preface
- This article is about MIT 6 S081-2020-lab8 (lock) implementation;
- I didn't pass the Buffer cache test when I found the "global optimal solution";
- Therefore, in Exercise 2, I only provide my various code attempts and ideas on the premise of finding the "global optimal solution";
- If you find any problems in the content, please don't save your keyboard.
preparation
There is not much new to see, only the first three sections of Chapter 8 (File system).
Hierarchical model of file system

This diagram is particularly like the hierarchical service model of computer network: the current layer invokes the services provided by the lower layer to provide better services for the upper layer. But in fact, when it comes to the file system, the meaning here is not so strong. It is more like the abstraction of Disk. The lower it goes, the closer it is to the peripheral Disk, and the higher it goes, the closer it is to the user process. Most of the time, the hierarchy of the file system is not very strict, so the significance of this figure is to help you understand the structure of the file system.
Disks are usually SSDs or HDDs. It takes between 100us and 1ms for SSDs to access a disk block, and about 10ms for HDDs. For disk drivers, disks are a collection of sectors, and the size of a Sector is 512B; For the operating system kernel, the disk is a series of Block arrays, and the size of a Block is 1024B. We don't need to focus on Sector today because the disk driver kernel/virtio_disk.c provides a good shield for the kernel. We only need to use its externally provided interface for reading and writing a Block of the disk (top half: virtio_disk_rw()), and the given Block number returns the Block cache.
/* kernel/buf.h */
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};
/* kernel/bio.c */
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
In order to speed up read-write access, the design of cache is necessary. The entire file system has a Buffer cache(struct bcache). The Buffer cache stores multiple Block caches (struct buf). These Block caches and bcache The head forms a circular double linked list through binit(). The Block cache replacement algorithm used in Buffer cache is LRU(Least Recently Used, bget()). bcache.head.prev side will be the farthest used Block cache, while bcache head. Next will be the most recently used Block cache. At the same time, in order to ensure the consistency of Block content in the concurrent thread environment, the Buffer cache is equipped with a Spin Lock, and all buffer caches share a sleep lock. Why not all spin locks and the role of sleep lock will be introduced in the next section.
The Logging layer will not be introduced here, because this is the content of the next Lab.
/* kernel/fs.h */
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
Inode layer is mainly a layer of abstraction for files. Each inode has a unique inode number, and the size of each inode is 64 bytes. Given an inode number, we can calculate which byte of which Block the inode is located on the disk. After getting the inode from this address, we can calculate the size of the file corresponding to the inode and the blocks in which the file is stored.
dinode. The first NDIRECT elements of addrs [] are all direct Block numbers. The first sizeof(buf)*NDIRECT bytes of the file are stored in these direct Blocks. If the file size is relatively small, it may not be able to be loaded with NDIRECT Blocks; If the file size is large and NDIRECT Blocks cannot be installed, you need dinode Addrs [NDIRECT] this Indirect block number comes in handy. Indirect Block acts as an index Block, which contains a series of Block numbers, and the Blocks referred to by these Block numbers are responsible for installing the remaining files that cannot be installed by direct Blocks. Therefore, the maximum size of a file is sizeof(buf)*(NDIRECT+(sizeof(buf)/sizeof(buf.blockno))) bytes.
/* kernel/fs.h */
struct dirent {
ushort inum;
char name[DIRSIZ];
};
If the files users see are inode numbers, and then operate the files through these inode numbers, the file system is too difficult to use. Users may not know which file they are operating.
Therefore, when it comes to the directory layer, it provides users with hierarchical namespace services. You can give your files a memorable name and organize these files in the form of hierarchical directory. In order to realize these two points at the same time, we introduce a new data structure: struct dirent. And in order to support access to these data structures, we have extended the type of inode, so now dinode The value of type can not only be T_FILE, or T_DIR, these macros are defined in kernel/stat.h. sizeof(dirent) is 16 bytes, the directory name is 14 bytes, and dinode Link represents how many file names point to this inode.
