preface
- The default reader has a basic understanding of the structure of the three-level page table;
- All of the following contents can be found in the xv6 book, experimental instructions and xv6 source code;
- When you find errors or improvements, please don't save your keyboard.
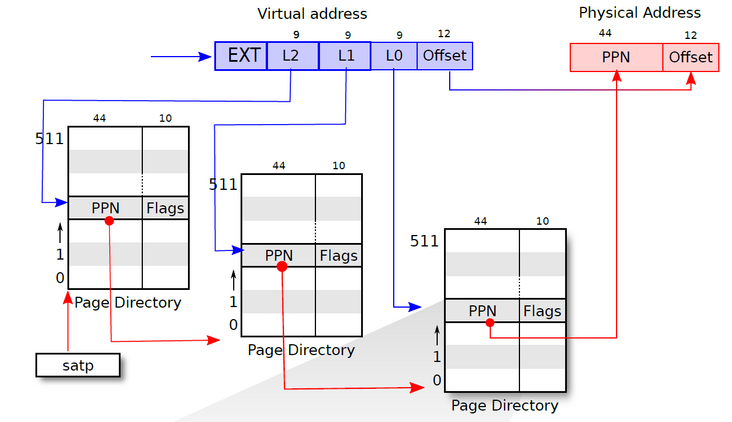
1, Preparatory work
1. Kernel memory layout
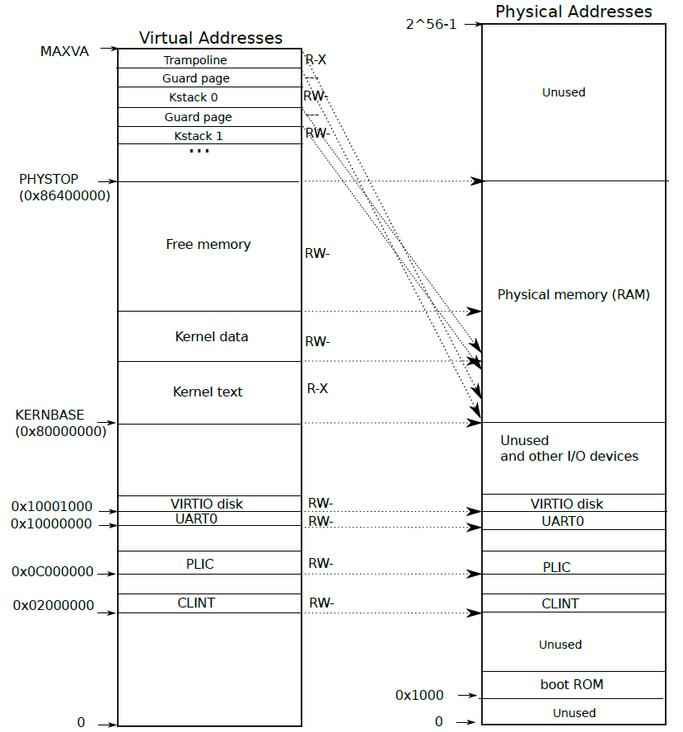
On the left is the virtual memory layout of the Kernel, and on the right is the physical memory layout mapped to the past. All processes in the system (including Kenel and user processes) are located between kenbase and PHYSTOP addresses. The end address of the Kernel is at the end of Kernel Data or the beginning of Free memory. It can be seen that the virtual address of the whole Kernel is directly mapped on RAM, and therefore the Trampoline page and kernel stack page are mapped twice for the convenience of Kernel access to these two places.
Note that the highest address value of the physical memory layout on the right is 2 ^ 56-1 and the lowest is 0, which means that the figure on the right covers all the physical memory in the system, indicating that the Kernel can access most of the addresses (most of it is because the total number of virtual addresses 2 ^ 39 is smaller than the total number of physical addresses). The user process must be in RAM, and the Kernel can be mapped and accessed directly.
It is worth mentioning that xv6 does not use all 39 bit virtual addresses. It discards the highest bit and only uses the remaining 38 bits. The specific reason seems to be related to the value type. I don't know the relevant details.
