Also known as, sort out your unreliable learning records.
YOLOv5 profile
YOLOv5 is built through yaml configuration file. First, it is in common Build a class with the same name in the PY file, and then read the corresponding operation from the configuration file. The class of the operation will be instantiated. The whole network structure is made up of Model class, and parse_ is called in Model. The model () function, after analyzing the configuration file by this function, calls the corresponding class to build the network, and then constructs the Model to implement the subsequent processing.
parse_ The model() function exists in Yolo Py file.
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
add = d['backbone'] + d['head']
Take yolov5s Yaml is one of the behavioral examples
[-1, 1, Conv, [64, 6, 2, 2]] #[from, number, module, args]
After defining the above parameters, parse_ The model() function takes out the contents of the yaml file by line and puts them into F, N, m and args in turn,
f = -1 represents the acceptance of features from the upper layer,
n = 1 means there is only one such operation,
m = Conv this layer needs to perform Conv operation,
args = [64, 6, 2, 2] represents that the output of this layer is 64 dimensional, with a convolution kernel of 3 * 3 and a step size of 1.
Among them, yolo.com needs to be parsed The code of m = eval(m) if isinstance(m, str) else m in py file.
SPP introduction
why
CNN can simply = convolution network layer + fully connected network part.
Convolution kernel: it can be applied to any size of input and produce any size of output.
Full connection layer: the parameter is the connection weight of the neuron for all inputs. If the input size is not fixed, the number of full connection layer parameters cannot be fixed.