The function provided by the path name layer is very simple: given a path name, the path name layer can parse it and find the files under the path. The analytical algorithm implemented by xv6 is linear scanning. That is, if you give the pathname / usr / RTM / xv6 / Fs c:
- The file system will first look for the root inode, and the inode number of the root inode is fixed to 1;
- Found that the type of root inode is T_DIR, and then traverse the Blocks pointed to by the root inode to search for dirent Directory whose name is usr;
- If it is not found, an error is returned. If it is found, the inode number to the usr is found, and the above steps are executed recursively;
- Finally get dirent Name is FS C. After obtaining the inode number;
- Found FS The inode type of C is T_FILE, found successfully.
The file descriptor layer provides many abstractions of Unix resources, including files, devices, pipes, sockets, etc. using this top-level file system interface can greatly simplify the operation of programmers accessing these resources. At first, file descriptors were only used for files. However, it was gradually found that the operation of resources such as devices and pipes was very similar to that of files, except opening, reading, writing and closing these operations. Therefore, the interfaces provided by the file system were used uniformly.
Organization structure of file system in Disk
The file system will regard the disk as an entire array of blocks, each of which is 1KB in size:
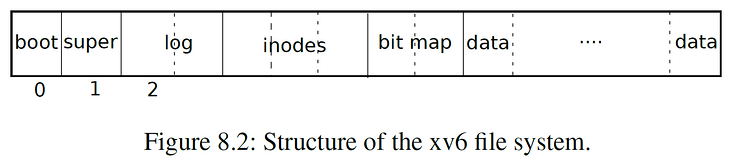
- disk[0] is either useless or the Boot Sector is used to start the operating system;
- disk[1] is called Super Block, which stores the metadata of the entire file system, including the size of the file system, the number of Data Blocks, the number of inodes, the number of Logging Blocks, etc;
- disk[2]~disk[31] are Logging Blocks;
- disk[32]~disk[44] store inode s;
- disk[45] is a bitmap. When the nth bit of the Block is set, it means that the Block with Block number n is being occupied;
- Disks [46]~ are all Data Blocks, and the occupied blocks store the contents of files or directories.
Buffer cache layer
The services provided by Buffer cache layer are as follows:
Ensure that there is no more than one copy (Block cache) of the same Disk block in the Buffer cache;
- Otherwise, data inconsistency will occur
Ensure that no more than one kernel thread accesses a Block cache at the same time;
- This is achieved by setting up a sleep lock for each Block cache
- Ensure that those Blocks that are frequently accessed have a copy in the Buffer cache (Block cache).
/* kernel/bio.c */
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock);
}
There are only two external interfaces of Buffer cache layer, one is break() and the other is bwrite(), both of which are in kernel / bio Defined in C. After the kernel thread completes the operation on a Block cache, it must release its lock (brelse()). Brelse () will not only release sleep lock, but also adjust the Block cache to bcache head. The next position indicates that it is the recently accessed Block cache.
bread()
- Given a Block number, return the corresponding locked Block cache;
- If hit, return directly;
- If it fails, select an idle Block cache according to the RLU algorithm (the refcnt field is 0, which means that the Block cache is not occupied by any kernel thread), choose to reuse it, set the valid field to 0, which means that the Block cache does not have data corresponding to the Disk block, and prompt the break() call to directly obtain the data of the Block from the disk.
- If there is no hit and there is no free Block cache, the file system will panic directly, which is a rough treatment.
bwrite()
- If a kernel thread modifies the content of a Block cache, it must call bwrite before releasing the Block cache sleep-lock, forcing the Block cache of the specified Block number to be written back to the Disk.
You can see that the implementation of bwrite() is simpler, so focus on the implementation of bread (). bread() called a bget():
/* kernel/bio.c */
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
If two kernel threads are concurrently executing bget(), in order to ensure that only one process is accessing the Buffer cache, the lock of the Buffer cache is obtained at the beginning of the function. After the last Block cache you want, you need to get the Sleep lock of the Block cache and return it.
/* kernel/sleeplock.c */
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void
releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
}
Why can't sleep lock be used together with Buffercache with ordinary spin lock? In fact, there are at least two considerations:
- Accessing a Block is a slow operation (in milliseconds). If a miss occurs during reading, the disk needs to be read. If the Block cache is modified, it needs to be written back to the disk. It is too slow compared with the speed of CPU executing instructions (in nanoseconds). Instead of keeping the CPU busy, sleep might as well let the CPU resources out.
