Article catalog
- preface
- 1, Demand analysis
- 2, Code implementation
- 1. Baidu character recognition
- 2. View the document to get access_token
- 3. Picture code
- 4. Code interpretation
- 3, Effect display
Many people study python,I don't know where to start. Many people study python,After mastering the basic grammar, I don't know where to find cases. Many people who have done cases do not know how to learn more advanced knowledge. So for these three types of people, I will provide you with a good learning platform, free video tutorials, e-books, and the source code of the course! QQ Group:861355058 Welcome to join, discuss and study together!
preface
Just a few days ago, a freshman broke my busy life. I wondered. I directly asked her what happened (old straight man)
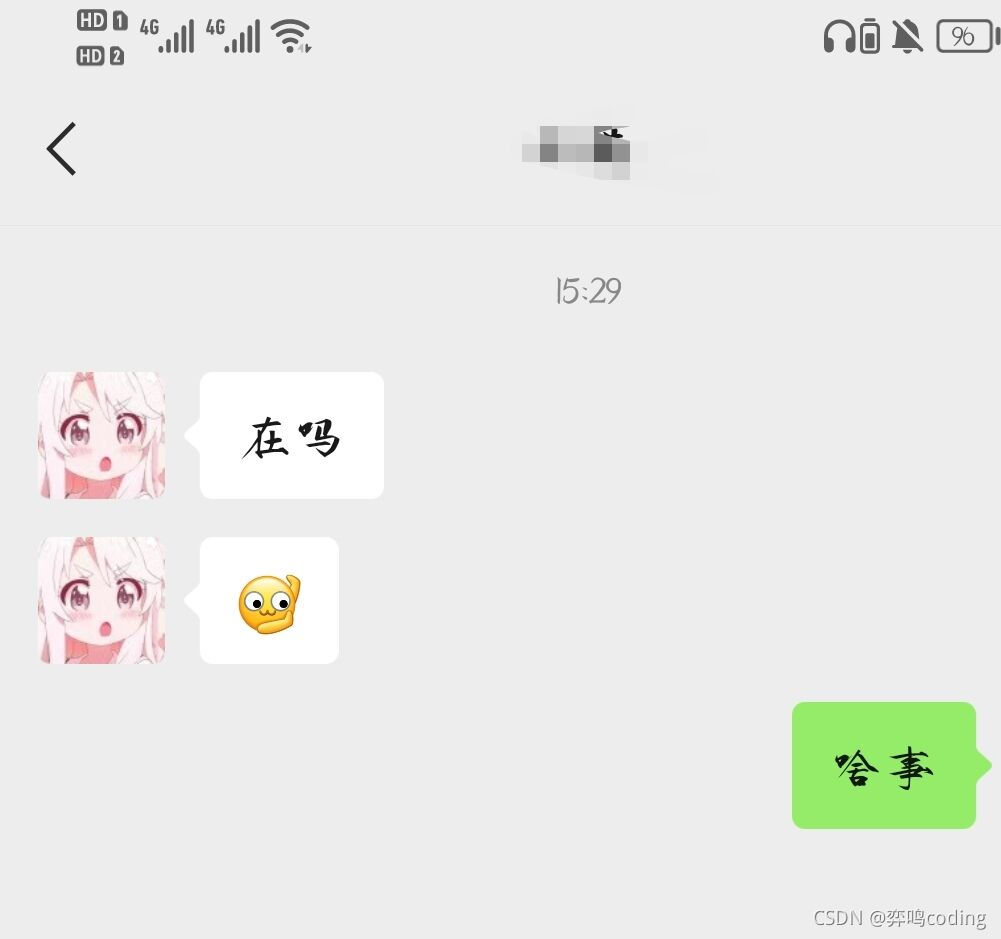
It turned out to be asking me for a favor. As a good senior, I must be happy to help others
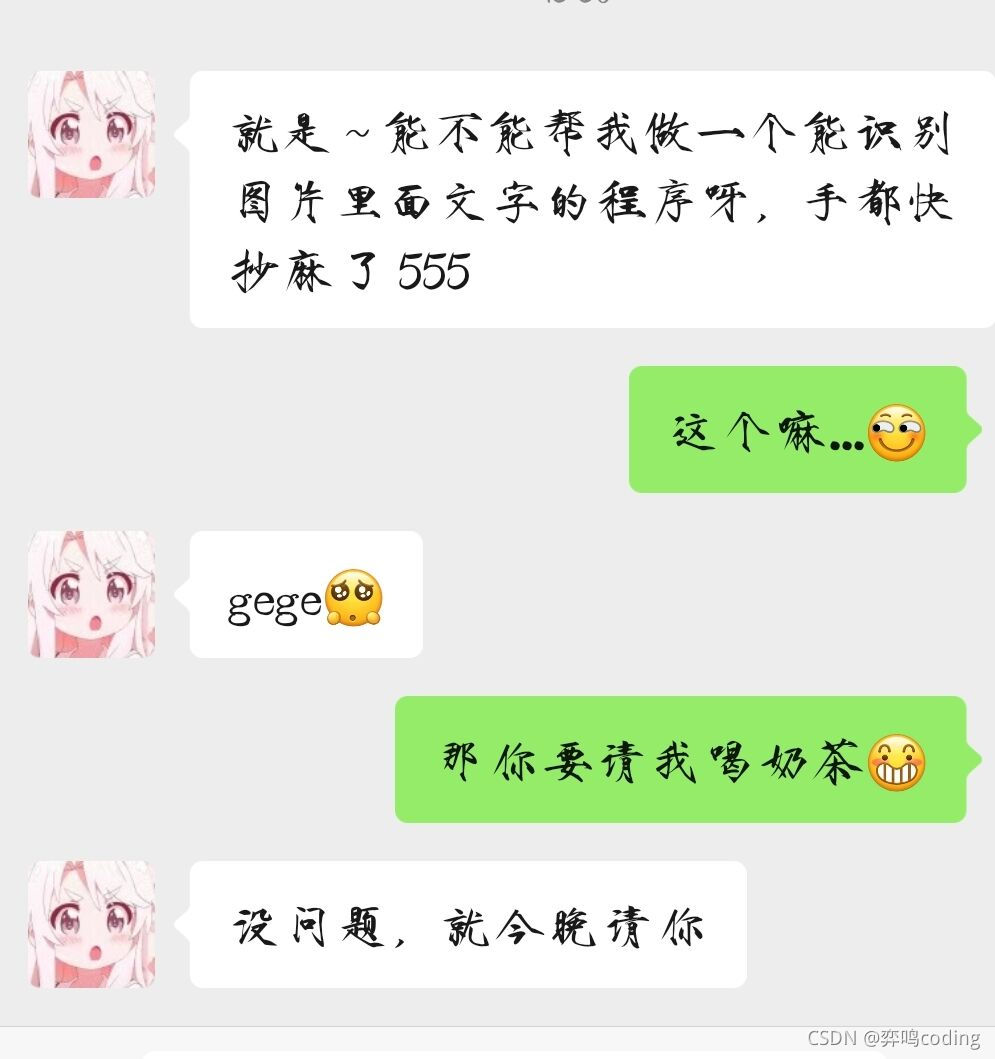
Don't say much and get to the point
1, Demand analysis
According to Xuemei's description, I just want a program that can recognize pictures and words. No matter what typesetting, I can directly recognize them in turn. It's mainly busy... Then I can directly use Baidu's ocr and finish it in half an hour!
