Fundamentals of XML (I)
1. Overview
1.1 definition (what is xml?)
XML (E ** X** t ensible M arkup L anguage) is commonly known as poor sister or e Ke dead sister. It is professionally called extensible markup language.
(1) What is markup refers to a markup language, or tag language, that is, a series of tags are used to describe data.
(2) What is expansion? In short, users can define their own labels.
1.2 function (what can it be used for?)
(1) As the standard of data transmission. Easy to read, maintain and expand. TM has nothing to do with language. Anyone will choose him to play the role of data transmission...
(2) As a profile. In fact, many software and frameworks provide XML file configuration, so that you can easily and quickly modify the functions of the software or framework.
(3) Persistent data. What do you mean by that? Simply put, you can save the data into an xml file and treat xml as a temporary small database. Of course, important data still needs to be stored in a serious database. Don't ask why, but it's unsafe to store data in xml.
(4) Simplify platform changes. When the system changes the platform, there will be incompatibility between ordinary data, but XML data is stored in text format, which makes XML easier to expand and upgrade without losing data. It's not easy to use.
1.3 history (tell the story of XML briefly?)
The initial markup language is GML (General Markup Language), which was born in 1969. It is used for communication between computers, and the communication will transmit data. Later, GML found that it was not very good, so it began to introspect and improve itself, so it was reborn in 1985 and renamed SGML (Standard General Markup Language), which is also used to communicate and transmit data. With the continuous development of the world wide web, in 1993, HTML language (HyperText Markup Language) appeared on the basis of SGML. The name should be familiar. The front-end must learn. It is mainly used for page display on the world wide web. However, HEML still has many defects, so the protagonist of this blog was born. In 1998, W3C launched XML (Extensible Markup Language), I originally wanted to use XML to replace HTML, but I didn't expect it to backfire. There are still some differences between them. Even now, XML can't complete the task given by the master, because html is widely used in the whole world wide web (people have been born for several years, have a lot of experience and are widely popular. It's a little unrealistic to forcibly replace others)
XML vs. HTML
1. XML is mainly used to describe data
2. HTML is mainly used to display data
2. XML syntax
2.1 document declaration
The optional part of the XML declaration file, if any, needs to be placed on the first line of the document. It is as follows
<?xml version="1.0" encoding="utf-8"?>
This describes the version of xml and the encoding format used for the document
2.2 elements
definition
Element refers to the tag in XML, which is also called tag and node (node is often called in the framework)
Writing standard
An XML element can contain letters, numbers and other visible characters, but it must comply with some of the following specifications
- Cannot start with a number or part of a punctuation mark
- Cannot contain spaces and specific symbols
- Tags must appear in pairs. Default end tags are not allowed
- The root element has one and only one, which is the parent of all other elements
- Case sensitive
- Multi level nesting is allowed, but cross nesting is not allowed
<root> <child> <subchild>...</subchild> </child> </root>
The tag here is the root element, as above
<root> <a>www.baidu.com</a> </root>
The element can contain the label body, as shown above
<root> <a></a> <root>
The element can also contain no label body, as above
<root> <a> www.baidu.com </a> </root>
<root> <a>www.baidu.com</a> </root>
Spaces and line breaks in XML tags will be treated as tag contents in the XML parser. For example, the contents of tags are different in the above two codes, as shown above
XML tags are case sensitive: start and close tags must be written with the same case, as shown below
<root> <message>This is correct</message> </root>
<root> <Message>This is wrong<message> </root>
XML tags are allowed to be nested but not crossed, as shown below
<root> <message> <a>This is correct</a> </message> </root>
<root> <message> <a>This is wrong</message> </a> </root>
2.3 properties
definition
Attribute s provide some additional information about elements.
