Reference materials: Bird brother's Linux private dishes: Basic Edition, Liu Chao's interesting talk about Linux operating system, UNIX/Linux system management technical manual, 4th Edition, in-depth understanding of Linux kernel, 3rd Edition, advanced programming in UNIX environment, 3rd Edition, Linux kernel source code scenario analysis Cyc2018 / CS notes: necessary basic knowledge for technical interview, Leetcode, computer operating system, computer network and system design (github.com)
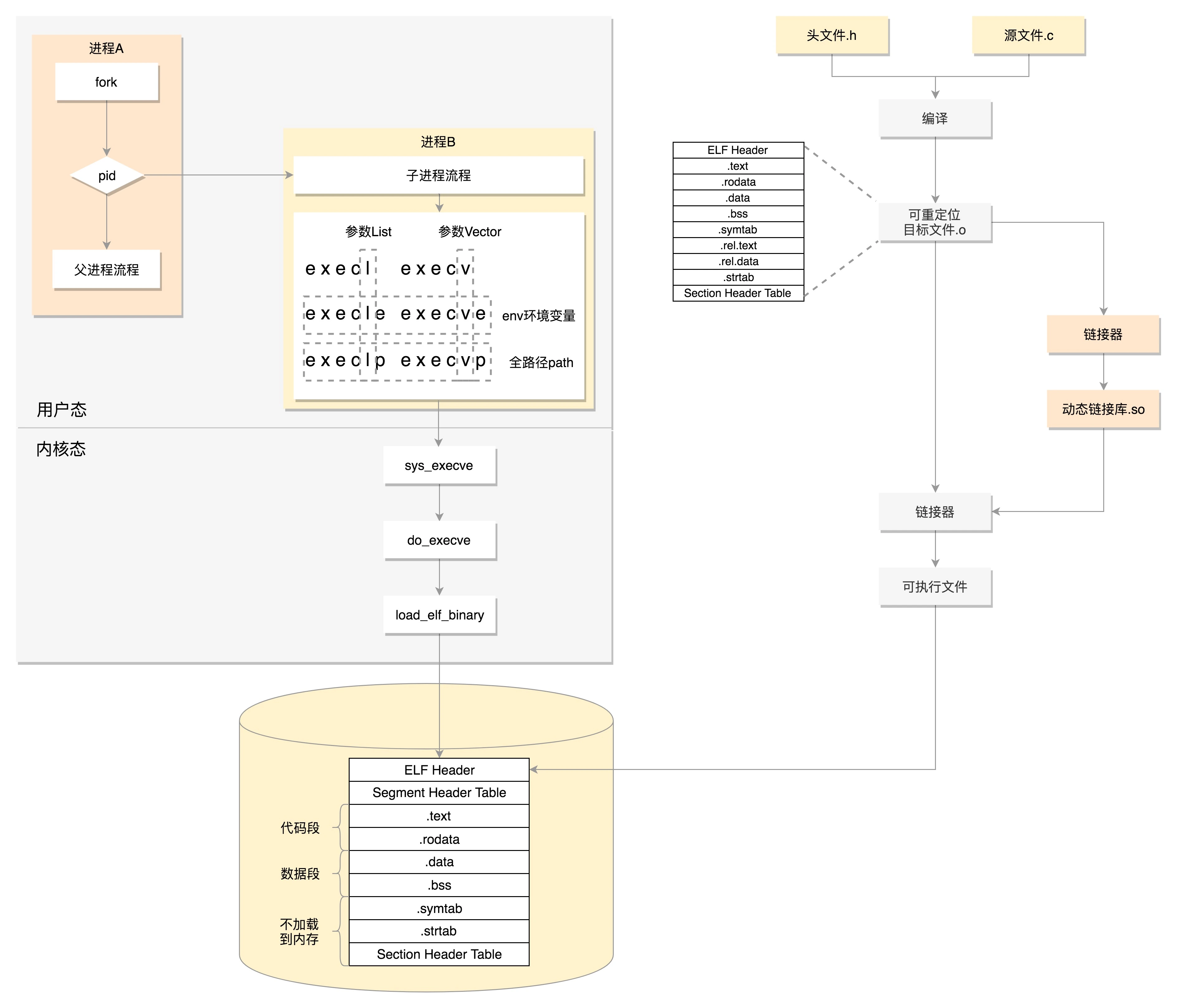
ELF file
ELF has three types of files:
- Relocatable file
- Executable file
- Shared object file
Relocatable file (. o file)
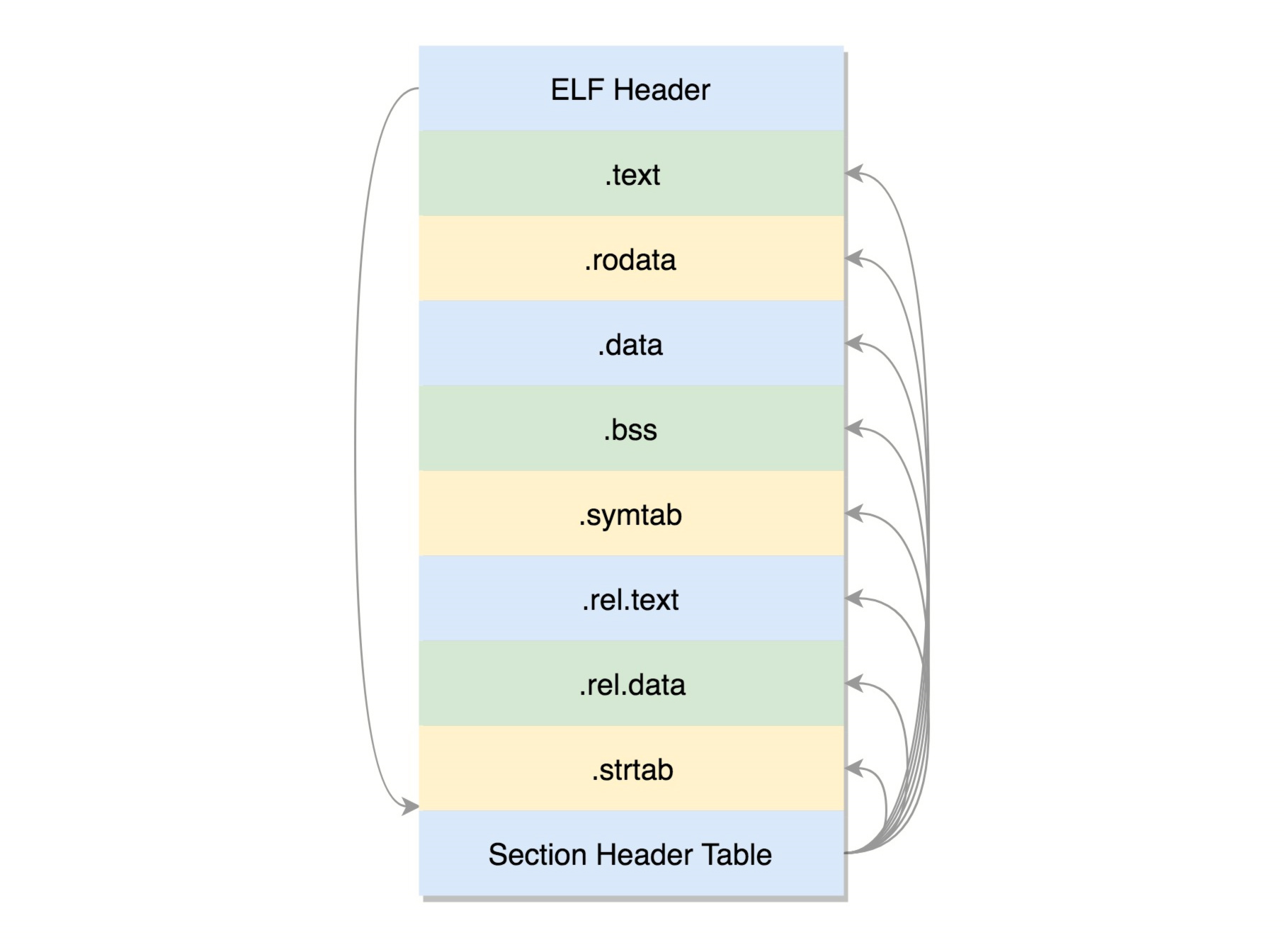
- . text: put the compiled binary executable code
- . data: initialized global variables
- . rodata: read only data, such as string constants and const variables
- . bss: the global variable is not initialized and will be set to 0 at runtime
- . symtab: symbol table, recording functions and variables
- . strtab: string table, string constants, and variable names
The header of an ELF file is used to describe the entire file. This file format is defined in the kernel as struct elf32_hdr and struct elf64_hdr. There is information describing the location of the section header table of the file, how many table entries there are, and so on.
The last Section Header Table stores metadata information. In this table, each section has an item, and the code also defines struct elf32_shdr and struct elf64_shdr.
Executable file

- ELF header: there is an e_entry, also a virtual address, is the entry for the program to run.
- Section segments: these section segments are merged by multiple. o files. They are divided into code segments that need to be loaded into memory, data segments and parts that do not need to be loaded into memory. Small sections are combined into large segments.
- Segment Header Table: defined in the code as struct elf32_phdr and struct elf64_phdr, in addition to the description of the paragraph, the most important thing is p_vaddr, this is the virtual address of the segment loaded into memory.
Shared object files (dynamic link libraries)
The binary file format created based on dynamic link library is ELF, but it is slightly different.
- An. interp Segment is added, which is ld-linux.so. This is a dynamic linker, that is, it does all the linking actions at run time.