CNN needs to first zoom the image to a fixed scale for each regional candidate.
problem
Speed bottleneck: repeatedly extracting features for each region proposal is extremely time-consuming.
Performance bottleneck: scaling all region proposal s to a fixed size will lead to unexpected geometric deformation. Moreover, due to the existence of speed bottleneck, it is impossible to train the model with multi-scale or a large amount of data enhancement.
Common ideas
The full connection layer needs fixed input. A network layer is added in front of the full connection layer to produce fixed output for any input.
For the output pool of the last layer of convolution layer, but the size and pace of the pool window are set to relative values (a proportional value of the output size).
Consequence: arbitrary input – fixed output
Solution SPPNet
Add SPM to the above ideas.
For example, an image is divided into 1, 4, 8, etc., and then features are extracted for each block and fused together----- Compatible with multiple scale features.
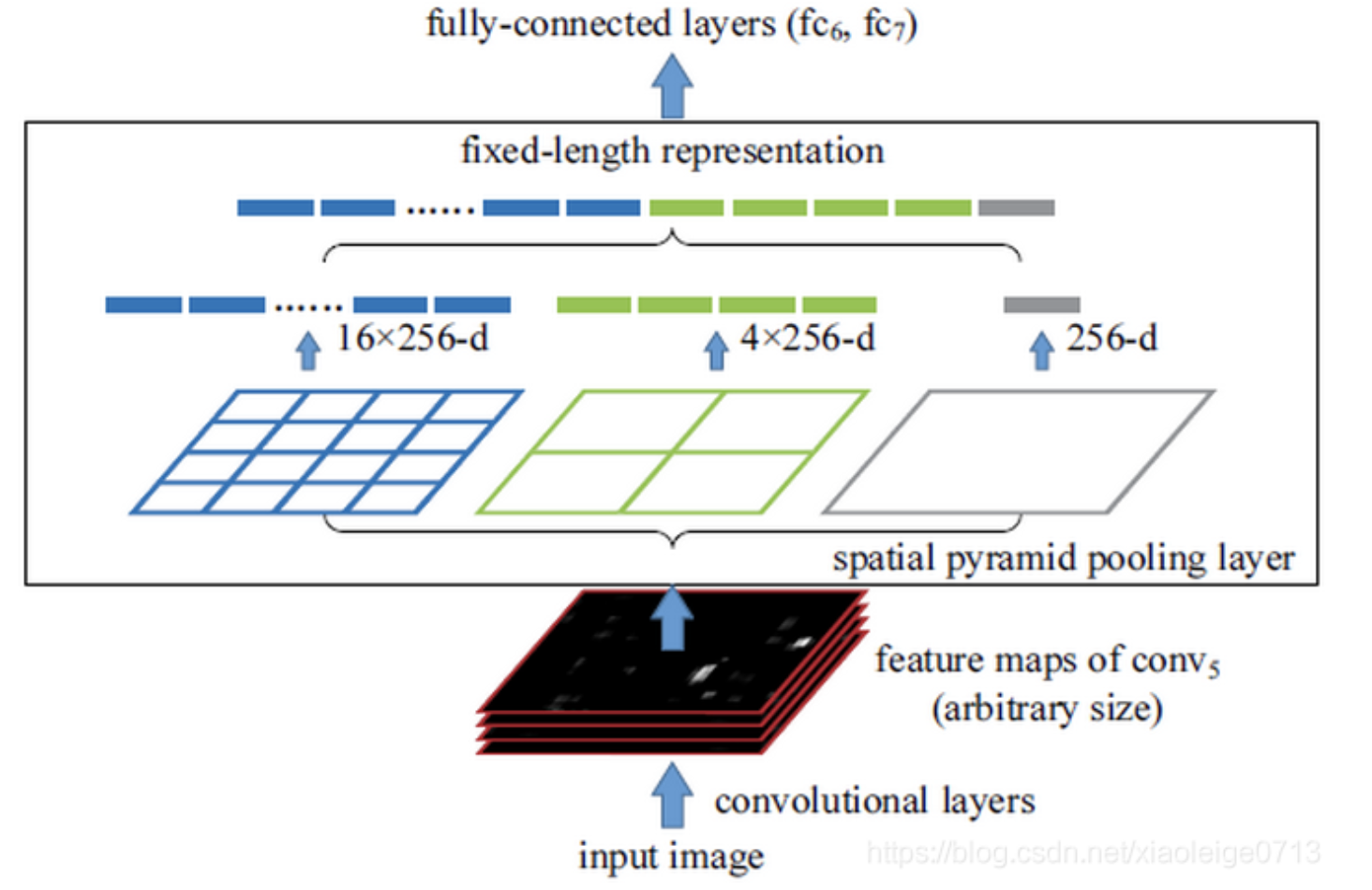
eg. output the feature map as 4x4x256, 2x2x256 and 1x1x256 in turn, and then put it into FC after splicing according to 256 channels.
SPP in YOLOv5
The SPP in YOLO just draws on the idea of SPP. As shown in the figure, YOLO adopts a unified step size, but convolution kernels of different sizes to realize SPP, and the unified step size means that the output feature map has the same size, but has different sensitivity to the region. Then, it is spliced according to the channel through concate and convoluted with 1x1 to realize feature fusion.
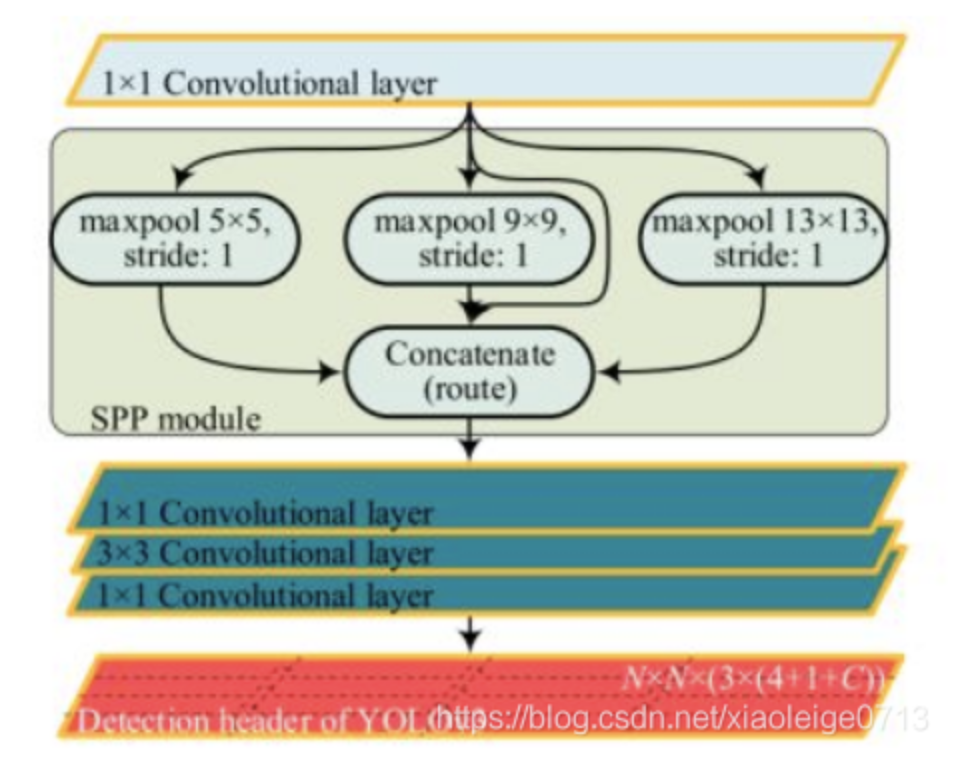
The input feature first passes through a Conv, and then the pooling of different kernel s, three pooling and input splicing are carried out respectively.
