1 windowing function
- The OVER clause is allowed only in the SELECT and ORDER BY processing phases
Two sum()over() in a select cannot be divided - Logical order of sql execution:
FROM,WHERE,GROUP BY,HAVING,
SELECT ,OVER,DISTINCE,
TOP,ORDER BY - Data scenario
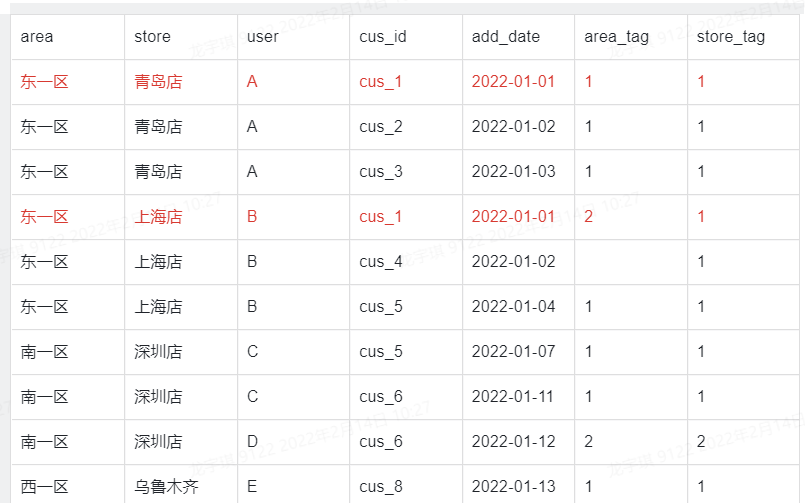
According to the above data, it is necessary to count how many customers wechat experts have added in the specified time period, how many customers corresponding to the store and how many customers in the region.
SELECT distinct
area,
store,
sum(if(store_tag=1,1,0)) over(partition by area,store) as store_num,
sum(if(area_tag=1,1,0)) over(partition by area) as area_num
FROM
(
SELECT
area,
store,
user,
cus_id,
add_date,
row_number() over(partition by area,store,cus_id order by add_date) as store_tag,
row_number() over(partition by area,cus_id order by add_date) as area_tag
FROM table_user_log
WHERE (a.add_date between '2022-01-01' and '2022-01-31')
) a
;
- uid,city_id,province_id,visit_date
Find the number of people visiting cities and provinces in a certain month
- Idea: row_number() over(partition by province_id order by visit_date) as uid_s
Then sum monthly uid_s=1
- sales_date,uid,amt
Find the sales of each month and the proportion of monthly sales in the whole year
select
date_time,
province,
mon_num/year_num as mon_rate
from
(select distinct
date_time,
province,
sum(number) over(partition by province,date_time) as mon_num,
sum(number) over(partition by province) as year_num
from da_dmp_tidb.dwd_market_competition_insur_df
where substr(date_time,1,4)='2021'
and (fuel_type='Plug in hybrid' or fuel_type='Pure electric')
) t1
order by
date_time,
province
-----------------Optimization:-------------------------
--date_time Form: 202202
select date_time ,
sum(number) as sales_amt,
sum(sum(number)) over(partition by substr(date_time,1,4)) as yearly_sales_amt,
sum(number) / sum(sum(number)) over(partition by substr(date_time,1,4)) sales_rate
from da_dmp_tidb.dwd_market_competition_insur_df
WHERE substr(date_time,1,4)='2021'
AND (fuel_type='Plug in hybrid' or fuel_type='Pure electric')
group by 1
;
- Windowing function instead of subquery
count(*) over() (select count(*) from t_person where fsalary < 5000)
- Usage of Order by
--ORDER BY Field name RANGE|ROWS BETWEEN Boundary rule 1 AND Boundary rule 2
--rows
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary rows between unbounded preceding and current row) --Sum salary in current line
from t_person
--range Locate by range
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary range between unbounded preceding and current row) Sum salary in current line
from t_person
--replace row_number According to the usage of FSalary Rank
--Calculate from the first line( UNBOUNDED PRECEDING)To current row( CURRENT ROW)Number of personnel
SELECT FName, FSalary,COUNT(*) OVER(ORDER BY FSalary ROWS BETWEEN UNBOUNDED PRECEDING ANDCURRENT ROW)
FROM T_Person;
RANGE indicates that the RANGE is defined according to the RANGE of values, while ROWS indicates that the RANGE is defined according to the RANGE of ROWS
2. Data quality assurance
https://help.aliyun.com/document_detail/123971.html
Data quality operation guide
1. Data quality risk monitoring
- Integrity:
Pay attention to whether the number of table rows is greater than 0, whether the number of table rows fluctuates normally, and whether fields have null values or duplicates - Accuracy:
Judge whether the data is accurate according to the business logic. In this case, if the UV and PV values are less than 0, it is obviously wrong data. - uniformity:
For different business processes and nodes, the same data must be consistent. For example, if there are Zhejiang and ZJ expressions in the province field of the table, two records will appear when group by province. - Timeliness:
Timeliness is mainly reflected in that the data of the final ADS layer can be output in time. The intelligent monitoring function of DataWorks can be used to ensure the timeliness of each link of data processing.
2. Data asset grading
Do we have asset grading work here?
3. Verification of online card points for task release
- For standard mode projects, you can use SQL statements to copy data from the production environment to the development environment, run business processes, and observe whether there are errors.
- For simple mode projects, you can directly run the business process to observe whether there are errors.
Simple mode project refers to a Dataworks workspace corresponding to a MaxCompute project. The development environment and production environment cannot be set, and only simple data development can be carried out. The simple mode workspace cannot have strong control over the data development process and table permissions. Advantages: fast iteration. After the code is submitted, it can take effect without publishing. Risk: the permission of the development role is too large. You can delete the table under this workspace at will, resulting in the risk of table permission.
4. Data quality risk monitoring
It mainly aims at the accuracy, consistency and integrity of data
- Monitoring classification: data volume, primary key, discrete value, summary value, business rules and logic rules.
- Monitoring granularity: field level and table level.
- Monitoring level: ODS, CDM and ADS layers of data, in which ODS and DWD layers mainly focus on data integrity and consistency. DWS and ADS layers have small amount of data and complex logic, and pay more attention to the accuracy of data.