- There are also two more section s in the ELF file:
- One is. PLT, Procedure Linkage Table (PLT)
- One is. got.plt, Global Offset Table (GOT)
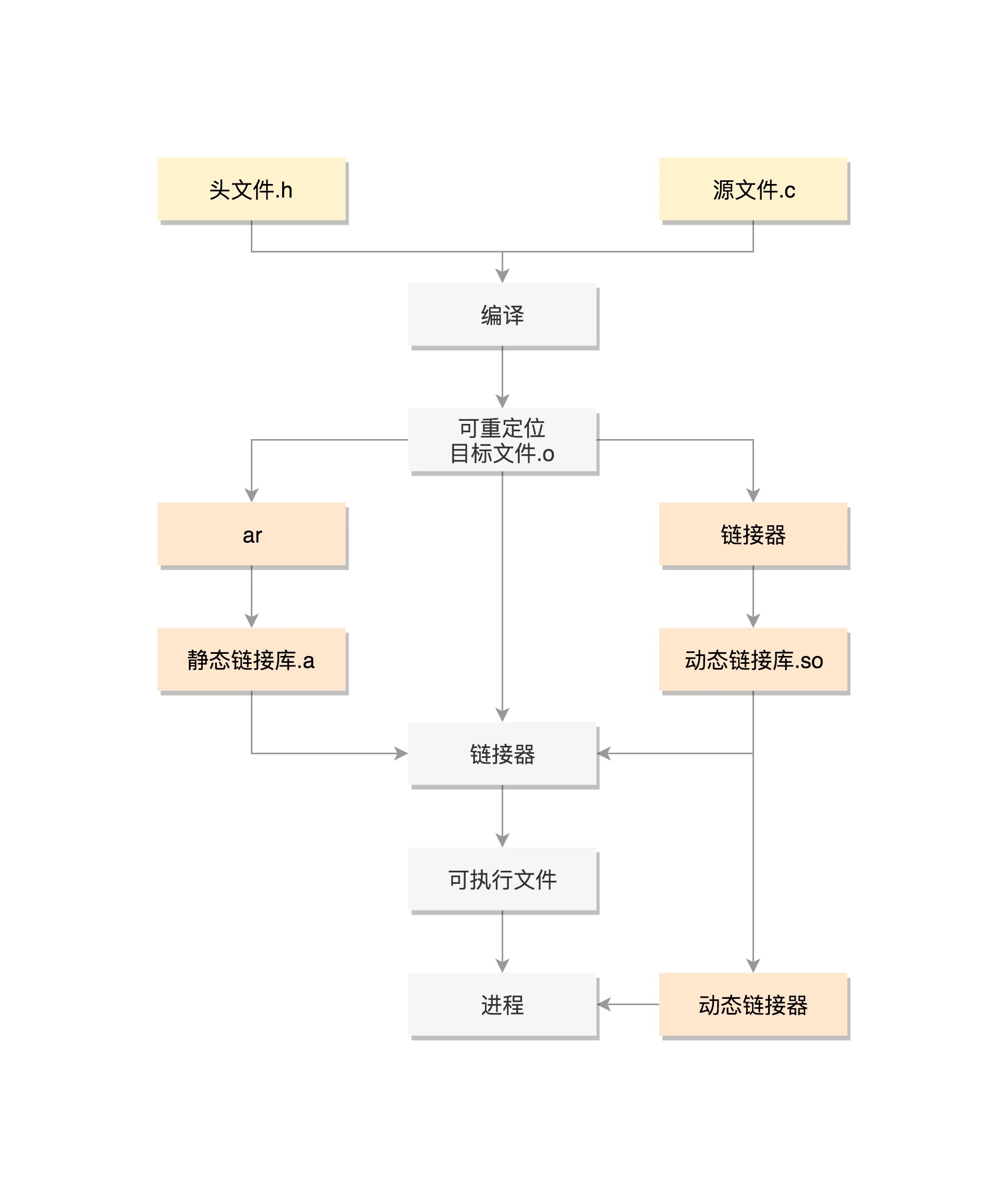
Process creation process
- Write code
- compile
- Generate. a file or. so file
- link
- function
Write code
Let's first create a file, which encapsulates the general logic of creating a process with a function, called process.c. the code is as follows:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int create_process (char* program, char** arg_list)
{
pid_t child_pid;
child_pid = fork ();
//Depending on the return value of fork, the parent and child processes go their separate ways
if (child_pid != 0)
return child_pid;
else {
//Run a new program through execvp
execvp (program, arg_list);
abort ();
}
}
Next, we create a second file, createprocess.c, and call the above function.
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int main ()
{
char* arg_list[] = {
"ls",
"-l",
"/etc/yum.repos.d/",
NULL
};
//Ran one of the simplest commands ls
create_process ("ls", arg_list);
return 0;
}
Compile
gcc -c -fPIC process.c gcc -c -fPIC createprocess.c
When compiling, do preprocessing work first, such as embedding the header file into the body and expanding the defined macro.
Then there is the real compilation process, and finally compiled into. o files.
Generate. a file or. so file
Archive a series of. o files through the ar command as a static link library, which is a. A file.
Through the linker, a series of. o files are recombined into a dynamic link library, which is a. so file.
Turn the. o file into a static link library file
The simple type is the static link library. A file (Archives), which only Archives a series of object files (. o) into one file and creates it with the command ar.
ar cr libstaticprocess.a process.o
Why do files need to be relocatable?
The. o file can be statically linked to a library (. A file). If it cannot be relocated, when you import the library, the library code is still in the location of the file and cannot be embedded into the current program at all.
Regroup. o files into dynamic link libraries
gcc -shared -fPIC -o libdynamicprocess.so process.o
It is not just a simple archive of a group of object files, but a re combination of multiple object files, which can be shared by multiple programs.
When a dynamic link library is linked to a program file, the last program file does not include the code in the dynamic link library, but only includes the reference to the dynamic link library, and does not save the full path of the dynamic link library, but only the name of the dynamic link library.
link
Statically linked to executable
gcc -o staticcreateprocess createprocess.o -L. -lstaticprocess
- -L means to find the. a file in the current directory
- -Lsstaticprocess will automatically complete the file name, for example, add the prefix lib and suffix. a to become libstaticprocess.a
- After finding the. A file, take out the process.o in it and make a link with createprocess.o to form the binary execution file static CreateProcess.
In the process of this link, the relocation works. Originally, create was called in createprocess.o_ Process function, but the location cannot be determined. Now merge process.o to know the location.
Consistency defect of static link library
Once the static link library is linked in, the section s of the code and variables are merged, so when the program runs, it does not depend on whether the library exists or not. If the same code segment is used by multiple programs, there will be multiple copies in memory, and once the static link library is updated, if the binary execution file is not recompiled, it will not be updated.
Dynamically link to executable
gcc -o dynamiccreateprocess createprocess.o -L. -ldynamicprocess
How to dynamically link so files to process space?
The dynamiccreateprocess program calls create in libdynamicprocess.so_ Process function. Because it is only found at runtime, when compiling, you don't know where this function is, so you create a PLT[x] in PLT.
This item is also some code, which is a bit like a local agent. In the binary program, create is not called directly_ The process function instead calls the proxy code in PLT[x], which will find the real create when running_ Process function.
Where to find the proxy code?
This uses GOT, which is also called create_ The process function creates a GOT[y]. This item is run-time create_ The real address of the process function in memory.
If this address calls the proxy code in PLT[x] in dynamiccreateprocess, the proxy code calls the corresponding item GOT[y] in the GOT table and calls create in libdynamicprocess.so loaded into memory_ The process function.
But how does GOT know?
For create_process function, get will create a GOT[y] at the beginning, but there is no real address because it doesn't know, but it has a way. It calls back to PLT and tells it that the agent code in you comes to me to create_ The real address of the process function. I don't know. Do something about it.
At this time, PLT will call PLT[0], that is, the first item. PLT[0] will call get [2], which is the entry function of LD linux.so. This function will find the create loaded into libdynamicprocess.so in memory_ The address of the process function, and then put this address in GOT[y]. Next time, the proxy function of PLT[x] can be called directly.
Run the program as a process
Knowing the ELF format, it is still a program at this time. How to load this file into memory?
- linux_binfmt: defines the method of loading binary files
- elf_format: ELF file format
linux_binfmt
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
} __randomize_layout;
elf_format
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,//Load is also used when loading the kernel image_ elf_ Binary format
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
//The principle is exec. The system calls the final load_elf_binary
return do_execve(getname(filename), argv, envp);
}
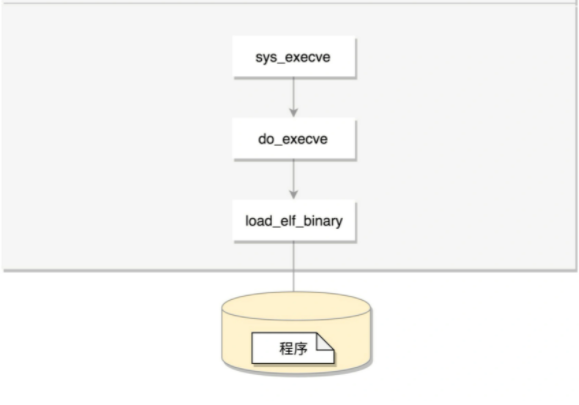
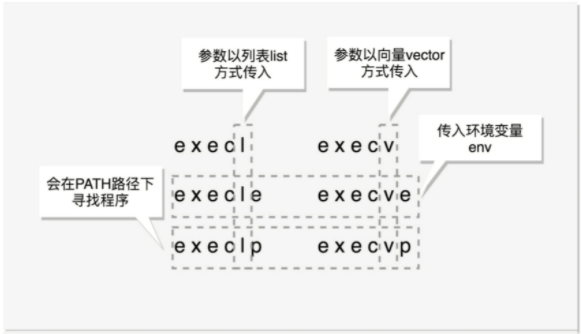
Exec function
exec is special. It is a group of functions:
- The function containing p (execvp, execlp) will find the program under the PATH;
- Functions that do not contain p need to input the full path of the program;
- Functions containing v (execv, execvp, execve) receive parameters in the form of an array;
- Functions containing l (execl, execlp, execle) receive parameters in the form of a list;
- The function containing e (execve, execle) receives environment variables as an array.
