1. yarn overview
1.1. yarn is the resource management module in the cluster
Provide resource management and scheduling for various computing frameworks
① Used to manage cluster resources (server hardware, including CPU, memory, disk, network IO, etc.);
② Scheduling various tasks running on yarn
Scheduler:Used for hadoop Running at the same time in a distributed cluster job Planning and constraints. In short: scheduling resources and managing tasks
1.2. Core starting point: separation of resource management and operation monitoring
① Global resource management - RM
② Each application corresponds to an application resource management - AM
1.3 dispatching level
① Primary dispatching management
Computing resource management (CPU, memory, disk, IO)
② Secondary dispatching management
Internal task calculation model management (Appmaster task refinement management)
2. Related concepts
2.1,ResourceManager
① Scheduler: allocate resources in the system to running applications according to capacity, queue and other conditions.
② Application Manager: monitor and manage all applications in the whole system, and track the progress and status of the assigned container.
2.2,NodeManager
Resource and task managers on each node
① Regularly report the resource usage on the node and the running status of each container to the resource manager
② Accept and process the start / stop request of appmast er's container
2.3,Appmaster
The programs consulted by users include an Appmaster, which is responsible for application monitoring, tracking application status, and restarting is a failed task.
2.4,Container
Resource abstraction, including memory, CPU, disk, network, etc
When Appmaster requests resources from resources, the resources returned by Resource manager for Appmaster are represented by container.
3. Type of scheduler
3.1 queue scheduling
Tasks are submitted in a queue. During resource allocation, first in first out is used. Only one task can be executed in the queue at the same time
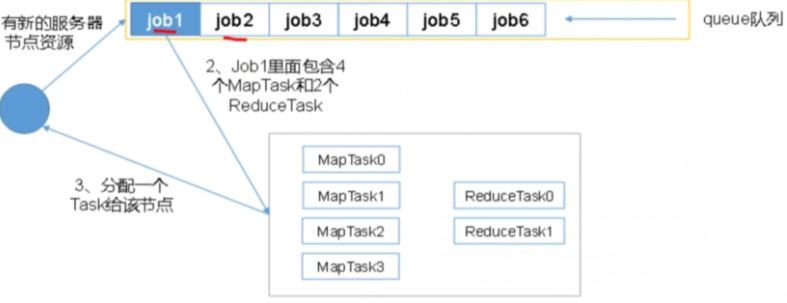
- Large tasks occupy cluster resources, causing other tasks to be blocked

3.2 capacity scheduler
Multi queue,Each queue is first in, first out,At the same time, only one task in the queue is executing. In the same queue, the first to arrive and the first to serve; :1,The parallelism of the queue is the number of queues; :2,Queue scheduling is adopted within each queue; :3,To prevent jobs of the same user from monopolizing resources in the queue,The scheduler will limit the resource amount of jobs submitted by the same user; :4,When submitting a task,A queue that is the most idle will be selected; :5,In order of job priority and submission time,Sort the tasks in the queue;

3.3 fair scheduler
Fair Scheduler :Multiple queues. Resources are allocated within each queue according to the vacancy size to start the task,Multiple tasks are executed in the queue at the same time, and the parallelism in the queue is greater than or equal to the number of queues,Schedule according to vacancy,Priority for those with large vacancies; :1,In each queue job Resources are allocated according to priority. The higher the priority, the more resources are allocated; :2,In the same queue, jobs are executed successively according to the vacancy,job The greater the resource gap,The earlier you get resources to run; Vacancy - With limited resources,each job The gap between the ideal computing resources and the actual computing resources;
Allocate fair resources to all applications, and fair scheduling can work in multiple queues. ①Suppose there are two A and B,They each have a queue; ②When A Start a job,and B No, job,A All cluster resources will be obtained; ③When B Start a job After, A of job It will continue to run, but after a while, each of the two tasks will get half of the cluster resources; ④if B Start the second one job And others job If it is still running, it will and B The first one job share B The resources of this queue, B Two job Each uses a quarter of the resources of the cluster, and A of job Half the resources of the cluster will still be used, and the result is that the resources will eventually be shared equally between the two users.
