introduction
You should know Qiwu weekly. It is a technical blog, which gathers a large number of technical articles contributed by excellent bloggers. I personally go to see the above articles every few days, but its official website often can't be opened. Every time I want to read the articles, I have to turn page by page to find the articles I want to read. Or, sometimes I just want to look at an article as an expansion of knowledge or a review of the old and know the new.
Considering the convenience of reading articles, we started the exploration of CLI tool. The core function of this tool is to quickly find out the article links published in Qiwu weekly from the perspective of developers.
major function
- Grab all article links
- Random N article links
- Automatic capture of scheduled tasks
Grab all article links
The purpose of this function is to capture article link data, provide data support for CLI tool development, and pave the way for subsequent development of keyword retrieval, article content crawling, article recommendation and other functions.
npx 75_action fetch
Article data local cache
When used as a command-line tool, the actual process of fetching data from the official website will consume 20s +, so local files are used to cache the captured article data. npx 75_ After the action random < n > command is executed, the data will be fetched locally from the customized cache, and the cache validity is 24h.
Random N article links
One of the main functions of the CLI tool is to run the command to randomly return the data of N articles.
npx 75_action random <N>
Automatic capture of scheduled tasks
Configure the scheduled task with Github Actions, execute the custom execution [[# grab all article links]] task at 0:08:16 every day, and package and upload the captured article data to GitHub for download.
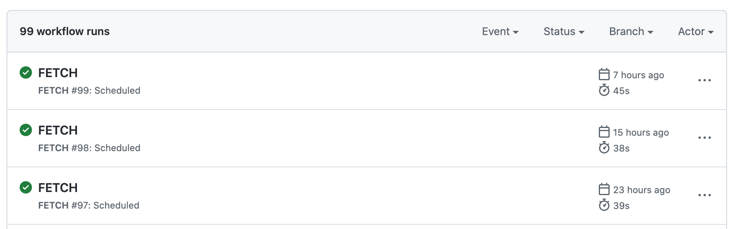
conceptual design
- Get article data

- CLI tools
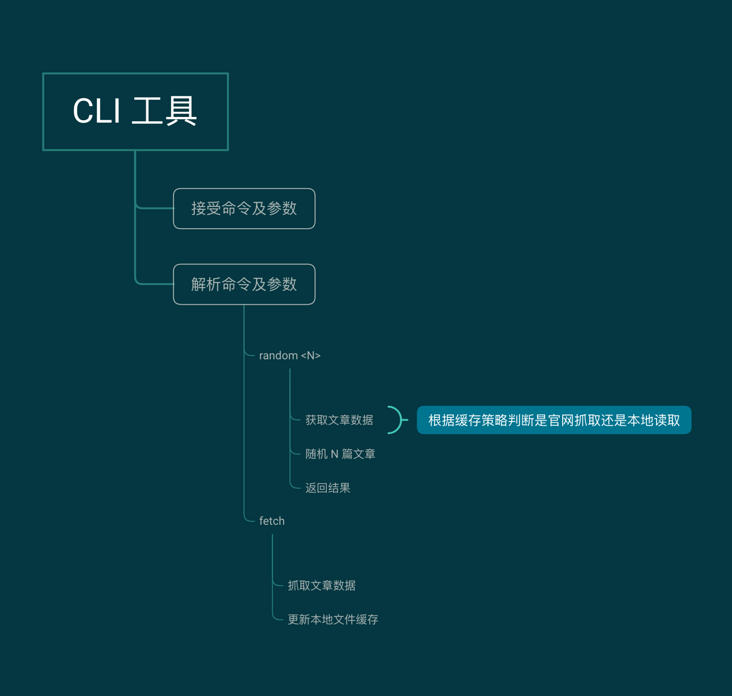
- Cache policy
Function realization
Article data capture
The corresponding source code can be viewed here: https://github.com/JohnieXu/7...
Grab the HTML on the front page of Qiwu Weekly's official website and parse the article collection data
function getCollections() {
return fetch(homeUrl)
.then(res => res.text())
.then(res => {
if (!res) {
return Promise.reject(new Error('Failed to get web page content'))
}
return cheerio.load(res)
})
.then($ => {
const list = $('ol.issue-list > li')
const collections = list.map((i, l) => {
const title = $(l).find('a').attr('title')
const url = $(l).find('a').attr('href')
const date = $(l).find('.date').attr('datetime')
return { title, url, date }
})
return collections
})
}Grab the HTML of the collection URL page and parse the article data under the collection
function getArticleDoc(url) {
return fetch(homeUrl + url)
.then(res => res.text())
.then(res => {
if (!res) {
return Promise.reject(new Error("Failed to get web page content"))
}
return cheerio.load(res)
})
}
function getArticles(doc) {
const $ = doc
const el = $('ul > li.article')
const list = el.map((i, l) => {
return {
title: $(l).find('h3.title > a').text(),
url: $(l).find('h3.title > a').attr('href'),
desc: $(l).find('.desc').text()
}
})
return list
}Integrate article data and sort output
getArticleDoc(url).then(getArticles).then(list => list.map((_, item) => ({ ...item, issue: title, date }))).then(list => {
all = [...all, ...list]
}) // Integrate article data
all = all.sort((a, b) => b.date.localeCompare(a.date)) // date in reverse orderThe date field of the article is the publication date (Journal date) of the corresponding set, for example, 2021-12-17. It needs to be arranged in reverse order String.prototype.localeCompare() Sort strings.
Article data cache
The corresponding source code can be viewed here: https://github.com/JohnieXu/7...