Process tree
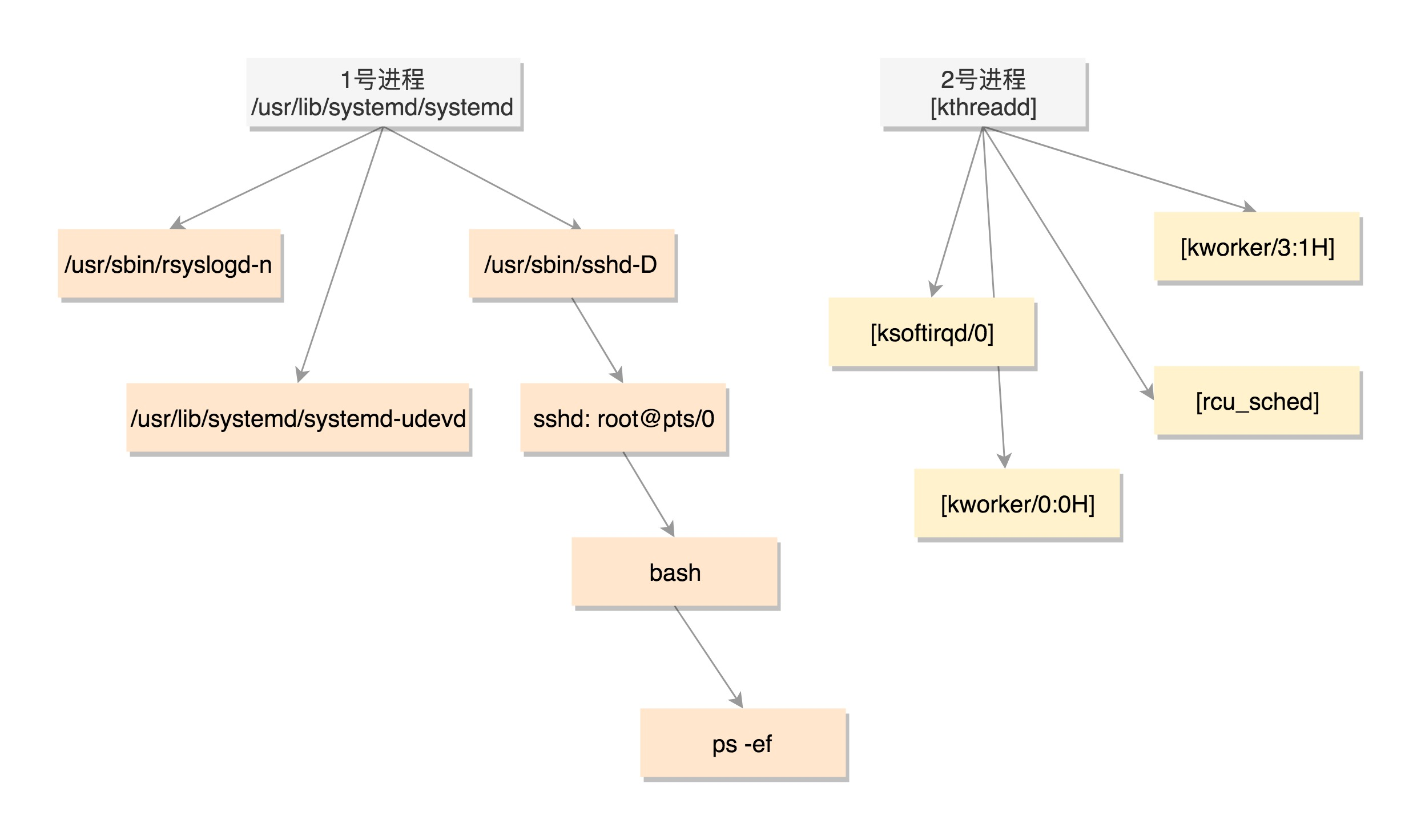
Data structure of process
Basic concepts
- Task: both processes and threads are uniformly called task in the kernel
- task_struct: unified Task management
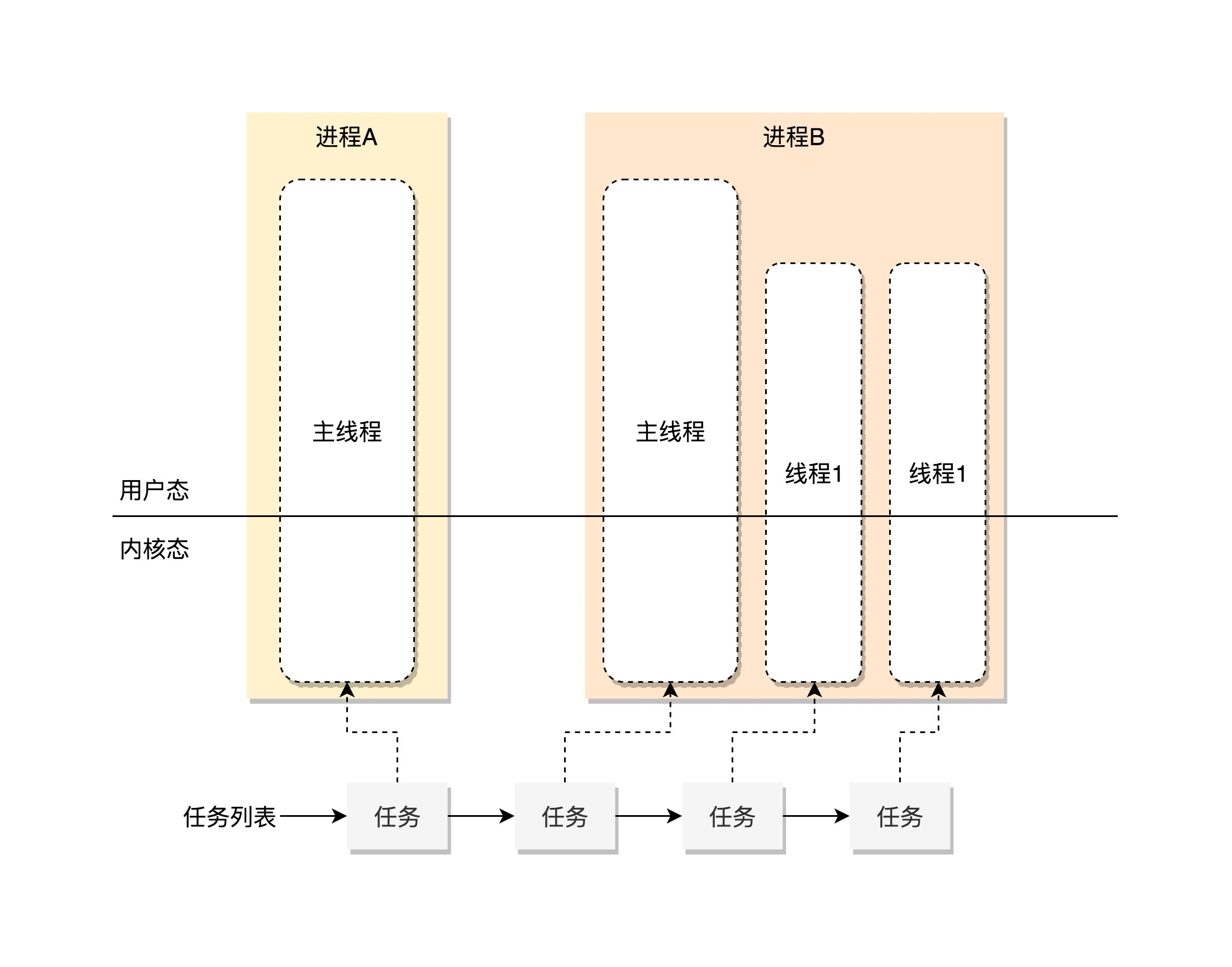
task list
All tasks_ Struct string.
struct list_head tasks;//A linked list
Field of Task
Task ID
task_struct involves the task ID as follows:
pid_t pid; pid_t tgid; struct task_struct *group_leader;
- pid: process id, current thread / process id
- tgid: thread group ID, main thread id.
- group_leader: main thread
for instance:
- If any process has only the main thread, the pid is itself, the tgid is itself, and the group is itself_ The leader points to himself.
- If a process creates other threads, that will change. The thread has its own pid. tgid is the pid and group of the main thread of the process_ The leader points to the main thread of the process.
Task status
state variable
In task_ In struct, the following variables are involved in task status:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ int exit_state; unsigned int flags;
sched.h header file
The available values of state are defined in the include/linux/sched.h header file.
/* Used in tsk->state: */ #define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define __TASK_STOPPED 4 #define __TASK_TRACED 8 /* Used in tsk->exit_state: */ #define EXIT_DEAD 16 #define EXIT_ZOMBIE 32 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) /* Used in tsk->state again: */ #define TASK_DEAD 64 #define TASK_WAKEKILL 128 #define TASK_WAKING 256 #define TASK_PARKED 512 #define TASK_NOLOAD 1024 #define TASK_NEW 2048 #define TASK_STATE_MAX 4096
State change
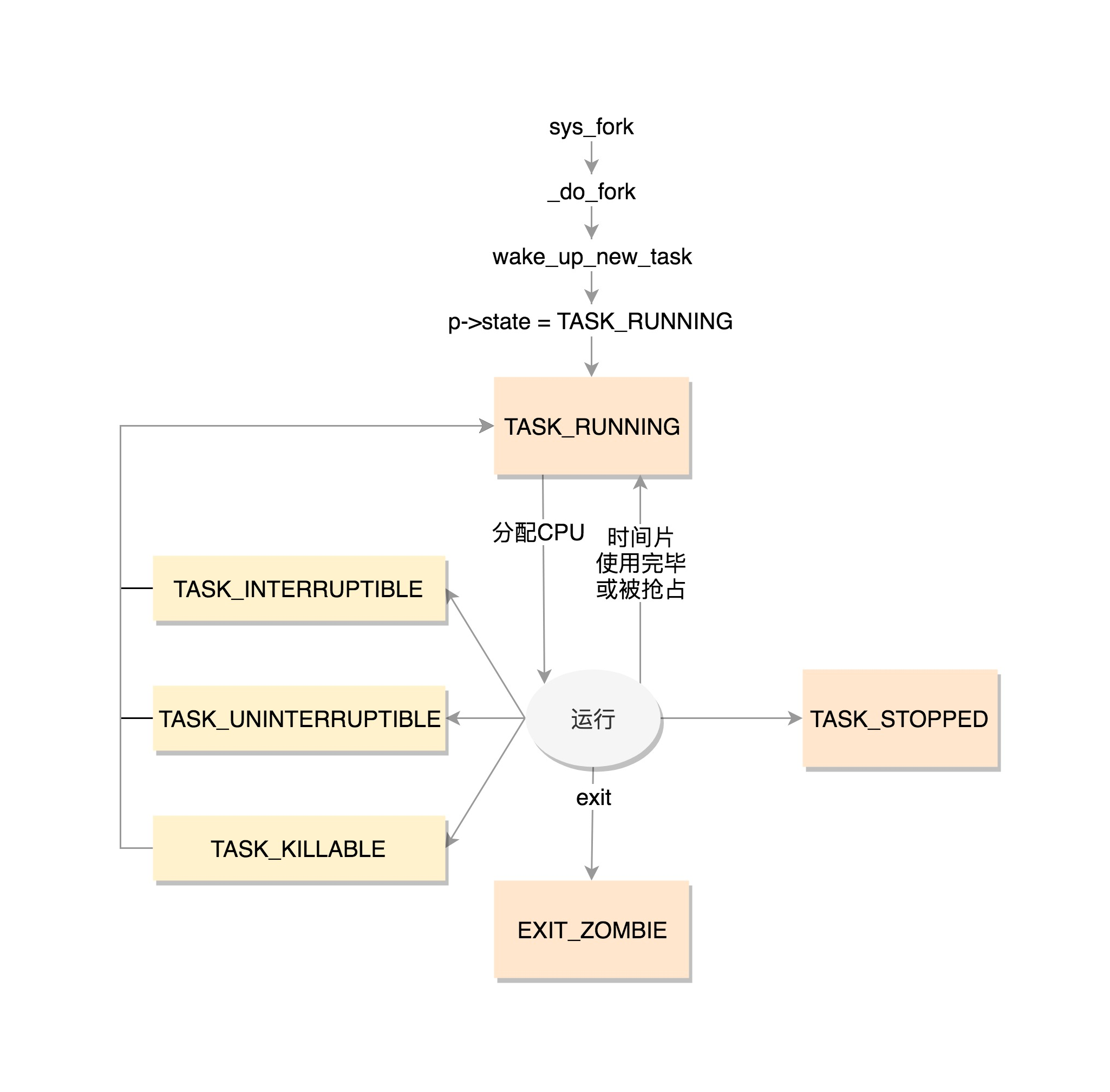
-
TASK_RUNNING: it does not mean that the process is running, but that the process is ready to run at any time. When a process in this state obtains a time slice, it is running; If the time slice is not obtained, it means that it is preempted by other processes and waiting for the time slice to be allocated again. Once a running process needs to perform some I/O operations, it needs to wait for the I/O to complete. At this time, it will release the CPU and enter the sleep state.