- Don't forget that the scheduler will release the process lock, so the interrupt will not be closed during sleep, and it can also respond to the interrupt sent by the disk, which is impossible for a general spin lock. Sleep lock is a very exquisite lock.
In general, bcache Lock protects which blocks are cached, while sleep lock protects the contents of the Block cache during reading and writing.
Experimental part
Memory allocator
Multiple CPUs Hart share a freelist resource in memory, which is bound to cause very serious competition.
Therefore, in this Exercise, we need to allocate a freelist and a supporting lock for each CPU.
So we give kernel / kalloc The struct kmem in C can be extended into a kmem array with length of NCPU.
After that, you can use the cpuid() function to obtain which CPU hart is currently performing relevant allocation and release operations.
In particular, when the freelist under a CPU hart is empty, in kalloc(), it needs to check whether the freelist under other CPU hart has any margin. If so, it can be taken directly back.
We entrust the initialization of kmems to the CPU hart with cpuid() == 0, so all free page s are in the freelist under the CPU hart at the beginning.
/* kernel/kalloc.c */
struct kmem {
struct spinlock lock;
struct run *freelist;
};
struct kmem kmems[NCPU];
void
kinit()
{
for (int ncpu = 0; ncpu < NCPU; ++ncpu)
initlock(&kmems[ncpu].lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int cid = cpuid();
acquire(&kmems[cid].lock);
r->next = kmems[cid].freelist;
kmems[cid].freelist = r;
release(&kmems[cid].lock);
pop_off();
}
void *
kalloc(void)
{
struct run *r;
push_off();
int cid = cpuid();
acquire(&kmems[cid].lock);
r = kmems[cid].freelist;
if(r)
kmems[cid].freelist = r->next;
else {
for (int _cid = 0; _cid < NCPU; ++_cid) {
if (_cid == cid)
continue;
acquire(&kmems[_cid].lock);
r = kmems[_cid].freelist;
if (r) {
kmems[_cid].freelist = r->next;
release(&kmems[_cid].lock);
break;
}
release(&kmems[_cid].lock);
}
}
release(&kmems[cid].lock);
pop_off();
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
Buffer cache
In the original implementation, we maintain the old and new access degree of Block cache in the form of global double linked list, that is, the oldest block is on the prev side of head and the latest block is on the next side of head.
In this Exercise, in order to reduce the degree of competition, we need to abandon the design of double linked list and use bucket hash table instead. Why can using hash tables reduce competition? Because the granularity of a lock for a large linked list is obviously smaller than that of a lock for each bucket, which intuitively reduces the competition frequency.
On the premise that there are only Buffer cache locks and hash bucket locks, assuming that evict's scheme follows the original, that is, "find the oldest one with zero references from all block caches", this will conflict with the goal of Exercise.
The reasons for the contradiction are as follows: we call the original evict scheme to find the "global optimal solution". When A process miss es, it must prevent any process from trying to access or update any Block cache in the Buffer cache, otherwise an error will occur. For example, when process A finds the "global optimal solution", process B hits the Block cache and modifies its ticks and references. After that, the two processes will share A Block cache, which is A catastrophic error.
When designing the synchronization between processes, it will be clearer to list the requirements:
- When different processes are trying to hit, they can execute in parallel as long as they are not the same bucket. Otherwise, they can execute in serial;
- When a process performs evict operation, all other processes have to wait.
