That day, little ape went to Ali for an interview. As soon as the interviewer Lao Wang came up, he threw him an interview question: why is it mandatory not to delete elements in foreach in Ali's Java development manual? The little ape looked happy after hearing this, because two years ago, 2019 In, he saw this question in the column of the advanced road of Java programmers 😆.
https://github.com/itwanger/toBeBetterJavaer
For the sake of the town building, first move a paragraph of English to explain fail fast.
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process. Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
The general meaning of this paragraph is that fail fast is a general system design idea. Once an error is detected, an exception will be thrown immediately, and the program will no longer be executed.
public void test(Wanger wanger) {
if (wanger == null) {
throw new RuntimeException("wanger Cannot be empty");
}
System.out.println(wanger.toString());
}
Once it is detected that wanger is null, it immediately throws an exception and lets the caller decide what to do in this case. wanger.toString() will not be executed in the next step -- to avoid more serious errors.
Many times, we will classify fail fast as an error detection mechanism of Java collection framework, but in fact, fail fast is not a unique mechanism of Java collection framework.
The reason why we put fail fast in the collection framework is that the problem is easy to reproduce.
List<String> list = new ArrayList<>();
list.add("Qing procedural ape");
list.add("Qing procedural ape");
list.add("A programmer whose article is really interesting");
for (String str : list) {
if ("Qing procedural ape".equals(str)) {
list.remove(str);
}
}
System.out.println(list);
This code seems to have no problem, but it runs with an error.

According to the wrong stack information, we can locate line 901 of ArrayList.
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
In other words, the checkForComodification method is triggered when removing. This method compares modCount and expectedModCount, and finds that they are not equal, so it throws a ConcurrentModificationException.
Why is the checkforconfirmation method executed?
Because for each is essentially a syntax sugar, and the bottom layer is implemented through the Iterator and the while loop. Take a look at the decompiled bytecode.
List<String> list = new ArrayList();
list.add("Qing procedural ape");
list.add("Qing procedural ape");
list.add("A programmer whose article is really interesting");
Iterator var2 = list.iterator();
while(var2.hasNext()) {
String str = (String)var2.next();
if ("Qing procedural ape".equals(str)) {
list.remove(str);
}
}
System.out.println(list);
Take a look at the iterator method of ArrayList:
public Iterator<E> iterator() {
return new Itr();
}
The internal class Itr implements the Iterator interface.
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
}
in other words new Itr() expectedModCount is assigned to modCount, and modCount is a member variable of the list, indicating the number of times the collection has been modified. Because the list executed the add method three times before.
- The add method calls the ensureCapacityInternal method
- The ensuurecapacityinternal method calls the ensureExplicitCapacity method
- In the ensureExplicitCapacity method modCount++
Therefore, the value of modCount is 3 after three times of add, so new Itr() The post expectedModCount value is also 3.
When the first loop is executed, it is found that "silence king two" is equal to STR, so it is executed list.remove(str).
- The remove method calls the fastRemove method
- Is executed in the fastRemove method modCount++
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
The value of modCount becomes 4.
When executing the second cycle, the next method of Itr will be executed (String str = (String) var3.next();), and the next method will call the checkForComodification method. At this time, the expectedModCount is 3 and the modCount is 4, so you have to throw the ConcurrentModificationException exception.
In fact, it is also mentioned in Alibaba's Java development manual that do not remove/add elements in the for each loop. Remove element, use Iterator mode.
The reason is actually the above analysis, due to the fail fast protection mechanism.
How to delete elements correctly?
1) break after remove
List<String> list = new ArrayList<>();
list.add("Qing procedural ape");
list.add("Qing procedural ape");
list.add("A programmer whose article is really interesting");
for (String str : list) {
if ("Qing procedural ape".equals(str)) {
list.remove(str);
break;
}
}
After the break, the loop is no longer traversed, which means that the next method of the Iterator is no longer executed, which means that checkForComodification The method is no longer executed, so the exception will not be thrown.
However, when there are duplicate elements in the List to be deleted, break is not appropriate.
2) for loop
List<String> list = new ArrayList<>();
list.add("Qing procedural ape");
list.add("Qing procedural ape");
list.add("A programmer whose article is really interesting");
for (int i = 0, n = list.size(); i < n; i++) {
String str = list.get(i);
if ("Qing procedural ape".equals(str)) {
list.remove(str);
}
}
Although the for loop can avoid the fail fast protection mechanism, that is, it will not throw an exception after removing the element; However, this procedure is problematic in principle. Why?
In the first cycle, i is 0 and list.size() is 3. After the remove method is executed, i is 1 and list.size() becomes 2. Because the size of list changes after remove, it means that the element "Qing Dynasty program ape" is skipped. Can you understand?