-
TASK_INTERRUPTIBLE sleep state: wait for I/O to complete and can be awakened by signal. After waking up, signal processing is performed instead of continuing the operation just now.
-
TASK_UNINTERRUPTIBLE sleep state: it cannot be awakened by signal, and can only wait for I/O operation to complete. Once the I/O operation cannot be completed for special reasons, no one can wake up the process at this time. Neither can kill, because kill is also a signal.
-
TASK_KILLABLE, a new sleep state that can be terminated: the process is in this state, and its operation principle is similar to TASK_UNINTERRUPTIBLE, but it can respond to fatal signals.
-
TASK_WAKEKILL: used to wake up the process when a fatal signal is received, while TASK_KILLABLE is equivalent to setting both bits.
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
- TASK_STOPPED: the process enters this state after receiving SIGSTOP, SIGTTIN, SIGTSTP or SIGTTOU signals.
- TASK_ Trace: indicates that the process is monitored by debugger and other processes, and the process execution is stopped by the debugger. When a process is monitored by another process, each signal will bring the process into this state.
- EXIT_ZOMBIE: once a process is about to end, exit is the first step_ Zombie status, but at this time, its parent process has not used wait() and other system calls to obtain its termination information. At this time, the process becomes a zombie process.
- EXIT_DEAD: the final state of the process. EXIT_ZOMBIE and EXIT_DEAD can also be used for exit_state.
sign
The above process state is related to the operation and scheduling of the process, and there are other states, which we call flags. In the flags field, these fields are defined as macros, starting with PF. Let me give a few examples here.
#define PF_EXITING 0x00000004 #define PF_VCPU 0x00000010 #define PF_FORKNOEXEC 0x00000040
- PF_EXITING: indicates exiting. When there is this flag, in the function find_ alive_ In the thread, find the living thread. If you encounter this flag, you can skip it directly.
- PF_VCPU: indicates that the process is running on the virtual CPU. In the function account_system_time, count the system running time of the process. If there is this flag, call account_guest_time, which is counted according to the time of the client.
- PF_FORKNOEXEC: indicates that the fork is over and there is no exec. In_ do_ Copy is called in the fork function_ Process. At this time, set the flag to PF_FORKNOEXEC. When load_ is called in Exec elf_ When binary, remove this flag again.
Fields for process scheduling
//Is it on the run queue int on_rq; //priority int prio; int static_prio; int normal_prio; unsigned int rt_priority; //Scheduler class const struct sched_class *sched_class; //Scheduling entity struct sched_entity se; struct sched_rt_entity rt; struct sched_dl_entity dl; //scheduling strategy unsigned int policy; //What CPU s can be used int nr_cpus_allowed; cpumask_t cpus_allowed; struct sched_info sched_info;
Fields about signal processing
/* Signal handlers: */ struct signal_struct *signal; struct sighand_struct *sighand;//Signal being processed sigset_t blocked; sigset_t real_blocked; //Blocked signal not processed sigset_t saved_sigmask; struct sigpending pending;//Signal waiting to be processed //The function stack in user mode is used by default. unsigned long sas_ss_sp; size_t sas_ss_size; unsigned int sas_ss_flags;
Fields for running statistics
During the process, there will be some statistics. You can see the following list for details. This includes the time consumed by the process in user mode and kernel mode, the number of context switches, and so on.
u64 utime;//CPU time consumed in user mode u64 stime;//CPU time consumed in kernel mode unsigned long nvcsw;//Voluntary context switching count unsigned long nivcsw;//Involuntary context switching count u64 start_time;//Process startup time, excluding sleep time u64 real_start_time;//Process start time, including sleep time
Process kinship
From the process of creating a process we talked about earlier, we can see that any process has a parent process. Therefore, the whole process is actually a process tree. All processes that have the same parent process have brotherhood.
struct task_struct __rcu *real_parent; /* real parent process */ struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */

- Parent points to its parent process. When it terminates, it must send a signal to its parent process.
- children represents the head of the linked list. All elements in the linked list are its child processes.
- Sibling is used to insert the current process into the sibling linked list.
Normally, real_parent and parent are the same, but there will be other situations. For example, bash creates a process whose parent and real_ Parents are bash. If you use GDB to debug a process on bash, GDB is the parent and Bash is the real of the process_ parent.
Process permissions
In Linux, process permissions are defined as follows:
/* Objective and real subjective task credentials (COW): */ const struct cred __rcu *real_cred; /* Effective (overridable) subjective task credentials (COW): */ const struct cred __rcu *cred;
In the annotation of this structure, there are two nouns that are more awkward, Objective and Subjective. In fact, the so-called authority is who I can manipulate and who can manipulate me.
- "Who can operate me". Obviously, at this time, I am the object to be operated, that is, Objective, and the one who wants to operate me is Subjective.
- "Who can I operate?" at this time, I am Subjective, and the object to be operated by me is objectie.
"Operation" means that one object performs some actions on another object. When the action is to be implemented, the permission must be approved. When the permissions on both sides are matched, the operation can be implemented.
- real_cred means who can operate my process
- cred means who I can operate in this process.
cred
cred is defined as follows:
struct cred {
......
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
......
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
......
} __randomize_layout;
As can be seen from the definitions here, most of them are about users and user groups to which users belong.
-
The first is uid and gid, and the annotation is real user/group id. Generally, the ID of the person who starts the process is the person who starts it. However, when approving permissions, the two are often not compared, that is, they do not work.
-
The second is euid and egid, and the annotation is effective user/group id. As soon as you look at the name, you know that it plays a "role". When the process wants to operate message queues, shared memory, semaphores and other objects, it is actually comparing whether the user and group have permissions.
-
The third is fsuid and fsgid, that is, filesystem user/group id. This is the permission to audit file operations.
Generally speaking, fsuid, euid and uid are the same, and fsgid, egid and gid are the same. Because whoever starts the process should audit whether the starting user has this permission.
But there are special circumstances.
chmod u+s program

For example, user a wants to play a game whose program is installed by user B. The permissions of the game program file are rwxr – r –. A does not have permission to run this program, so user B should give user a permission. User B said no problem, they are all friends, so user B set the permission rwxr-xr-x that all users can execute the program, and said brother, you play.
Therefore, user A obtains the permission to run the game. When the game is running, the uid, euid and fsuid of the game process are user A. It seems no problem. I had A good time.
User A finally passed the pass. When he wanted to keep the pass data, he found that it was broken. The player data of the game was saved in another file. This file permission rw ------- only gives user B write permission, and the euid and fsuid of the game process are user A, of course, can't be written in. It's over. This game is in vain.
How to solve this problem? We can use the chmod u+s program command to set the identification bit of set user ID for the game program and change the game permission into rwsr-xr-x. At this time, when user a starts the game again, of course, the process uid created is still user a, but euid and fsuid are not user A. when you see the set user ID ID ID, it is changed to the ID of the owner of the file, that is, euid and fsuid are changed to user B, so that the customs clearance results can be saved.
In Linux, a process can set the user ID through setuid at any time. Therefore, the ID of user B of the game program will be saved in one place, which is suid and sgid, that is, saved uid and save gid. This makes it easy to use setuid and change permissions by setting uid or suid.
capabilities mechanism
In addition to controlling permissions by users and user groups, another mechanism of Linux is capabilities.
The original permission to control the process is either a high-level root user or an ordinary user with ordinary permissions. At this time, the problem is that the root user's permission is too large and the ordinary user's permission is too small. Sometimes, if an ordinary user wants to do something with high permission, he must give him the permission of the whole root. This is too unsafe.
Therefore, we introduce a new mechanism, capabilities, which uses a bitmap to represent permissions. The defined permissions can be found in capability.h. Let me list a few here.
#define CAP_CHOWN 0 #define CAP_KILL 5 #define CAP_NET_BIND_SERVICE 10 #define CAP_NET_RAW 13 #define CAP_SYS_MODULE 16 #define CAP_SYS_RAWIO 17 #define CAP_SYS_BOOT 22 #define CAP_SYS_TIME 25 #define CAP_AUDIT_READ 37 #define CAP_LAST_CAP CAP_AUDIT_READ
For processes run by ordinary users, when they have this permission, they can do these operations; When there is no, you can't do it. In this way, the granularity is much smaller.