After understanding the types of locks, I found that read-write locks can best meet the needs here. Therefore, we intend to encapsulate a lock similar to a read-write lock, so the following is the implementation of Exercise:
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKET 13
struct entry {
struct buf *value;
struct entry *next;
uint ticks;
};
struct entry entries[NBUF];
struct bucket {
struct entry *e;
struct spinlock lock;
};
struct bucket table[NBUCKET];
int valid_cnt = 0;
struct entry *
remove(uint blockno)
{
int i = blockno % NBUCKET;
struct entry **p = &table[i].e;
struct entry *prev = 0;
struct entry *e = table[i].e;
for (; e; e = e->next) {
if (e->value->blockno == blockno) {
if (!prev)
*p = e->next;
else
prev->next = e->next;
return e;
}
prev = e;
}
return 0;
}
#define MAX_QUEUE_SIZE NBUF
struct entry *priority_queue[MAX_QUEUE_SIZE];
int
parent_index(int i)
{
return (i-1)/2;
}
int
left_child_index(int i)
{
return (2*i)+1;
}
int
right_child_index(int i)
{
return (2*i)+2;
}
void
swap_element(int i1, int i2)
{
struct entry *temp = priority_queue[i1];
priority_queue[i1] = priority_queue[i2];
priority_queue[i2] = temp;
}
uint current_queue_size = 0;
int
queue_push(struct entry *e)
{
if (current_queue_size == MAX_QUEUE_SIZE) return 1;
int current_idx = current_queue_size;
int parent_idx = parent_index(current_idx);
priority_queue[current_idx] = e;
while (current_idx != 0 && priority_queue[current_idx]->ticks < priority_queue[parent_idx]->ticks) {
swap_element(current_idx, parent_idx);
current_idx = parent_idx;
parent_idx = parent_index(current_idx);
}
++current_queue_size;
return 0;
}
struct entry *
queue_pop()
{
if (current_queue_size == 0) return 0;
struct entry *top_element = priority_queue[0];
int current_idx = 0;
swap_element(--current_queue_size, 0);
int left_child_idx;
int right_child_idx;
int min_child_idx;
uint left_child_ticks;
uint right_child_ticks;
uint current_ticks;
while (1) {
left_child_idx = left_child_index(current_idx);
right_child_idx = right_child_index(current_idx);
if (left_child_idx >= current_queue_size)
break;
left_child_ticks = priority_queue[left_child_idx]->ticks;
current_ticks = priority_queue[current_idx]->ticks;
if (right_child_idx >= current_queue_size) {
if (left_child_ticks < current_ticks)
swap_element(left_child_idx, current_idx);
break;
}
right_child_ticks = priority_queue[right_child_idx]->ticks;
min_child_idx = left_child_ticks < right_child_ticks ? left_child_idx : right_child_idx;
min_child_idx = priority_queue[min_child_idx]->ticks < current_ticks ? min_child_idx : current_idx;
if (min_child_idx == current_idx)
break;
else {
swap_element(min_child_idx, current_idx);
current_idx = min_child_idx;
}
}
return top_element;
}
void
queue_clear()
{
current_queue_size = 0;
}
struct {
struct spinlock lock;
struct buf buf[NBUF];
} bcache;
struct rwlock {
uint evicting;
uint hitting;
struct spinlock *lock;
};
struct rwlock evict_lock;
struct spinlock _evict_lock;
void
initrwlock(struct rwlock *rwlk, struct spinlock *splk)
{
rwlk->lock = splk;
rwlk->hitting = 0;
rwlk->evicting = 0;
}
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting == 1) {
release(rwlk->lock);
acquire(rwlk->lock);
}
++rwlk->hitting;
} else {
while (rwlk->evicting == 1 || rwlk->hitting != 0) {
release(rwlk->lock);
acquire(rwlk->lock);
}
rwlk->evicting = 1;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
--rwlk->hitting;
} else {
rwlk->evicting = 0;
}
release(rwlk->lock);
}
void
binit(void)
{
memset(entries, 0, sizeof(struct entry)*NBUF);
memset(table, 0, sizeof(struct bucket)*NBUCKET);
memset(bcache.buf, 0, sizeof(struct buf)*NBUF);
initlock(&bcache.lock, "bcache");
initlock(&_evict_lock, "bcache-evict");
initrwlock(&evict_lock, &_evict_lock);
struct buf *b;
for (b = bcache.buf; b < bcache.buf+NBUF; ++b)
initsleeplock(&b->lock, "buffer");
struct bucket *bkt;
for (bkt = table; bkt < table+NBUCKET; ++bkt)
initlock(&bkt->lock, "bcache-bucket");
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
// Is the block already cached?
