Today, when studying the Java concurrency container and framework, we can see why we should use ConcurrentHashMap. One reason is: thread unsafe HashMap. HashMap will cause a dead loop when executing put operation concurrently, because multithreading will cause the Entry linked list of HashMap to form a ring data structure and fall into a dead loop when searching.
After correcting the reasons, I read other blogs, which are more abstract, so here I show them in the form of graphics. I hope to support them!
1) When adding elements to HashMap, it will cause the expansion of HashMap container. The principle will not be explained, and the source code will be attached directly, as follows:
/**
*
* Add elements to the table. If the table is not long enough after inserting elements, the resize method will be called to expand the capacity
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
/**
* resize()The methods are as follows. The most important is the transfer method, which adds the elements in the old table to the new table
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
2) Referring to the above code, the transfer method is introduced. (key point of introduction) this is the root cause of dead cycle when HashMap is concurrent. Next, combined with the source code of transfer, explain the principle of life and death cycle. First list the transfer code (this is the source module of JDK7), as follows:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; ---------------------(1)
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} // while
}
}
3) Assumptions:
Map<Integer> map = new HashMap<Integer>(2); // Only two elements can be placed, of which the threshold is 1 (when only one element is filled in the table), that is, the capacity will be expanded when the inserted element is 1 (known from the addEntry method) //Two elements 3 and 7 are placed. If you want to place another element 8 (not equal to 1 after hash mapping), it will cause capacity expansion
The hypothetical placement results are shown as follows:
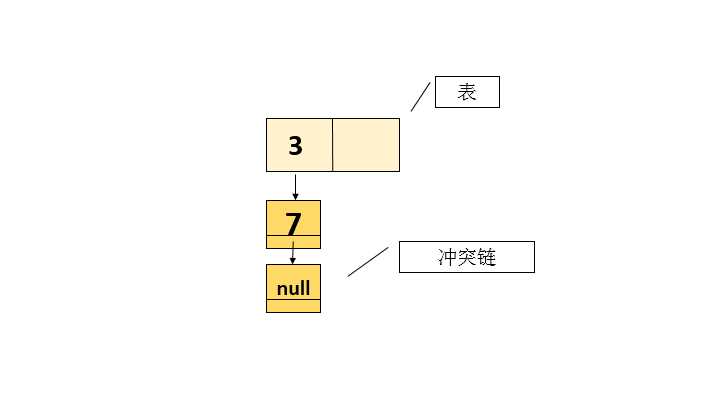
Now there are two threads A and B, both of which need to perform the put operation, that is, add elements to the table, that is, thread A and thread B will see the state snapshot in the figure above.
The execution sequence is as follows:
Execution 1: thread A is suspended at (1) in the transfer function (marked in the transfer function code). In the stack of thread A:
e = 3 next = 7
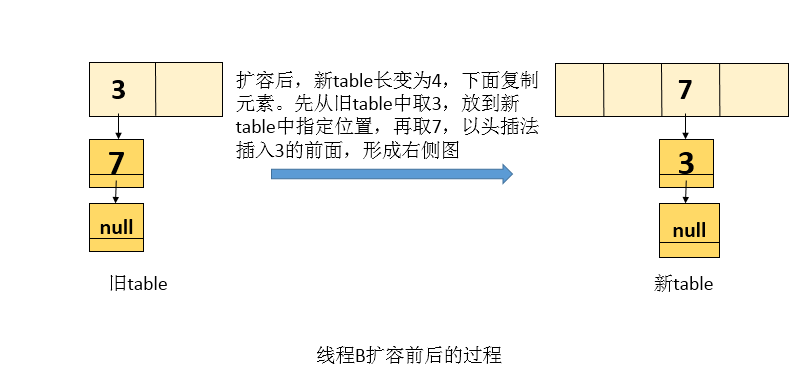
Execution 2: thread B executes the while loop in the transfer function, that is, it will change the original table into a new table (in thread B's own stack) and then write it to memory. As shown in the following figure (assuming that the two elements will also be mapped to the same location under the new hash function)
Execution 3: thread A is disconnected and then executed (the old table is still seen), that is, it is executed from the transfer code (1). The current e = 3 and next = 7, which have been described above.