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)): ## ch_in, ch_out
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
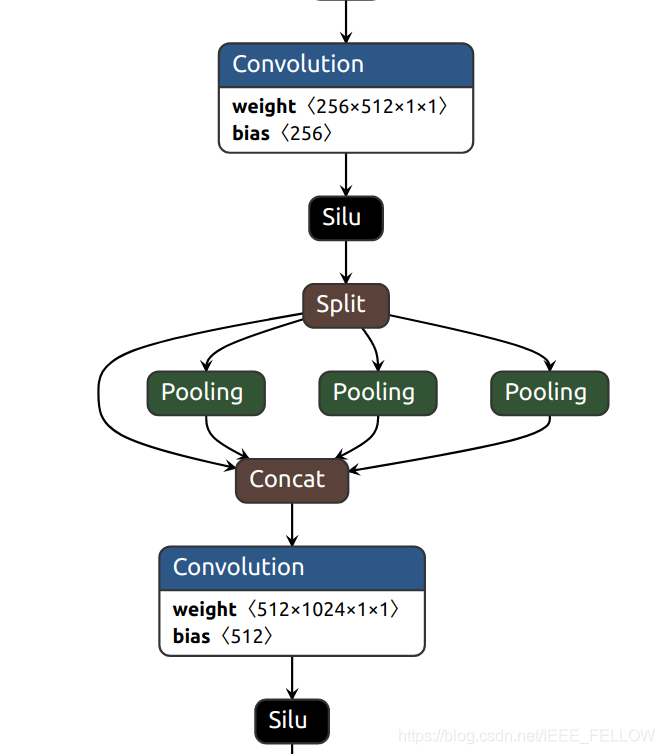
SPPF
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
ASPP
Atrus convolution, also known as divided convolutions, namely cavity convolution / porous convolution / expansion convolution / expansion convolution / porous convolution. See https://arxiv.org/pdf/1511.07122.pdf .
Blog reference https://blog.csdn.net/qq_41731861/article/details/120967519
The difference from the ordinary convolution operation lies in the hole convolution, that is, some values (rate-1) of zero are inserted into the convolution kernel according to a certain law, so that the receptive field increases without increasing the receptive field by reducing the image size. The superposition of small convolution kernel can linearly increase the receptive field, and this method increases the receptive field exponentially.
ASPP
DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. A technique for improving receptive field is proposed in this paper.
The cavity spatial convolution pooling (ASPP) samples the cavity convolution of a given input at different sampling rates in parallel, which is equivalent to capturing the context of the image at multiple scales.
In the experiment, I directly changed the convolution in SPP into the hole convolution in ASSP.
Feel useless = =.
Study again, study again.
To be considered
ASPP potential problems:
- The Gridding Effect kernel is not continuous
- Long-ranged information might be not relevant
It has an effect on the segmentation of some large objects, but it may have disadvantages but no advantages for small objects. How to deal with the relationship between objects of different sizes at the same time.
propose
HDC (Hybrid Dilated Convolution)
https://blog.csdn.net/xiaoleige0713/article/details/114261794
Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
https://github.com/ElegantAnkster/ASPP/blob/main/ASPP.py
https://github.com/ultralytics/yolov5
https://blog.csdn.net/IEEE_FELLOW/article/details/117536808
https://blog.csdn.net/qq_41731861/article/details/120967519