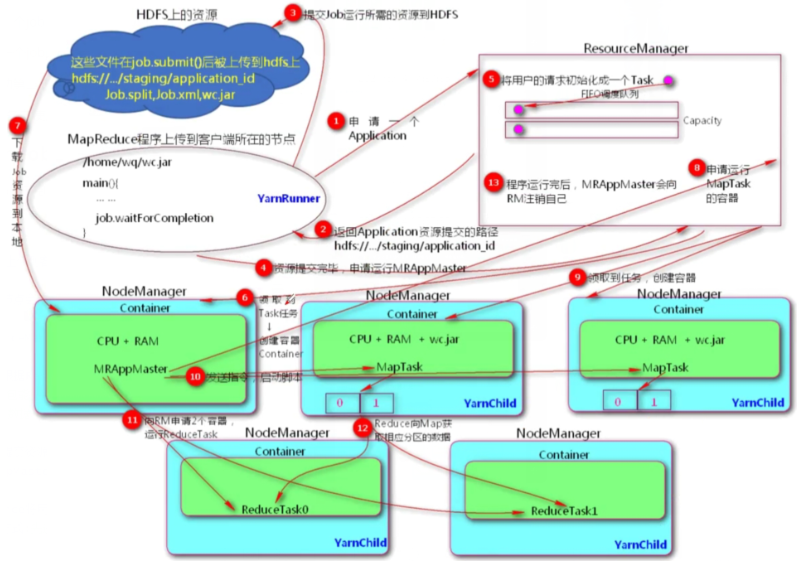
4. Yan job submission process
- The internal steps of submitting a Job to the hadoop cluster
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-o9bwes3e-1627811225383) (C: / users /% E6% 9D% 8e% E6% B5% B7% E4% BC% 9F / appdata / roaming / typora / typora user images / image-20210616194540155. PNG)]
1,MR The program is uploaded to the node where the client is located, and the moment you hit enter 2,The client node sends ResourceManager Apply for one Application 3,ResourceManager A resource submission path is returned to the client node,About to be submitted by the client jar Package final submission to HDFS Corresponding path of application_id; 4,Client based ResourceMnager Feedback results,Will Job Resource requirements submitted to HDFS upper; :jar The package can be used by all nodemanager Executed,nodemanager The corresponding data will be downloaded during calculation jar package :Mobile data is not as good as mobile computing; 5,After the client submits the resource, it will send it to the ResourceManager Request to run a MRAppMaster process; MRAppMaster process:towards ResourceManager Apply for resources; 6,Resource Initialize the user request as a Task; Scheduling mode:fifo 7,Nodemanager Received task Computing tasks in many nodemanager Choose one at random as MRAppMaster,Will create a container container(CPU,Memory, network bandwidth) 8,download job Resources arrive locally, i.e MRAppMaster Where NodeManager Node of; 9,MRAppMaster towards ResourceMnager apply Maptask Running container; 10,nodemanager Get the task, create a container and download it jar package; 11,MRAppMaster Send command startup script,Maptask Parallel execution,The calculation result is written to the partition; :such as Maptask The calculation results have only two partitions; 12,maptask After the calculation, MRAppMaster towards Reduce Apply accordingly reduce Required number of containers 13,Reduce towards Map Obtain the data of the corresponding partition, perform parallel computing, and land to HDFS upper; 14,After the program runs MRAppMaster towards RM Apply for cancellation,nodemanager Will to RM After reporting the calculation, apply for other calculation tasks;
5. Frequently asked questions
5.1. Kill Command is stuck for several minutes without log output
P: Submit Hive query task, job status running, log prompt: Kill Command is stuck for several minutes without log output. What should I do?
YarnApplicationState Field is the current job status, Queue The cluster queue is currently running View the running status of the task as waitting,That is, wait for the running status of the resource, because the queue used by the user is root.default,This queue is a public queue, and waiting occurs when resources are tight. Solution: for application groups with separate queues for application clusters, it is necessary to check whether batch tasks are started in the queue, resulting in tight resource queues. Check the shortage of resources caused by normal use. It is recommended that users apply for resource queue expansion to solve the problem.
5.2. How to select a scheduler in a production environment?
Big factory:If the requirement for concurrency is high and fairness is selected, the server performance must be improved OK; Small and medium-sized companies:The cluster server resources are not sufficient, and the capacity is selected.
5.3 how to configure queues in a production environment
(1)The scheduler defaults to 1 default Queue, unable to meet production requirements. (2)According to business module:Login registration, shopping cart, order placement, business unit 1, business unit 2