Before remove, list.get(1) was "Qing Dynasty program"; But after remove, list.get(1) became "a programmer whose article is really interesting", and list.get(0) became "Qing Dynasty program ape".
3) Using Iterator
List<String> list = new ArrayList<>();
list.add("Qing procedural ape");
list.add("Qing procedural ape");
list.add("A programmer whose article is really interesting");
Iterator<String> itr = list.iterator();
while (itr.hasNext()) {
String str = itr.next();
if ("Qing procedural ape".equals(str)) {
itr.remove();
}
}
Why can the remove method of Iterator avoid the fail fast protection mechanism? Just look at the source code of remove.
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
It will be executed after deletion expectedModCount = modCount, which ensures the synchronization of expectedModCount and modCount.
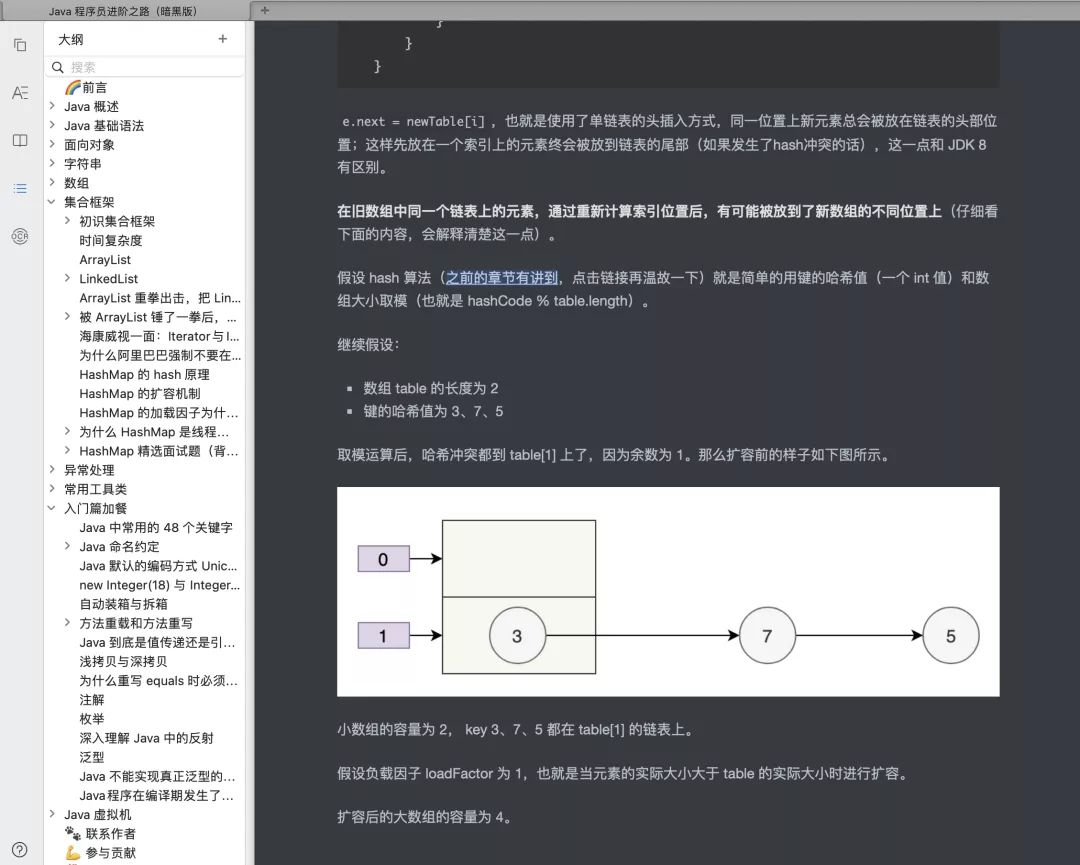
To sum up, fail fast is a protection mechanism, which can be verified by deleting the elements of the collection through a for each loop.
In other words, for each is essentially a syntax sugar. It is very important to traverse the collection, but it is not suitable for manipulating the elements in the collection (addition and deletion).
This is the 63rd column of the advanced path of Java programmers. The advanced path of Java programmers is funny, humorous, easy to understand, and extremely friendly and comfortable for java beginners 😘, The content includes but is not limited to Java syntax, Java collection framework, Java IO, Java Concurrent Programming, Java virtual machine and other core knowledge points.
https://github.com/itwanger/toBeBetterJavaer
The PDF of bright white version and dark version are also ready to become better Java engineers together, Chong!
Finally, pdf pays attention to the private letter reply "666".