PostgerSQL object identifier
OID
OID is an identifier used in PostgreSQL to identify database objects (database, table * *, view, * * stored procedure, etc.), which is represented by an unsigned integer of 4 bytes. It is the primary key of most system tables in PostgreSQL.
Type oid represents an object identifier. There are also alias types of multiple OIDs: regproc,regprocedure, regoper, regoperator,regclass, regtype, regrole,regnamespace, regconfig, and regdictionary.
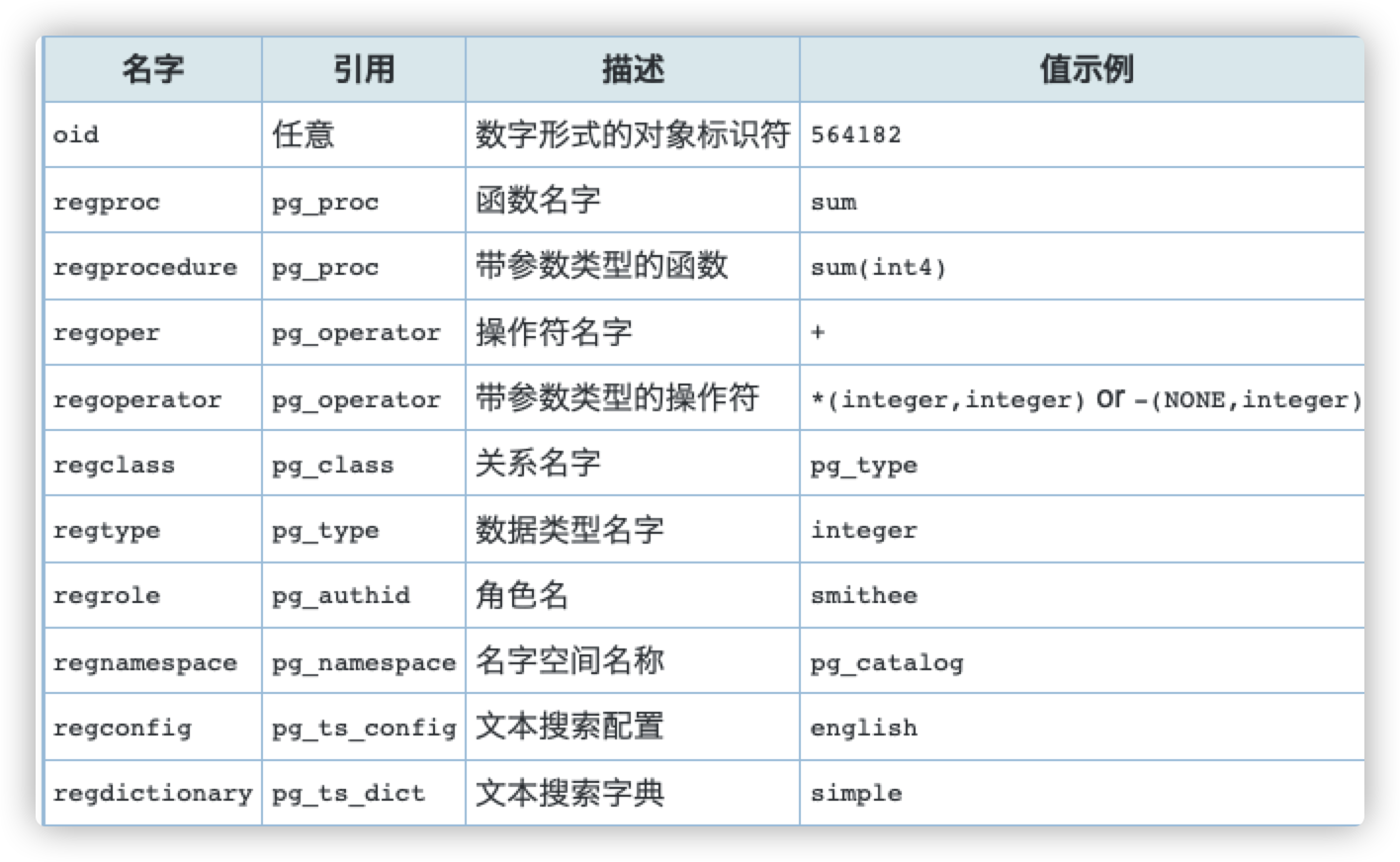
The alias type of oid has no operations other than specific input and output routines. These routines can accept and display the symbolic names of system objects instead of the original numeric values used by type oid. Alias types make it easy to find oid values for objects. For example, check the PG associated with a table course_ In the attribute line, you can write:
SELECT * FROM pg_attribute WHERE attrelid = 'course'::regclass;

OID usually exists as a hidden column in the system table. It is uniformly allocated within the scope of the entire PostgreSQL database cluster. Because there are only four bytes, it is not enough to provide database wide uniqueness in large databases, and even in some large tables.