Usage specification
The XML attribute is written in the start tag, and the attribute value must be quoted. For example, it can be a double reference or a single quotation mark, as shown below
<root> <person sex="female"></person> </root>
<root> <person sex='female'></person> </root>
An element can have mu lt iple attributes. Its basic format is: < element name attribute name = "attribute value" attribute name = "attribute value" >
<root> <person sex="female" age='18' email="xxqq.com"><person> </root>
Element and attribute usage instances
Use the date attribute to describe the time
<note date="10/01/2021"> <to>tom</to> <from>mary</from> <msg>love</msg> </note>
Use the date element to describe the time
<note> <date>10/01/2021</date> <to>tom</to> <from>mary</from> <msg>love</msg> </note>
Use the date element and its extension elements to describe the data
<note> <date> <day>10</day> <month>02</month> <year>2021</year> </date> <to>tom</to> <from>mary</from> <msg>love</msg> </note>
If there are multiple identical tags, you can use id to distinguish them
<message> <note id="1"> <date> <day>10</day> <month>02</day> <year>2021</year> </date> <to>tom</to> <from>mary</from> <msg>love</msg> </note> <note id="2"> <date> <day>10</day> <month>02</day> <year>2021</year> </date> <to>tom</to> <from>mary</from> <msg>together</msg> </note> </message>
2.4 entities
definition
Some characters have special meanings and cannot be used directly in XML documents.
If you put the character "<" in an XML element, an error will occur because the parser will treat it as the beginning of a new element.
<?xml version="1.0" encoding="utf-8"?> <message>if salary < 1000 then</message>
The browser will report an error: invalid element name
At this time, you can use the predefined entity in XML to replace this special symbol, as follows
<?xml version="1.0" encoding="utf-8"?> <message>if salary < 1000 then</message>
Predefined and custom entities
Predefined Entities
Predefined entities in XML include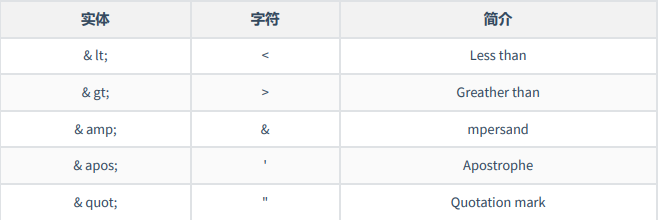
You can see the format that defines the entity: & entity name
**Custom entity**
Format:
<!DOCTYPE Root element name[ <!ENTITY Entity name entity content> ]>
For example:
<!DOCTYPE root[ <!ENTITY school "Tsinghua University"> ]> <root> <name>&school;</name> </roo>
The browser displays the following results

2.5 notes
Format:
<!-- Note Content -->
Note a few points when using comments
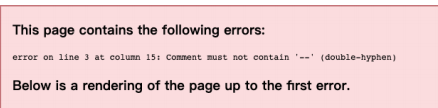
(1) Do not appear in comments –
<!-- -- --> <!-- The above comments will report errors -->
Browser parsing results

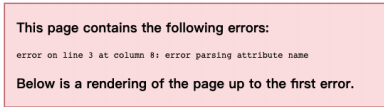
(2) Don't put notes in the middle of the label
<root> <name <!-- notes --> >java </name> </root>
Browser parsing results
(3) Comments cannot be nested
<root> <!-- Outer notes <! -- inline comment --> --> <name>XML</name> </root>
Browser parsing results
3,CDATA
The XML parser will parse all the text in the XML document. When an XML element is parsed, the text between its tags will also be parsed.
<root> <tag> <name>&</name> <entity>&</entity> </tag> </root>
Browser parsing results

In xml
- The content parsed by the parser is called PCDATA (Parsed CDATA)
- The content that the parser will not parse is called CDATA (Character Data)
In some cases, we don't want the parser to parse the special content written in xml, such as special characters and codes. Instead, we want to output these contents as strings without any additional parsing. At this time, we can write these contents in the specified CDATA area.
Format of CDATA area
<![CDATA[A string that needs to be output as is]]>
For example:
<root> <tag> <name>&</name> <entity><![CDATA[&]]></entity> </tag> </root>
All text in the XML document will be parsed by the parser. Only the text in the CDATA section will be parsed by the parser
4. XML and CSS
CSS introduction
The content in the XML file can be rendered in style with CSS, such as controlling font size, color, etc.
CSS (Cascading Style Sheets) Cascading Style Sheets are usually used to render the content in HTML or XML
For example: first create a file with css suffix, and write the following code in this file
name{
font-size:30px;
font-weight:bold;
color:red;
}
name{
font-size:30px;
font-weight:bold;
color:green;
}
Processing instructions
Processing instruction, or PI (processing instruction) for short, can be used to specify how the parser parses the contents of XML documents.
For example, in an XML document, you can use the XML stylesheet instruction to notify the XML parsing engine to render the XML content using the test.css file.