2, Code implementation
1. Baidu character recognition
Official entrance of character recognition
https://ai.baidu.com/tech/ocr/general

Click to use it immediately. Let's go whoring for nothing. Anyway, it's less than 1000 times a month
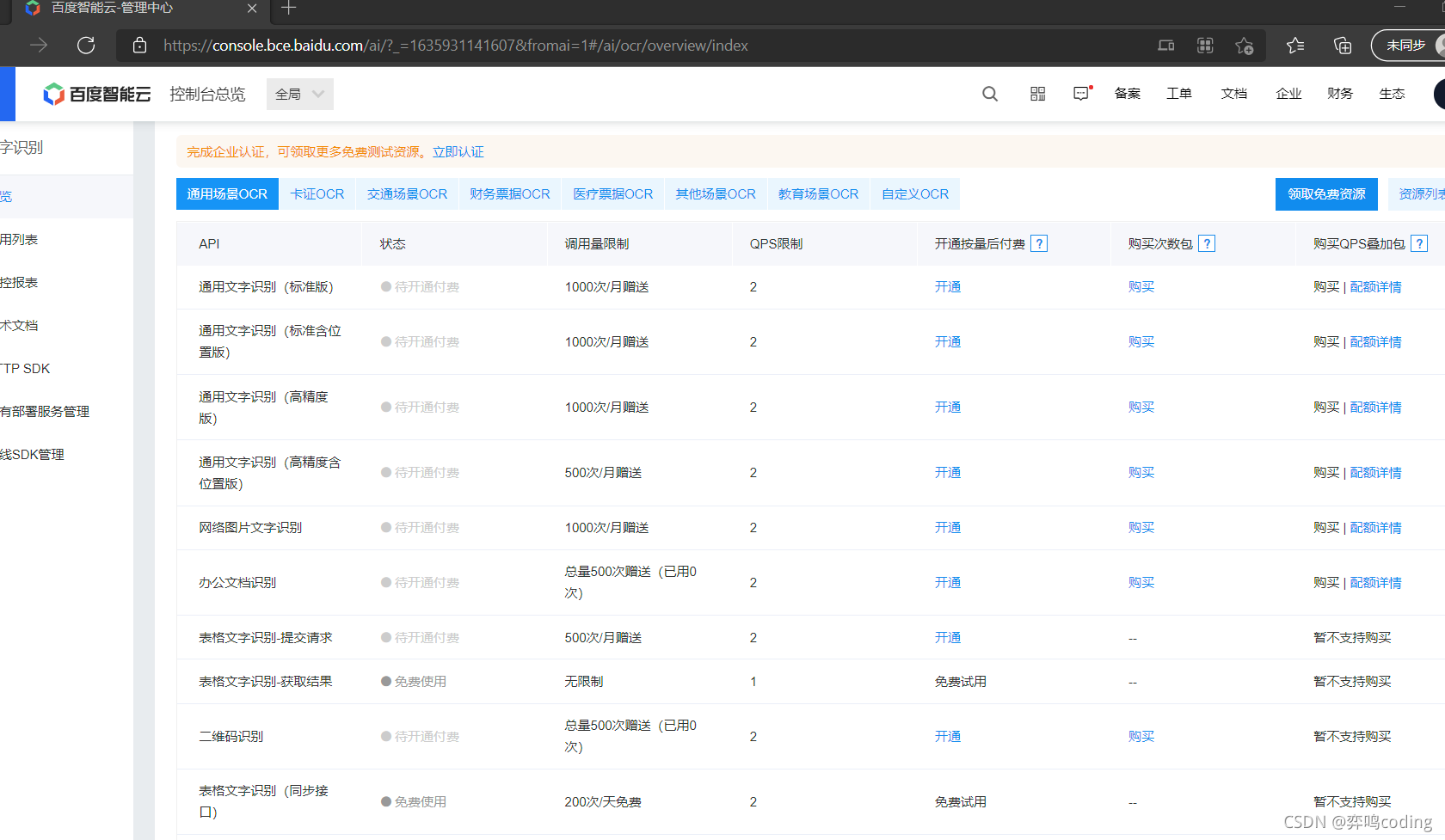
Create an application, enter the application name, this is optional, and then choose a character recognition - free, if I have money, when I didn't say it.
The following figure is created successfully.