struct buf *b;
int nbucket = blockno%NBUCKET;
struct entry *e;
acquirerwlock(&evict_lock, 1);
acquire(&table[nbucket].lock);
for (e = table[nbucket].e; e; e = e->next) {
b = e->value;
if (b->dev == dev && b->blockno == blockno) {
++b->refcnt;
release(&table[nbucket].lock);
releaserwlock(&evict_lock, 1);
acquiresleep(&b->lock);
return b;
}
}
release(&table[nbucket].lock);
releaserwlock(&evict_lock, 1);
// ------------------------------------------------------------
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
acquirerwlock(&evict_lock, 0);
if (valid_cnt < NBUF) {
b = &bcache.buf[valid_cnt];
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
e = entries + valid_cnt;
e->value = b;
e->next = table[nbucket].e;
table[nbucket].e = e;
++valid_cnt;
releaserwlock(&evict_lock, 0);
acquiresleep(&b->lock);
return b;
}
// -------------------------------------------------------
for (e = entries; e < &entries[NBUF]; ++e)
queue_push(e);
while ((e = queue_pop()) != 0) {
b = e->value;
int _nbucket = b->blockno % NBUCKET;
if (b->refcnt == 0) {
queue_clear();
if (_nbucket != nbucket) {
remove(b->blockno);
e->next = table[nbucket].e;
table[nbucket].e = e;
}
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
releaserwlock(&evict_lock, 0);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
acquirerwlock(&evict_lock, 0);
int nbucket = b->blockno % NBUCKET;
for (struct entry *e = table[nbucket].e; e; e = e->next)
if (e->value->blockno == b->blockno) {
e->ticks = ticks;
break;
}
--b->refcnt;
releaserwlock(&evict_lock, 0);
releasesleep(&b->lock);
}
void
bpin(struct buf *b) {
int nbucket = b->blockno % NBUCKET;
acquire(&table[nbucket].lock);
++b->refcnt;
release(&table[nbucket].lock);
}
void
bunpin(struct buf *b) {
int nbucket = b->blockno % NBUCKET;
acquire(&table[nbucket].lock);
--b->refcnt;
release(&table[nbucket].lock);
}
At first, I naively allocated entry memory with malloc. Later, I suddenly realized that there seemed to be no heap like a user process in the kernel memory layout, and the kernel could only allocate a full page of memory blocks at one time. Fortunately, the number of entries corresponds to the number of buffer caches one by one, so it can be allocated statically directly. Therefore, the original implementation is changed. Otherwise, I really can't think of how to allocate entries dynamically for the time being.
For the method of finding the oldest Block cache with a reference number of 0, no matter which sort algorithm (bubbling, merging, fast sorting) is used. I use the priority queue here because it is relatively simple to implement and the cost is not too large (but it is recommended to open a global sorting array and make the quick sorting of entries more concise, which is different from the operations of writing in and out of the queue). In other high-level languages, there are built-in libraries to provide the implementation of priority queue, but unfortunately, the wheels can only be built repeatedly in C. It should be noted that this priority queue needs to be implemented on a small top heap, which can be regarded as reviewing the knowledge of data structure.
I chose 13 as the number of hash buckets, because it is suggested that the number of buckets should be a prime number as far as possible. Why is it best to be prime? I attached the answer to this question in the reference link.
After initialization, there is no entry in our hash table, so a bget() cannot hit any of them. At this time, according to the original logic, the program will eliminate a Block cache with a reference number of 0. However, because the hash table is empty, the program will consider the elimination failed and directly panic. This is obviously unreasonable, because we don't even have a Block cache, so we need to check whether all block caches are valid before removing them. With the system running, the Buffer cache will soon be full, so this check cannot be performed many times.
Here's the point! After running bcache test, test0 and test1 can execute smoothly without any panic and deadlock, but test0 doesn't hang up unexpectedly. test0 gives that our read-write lock has been competed for more than 800000 times. Here, the goal of test0 (less than 500 times) is nearly 1000 times worse.