-
Process element 3 and put 3 into the new table of thread A's own stack (the new table is in thread A's own stack, which is thread private and does not affect thread 2). The figure after processing 3 is as follows:
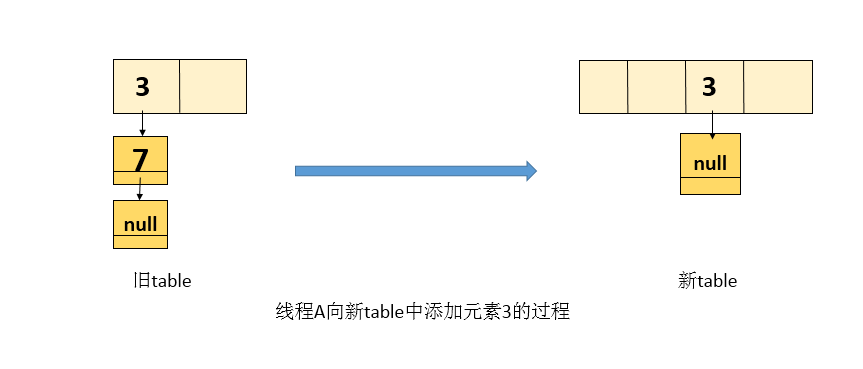
-
Thread A copies element 7 again. The current e = 7, while the next value is 3 because thread B modifies its reference. The new table after processing is as follows:
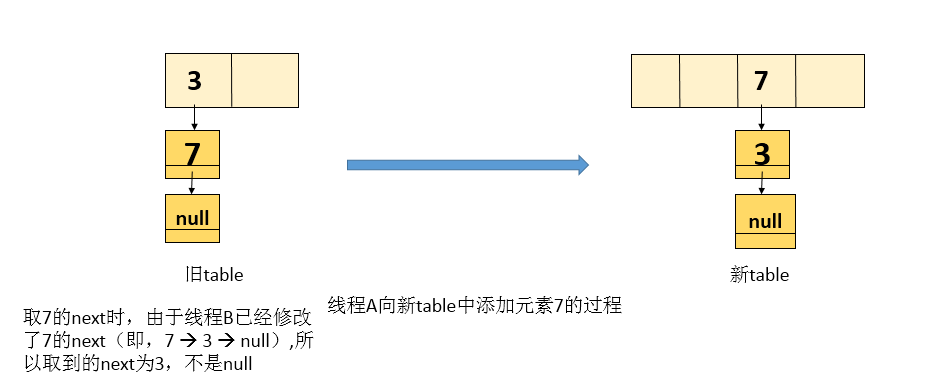
-
Since the next = 3 obtained above, and then the while loop, that is, the current processing node is 3, and the next is null, exit the while loop. After executing the while loop, the contents in the new table are as follows:
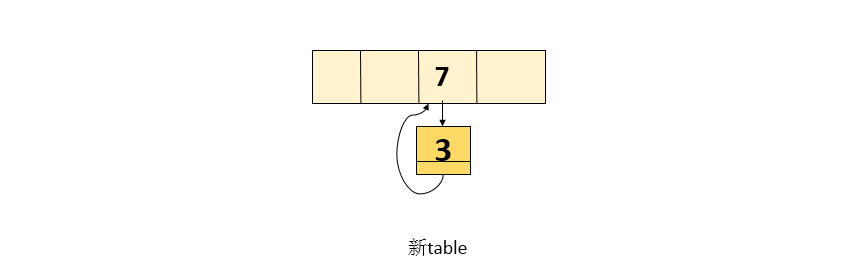
-
When the operation is completed and the search is performed, it will fall into an endless loop!