-
cap_permitted indicates the permissions that the process can use. But what really works is cap_effective.
-
cap_ Cap can be included in permitted_ No permission in effective. A process can give up some of its permissions when necessary, which is more secure. Suppose you have been broken because of a code vulnerability, but if you can't do anything, you can't make a further breakthrough.
-
cap_inheritable means that when the inheritable bit is set in the extended attribute of the executable file, calling exec to execute the program will inherit the inheritable set of the caller and add it to the permitted set. However, when executing exec under a non root user, the inheritable set is usually not retained, but it is often a non root user who wants to retain permissions, so it is very chicken ribs.
-
cap_bset, that is, capability bounding set, is the permission allowed to be reserved by all processes in the system. If a permission does not exist in this collection, all processes in the system do not have this permission. Even processes that execute with superuser privileges are the same. This has many advantages. For example, after the system starts, remove the permission to load the kernel module, and all processes cannot load the kernel module. In this way, even if the machine is broken, it can't do too many harmful things.
-
cap_ambient is a relatively new addition to the kernel to solve cap_inheritable chicken ribs, that is, how to retain permissions when a non root user process uses exec to execute a program. When exec is executed, cap_ The ambient is added to the cap_ In permitted, set it to cap at the same time_ Effective.
memory management
Each process has its own independent virtual memory space, which needs to be represented by a data structure, mm_struct. This is described in detail in the memory management section. Here you have an impression.
struct mm_struct *mm; struct mm_struct *active_mm;
File and file system
Each process has a file system data structure and an open file data structure. We'll talk about this in detail in the file system section.
/* Filesystem information: */ struct fs_struct *fs; /* Open file information: */ struct files_struct *files;
Function stack
User state function stack
In the memory space of the process, the stack is a structure that grows from high address to low address, that is, the top of the stack is at the top of the stack, and the operation of entering and exiting the stack starts from the top of the stack below.
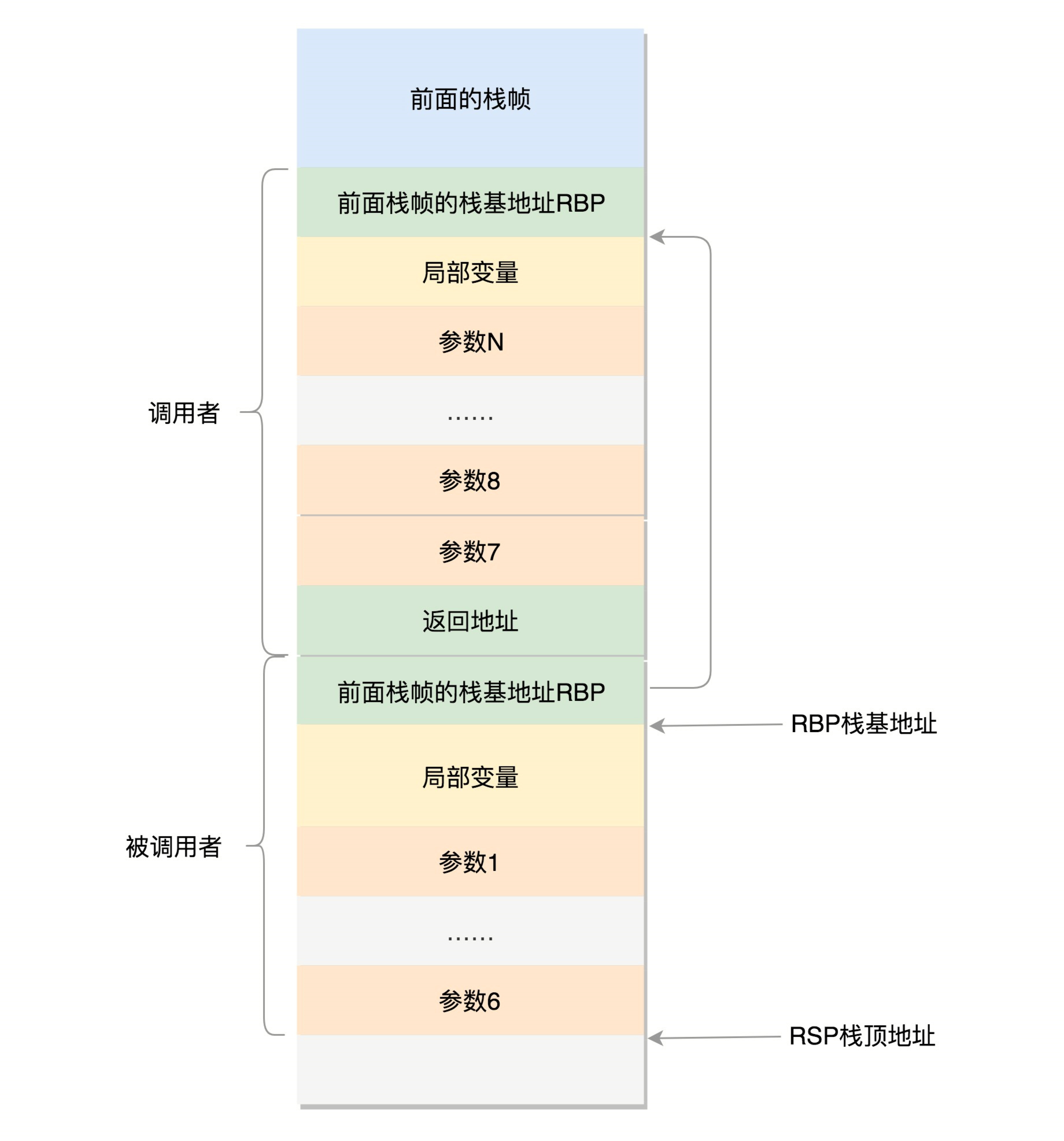
- rax is used to save the returned results of function calls.
- The stack top pointer register becomes rsp, pointing to the stack top position. The Pop and Push operations of the stack will automatically adjust the rsp,
- The stack base pointer register becomes rbp, pointing to the starting position of the current stack frame.
- The six registers rdi, rsi, rdx, rcx, r8 and r9 are used to pass and store the six parameters during function calls. If it exceeds 6, it still needs to be put in the stack.
Sometimes the first six parameters need to be addressed, but if they are in the register, they do not have an address, so they will still be placed in the stack, but the operation placed in the stack is done by the called function.
The above stack operations are carried out in the memory space of the process.
Kernel state function stack
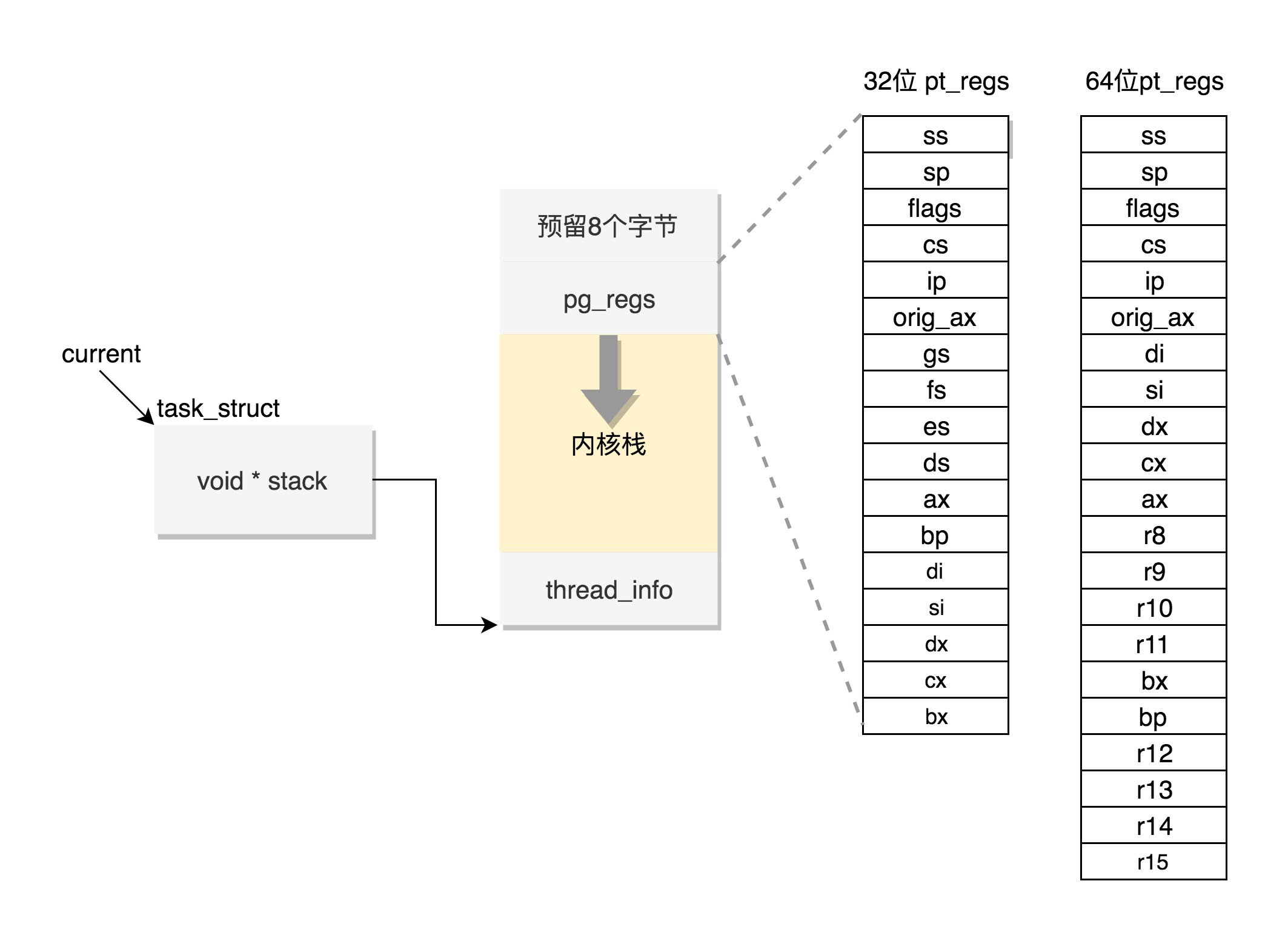
-
thread_info: this structure is for task_ Supplement to struct structure.