/* kernel/riscv.h */ ... // one beyond the highest possible virtual address. // MAXVA is actually one bit less than the max allowed by // Sv39, to avoid having to sign-extend virtual addresses // that have the high bit set. #define MAXVA (1L << (9 + 9 + 9 + 12 - 1))
2,sbrk()
We will derive a series of functions from the system call sbrk(). sbrk() is used to increase or decrease the available heap size of user processes. Its function call tree is as follows:

int growproc(int n) :
- pagetable_t type pointer will directly point to the top-level page table address;
- If $n > 0 $, call uvmalloc() to allocate memory and increase the user process memory by n/PGSIZE pages (PGSIZE=4096B);
- If $s < 0 $, call uvmdealloc() to allocate memory and reduce the user process memory by n/PGSIZE pages.
void * kalloc(void): allocate a page size of physical memory
- All free page s are recorded in stuct kmem;
- struct run is a structure defined by a loop, which records the free page in RAM in the form of a linked list.
void kfree(void *pa): release a page and append it to the header of kmem.freelist
- We can see something from kfree's source code:
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree");- This indicates that the Kernel is unwilling to release kernel text and data, at least it cannot call kfree() to do so.
pte_t * walk(pagetable_t pagetable, uint64 va, int alloc):
- The translation of virtual addresses is left to the hardware MMU, and xv6 adds a walk function to simulate this process, which is one of the core functions of the page table:
// Some necessary macro definitions
// Get the PTE corresponding to the physical address (all flags fields are zero)
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
// Get the physical address of the page table pointed to by the PTE
#define PTE2PA(pte) (((pte) >> 10) << 12)
// Truncate the lower 10 bits to obtain the PPN field of PTE
#define PTE_FLAGS(pte) ((pte) & 0x3FF)
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
// Gets the index number of the virtual address at the level level
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
// one beyond the highest possible virtual address.
// MAXVA is actually one bit less than the max allowed by
// Sv39, to avoid having to sign-extend virtual addresses
// that have the high bit set.
#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))
// Returns the address of the PTE corresponding to the virtual address va under pagetable
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
// Loop through the first two page tables
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
// If current PTE is available
if(*pte & PTE_V) {
// Update to the physical address of the next level page table
pagetable = (pagetable_t)PTE2PA(*pte);
// If it is not available, it is determined whether to allocate a new next level page table according to the alloc parameter
// The size of a page table is 512 × (44+10)/8=27 × 2^7B
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
// Initialize the newly allocated page table
memset(pagetable, 0, PGSIZE);
// Update the PTE field content of the current page table
*pte = PA2PTE(pagetable) | PTE_V;
}
}
// Returns the address of the PTE corresponding to va in the page table of the last level
return &pagetable[PX(0, va)];
}int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm):
- Map successive pa/PGSIZE pages starting from pa to the virtual address of the given page table (the mapped virtual address must be ~PTE_V).
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
// Round down to the size of a page
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
// Create the PTE corresponding to the current virtual address in the last level page table
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("remap");
// Set the PTE field corresponding to the current virtual address with the address of the current physical page
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
// Both the virtual address and the physical address are incremented by a PGSIZE
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}3,main()
In the main() function, let's focus on the following calls related to the page table:
... kinit(); // physical page allocator kvminit(); // create kernel page table kvminithart(); // turn on paging procinit(); // process table ...
Note the size relationship of these addresses (increase from top to bottom, subject to the xv6 source code):
- KERNBASE: 0x0000000080000000
- etext: 0x0000000080008000
- end: 0x0000000080027020
- PHYSTOP: 0x0000000088000000
kinit(): clear RAM and add all page s to kmem.freelist one by one;
- This is a call to freerange(end, (void*)PHYSTOP); To achieve this, after calling kmem.freelist, there will be 32728 pages in the linked list, and then kalloc() will take pages from Free memory;
kvminit(): initialize the page table of the kernel, and call the corresponding kvmmap() function in turn according to the page table layout of the kernel;
- The kvmmap() function is a simple wrapper around the mappages() function, so the pages in kmem.list will be consumed only when a new page table is allocated;
There is a line of code that you can pay a little attention to:
// map kernel data and the physical RAM we'll make use of.
- `etext` yes kernel `text` The end address of this call also means `RAM` All in page Are mapped directly.