Cache file and validity period
const CACHE_FILE = './.75_action/.data.json'
const CACHE_TIME = 1000 * 60 * 60 * 24; // Cache 24h
const homeDir = require('os').homedir()
const p = path.resolve(homeDir, CACHE_FILE) // The cache file path is in the user's home directoryRead the modification time of the cache file to determine whether it has expired (if there is no cache file, the cache has expired)
function isCacheOutDate() {
const p = path.resolve(require('os').homedir(), CACHE_FILE)
if (!fs.existsSync(p)) {
return true
}
const stat = fs.statSync(p)
const lastModified = stat.mtime
const now = new Date()
return now - lastModified >= CACHE_TIME
}If it is not expired, read the cache file as the captured article data
function getHomeFileJson() {
const homeDir = require('os').homedir()
const p = path.resolve(homeDir, CACHE_FILE)
const jsonStr = fs.readFileSync(p)
let json
try {
json = JSON.parse(jsonStr)
} catch(e) {
console.error(e)
json = []
}
return json
}Grab the article data and write it to the local cache
function writeFileToHome(json) {
const homeDir = require('os').homedir()
const p = path.resolve(homeDir, CACHE_FILE) // The write path is the user's home directory
return mkdirp(path.dirname(p)).then(() => {
fs.writeFileSync(p, JSON.stringify(json, null, 2)) // Serialization using JSON format
})
}CLI tool development
Configure bin entry
Run NPX 75_ The action command uses node JS executes the command pointed to here_ action. JS script
{
"bin": {
"75_action": "bin/75_action.js"
}
}The source code of the script file pointed to can be viewed here: https://github.com/JohnieXu/7...
Command line parameters
Registering CLI commands and parsing command parameters using the commander Library
const program = require('commander')
// Registration command
program.command('random [number]')
.description('Random acquisition n Article link')
.option('-d, --debug', 'open debug pattern')
.action((number, options) => {
number = number || 1
if (options.debug) {
console.log(number, options)
}
fetch({ save: 'home', progress: true }).then(({ collections, articles }) => {
const selected = random(number, articles)
console.log(JSON.stringify(selected, null, 2))
process.exit()
}).catch((e) => {
console.log(e)
process.exit(1)
})
})
program.command('fetch')
.description('Re crawl article links')
.option('-d, --debug', 'open debug pattern')
.action((options) => {
if (options.debug) {
console.log(options)
}
fetch({ save: 'home', progress: true, reload: true }).then(({ collections, articles }) => {
console.log(`Grab complete, total ${collections.length}A collection, ${articles.length}Article`)
process.exit()
})
})
program.parse(process.argv)Command line progress bar
Using cli progress library to realize the effect of command line progress bar

const cliProgress = require('cli-progress')
const bar1 = new cliProgress.SingleBar({}, cliProgress.Presets.shades_classic)
bar1.start(collections.length, 0) // Set the number of article collections to the total progress value
bar1.update(doneLen) // Update the progress bar after crawling any collection articleTimed data capture
This function uses GitHub Actions to automatically execute scheduled tasks. You can add the corresponding yml configuration file to the project. The corresponding source code can be viewed here: https://github.com/JohnieXu/7...
name: FETCH
on:
push:
branches:
- master
schedule:
- cron: "0 0,8,16 * * *" # Every day at 0.8:16 (with 8-hour time difference)
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [16.x]
# See supported Node.js release schedule at https://nodejs.org/en/about/releases/
steps:
- uses: actions/checkout@v2
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v2
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- run: npm i -g yarn
- run: yarn
- run: node index.js
- name: Save
uses: actions/upload-artifact@v2
with:
path: data.jsonClone the warehouse source code with actions/checkout, and switch the node with actions / setup node JS version is 16 10. Finally, using actions / upload artifact will execute node index Data generated by JS command The JSON file is packaged and the output is uploaded to GitHub.
Execution effect
Npm package release
To ensure that this project supports the command NPX 75_ To execute action, you need to publish this project to the official npm warehouse. The project name is 75_action.
The publishing process is as follows (some commands are selected according to the actual situation). The nrm usage can be viewed here: https://www.npmjs.com/package... .
nrm use npm # Switch npm source to official npm login # Login npm account npm run publish# release
Finished product display
The following commands are executed on the terminal and require node JS version at least 10 X and above, and node and npx commands in the terminal can be used normally
A random article
npx 75_action random
Random 5 articles
npx 75_action random 5
Random N articles (N is a positive integer)
npx 75_action random N
Grab and update local article data
npx 75_action fetch
epilogue
This paper implements a CLI tool for capturing the title, description and original links of Qiwu weekly articles. The tool is based on node JS execution. It basically meets the need to quickly obtain the article links of Qiwu weekly. At the same time, the article data can be cached locally, which effectively improves the use experience. In addition, some advanced functions have not been developed, such as keyword search according to the article title, return to the latest article collection, classification according to the article title, article Link validity detection, etc.
The above undeveloped functions will be developed in succession as appropriate. You are also welcome to pay attention to the follow-up progress of the project. The project address is here: https://github.com/JohnieXu/7... .
reference material
[1] String.prototype.localeCompare(): https://developer.mozilla.org...
[2] Documentation used by cherio: https://github.com/cheeriojs/...
[3] Documents used by the commander: https://github.com/tj/command...
[4] CLI progress documentation: https://github.com/npkgz/cli-...
[5] GitHub Actions tutorial: https://docs.github.com/cn/ac...