In the old version, OID can also be used to identify tuples. For duplicate rows without a primary key, if OID is used as the unique ID, the specified row data can be deleted according to it. When we created the table before, default_with_oids is off by default. In the old version, you can specify to enable OID when executing the create table statement.
create table foo (
id integer,
content text
) with oids;
However, starting with Postgres 12, the use of OID as an optional system column on the table has been deleted. Will no longer be available:
- CREATE TABLE... WITH OIDS command
- default_with_oids (boolean) compatibility setting
The data type OID is retained in Postgres 12. You can explicitly create column OIDs of type.
XID
Transaction ID:
- It is composed of 32 bits, which may cause the problem of transaction ID rollback. Refer to file
- Sequential generation and sequential increment
- There is no data change, such as INSERT, UPDATE, DELETE and other operations. In the current session, the transaction ID will not change
The data types used in the database system are xmin and xmax.
- xmin stores the transaction ID that generated the tuple, which may be an insert or update statement
- xmax stores xids that delete or lock this tuple
A simple example is as follows:
select id, xmin, xmax from course;
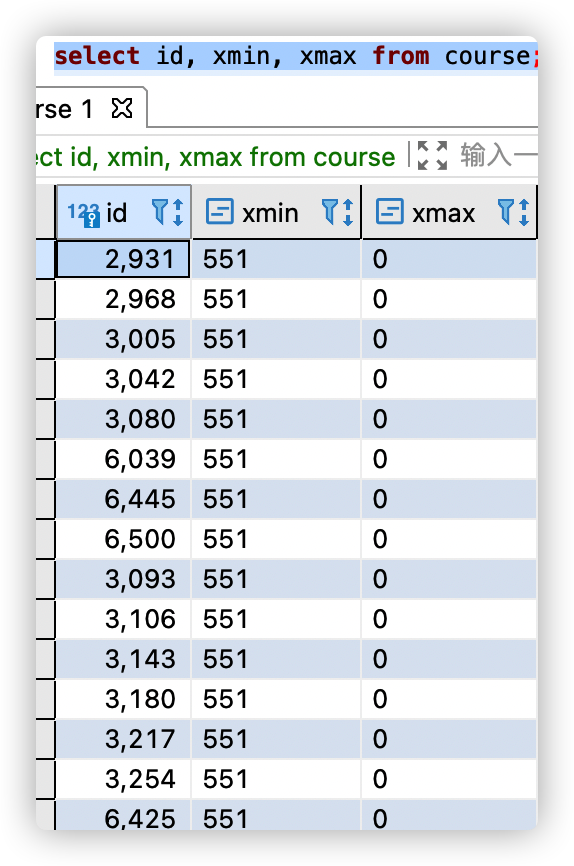
When the XID of PostgreSQL reaches 4 billion, it will cause overflow, so the new XID is 0. According to the MVCC mechanism of PostgreSQL, previous transactions can see the tuples created by the new transaction, while new transactions cannot see the tuples created by previous transactions, which violates the visibility of transactions. Specific reference file
CID
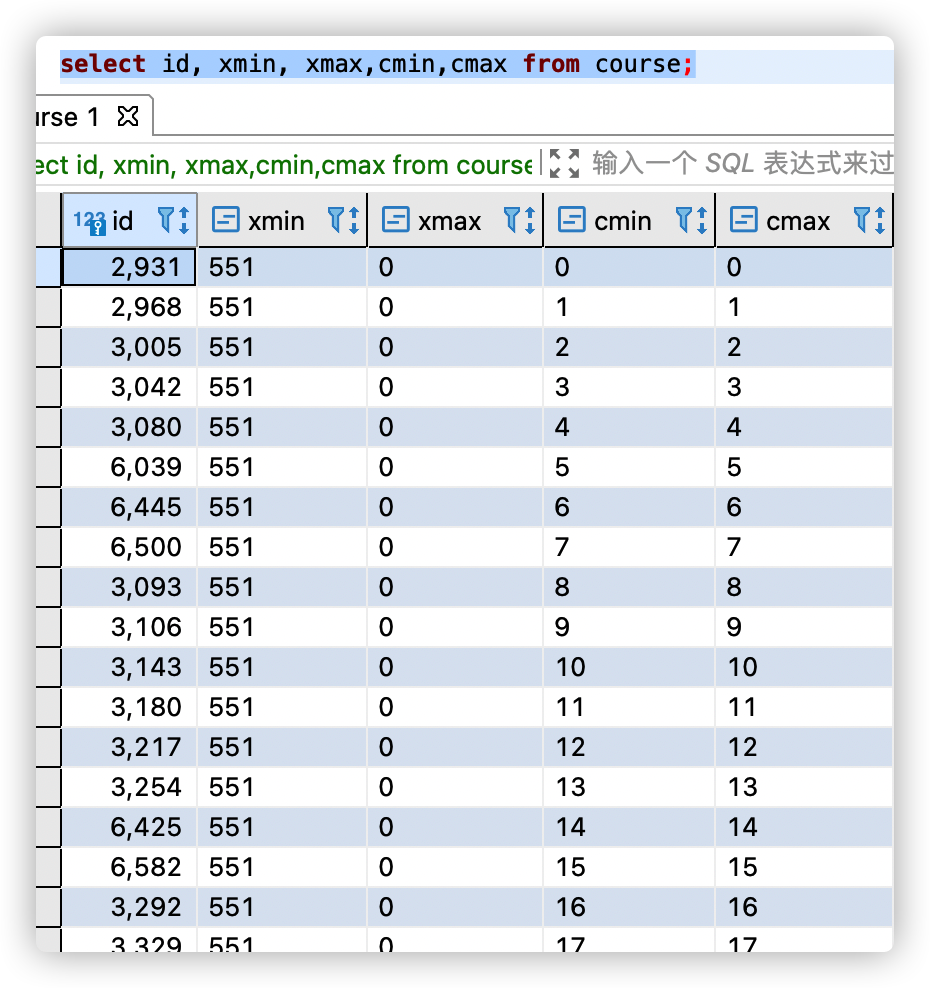
The CID name is the command identifier. Each table of PG contains some system fields. The data types used for CID are cmax and cmin.
