In the process of writing crawler, we often need to parse the list page of the website. For example, the following example:
<html> <head> <meta charset="utf-8"> <title>Test relative path</title> </head> <body> <div> <h1>List of books</h1> <ul> <li><a href="http://127.0.0.1:8000/book/1.html">First book</a></li> <li><a href="http://127.0.0.1:8000/book/2.html">Second book</a></li> <li><a href="http://127.0.0.1:8000/book/3.html">The third book</a></li> <li><a href="http://127.0.0.1:8000/book/4.html">The fourth book</a></li> <li><a href="http://127.0.0.1:8000/book/5.html">The fifth book</a></li> </ul> </div> </body> </html>
The operation effect is shown in the figure below:
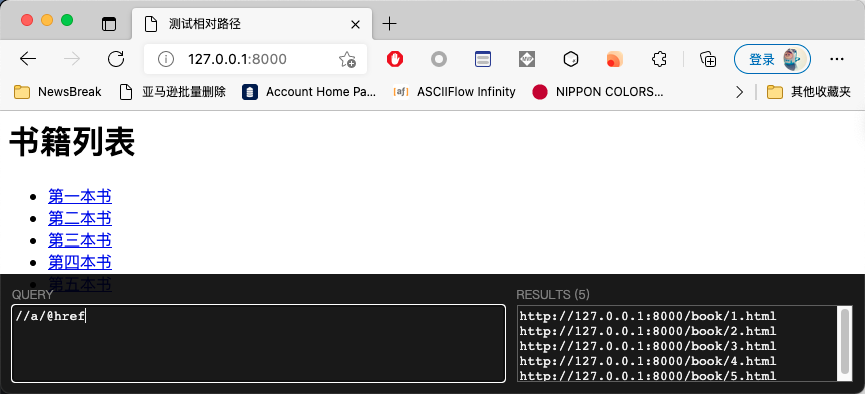
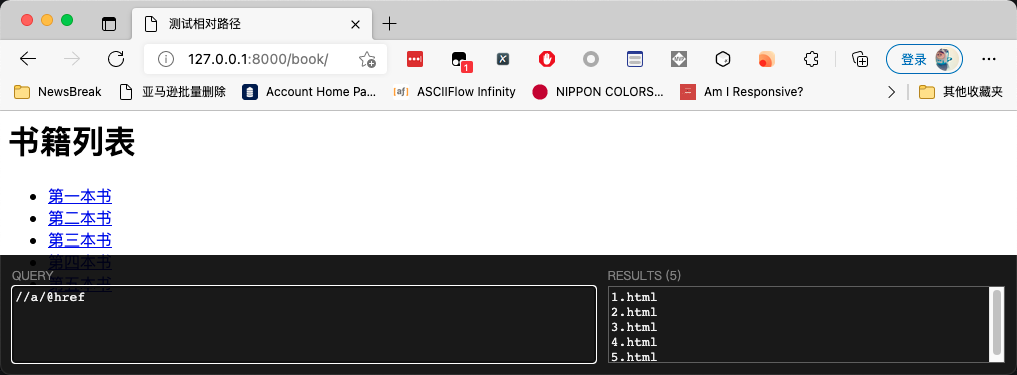
In this case, I want to get the URL of each item, which is very simple. Just write an XPath directly, as shown in the following figure:
If you look closely, you will find that the URL of each connection is http://127.0.0.1:8000 At the beginning. The address of the current list page is also http://127.0.0.1 : 8000. Therefore, for simplicity, relative paths can be used in the < a > tag:
<html> <head> <meta charset="utf-8"> <title>Test relative path</title> </head> <body> <div> <h1>List of books</h1> <ul> <li><a href="/book/1.html">First book</a></li> <li><a href="/book/2.html">Second book</a></li> <li><a href="/book/3.html">The third book</a></li> <li><a href="/book/4.html">The fourth book</a></li> <li><a href="/book/5.html">The fifth book</a></li> </ul> </div> </body> </html>
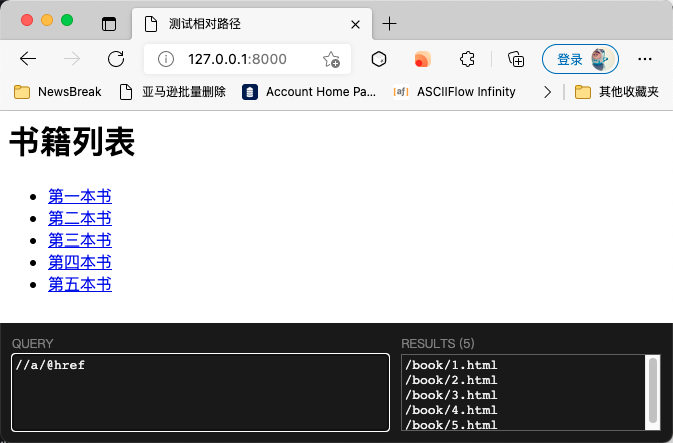
The running effect is shown in the following figure. Only half of the URL can be extracted with XPath:
However, the browser can correctly recognize such a relative address, and when you click, it can automatically jump to the correct address:
If the relative path starts with /, it will be in the relative path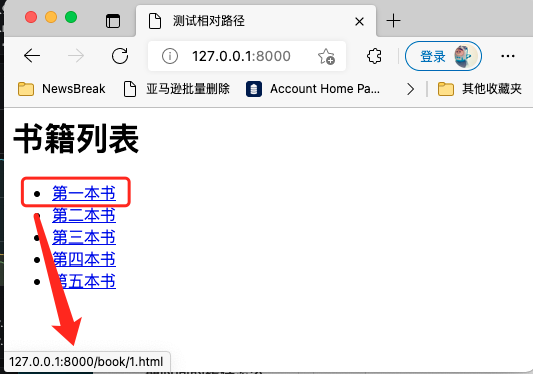
The main domain name of the website is spliced in front of the path.
But what if the address of the current list page overlaps with the relative path of the link? As shown in the figure below:
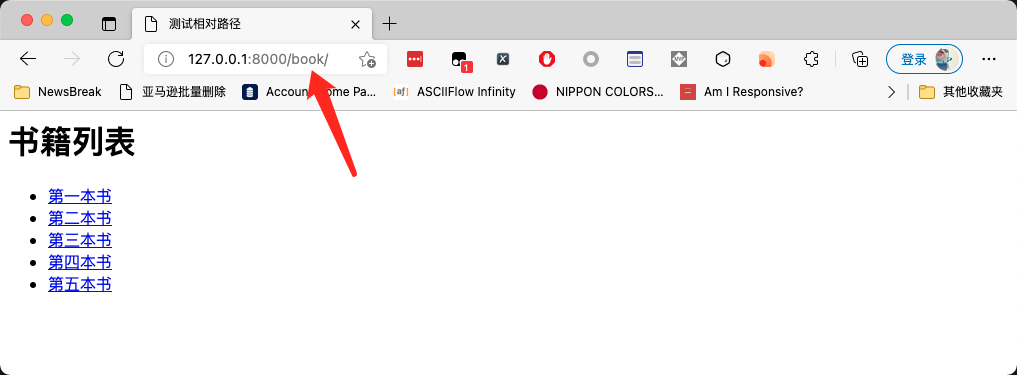
The address of the current page is http://127.0.0.1:8000/book . The relative address is / book / 1 html. In this case, it can be further simplified. Instead of adding a slash in front of the relative path, change the HTML to:
<html> <head> <meta charset="utf-8"> <title>Test relative path</title> </head> <body> <div> <h1>List of books</h1> <ul> <li><a href="1.html">First book</a></li> <li><a href="2.html">Second book</a></li> <li><a href="3.html">The third book</a></li> <li><a href="4.html">The fourth book</a></li> <li><a href="5.html">The fifth book</a></li> </ul> </div> </body> </html>
The operation effect is shown in the figure below:
In this case, the browser can still give correct recognition, as shown in the following figure:
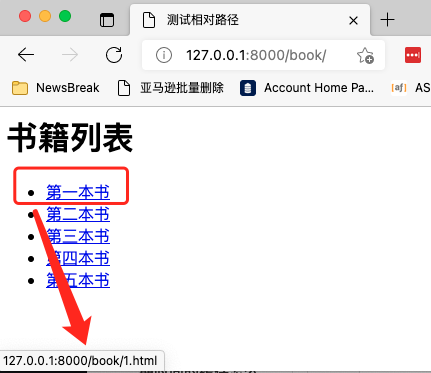
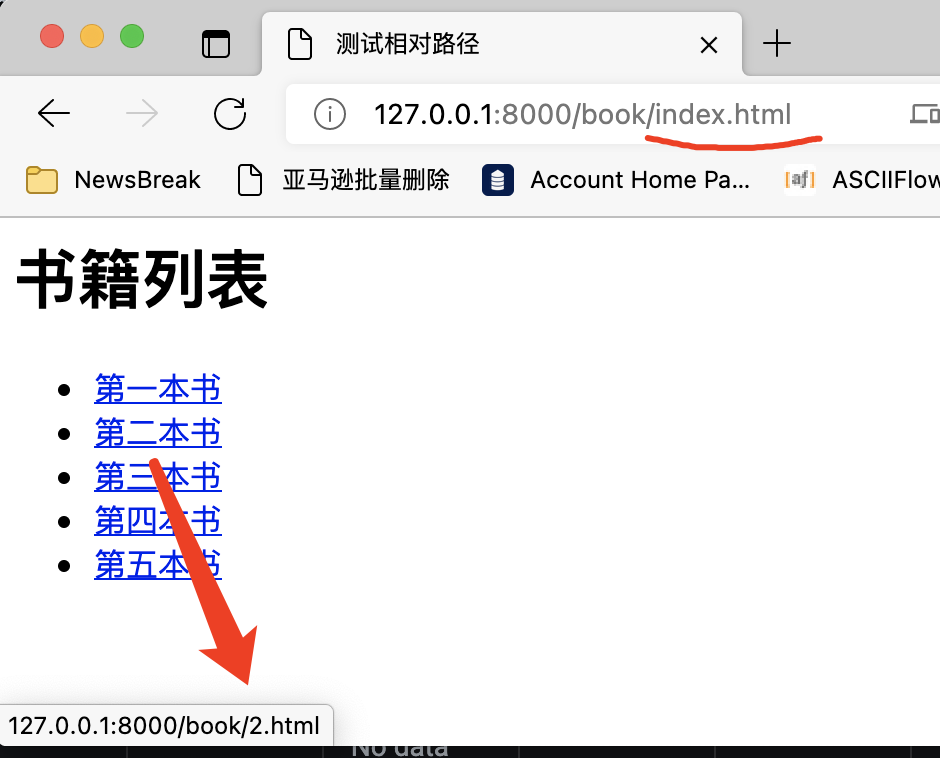
The browser knows that if the relative path does not start with /, it will splice the URL of the current page with the relative path. However, it should be noted that when splicing, the part to the left of the rightmost slash will be taken. The right part will be discarded. It is equivalent to splicing the file address, using the folder where the file is located to splice the new address. As shown in the figure below:
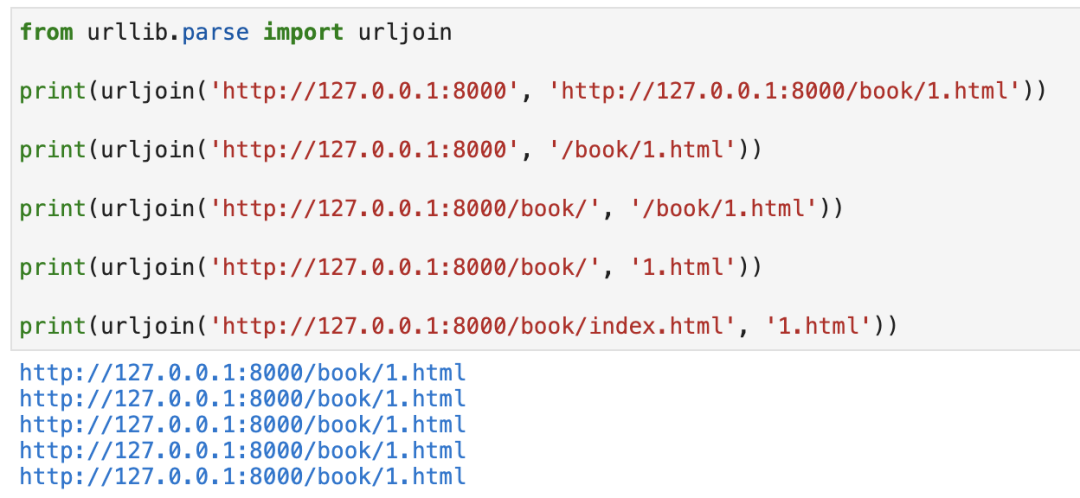
If you can't remember how to distinguish, you can use the urllib that comes with Python parse. Urljoin, as shown in the following figure:
Seeing here, you may think I wrote another article today. Is it worth writing an article about such a simple thing?