Because task_ The structure of struct is huge but universal. Different architectures need to save different things, so what is often related to the architecture is put in thread_ Inside.
-
page_64_types.h: defines the kernel stack
-
thread_union: thread_info and stack together
-
pt_regs: save the CPU context during user mode operation in the register variable of this structure.
page_64_types.h
Linux assigns a kernel stack to each task. Kernel stack on 64 bit system arch/x86/include/asm/page_64_types.h is defined as follows: on page_ It is required to shift two bits to the left based on size, that is, 16K, and the starting address must be an integer multiple of 8192.
#ifdef CONFIG_KASAN #define KASAN_STACK_ORDER 1 #else #define KASAN_STACK_ORDER 0 #endif #define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER) #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
thread_union
There is such a union in the kernel code, which will thread_info and stack are put together in the include/linux/sched.h file.
union thread_union {
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
This union is defined in this way. It starts with thread_info, followed by stack.
pt_regs
At the highest address end of the kernel stack, another structure PT is stored_ Regs, as defined below.
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
};
#endif
Are you familiar with this? We have seen this structure many times when talking about system call. When the system calls from user state to kernel state, the first thing to do is to save the CPU context during the operation of user state. In fact, it is mainly stored in the register variable of this structure. In this way, when returning from the kernel system call, the process can continue to run in the place just now.
If we compare the contents of the system call section, you will find that the order of stack values and struct Pt during system call_ The order of register definitions in regs is the same.
In the kernel, the CPU register ESP or RSP has pointed to the top of the kernel stack. Calls in the kernel state have a process similar to that in the user state.
Through task_struct find kernel stack
Relevant contents involved:
- task_stack_page: find the kernel stack of the thread
- task_pt_regs: Get task_struct corresponding pt_regs
task_stack_page
If there is a task_ The stack pointer of struct is in hand. You can find the thread kernel stack through the following function:
static inline void *task_stack_page(const struct task_struct *task)
{
return task->stack;
}
task_pt_regs
From task_ How to get the corresponding Pt from struct_ What about regs? We can use the following function:
/*
* TOP_OF_KERNEL_STACK_PADDING reserves 8 bytes on top of the ring0 stack.
* This is necessary to guarantee that the entire "struct pt_regs"
* is accessible even if the CPU haven't stored the SS/ESP registers
* on the stack (interrupt gate does not save these registers
* when switching to the same priv ring).
* Therefore beware: accessing the ss/esp fields of the
* "struct pt_regs" is possible, but they may contain the
* completely wrong values.
*/
#define task_pt_regs(task)
({
unsigned long __ptr = (unsigned long)task_stack_page(task);
__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING;
((struct pt_regs *)__ptr) - 1;
})
You will find that this is from task first_ Struct finds the start of the kernel stack. Then add thread to this position_ Size reaches the final position and is converted to struct pt_regs, minus one, is equivalent to reducing one Pt_ The location of regs is the first address of this structure.
TOP_OF_KERNEL_STACK_PADDING
There is a top here_ OF_ KERNEL_ STACK_ Padding is defined as follows:
#ifdef CONFIG_X86_32 # ifdef CONFIG_VM86 # define TOP_OF_KERNEL_STACK_PADDING 16 # else # define TOP_OF_KERNEL_STACK_PADDING 8 # endif #else # define TOP_OF_KERNEL_STACK_PADDING 0 #endif
That is, 8 on 32-bit machines and 0 on others. Why? Because of the stack pt_regs has two cases. We know that the CPU uses ring to distinguish permissions, so Linux can distinguish between kernel state and user state.
-
In the first case, we take the system call involving the change from user state to kernel state. Because the permission change is involved, the SS and ESP registers will be saved on the stack. These two registers occupy a total of 8 byte s.
-
In another case, the 8 byte s will not be stacked without permission changes. This will make the two situations incompatible. If there is no stack access, an error will be reported, so it's better to reserve it here to ensure security. On 64 bit, this problem is modified to a fixed length.
Well, now if you have a task_ With struct in hand, you can easily get the kernel stack and kernel registers.
Find task through kernel stack_ struct
If a process currently executing on a CPU wants to know its task_ Where is struct and what should we do?
Related contents involved:
- thread_info: a member variable task points to task_struct
- current_thread_info: get thread_info to get task_struct. The new implementation can obtain the currently running task_struct.
- current.h: in the new mechanism, each CPU runs tasks_ Struct does not pass thread_info is obtained and directly placed in the Per CPU variable.
thread_info
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
There is a member variable task pointing to task_struct, so we often use current_ thread_ Info () - > task to get the task_struct.
current_thread_info
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE);
}
And thread_ The position of info is the highest position of the kernel stack, minus THREAD_SIZE, it's thread_ Start address of info.
But now it's like this. There's only one flag left.
struct thread_info {
# unsigned long flags; /* low level flags */
};
How to get the currently running task at this time_ What about struct? current_thread_info has a new implementation.
current_thread_info new implementation
In include / Linux / thread_ Current is defined in info. H_ thread_ info.
#include <asm/current.h> #define current_thread_info() ((struct thread_info *)current) #endif
What is current? Defined in arch/x86/include/asm/current.h.
current.h
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);//Declare Per CPU variable
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
#define current get_current
Here, you will find that in the new mechanism, each CPU runs tasks_ Struct does not pass thread_info is obtained and directly placed in the Per CPU variable.
In the case of multi-core, CPUs run at the same time, but when they use other hardware resources together, we need to solve the synchronization problem between multiple CPUs.
Per CPU
Per CPU variable is an important synchronization mechanism in the kernel. As the name suggests, the per CPU variable is to construct a copy of the variable for each CPU, so that multiple CPUs operate their own copies and do not interfere with each other. For example, the variable current of the current process_ Task is declared as a per CPU variable.
- To use the Per CPU variable, first declare this variable. In arch/x86/include/asm/current.h:
- DECLARE_PER_CPU(struct task_struct *, current_task);
- Then define this variable. In arch/x86/kernel/cpu/common.c:
- DEFINE_PER_CPU(struct task_struct *, current_task) = &init_task;
That is, when the system is just initialized, current_ All tasks point to init_task. When a process on a CPU switches, current_ The task is modified to the target process to switch to.
this_cpu_read_stable
When you want to get the current running task_struct, you need to call this_cpu_read_stable to read.
#define this_cpu_read_stable(var) percpu_stable_op("mov", var)
Well, now if you are a process running on a CPU, you can easily get the task_struct.
thread
How do I create a thread?

Write a demo named download.c as follows:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define NUM_OF_TASKS 5
//1. Declare thread function
void *downloadfile(void *filename)
{
printf("I am downloading the file %s!\n", (char *)filename);
sleep(10);
long downloadtime = rand()%100;
printf("I finish downloading the file within %d minutes!\n", downloadtime);
//A running thread can call pthread_exit exits the thread. This function can pass in a parameter and convert it to (void *) type. This is the return value of thread exit.
pthread_exit((void *)downloadtime);
}
//Main thread
int main(int argc, char *argv[])
{
//2. Next, we declare an array with five pthreads_ Thread object of type T.
char files[NUM_OF_TASKS][20]={"file1.avi","file2.rmvb","file3.mp4","file4.wmv","file5.flv"};
//3. Declare thread object
pthread_t threads[NUM_OF_TASKS];
int rc;
int t;
int downloadtime;
/*4.Declare thread properties
Next, declare a thread attribute pthread_attr_t. We passed pthread_attr_init initializes this property and sets the property PTHREAD_CREATE_JOINABLE. This means that in the future, the main thread waits for the end of this thread and gets the state at exit.
*/
pthread_attr_t thread_attr;
pthread_attr_init(&thread_attr);
pthread_attr_setdetachstate(&thread_attr,PTHREAD_CREATE_JOINABLE);
/*5.Create thread
Next is a loop. Pthread can be called for each file and each thread_ Create creates a thread. There are four parameters in total. The first parameter is the thread object, the second parameter is the thread property, the third parameter is the thread running function, and the fourth parameter is the parameter of the thread running function. The main thread sends its own tasks to the child thread through the fourth parameter.
*/
for(t=0;t<NUM_OF_TASKS;t++){
printf("creating thread %d, please help me to download %s\n", t, files[t]);
rc = pthread_create(&threads[t], &thread_attr, downloadfile, (void *)files[t]);
if (rc){
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
//6. Destroy thread properties
pthread_attr_destroy(&thread_attr);
/*7.Wait for the thread to end
After task allocation, each thread downloads a file. The next thing the main thread has to do is wait for these subtasks to complete. When a thread exits, it sends a signal to all other threads in the same process. One thread uses pthread_join gets the return value of the thread exit. The return value of the thread is passed through pthread_ The join is passed to the main thread, so that the sub thread will tell the main thread the time spent downloading the file.
*/
for(t=0;t<NUM_OF_TASKS;t++){
pthread_join(threads[t],(void**)&downloadtime);
printf("Thread %d downloads the file %s in %d minutes.\n",t,files[t],downloadtime);
}
//8. End of main thread
pthread_exit(NULL);
}
Multithreaded programs rely on libpthread.so.
gcc download.c -lpthread
Thread data
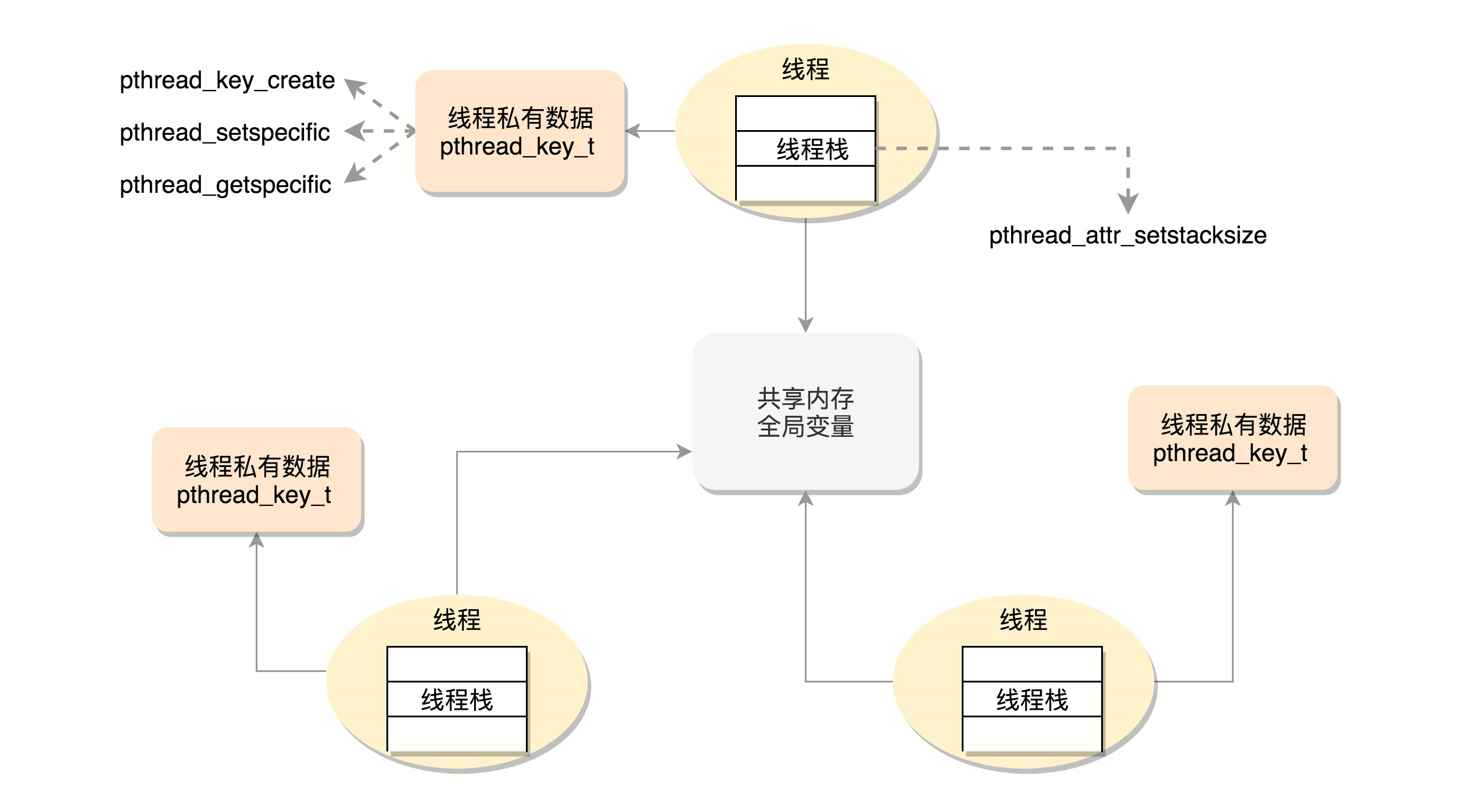
- The first is the local data on the thread stack
- The second type of data is the global data shared throughout the process.
- The third type of data is Thread Specific Data
Shared data protection issues
Mutex (Mutual Exclusion)

#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define NUM_OF_TASKS 5
//1. Declare shared variables
int money_of_tom = 100;
int money_of_jerry = 100;
//2. Declare the lock. Remove the following line for the first run
pthread_mutex_t g_money_lock;
void *transfer(void *notused)
{
pthread_t tid = pthread_self();
printf("Thread %u is transfering money!\n", (unsigned int)tid);
//Get lock. Remove the following line for the first run
pthread_mutex_lock(&g_money_lock);
sleep(rand()%10);
money_of_tom+=10;
sleep(rand()%10);
money_of_jerry-=10;
//Release the lock. Remove the following line for the first run
pthread_mutex_unlock(&g_money_lock);
printf("Thread %u finish transfering money!\n", (unsigned int)tid);
pthread_exit((void *)0);
}
int main(int argc, char *argv[])
{
pthread_t threads[NUM_OF_TASKS];
int rc;
int t;
//3. Initialize the lock. Remove the following line for the first run
pthread_mutex_init(&g_money_lock, NULL);
//4. Create thread
for(t=0;t<NUM_OF_TASKS;t++){
rc = pthread_create(&threads[t], NULL, transfer, NULL);
if (rc){
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
for(t=0;t<100;t++){
//Remove the following line for the first run
pthread_mutex_lock(&g_money_lock);
printf("money_of_tom + money_of_jerry = %d\n", money_of_tom + money_of_jerry);
//Remove the following line for the first run
pthread_mutex_unlock(&g_money_lock);
}
//Destroy the lock. Remove the following line for the first run
pthread_mutex_destroy(&g_money_lock);
pthread_exit(NULL);
}
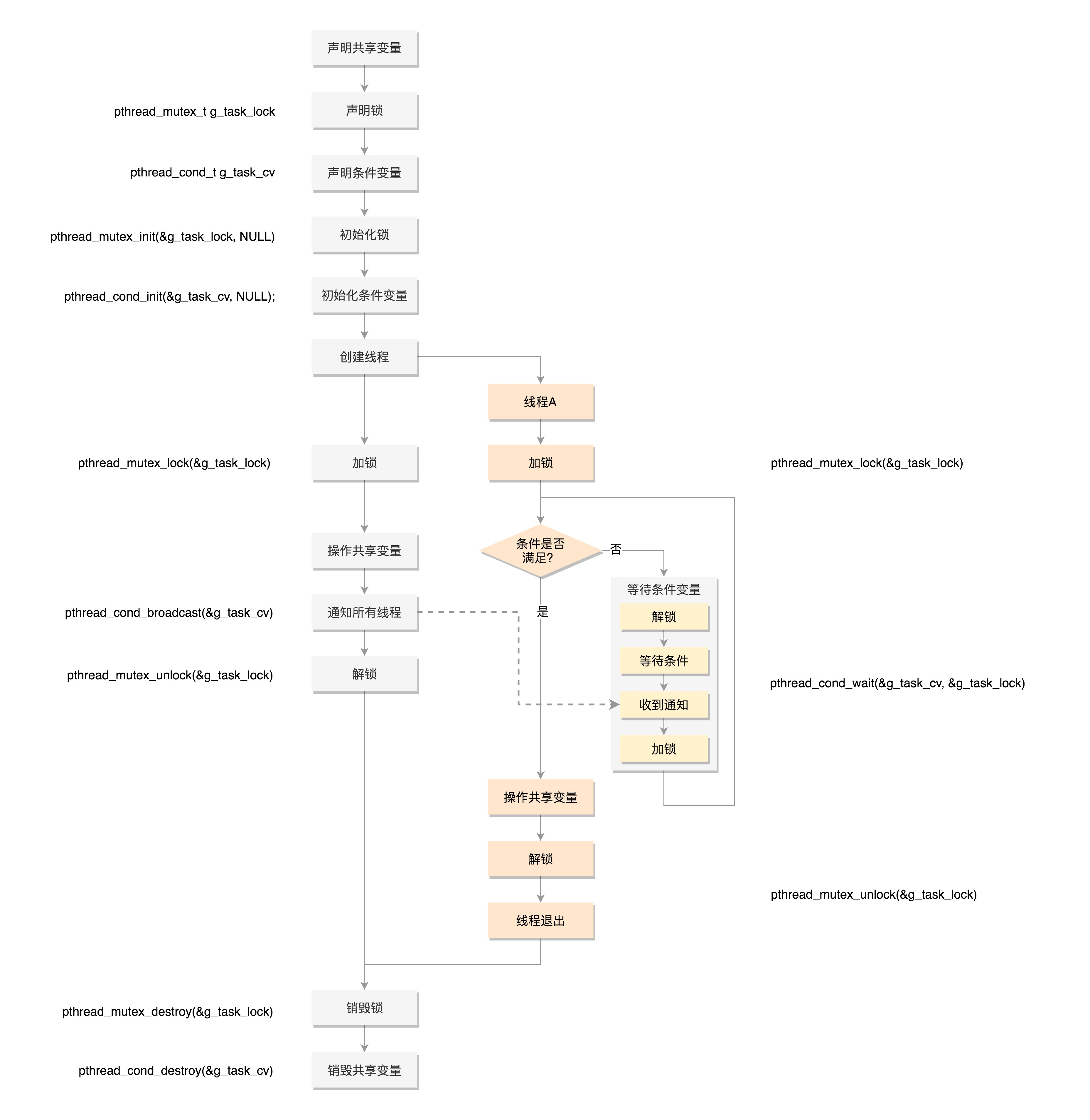
pthread_mutex_lock() blocks the thread, and pthread_mutex_trylock() does not block threads, but how do you tell a thread that the lock is idle? In fact, it is notified through condition variables.
Conditional variables and mutexes achieve synchronous waiting
When it receives a notification to operate shared resources, it still needs to grab the mutex, because many people may have been notified and accessed, so the condition variable and mutex are used together.
summary
We first generate so files and executable files through the file compilation process on the right of the figure and put them on the hard disk. Process A in user mode on the left of the figure below executes fork, creates process B, and executes exec series system calls in the processing logic of process B. This system call will pass load_elf_binary method, load the executable file just generated into the memory of process B for execution.
In this section, we talked about the complex data structure of process management. I'd like to draw a diagram to summarize it. This figure is a process management task_ Structure diagram of struct. The red part is the part talked about today. You can say their meaning in this picture.