- Kvminichart(): set the bit of satp register to kernel page, and then clear the TLB cache. After that, the addresses in all codes will be virtual addresses under the kernel page table;
procinit(): pre allocate space for the kernel stack of subsequent NPROC user processes and map it into the corresponding position in the virtual memory layout of the kernel. This is done through the following three lines of code:
char *pa = kalloc(); uint64 va = KSTACK((int) (p - proc));
4,trampoline
Trampoline contains uservec and userret functions (/ kernel/trampoline.S), which are the functions to be executed when handling interrupts.
There are three types of interrupts in xv6:
- System call;
- Operation error (e.g. division by zero, use of inappropriate virtual address);
- The device can mask interrupts (such as read-write returns).
I learned from the unit that interrupt response, interrupt processing and interrupt response are completed by hardware, while the on-site protection during interrupt processing is completed by software. Now, this software is the operating system. When an interrupt occurs, the hardware (RISC-V) and software (xv6's kernel) need to jointly maintain the following control registers:
- stevec: the kernel saves uservec (for interrupts from user space) or kernel VEC (for interrupts from kernel space) here;
- sepc: RISC-V saves the current program counter here to facilitate interrupt return;
- Cause: RISC-V saves the cause of the interrupt here;
- sscratch: the kernel will save the address of the trapframe page here;
- sstatus: if the kernel clears the SIE bit, the RISC-V shutdown is interrupted. The SPP bit represents whether the source of the current interrupt is user mode or supervisor mode, which is convenient to return to the corresponding mode.
When an interrupt occurs, the hardware should do the following:
- If the device is interrupted and the SIE bit of the current ssStatus is cleared, RISC-V will ignore the interrupt, otherwise continue to perform the following steps;
- Clear the SIE bit, indicating that the maskable interrupt is closed;
- Assign the value of the current pc to sepc;
- Save the current mode information to the SSP bit of ssStatus;
- Set scause;
- Set the current mode bit supervisor mode;
- Assign stvec to pc;
- Execute the interrupt handler.
When an interrupt occurs, the software generally needs to do the following:
- Set the address of the kernel page table to the satp register;
- Set the address of the kernel stack to the sp register;
- ......
The reason why it is general is that each operating system kernel will have its own careful thinking in the design of this area. lab 3 takes this as an article.
For interrupts from user space, a clear function call chain is uservec - > usertrap - > usertrapret - > userret. We need to switch from the user page table to the kernel page table in uservec. In order to enable the function code to continue to execute before and after switching, the following two necessary conditions need to be met:
Do not change the logical address;
- The pc register executes subsequent instructions by continuously increasing itself, so the virtual address of the code cannot change.
Don't change the physical address.
- Of course, the physical address mapped through PTE has changed, which is obviously an error.
Therefore, everyone (including the kernel) of trampoline is also set at the top of the virtual address space. When initializing the page table of each process, the mapping () function is used to ensure the consistency of PTE.
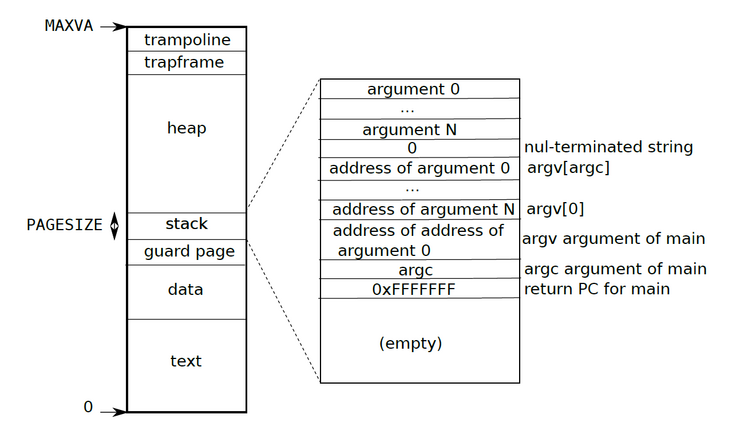
5,uservec()
uservec's task is to set the satp register to kernel pagetable and save the value in the register into the trap frame. When initializing the user's page table, the trapframe is mapped in the user's virtual address space and directly below the trampoline. Therefore, when satp = user pagetable, we can easily save the value of the register into the trapframe. But after switching to kernel pagetable, how does the kernel access the user's trackframe? In fact, after initializing the page table of the process, you can directly access p - > trapframe:
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}Before copying the register value to the trapframe, you need to pay attention to one detail. RISC-V has 32 integer registers, which are x0~x31; Where x1~x31 are general-purpose registers, their ABI aliases need to be used when they are used in assembly code. If you want to copy the values of these 31 general registers to the trapframe, you need to vacate the position of the register (a bit similar to the digital huarongdao). RISC-V does this through sscratch register and csrrw instruction:
uservec:
#
# sscratch points to where the process's p->trapframe is
# mapped into user space, at TRAPFRAME.
#
# swap a0 and sscratch
# so that a0 is TRAPFRAME
csrrw a0, sscratch, a0
# save the user registers in TRAPFRAME
sd ra, 40(a0)
...
sd t6, 280(a0)
# save the user a0 in p->trapframe->a0
csrr t0, sscratch
sd t0, 112(a0)
...The next step is to safely assign some important fields in the trapframe to the register. After execution, the page table is the kernel pagetable:
struct trapframe {
/* 0 */ uint64 kernel_satp; // kernel page table
/* 8 */ uint64 kernel_sp; // top of process's kernel stack
/* 16 */ uint64 kernel_trap; // usertrap()
/* 24 */ uint64 epc; // saved user program counter
/* 32 */ uint64 kernel_hartid; // saved kernel tp
...
};uservec:
# restore kernel stack pointer from p->trapframe->kernel_sp
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
ld tp, 32(a0)
# load the address of usertrap(), p->trapframe->kernel_trap
ld t0, 16(a0)
# restore kernel page table from p->trapframe->kernel_satp
ld t1, 0(a0)
csrw satp, t1
sfence.vma zero, zero
# a0 is no longer valid, since the kernel page
# table does not specially map p->tf.
...Someone should ask when the values of these fields in the trapframe were initialized? The answer is to allocate and initialize the usertrapret function to invoke the user process, and then return to user space after the call is completed. The call chain is fork () - > allocproc () - > forkret () - > usertrapret (). The logic is relatively clear and simple, so turn to the implementation of usertrapret. It can also be seen from this that all user processes in the system, except the init process, are generated by calling the fork function.
6,usertrap()
/* /kernel/trap.c */
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(p->killed)
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}usertrap function is the core function of interrupt processing, but it is not difficult to understand, so I will briefly mention several details:
- Once again, save the pc to the user process's trap frame. This is because considering that nesting will overwrite the contents of sepc register, it is better to assign it when calling usertrapret;
- If it is a system call, execute it. Before that, pc should remember to add 4, because we certainly don't want to execute ECALL instruction again after the interrupt returns, and the length of ECALL instruction is 4 bytes;
- If it is an exception, directly kill the whole error process, that is, exit(-1);
- Combined with the implementation of the Scheduler function, the current xv6 scheduling algorithm should be the Round Robin scheduling algorithm, which generates interrupts through the device timer to give up the CPU.
2, Lab 3
With these pre knowledge, let's look at the original text at the end of Chapter 4 of xv6 book:
The need for special trampoline pages could be eliminated if kernel memory were mapped into every process's user page table (with appropriate PTE permission flags). That would also eliminate the need for a page table switch when trapping from user space into the kernel. That in turn would allow system call implementations in the kernel to take advantage of the current process's user memory being mapped, allowing kernel code to directly dereference user pointers. Many operating systems have used these ideas to increase efficiency. Xv6 avoids them in order to reduce the chances of security bugs in the kernel due to inadvertent use of user pointers, and to reduce some complexity that would be required to ensure that user and kernel virtual addresses don't overlap.
The above is what Lab3 needs to do.
We need to make each user process have an independent copy of the kernel page table. This page table can be regarded as a combination of user page table and kernel page table. The benefits of doing so are also mentioned at the end of the experimental guidance:
Linux uses a technique similar to what you have implemented. Until a few years ago many kernels used the same per-process page table in both user and kernel space, with mappings for both user and kernel addresses, to avoid having to switch page tables when switching between user and kernel space. However, that setup allowed side-channel attacks such as Meltdown and Spectre.