We might as well calculate the hit rate of Buffer cache from power on to the end of test0. I used two counter variables to record the results here. The results show that bget() has been requested nearly 32000 times, of which evict operation has been performed less than 90 times, and the hit rate is as high as 99.72%. On average, there is only one evict request out of 357 requests. Obviously, an evict will spin for a long time, and most of the competition times come from here. That's easy. We might as well let the process sleep requesting evict pass by and wait until there are no other bget() requests to wake up it. Therefore, the second version of the following is an improved read-write lock acquisition and release operation:
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting == 1)
sleep(rwlk, rwlk->lock);
++rwlk->hitting;
} else {
while (rwlk->evicting == 1 || rwlk->hitting != 0)
sleep(rwlk, rwlk->lock);
rwlk->evicting = 1;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
if (--rwlk->hitting == 0)
wakeup(rwlk->lock);
} else {
rwlk->evicting = 0;
wakeup(rwlk->lock);
}
release(rwlk->lock);
}
Of course, if you don't think it's necessary to sleep, you can also let it spin. However, no matter which version, after running bcachetest, the program directly stuck. Hit operations are very frequent, which makes no process have the opportunity to perform evict operations. Even if there is no process of hit operation at present, the overhead of wakeup and scheduling execution is very large. During this period, it is likely that new hit processes will come in, and rwlk->hittng will be discovered when the evict process wakes up. 0 went to sleep again. Here, I have checked many times and found no possibility of deadlock. It is likely that most processes failed to hit the target in the end. They fell asleep when they wanted the Block cache, and then no process woke them up.
We need to update the policy so that the priority of evcit operation is higher than that of hit operation, that is, an evict operation comes. If there is a hit operation currently, respond to the evict operation immediately after the hit operation is completed. The following is the acquisition and release operation of the improved read-write lock in the third version. We have added an evicted field for the read-write lock:
struct rwlock {
uint evicting;
uint hitting;
uint evicted;
struct spinlock *lock;
};
struct rwlock evict_lock;
struct spinlock _evict_lock;
void
initrwlock(struct rwlock *rwlk, struct spinlock *splk)
{
rwlk->lock = splk;
rwlk->hitting = 0;
rwlk->evicting = 0;
rwlk->evicted = 1;
}
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting != 0)
sleep(rwlk, rwlk->lock);
++rwlk->hitting;
} else {
++rwlk->evicting;
while (rwlk->evicted == 0 || rwlk->hitting != 0)
sleep(rwlk, rwlk->lock);
rwlk->evicted = 0;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
if (--rwlk->hitting == 0 && rwlk->evicting == 0)
wakeup(rwlk);
} else {
--rwlk->evicting;
rwlk->evicted = 1;
wakeup(rwlk);
}
release(rwlk->lock);
}
bcachetest ran smoothly, and our competition times reached a new high, reaching an unprecedented number of tot= 50236847. I'm stupid because the previous analysis is inconsistent with the reality. Change the third edition to all spins, and the number of competitions is as much as tot= 487775; When it is changed to hit spin and evict mutual exclusion, the number of competition is tot= 49768743; Change to evict spin. When hit is mutually exclusive, the number of contentions is tot= 22981816.
Here I really tried my best. Finally, I couldn't help reading the articles written by others about this experiment. Anyway, at least what I see now passed the test by using the method of "local optimal solution". Although I didn't find that I passed the test when I found the "global optimal solution", it's difficult for me to agree that this is correct. Therefore, I can only provide one idea here. It is the limit to do this experiment alone.
Postscript
This lock experiment is really difficult. I don't know if it's difficult for me to do it or if there is a simpler method. Before Hard's Exercise, the actual coding amount was small, but it was difficult to think of it. However, Exercise 2 of this experiment wrote about 300 lines, which was particularly difficult to debug. I thought for a long time (intermittently for about three days). During this period, I tried to use various schemes, first spin lock, then mutex lock, then read-write lock (spin lock implementation), and finally read-write lock (mutex Implementation), as well as some other bugs. During this period, the frequency of competition has been more than 800000 times, more than 20 million times, more than 10000 times and more than 50 million times, which is really a test of people's patience. I didn't record all this because there were too many