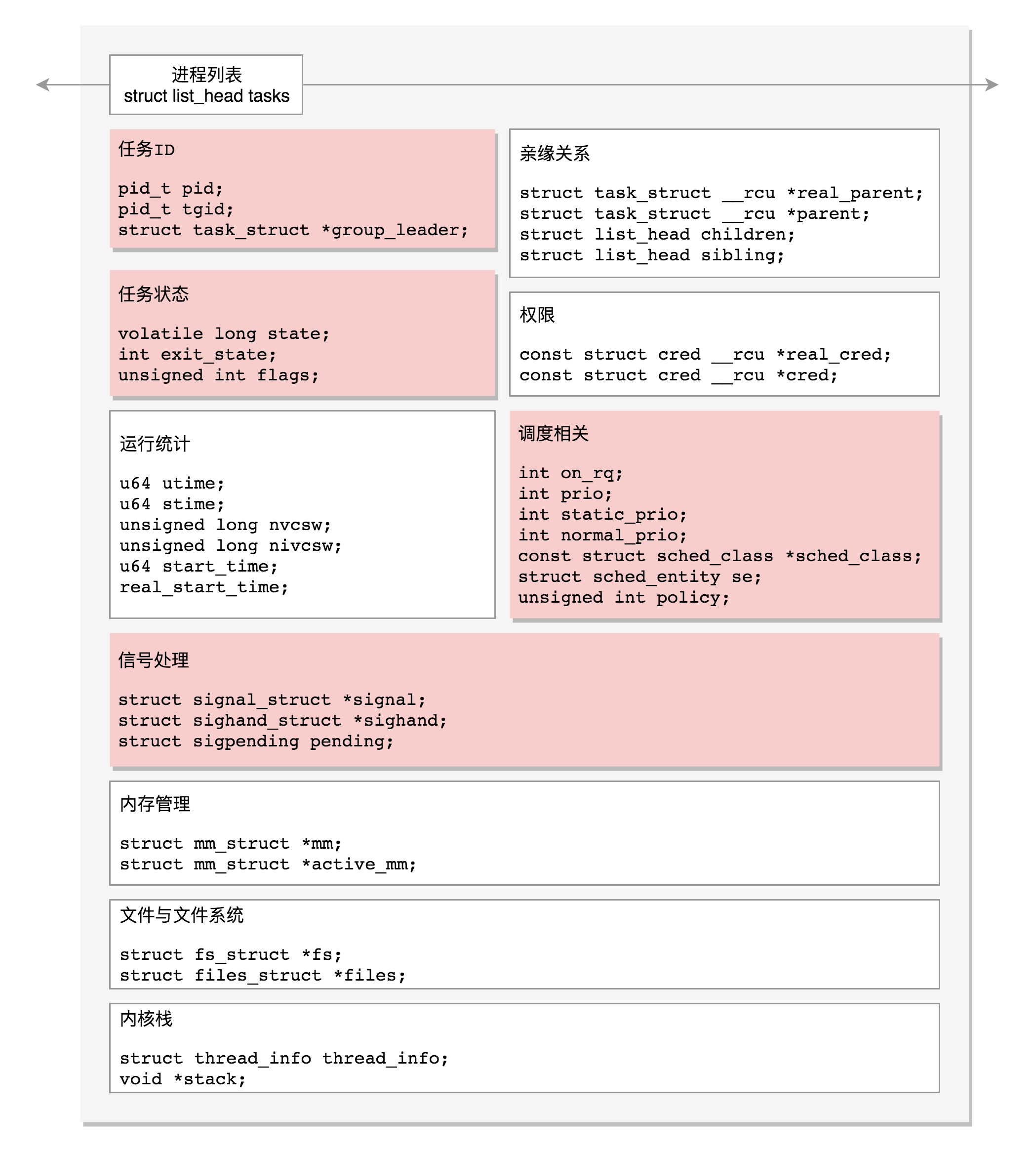
In this section, we have finally finished talking about the complex data structure of process management. Please remember the following two points:
-
The data structure of process kinship maintenance is a valuable implementation method. Similar structures will appear in many places in the kernel;
-
The principle of setuid in process permission is difficult to understand, but it is very important. It is often tested in interviews.
Although this section only introduces the kernel stack, the content is more important. If you say task_ Other member variables of struct are related to process management, and the kernel stack is related to process operation.
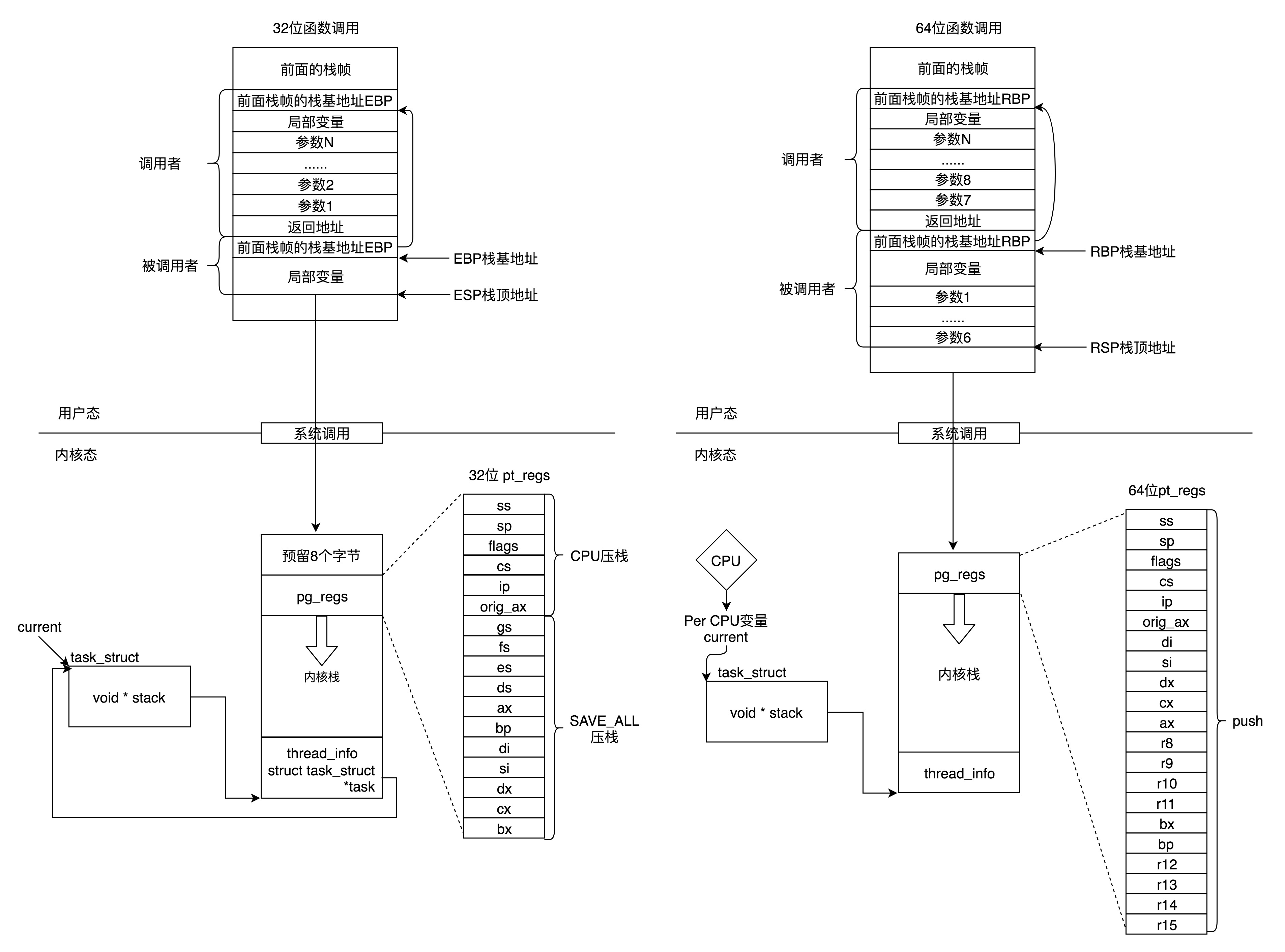
I drew a diagram here to summarize the working modes of 32-bit and 64 bit. The left is 32-bit and the right is 64 bit.
In user mode, the application makes at least one function call. 32-bit and 64 bit pass parameters in a slightly different way. 32-bit uses the function stack, the first six parameters of 64 bit use registers, and others use the function stack.
In the kernel state, both 32-bit and 64 bit use the kernel stack, and the format is slightly different, mainly focusing on pt_regs structure.
In kernel mode, 32-bit and 64 bit kernel stacks and tasks_ The association relationship of struct is different. 32-bit mainly depends on thread_info, 64 bit mainly depends on per CPU variables.
Remove the following line from this run
pthread_mutex_unlock(&g_money_lock);
}
//Destroy the lock. Remove the following line for the first run
pthread_mutex_destroy(&g_money_lock);
pthread_exit(NULL);
}
pthread_mutex_lock()Will block the thread, and pthread_mutex_trylock()The thread will not be blocked, but how to tell the thread that the lock is idle? In fact, it is notified through condition variables. ### Conditional variables and mutexes achieve synchronous waiting When it receives a notification to operate shared resources, it still needs to grab the mutex, because many people may have been notified and accessed, so the condition variable and mutex are used together. [External chain picture transfer...(img-c3pGTNCq-1638583442520)] # summary First, we generate the file through the file compilation process on the right side of the figure so Files and executable files, on the hard disk. The user status process on the left of the figure below A implement fork,Create process B,In process B In the processing logic of, execute exec Series of system calls. This system call will pass load_elf_binary Method to load the executable file just generated into the process B Executed in memory. [External chain picture transfer...(img-yJXBAGlm-1638583442520)] ------ In this section, we talked about the complex data structure of process management. I'd like to draw a diagram to summarize it. This diagram is process management task_struct Structure diagram of. The red part is the part talked about today. You can say their meaning in this picture. [External chain picture transfer...(img-JzjbeZG5-1638583442521)] ------ In this section, we have finally finished talking about the complex data structure of process management. Please remember the following two points: - The data structure of process kinship maintenance is a valuable implementation method. Similar structures will appear in many places in the kernel; - In process permissions setuid This is difficult to understand, but it is very important. The interview often takes the exam. **** Although this section only introduces the kernel stack, the content is more important. if task_struct Other member variables are related to process management, and the kernel stack is related to process operation. I drew a diagram here to summarize the working modes of 32-bit and 64 bit. The left is 32-bit and the right is 64 bit. In user mode, the application makes at least one function call. 32-bit and 64 bit pass parameters in a slightly different way. 32-bit uses the function stack, the first six parameters of 64 bit use registers, and others use the function stack. In the kernel state, both 32-bit and 64 bit use the kernel stack, and the format is slightly different, mainly focusing on pt_regs Structurally. In kernel mode, 32-bit and 64 bit kernel stacks and task_struct The relationship is different. 32-bit mainly depends on thread_info,64 Bit mainly depends on Per-CPU Variable. [External chain picture transfer...(img-wqSt6mwK-1638583442521)]