When doing the experiment for the first time, don't think too much. First think about what the three exercises do respectively, so as to prevent the situation of fighting wisdom and courage with the air. Basically follow the tips on the experimental guidance. I don't show my code. First, my coding is too smelly, and I need to implement it online; Second, my own implementation of Exercise 3 always reported an abnormal interruption of kerneltrap. After checking for several laps, I finally gave up and only got the scores of the first two exercises.
summary
Keep your feet on the ground and don't think about it.
other
Clever use of page fault exception
I believe some people will think that calling exec() immediately in the call of fork() is a waste of resources, because it is meaningless for the child process to copy the memory content of the parent process, which is a short board in xv6 design. Therefore, on the real OS, someone designed the cow (copy on write) fork function. The mechanism of this function is as follows:
- First, when creating a child process, do not copy all memory, but set all PTE s of the last level page table of the parent process to read only, and then copy the child process to the page table of the parent process.
- The child parent process is fine when reading, but once one party intends to write, it will throw a page fault exception, which is handled by the kernel.
- If it is xv6, the kernel will kill the process directly without mercy. But here, the kernel will copy the page pointed to by the PTE that raises the exception, map it to the page table of the child process, and set their PTEs to writable.
People who have learned about segment trees should soon realize the benefits of this mechanism, which is lazy modification. Similarly, any function related to paging, combined with page fault, can effectively improve its resource utilization, such as lazy allocation, paging from disk, automatically extending stacks and memory mapped files.
Process switching
Under the running model of single core CPU only, the interaction between CPU context and memory is roughly as follows from the beginning of scheduler() calling swtch() to the end of timer interrupt and yield() calling swtch() when it comes out of CPU:
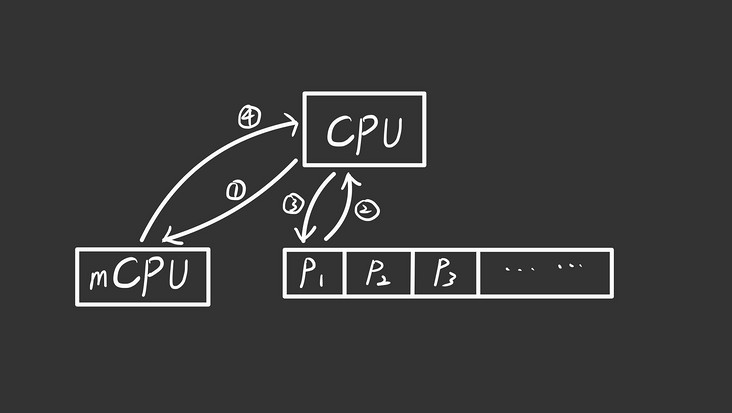
In the main() function, after userinit() initializes the init process, it will be scheduled by the scheduler. Let's look at some details of what happens during scheduling. After the scheduler finds the init process, it will execute swtch (& C - > context, & P - > context). This swtch() call is to execute step ① and ② above.
/* kernel/swtch.S */
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
...
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
...
ld s11, 104(a1)
retswtch() mainly exchanges the callee saved register and finds that the most critical program counter and user page table are not set. How do you execute the instructions of the user process? The answer is that the on-off interrupt returns to set the program counter. The LD, RA, 0 (A1) instruction means to assign the value of P - > context.ra to the RA register (return address register). We found the initial value of this field in allocproc() function:
// Set up new context to start executing at forkret, // which returns to user space. memset(&p->context, 0, sizeof(p->context)); p->context.ra = (uint64)forkret; p->context.sp = p->kstack + PGSIZE;
Therefore, after swtch executes the ret instruction, the program counter is set to the position of the forklet function and starts to execute the interrupt return instruction.
Reference link
- xv6: a simple, Unix-like teaching operating system, by Russ Cox, Frans Kaashoek, Rober Morris
- [ARM Linux] Why does the kernel page table of each process allocate storage space separately?
- Detailed explanation of GDB debugging command
- Fall2020/6.S081 - how to use gdb in QEMU
- layout usage of gdb debugging