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet href="test.css" type="text/css"?> <class> <student id="001"> <name>Zhang San</name> <age>20</age> </student> <student id="002"> <name>Li Si</name> <age>20</age> </student> </class>
The effect after rendering is as follows:

5. Namespace
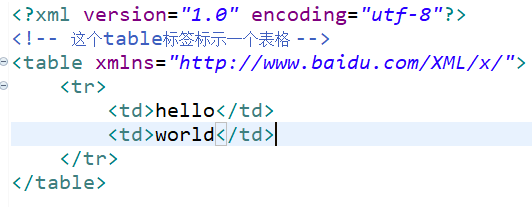
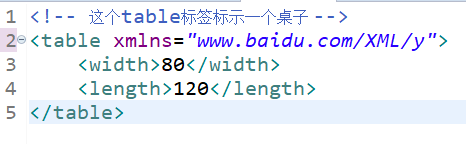
Because tags in XML documents can be customized by users, tag elements or attributes with the same name may appear in two different XML documents. If we do not provide differences in syntax, the XML processor will not be able to distinguish them. As follows,
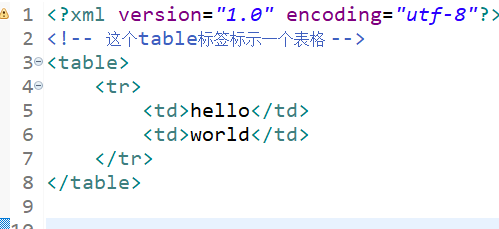
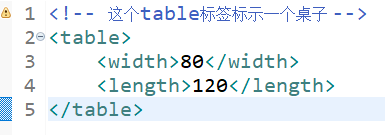
In order to avoid conflict, the solutions are as follows:
(1) Use different prefixes to distinguish
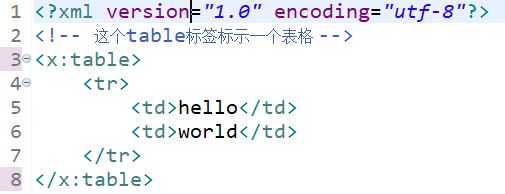
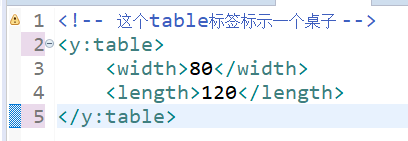
Here, x and y are the prefixes that distinguish the two table labels.
(2) Use the prefix and declare which namespace the prefix belongs to
Syntax of namespace declaration: xmlns: prefix = "URI".
Uniform resource identifier (URI, full name: Uniform Resource Identifier)
A uniform resource identifier (URI) is a string of characters that can identify Internet resources.
The most commonly used URI is the uniform resource locator (URL) used to identify Internet domain names and addresses. Another less common URI is uniform resource naming (URN).
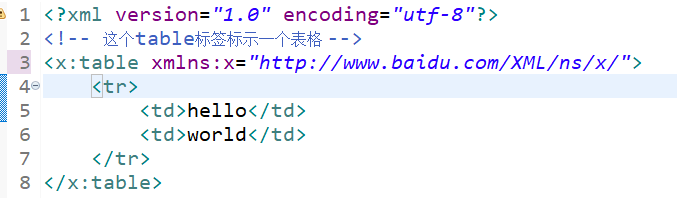
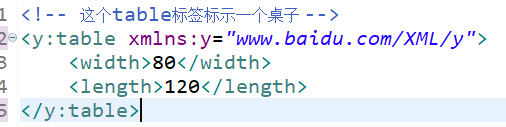
You can see that I have defined an xmlns:x attribute in the root tag. xml represents xml nameSpace, and X is the declared namespace, which can be understood as http://www.baidu.com/XML.x An alias for. Using X in the tag is equivalent to using the uri address. Once the prefix x is used, it means that the tag belongs to http://www.baidu.com/XML/x Elements under this namespace.
In addition, of course, you can also define multiple namespaces in a document, as follows
<b:book xmlns:b="http://www.baidu.com/xml/b"
xmlns:a="http://www.baidu.com/xml/a">
(3) Define default namespace directly
The default namespace eliminates the need to use prefixes in all child elements.
Format: xmlns = "URI"
As follows: