaches the onStop() Lifecycle state. This is similar to the way LiveData provides us with automatic Lifecycle processing.
Note: you may choose to continue using LiveData in your presentation layer (activity). In this case, you can use Flow The aslivedata() extension function easily converts from Flow to LiveData in ViewModel. This decision will have some consequences, which we will discuss in the next lesson. We will show that using SharedFlow and StateFlow is more versatile end-to-end and may be more suitable for your architecture.

img
「What are the issues with using Flow in the View Layer?」
The first problem of this method is the processing of the life cycle, and LiveData will automatically process it for us. In the above example, we implemented a similar behavior by using launchWhenStarted {}.
But there is another problem: because Flow is declarative and only runs (materialized) during collection, if we have multiple collectors, each collector will run a new Flow, which is completely independent of each other. Depending on what you do, such as database or network operations, this can be very ineffective. If we expect the operation to be done only once to ensure correctness, it may even lead to an incorrect state. In our actual example, we will add a new GeoQuery listener for each collector -- it may not be a key problem, but it must be a waste of memory and CPU cycles.
❝ note: if you use Flow in ViewModel Aslivedata () converts your Repository Flow into LiveData, and LiveData will become the only collector of Flow. No matter how many observers there are in the presentation layer, only one Flow is collected. However, in order for this architecture to run smoothly, you need to ensure that each of your other components accesses your live data from the ViewModel rather than Flow directly from the Repository. This may prove to be a challenge, depending on the decoupling degree of your application: all components that need a Repository, such as the implementation of interactors (use cases), will now rely on activity instances to obtain ViewModel instances, and the scope of these components needs to be limited accordingly. We just want a GeoQuery listener, no matter how many collectors we have in the view layer. We can do this by sharing the process among all collectors.
SharedFlow to the rescue
SharedFlow is a stream that allows multiple collectors to share themselves, so for all simultaneous collectors, only one stream is effectively run (materialized). If you define a SharedFlow that accesses the database and it is collected by multiple collectors, the database access will run only once, and the generated data will be shared with all collectors.
StateFlow can also be used to achieve the same behavior: it is a dedicated SharedFlow with Value (its current state) and a specific SharedFlow configuration (constraint). We will discuss these constraints later.
We have an operator to convert any Flow to SharedFlow.
fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T> (source)
Let's apply it to our data source.
This range is where all calculations for materialized Flow will be completed. Since our data source is @ Singleton, we can use the application process's LifecycleScope, which is a LifecycleCoroutineScope. It is created when the process is created and destroyed only when the process is destroyed.
For the start parameter, we can use sharingstarted Whilesubscribed(), which makes our Flow share (materialize) only when the number of subscribers changes from 0 to 1, and stop sharing when the number of subscribers changes from 1 to 0. This is similar to the LiveData behavior we implemented earlier by adding a GeoQuery listener to the onActive() callback and removing the listener from the onInactive() callback. We can also configure it to start eagerly (materialize immediately and never de materialize) or lazily (materialize at the first collection and never de materialize), but we really want it to stop the upstream database collection when it is not collected by the downstream.
Note on terms: just as we use the term observer for LiveData and collector for cold flow, we use the term subscriber for SharedFlow. For replay parameters, we can use 1: the new subscriber will get the last issued value immediately after subscription.
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
private fun GeoQuery.asFlow() = callbackFlow {
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
emit(State.Ready(map.toMap())
}
override fun onGeoQueryError(e: DatabaseError) {
emit(State.Error(map.toMap(), e.toException())
}
}
addGeoQueryEventListener(listener)
awaitClose { removeGeoQueryEventListener(listener) }
}.shareIn(
ProcessLifecycleOwner.get().lifecycleScope,
SharingStarted.WhileSubscribed(),
1
)
val locations: Flow<State> = geoQuery.asFlow()
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
It may be helpful to think of SharedFlow as a flow collector itself. It concretizes our upstream cold flow into hot flow, and shares the collected values among many downstream collectors. There is an intermediary between the cold flow upstream and multiple collectors downstream.
Now, we may think that our activities do not need to be adjusted. Wrong! There is a problem: when collecting traffic in a coroutine started with launchWhenStarted {}, coroutine will pause. The looper will pause at onStop() and resume at onStart(), but it will still be subscribed to the stream. For MutableSharedFlow, this means MutableSharedFlow The subscriptioncount does not change for paused coroutines. To take advantage of sharingstarted With the power of whilesubscribed(), we need to actually unsubscribe on onStop() and subscribe again on onStart(). This means canceling the collected looper and re creating it.
(see current issue and current issue for more details).
Let's create a class for this general purpose.
@PublishedApi
internal class ObserverImpl<T> (
lifecycleOwner: LifecycleOwner,
private val flow: Flow<T>,
private val collector: suspend (T) -> Unit
) : DefaultLifecycleObserver {
private var job: Job? = null
override fun onStart(owner: LifecycleOwner) {
job = owner.lifecycleScope.launch {
flow.collect {
collector(it)
}
}
}
override fun onStop(owner: LifecycleOwner) {
job?.cancel()
job = null
}
init {
lifecycleOwner.lifecycle.addObserver(this)
}
}
inline fun <reified T> Flow<T>.observe(
lifecycleOwner: LifecycleOwner,
noinline collector: suspend (T) -> Unit
) {
ObserverImpl(lifecycleOwner, this, collector)
}
inline fun <reified T> Flow<T>.observeIn(
lifecycleOwner: LifecycleOwner
) {
ObserverImpl(lifecycleOwner, this, {})
}
Note: if you want to use this custom viewer in your project, you can use this library: https://github.com/psteiger/flow-lifecycle-observer Now, we can adjust our Activity to use the one we just created Observein (lifecycle owner) extension function.
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
viewModel
.locations
.onEach { /* new locations received */ }
.observeIn(this)
}
}
When the Lifecycle of the Lifecycle owner reaches the CREATED state (just before the onStop() call), the collector coroutine CREATED with observein (Lifecycle owner) will be destroyed. Once it reaches the STARTED state (after the onStart() call), it will be re CREATED.
Note: why is the CREATED status? Shouldn't it be STOPPED? It sounds strange at first, but it makes sense. Lifecycle.State has only the following states.
Create, destroy, initialize, restore, start. There are no STOPPED and PAUSED states. When the lifecycle reaches onPause(), it does not enter a new state, but returns to the STARTED state. When it reaches onStop(), it returns to the CREATED state.

img
We now have a data source that is implemented only once, but shares its data with all subscribers. Once there is no subscriber, its upstream collection will stop, and once the first subscriber reappears, it will restart. It has no dependency on the Android platform and is not bound to the main thread (by simply applying the. flowOn() operator: flowOn(Dispatchers.IO) or flowOn(Dispatchers.Default), traffic conversion can occur in other threads).
But what if I need to eventually access the current state of the flow without collecting it?
If we really need to use it like LiveData value to access the state of Flow. We can use StateFlow, which is a special and limited SharedFlow. Instead of applying the shareIn() operator, we can apply stateIn() to materialize the Flow.
fun <T> Flow<T>.stateIn(
scope: CoroutineScope,
started: SharingStarted,
initialValue: T
): StateFlow<T> (source)
From the method parameters, we can see that there are two basic differences between sharedIn() and stateIn().
- stateIn() does not support customization of replay. StateFlow is a SharedFlow with fixed replay = 1. This means that new subscribers will get the current status immediately when they subscribe.
- stateIn() requires an initial value. This means that if you don't have an initial value at that time, you will need to make StateFlow type T null, or use a sealed class to represent an empty initial value.
❝ the state flow is a shared flow State flow is a special-purpose, high-performance and efficient implementation of SharedFlow for the narrow but widely used situation of sharing state. See the SharedFlow documentation for basic rules, constraints, and operators that apply to all shared flows. The state flow always has an initial value. It copies the latest value to the new subscriber, does not buffer any more values, but retains the last issued value, and does not support resetReplayCache. When a state flow is created with the following parameters and the distinct until changed operator is applied to it, its behavior is exactly the same as that of a shared flow
// MutableStateFlow(initialValue) is a shared flow with the following parameters:
val shared = MutableSharedFlow(
replay = 1,
onBufferOverflow = BufferOverflow.DROP_OLDEST
)
shared.tryEmit(initialValue) // emit the initial value
val state = shared.distinctUntilChanged() // get StateFlow-like behavior
When you need a StateFlow with behavior adjustments, use SharedFlow, such as additional buffering, replaying more values, or omitting initial values.
However, pay attention to the obvious compromise of choosing SharedFlow: you will lose stateflow value.
Which to choose, StateFlow or SharedFlow?
The simple way to answer this question is to try to answer several other questions.
"Do I really need to use myFlow.value to access the current state of the flow at any time?"
❝ if the answer to this question is no, you can consider SharedFlow. ❞
"Do I need to support launching and collecting duplicate values?"
❝ if the answer to this question is yes, you will need SharedFlow. ❞
"Do I need to replay more than the latest value for new subscribers?"
❝ if the answer to this question is yes, you will need SharedFlow. ❞
As we can see, StateFlow for all things is not automatically the right answer.
- It ignores (confuses) duplicate values, which are not configurable. Sometimes you need not to ignore duplicate values. For example, for a connection attempt, store the attempt results in a stream and try again after each failure.
- In addition, it requires an initial value. Because SharedFlow doesn't Value, so it doesn't need to be instantiated with the initial value -- the collector will pause directly until the first value appears, and no one will try to access it until any value arrives value. If you do not have the initial value of StateFlow, you must make the StateFlow type nullable T?, And use null as the initial value (or declare a sealed class for the default no value).
- In addition, you may want to adjust the playback value. SharedFlow can replay the last n values for new subscribers. StateFlow has a fixed replay value of 1 -- it only shares the current state value.
Both support sharingstarted (eagerly, lazy or whilesubscribed()) configuration. I usually use sharingstarted Whilesubscribed() and destroy / create all my collectors on Activity onStart()/onStop(), so when users do not actively use the application, the upstream collection of data sources will stop (this is similar to deleting / re adding listeners on LiveData onActive()/onInactive()).
StateFlow's constraints on SharedFlow may not be the best for you. You may want to use behavior to adjust and choose to use SharedFlow. Personally, I rarely need to access myflow Value, and I like the flexibility of SharedFlow, so I usually choose SharedFlow.
Read more about StateFlow and SharedFlow in the official documentation.
A practical case where SharedFlow instead of StateFlow is needed
Consider the following wrapper around Google billing client library. We have a MutableSharedFlow billingClientStatus to store the current connection status with the billing service.
We set its initial value to SERVICE_DISCONNECTED. We collect billingClientStatus, and when it is uncertain, we try to start a connection with the billing service (). If the connection attempt fails, we will issue SERVICE_DISCONNECTED.
In this example, if billingClientStatus is a MutableStateFlow instead of MutableSharedFlow, its value is already SERVICE_DISCONNECTED, and we try to set it to the same value (connection retry failed), it will ignore the update, so it will not try to reconnect again.
@Singleton
class Biller @Inject constructor(
@ApplicationContext private val context: Context,
) : PurchasesUpdatedListener, BillingClientStateListener {
private var billingClient: BillingClient =
BillingClient.newBuilder(context)
.setListener(this)
.enablePendingPurchases()
.build()
private val billingClientStatus = MutableSharedFlow<Int>(
replay = 1,
onBufferOverflow = BufferOverflow.DROP_OLDEST
)
override fun onBillingSetupFinished(result: BillingResult) {
billingClientStatus.tryEmit(result.responseCode)
}
override fun onBillingServiceDisconnected() {
billingClientStatus.tryEmit(BillingClient.BillingResponseCode.SERVICE_DISCONNECTED)
}
// ...
// Suspend until billingClientStatus == BillingClient.BillingResponseCode.OK
private suspend fun requireBillingClientSetup(): Boolean =
withTimeoutOrNull(TIMEOUT_MILLIS) {
billingClientStatus.first { it == BillingClient.BillingResponseCode.OK }
true
} ?: false
init {
billingClientStatus.tryEmit(BillingClient.BillingResponseCode.SERVICE_DISCONNECTED)
billingClientStatus.observe(ProcessLifecycleOwner.get()) {
when (it) {
BillingClient.BillingResponseCode.OK -> with (billingClient) {
updateSkuPrices()
handlePurchases()
}
else -> {
delay(RETRY_MILLIS)
billingClient.startConnection(this@Biller)
}
}
}
}
private companion object {
private const val TIMEOUT_MILLIS = 2000L
private const val RETRY_MILLIS = 3000L
}
}
In this case, we need to use SharedFlow, which supports the emission of continuous duplicate values.
On the GeoFire use-case
If you have a practical need to use GeoFire, I have developed a library, GeoFire KTX, which allows you to convert GeoQuery objects to Flow at any time. It also supports obtaining datasnaps located in other DatabaseReference roots with the same subkeys as GeoFire roots, because this is a common use case of GeoQuery. It also supports obtaining the data as an instance of a class rather than a data snapshot. This is done through Flow conversion. The source code of the library completes the example given in this paper.
For other Android libraries, see https://github.com/psteiger .
https://github.com/psteiger/geofire-ktx/blob/master/geofire/src/main/java/com/freelapp/geofire/flow/GeoQuery.kt
Original link: https://proandroiddev.com/should-we-choose-kotlins-stateflow-or-sharedflow-to-substitute-for-android-s-livedata-2d69f2bd6fa5
Focus on Android kotlin fluent welcome to visit
Author: Xu Yisheng