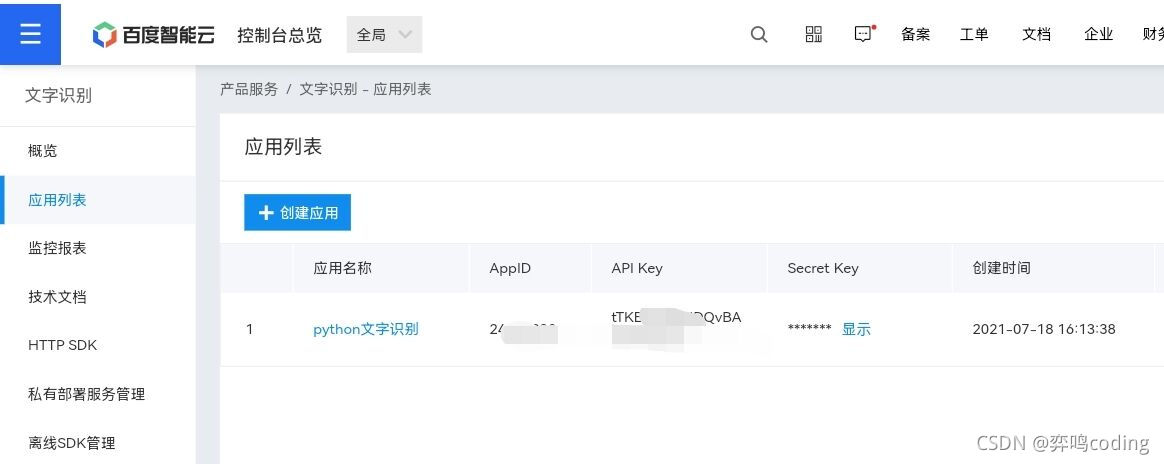
API Key and Secret Key are to be used.
2. View the document to get access_token
The next step is to look at the documents and see how they are used
https://ai.baidu.com/ai-doc/OCR/1k3h7y3db
If you can't read the documents, I'll just talk about what I need. Let's learn the rest by ourselves.
From the document point of view, we first need to get one thing - access_token
Official website code
# encoding:utf-8 import requests # client_id Obtained for the official website AK, client_secret Obtained for the official website SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_ type=client_ credentials&client_ Id = [AK obtained on the official website] & Client_ Secret = [SK obtained on the official website]' response = requests.get(host) if response: print(response.json()) My code import requests def access_token(): url = 'https://aip.baidubce.com/oauth/2.0/token' token_ = { 'grant_type': 'client_credentials', # API Key 'client_id': 'Obtained on the official website AK', # ecret Key 'client_secret': 'Obtained on the official website SK' } res = requests.post(url, data=token_) res = res.json() print(res) access_token = res['access_token'] print(access_token) return access_token if __name__ == '__main__': access_token()
The official website says that it is recommended to use post, so we use post, but the official code uses the method of get. In fact, the results are the same, and we can get the required data. But the official code still needs one step to extract access_token.
access_token = response.json()['access_token']

Then you can get access_token.

If you encounter errors in this process, there are documents, and they will be more detailed than I said, so if you encounter problems, you can read the documents first. If you can't, you can ask me.
Get access_token function
def access_token(): url = 'https://aip.baidubce.com/oauth/2.0/token' token_ = { 'grant_type': 'client_credentials', # API Key 'client_id': 'Own acquisition', # ecret Key 'client_secret': 'Own acquisition' } res = requests.post(url, data=token_) res = res.json() print(res) access_token = res['access_token'] print(access_token) return access_token
Just call it directly when we need it.