- cmin: the command ID of the command to insert the tuple in the insert transaction (accumulated from 0)
- cmax: the command ID of the command to delete the tuple in the insert transaction (accumulated from 0)
cmin and cmax are used to determine whether line version changes caused by other commands in the same transaction are visible. If all commands in a transaction are executed in strict order, each command can always see all changes in the previous transaction without using the command ID.
A simple example is as follows:
select id, xmin, xmax,cmin,cmax from course;
TID
TID is called tuple identifier (row identifier). A tuple ID is a pair (block number, intra block tuple index), which identifies the physical location of a row in its table.
A simple example is as follows:
select ctid,id, xmin, xmax,cmin,cmax from course;

After understanding the above four identifiers, let's learn how data is stored in PostgreSQL.
PostgreSQL data store
As for data storage, we all know that data exists in a data table in the database, and each data record corresponds to a row in the data table, so we view the data storage of each hierarchy from top to bottom.
PGDATA directory structure
PGDATA is where PostgreSQL stores all data.
For the setting of PGDATA, you can execute the following commands first.
postgres=# show data_directory;
data_directory
-----------------------------
/Library/PostgreSQL/12/data
(1 row)
Next, let's take a look at the files in the PGDATA folder. First open the command line window, and then enter the above directory.
MacBook-Pro 12 % cd /Library/PostgreSQL/12/data cd: permission denied: /Library/PostgreSQL/12/data
If you encounter the above problems, execute the following command to try to simulate postgresql user login using sudo:
MacBook-Pro 12 % sudo -u postgres -i The default interactive shell is now zsh. To update your account to use zsh, please run `chsh -s /bin/zsh`. For more details, please visit https://support.apple.com/kb/HT208050.