Let's look at the following example:
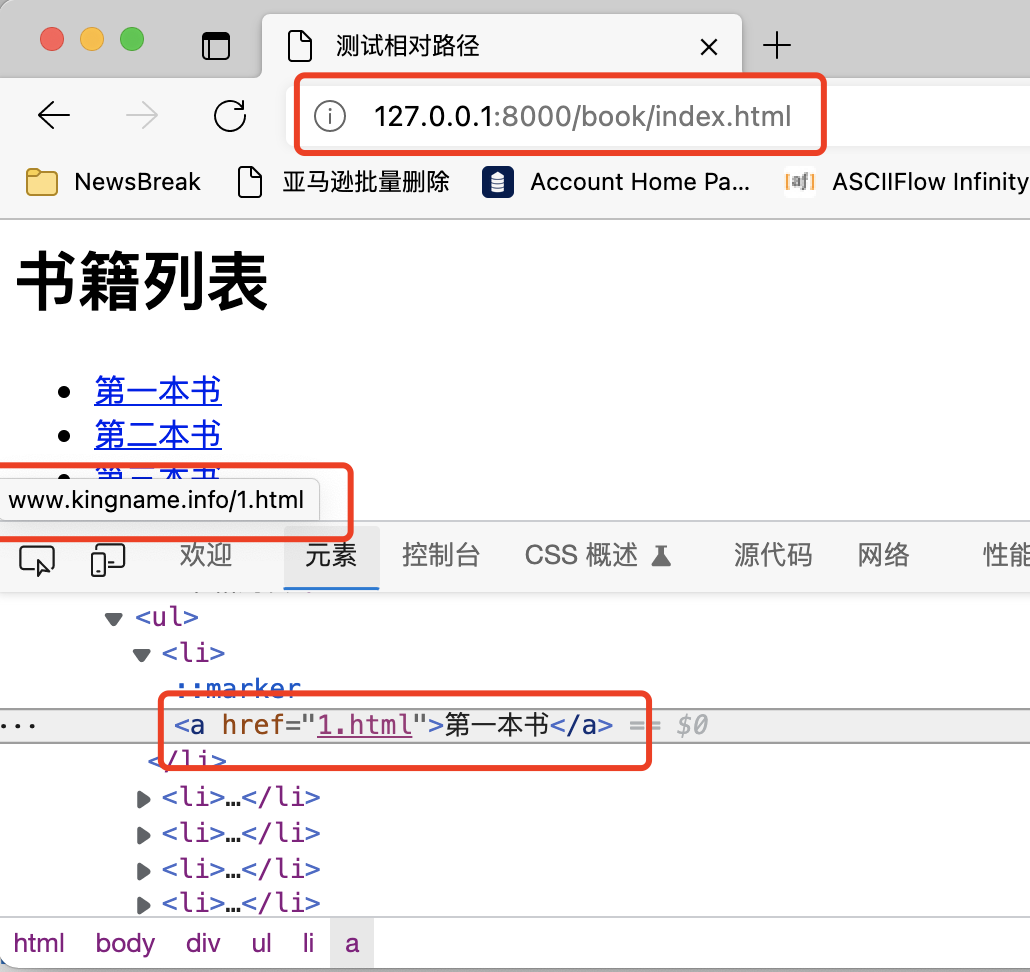
Domain name is http://127.0.0.1:8000/book/index.html , the relative domain name is 1 HTML, but why is the URL automatically recognized by the browser www.kingname.html info/1.html?
The key to this problem lies in the label in the source code:
<html> <head> <meta charset="utf-8"> <title>Relative test path</title> <base href="http://www.kingname.info"> </head> <body> <div> <h1>List of books</h1> <ul> <li><a href="1.html">First book</a></li> <li><a href="2.html">Second book</a></li> <li><a href="3.html">The third book</a></li> <li><a href="4.html">The fourth book</a></li> <li><a href="5.html">The fifth book</a></li> </ul> </div> </body> </html>
If there is a tag in the header of the HTML code, the value of its href attribute will be used to splice an absolute path with the relative path instead of the URL of the current page.
If you don't know this, your crawler may have problems splicing sub page URLs. The website can also use this mechanism to construct a honeypot. The URL spelled out according to the label is the real sub page address, and the URL spliced with the current page URL is the honeypot address. After the crawler accesses it, it will catch false data or be blocked immediately.
For a detailed description of the label, you can read: The Document Base URL element
reference
[1] The Document Base URL element: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/base
Official account: WeChat public No. code