According to the instructions of the document, we began to write the code to read the image
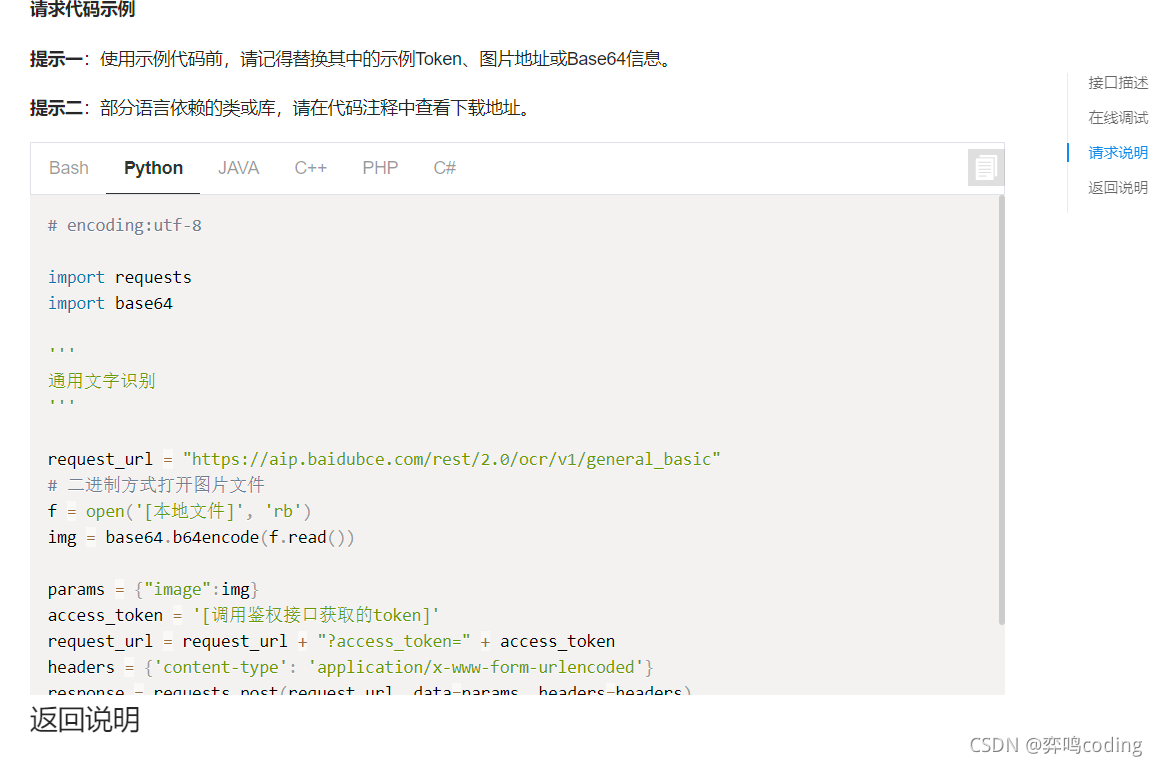
3. Picture code
def raed_pic(): url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate" request_url = url + "?access_token=" + access_token() f = open('6.jpg', 'rb') img = base64.b64encode(f.read()) # See the document for parameters params = {"image": img, "language_type": "CHN_ENG", "recognize_granularity": "small", } headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) # print(response) # res = response.json() # print(res) # Judge whether the response is successful if response: # Save the read text file and create it automatically file_name = "yiming6.txt" # What I didn't say is write operation with open(file_name, 'w', encoding='utf-8') as f: for j in res: f.write(j["words"] + "\n")
4. Code interpretation
From the json analysis, we only need to extract the words_ Words in result

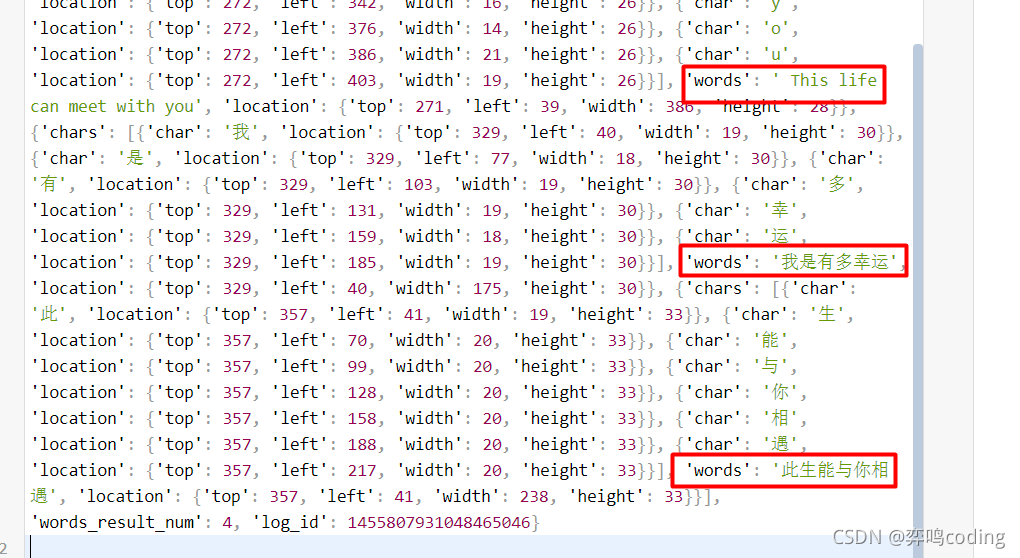
3, Effect display
The effects are as follows:
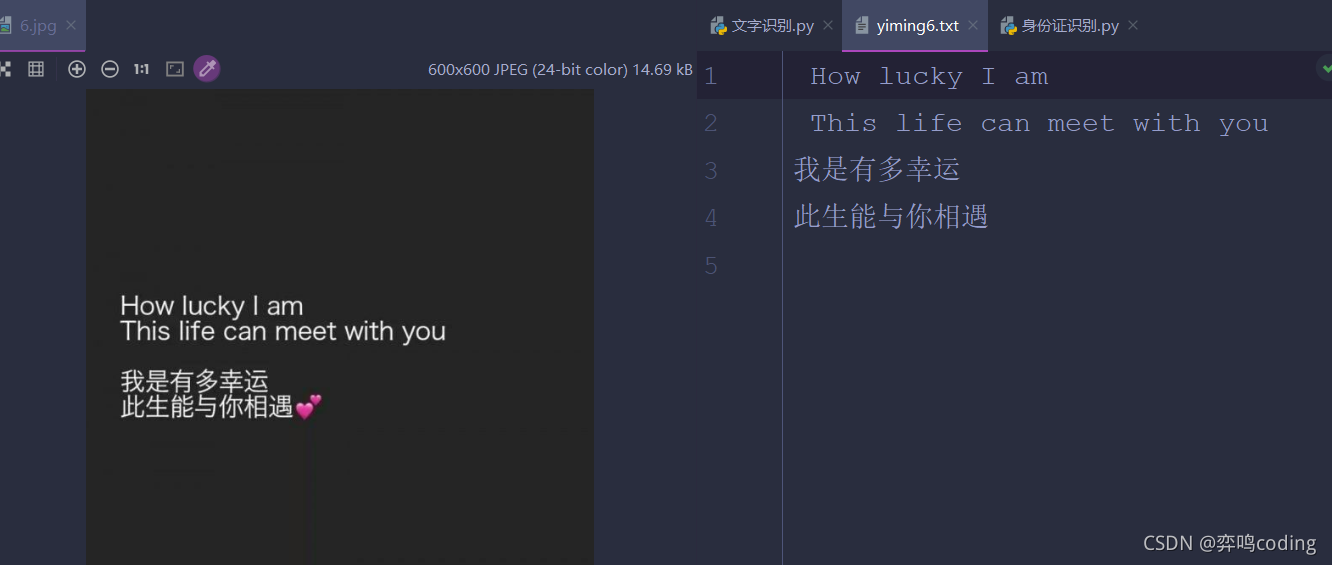
nice! Of course, you can write a cycle and directly traverse all the pictures in a folder to get the text of each picture. Then read the text and put it in the same txt file. If you have spare time, you can try it. I won't write it. Finally, I succeeded in getting Xuemei's milk tea, so I won't go on the picture, hee hee~