Then execute the following command:
tree -FL 1 /Library/PostgreSQL/12/data /Library/PostgreSQL/12/data ├── PG_VERSION ├── base/ ├── current_logfiles ├── global/ ├── log/ ├── pg_commit_ts/ ├── pg_dynshmem/ ├── pg_hba.conf ├── pg_ident.conf ├── pg_logical/ ├── pg_multixact/ ├── pg_notify/ ├── pg_replslot/ ├── pg_serial/ ├── pg_snapshots/ ├── pg_stat/ ├── pg_stat_tmp/ ├── pg_subtrans/ ├── pg_tblspc/ ├── pg_twophase/ ├── pg_wal/ ├── pg_xact/ ├── postgresql.auto.conf ├── postgresql.conf ├── postmaster.opts └── postmaster.pid
Introduce several common folders:
- Database /: stores database data (except those specifying other tablespaces). The name of the subdirectory is the OID of the database in pg_database.
- postgresql.conf: PostgreSQL configuration file
database data storage
As mentioned above, each database data is stored in the database / directory, and the file name is called dboid.
Since OID is a hidden column of the system table, when viewing the OID of database objects in the system table, it must be explicitly specified in the SELECT statement. We enter the postgres command line window and execute the following commands:
postgres=# select oid,datname from pg_database;
oid | datname
-------+-----------
13635 | postgres
1 | template1
13634 | template0
16395 | mydb
16396 | dvdrental
16399 | testdb
(6 rows)
select oid,relname from pg_class order by oid;
We can see oid in the base directory under the PGDATA folder
MacBook-Pro:base postgres$ ls /Library/PostgreSQL/12/data/base 1 13634 13635 16395 16396 16399
It can be seen from the above that the data related to postgres database is stored in PGDATA/base/13635 directory.
table data storage
Above, we locate the storage location of the database, and then we locate the location of the data table.
The data of each table (mostly) is placed in the file $PGDATA/base/{dboid}/{relfilenode}. Generally, relfilenode is consistent with tboid, but it will also change in some cases, such as TRUNCATE, REINDEX, CLUSTER and some forms of ALTER TABLE.
CREATE TABLE public.cities (
city varchar(80) NOT NULL,
"location" point NULL,
CONSTRAINT cities_pkey PRIMARY KEY (city)
);
postgres=# select oid,relfilenode from pg_class where relname = 'cities';
oid | relfilenode
-------+-------------
16475 | 16475
(1 row)
insert into cities values('Beijing',null);
insert into cities values('Shanghai',null);
truncate cities ;
postgres=# select oid,relfilenode from pg_class where relname = 'cities';
oid | relfilenode
-------+-------------
16475 | 16480
(1 row)
SELECT * FROM pg_attribute WHERE attrelid = 'course'::regclass;
In addition to the above SQL statements, we can also use the system function pg_relation_filepath to view the file storage location of the specified table.
postgres=# select pg_relation_filepath('cities');
pg_relation_filepath
----------------------
base/13635/16480
(1 row)
When you view the PGDATA/base/13635 / directory, you will find the 16480 folder. In addition, you will also find some files named relfilenode_fsm,relfilenode_vm,relfilenode_init, there are usually three kinds of files about 16480: 16480 and 16480_fsm,16480_vm is the data or index file of the corresponding table of the database, its corresponding free space mapping file and its corresponding visibility mapping file.
If the data file is too large, how will it be named?
After the table or index exceeds 1GB, it is divided into 1GB segments. The file name of the first segment is the same as the file node, and the subsequent segments are named filenode 1,filenode.2 wait. This arrangement avoids problems on some platforms with file size restrictions.
postgres=# create table bigdata(id int,name varchar(64));
postgres=# insert into bigdata select generate_series(1,20000000) as key, md5(random()::text);
postgres=# select pg_relation_filepath('bigdata');
pg_relation_filepath
----------------------
base/13635/16486
(1 row)
#Switch command line interface
MacBook-Pro:base postgres$ ls 13635 |grep 16486
16486
16486.1
16486_fsm
Tuple data storage
As mentioned above, when storing a table, each data file (heap file and index file) can store 1G of capacity, and each file is composed of several fixed pages. The default size of the page is 8192 bytes (8KB). These pages in a single table file are numbered sequentially from 0. These numbers are also called "block numbers". If the first page space has been filled with data, postgres will immediately add a new blank page at the end of the file (i.e. after the filled Page) to continue storing data until the current table file size reaches 1GB. If the file reaches 1GB, recreate a new table file, and then repeat the above process.
The interior of each page is composed of a page header, several line pointers and several header tuples. Because the default size of each file is 1GB and the page size is 8kb, each file has about 131072 pages.
First, let's look at the page structure.
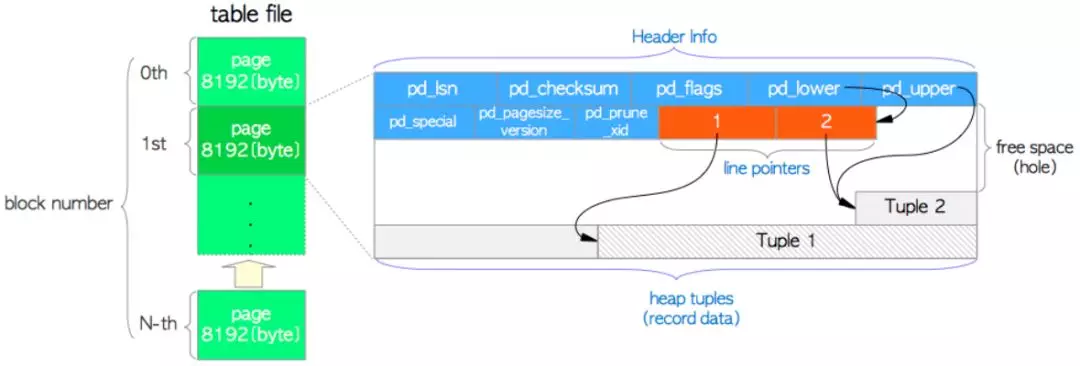
Of which:
-
page header: 24 bytes, which stores the basic information of the page, including pd_lsn,pd_checksum,pd_special…
pd_lsn: Stores the most recent changes to the page xlog. pd_checksum: Store page checksums. pd_lower,pd_upper: pd_lower Pointer to line( line pointer)The tail of the, pd_upper Point to the last tuple. pd_special: Used in index pages, it points to the beginning of a special space. pd_flags: Used to set the bit flag. pd_pagesize_version: Page size and page version number. pd_prune_xid: Removable old XID,Zero if none.
-
line pointe: line pointer, 4 bytes, in the form of (offset, length) binary, pointing to related tuple s
-
heap tuple: used to store row data. Note that tuples are stacked forward from the end of the page, and the free space between tuples and row pointers is the data page.
-
Blank space: if the space is not applied for, the new line point is applied from its head end, and the new tuple is applied from its tail end
Therefore, when looking for row data, we need to know which page and which item (page_index, item_index) of the page. It is usually called CTID(ItemPointer). We can view the CTID of each column through the following statement:
select ctid,* from course;
The query results are as follows:

For a detailed explanation of tuple structure and data changes, you can refer to this paper.
extend
schema
In addition to the default public schema, PostgreSQL also has two important system schemas: information_schema and pg_catalog.
By viewing pg_catalog.pg_namespace to view all the schema s in the current database.
postgres=# select * from pg_catalog.pg_namespace ;
oid | nspname | nspowner | nspacl
-------+--------------------+----------+-------------------------------------
99 | pg_toast | 10 |
12314 | pg_temp_1 | 10 |
12315 | pg_toast_temp_1 | 10 |
11 | pg_catalog | 10 | {postgres=UC/postgres,=U/postgres}
2200 | public | 10 | {postgres=UC/postgres,=UC/postgres}
13335 | information_schema | 10 | {postgres=UC/postgres,=U/postgres}
(6 rows)
The tables, views and indexes we create are all in public by default.
information_schema is provided to facilitate users to view table / view / function information. It is mostly a view.
select * from information_schema."tables";
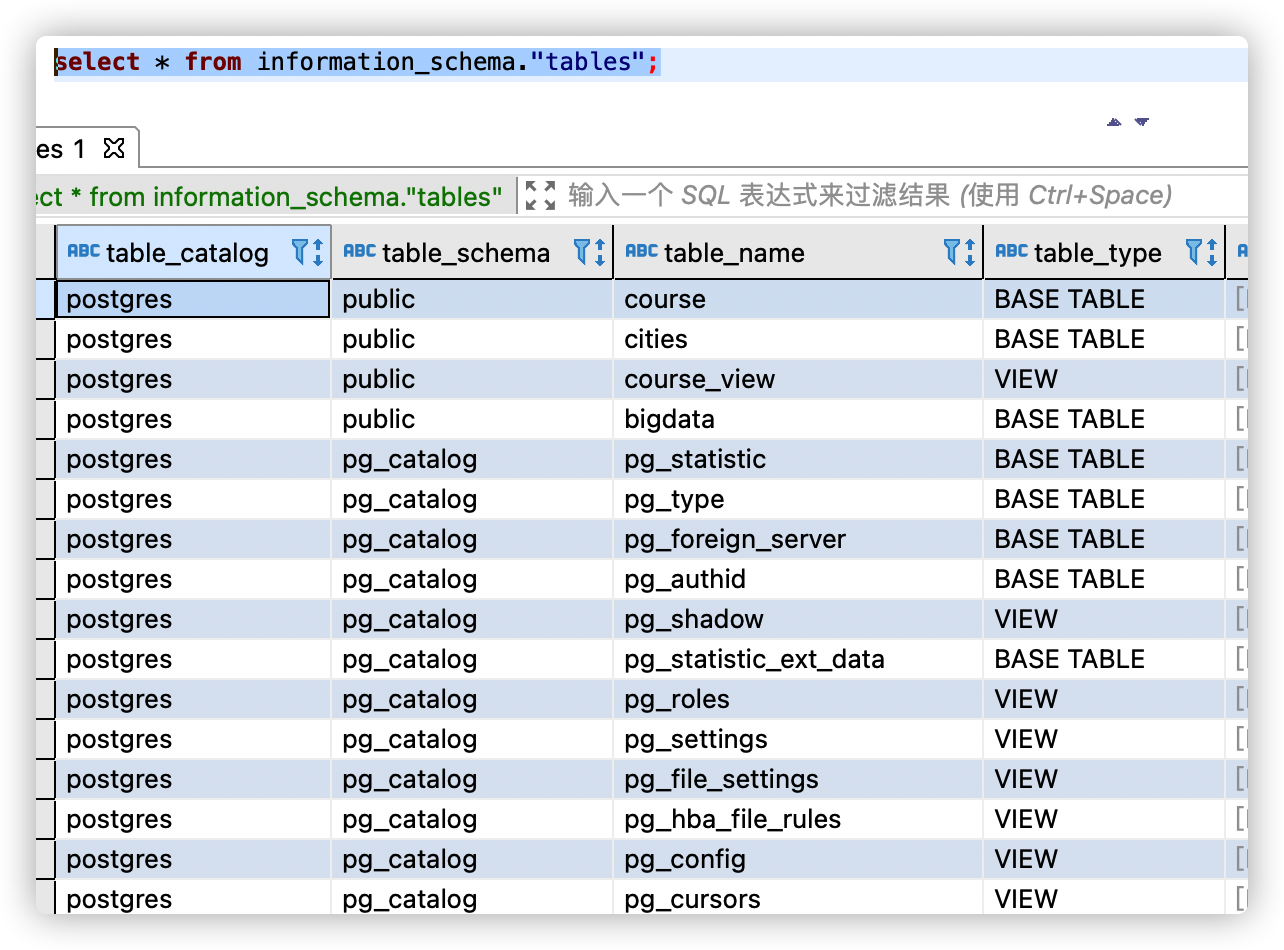
pg_catalog contains system tables and all built-in data types, functions, and operators. pg_ There are many system tables under catalog, such as pg_class,pg_attribute,pg_authid, etc. for a detailed description of these tables, please refer to this paper.
reference
SQL, Postgres OID, what are they and why are they useful?
Detailed explanation of PostgreSQL system fields cmin and cmax
PgSQL · characteristic analysis · MVCC mechanism analysis
PgSQL · feature analysis · transaction ID rollback problem
Dry goods | PostgreSQL data table file underlying structure layout analysis