Article catalogue
2, MySQL index
1. Concept of index
- We have studied collections before. One of the characteristics of ArrayList collection is index. So what are the benefits of having an index?
- Yes, query data quickly! We can quickly find the desired data through the index. The indexing function in our MySQL database is similar!
- Index in MySQL database: it is a data structure that helps MySQL obtain data efficiently! Therefore, the essence of index is data structure.
- In addition to table data, the database system also maintains data structures that meet specific search algorithms. These data structures point to data in some way, so that advanced search algorithms can be realized on these data structures. This data structure is index.
- A data table for storing data. An index configuration file is used to save indexes. Each index points to a certain data (table demonstration)
- For example, the search principle without index and with index
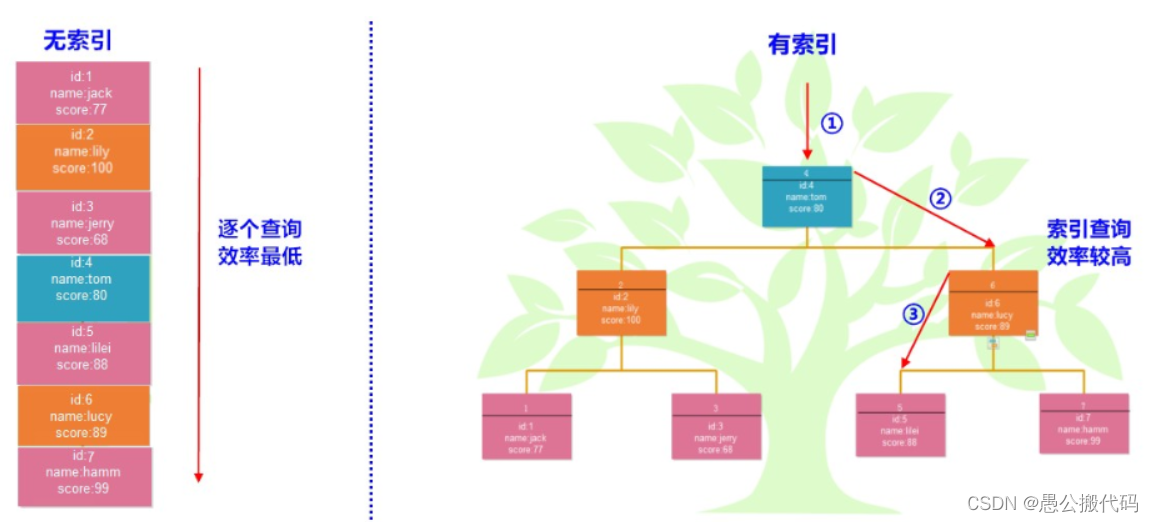
2. Classification of index
- Functional classification
- Ordinary index: the most basic index, which has no restrictions.
- Unique index: the value of index column must be unique, but null value is allowed. If it is a composite index, the combination of column values must be unique.
- Primary key index: a special unique index. No null value is allowed. Generally, the primary key index is created at the same time when the table is being created.
- Composite index: as the name suggests, it is to combine single column indexes.
- Foreign key index: only InnoDB engine supports foreign key index to ensure the consistency and integrity of data and realize cascade operation.
- Full text index: a way to quickly match all documents. The InnoDB engine supports full-text indexing only after version 5.6. MEMORY engine does not support.
- Structural classification
- B+Tree index: one of the most frequently used index data structures in MySQL is the default index type of InnoDB and MyISAM storage engines.
- Hash index: the index type supported by the Memory storage engine in MySQL by default.
3. Index operation
- Data preparation
-- establish db12 database CREATE DATABASE db12; -- use db12 database USE db12; -- establish student surface CREATE TABLE student( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10), age INT, score INT ); -- Add data INSERT INTO student VALUES (NULL,'Zhang San',23,98),(NULL,'Li Si',24,95), (NULL,'Wang Wu',25,96),(NULL,'Zhao Liu',26,94),(NULL,'Zhou Qi',27,99);
- Create index
- Note: if a column in a table is a primary key, the primary key index will be created for it by default! (primary key columns do not need to be indexed separately)
-- Standard grammar CREATE [UNIQUE|FULLTEXT] INDEX Index name [USING Index type] -- Default is B+TREE ON Table name(Listing...); -- by student Create a common index for the name column in the table CREATE INDEX idx_name ON student(NAME); -- by student Create a unique index for the age column in the table CREATE UNIQUE INDEX idx_age ON student(age);
- View index
-- Standard grammar SHOW INDEX FROM Table name; -- see student Index in table SHOW INDEX FROM student;
- alter statement to add an index
-- General index ALTER TABLE Table name ADD INDEX Index name(Listing); -- Composite index ALTER TABLE Table name ADD INDEX Index name(Column name 1,Column name 2,...); -- primary key ALTER TABLE Table name ADD PRIMARY KEY(Primary key column name); -- Foreign key index(Adding a foreign key constraint is the foreign key index) ALTER TABLE Table name ADD CONSTRAINT Foreign key name FOREIGN KEY (Foreign key column name of this table) REFERENCES Main table name(Primary key column name); -- unique index ALTER TABLE Table name ADD UNIQUE Index name(Listing); -- Full text index(mysql Only text types are supported) ALTER TABLE Table name ADD FULLTEXT Index name(Listing); -- by student In the table name Add full-text index to column ALTER TABLE student ADD FULLTEXT idx_fulltext_name(name); -- see student Index in table SHOW INDEX FROM student;
- Delete index
-- Standard grammar DROP INDEX Index name ON Table name; -- delete student In table idx_score Indexes DROP INDEX idx_score ON student; -- see student Index in table SHOW INDEX FROM student;
4. Index efficiency test
-- establish product Commodity list CREATE TABLE product( id INT PRIMARY KEY AUTO_INCREMENT, -- commodity id NAME VARCHAR(10), -- Trade name price INT -- commodity price ); -- Define a storage function, generate a random string with a length of 10 and return it DELIMITER $ CREATE FUNCTION rand_string() RETURNS VARCHAR(255) BEGIN DECLARE big_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ'; DECLARE small_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 1; WHILE i <= 10 DO SET small_str =CONCAT(small_str,SUBSTRING(big_str,FLOOR(1+RAND()*52),1)); SET i=i+1; END WHILE; RETURN small_str; END$ DELIMITER ; -- Define stored procedures and add 1 million pieces of data to product In the table DELIMITER $ CREATE PROCEDURE pro_test() BEGIN DECLARE num INT DEFAULT 1; WHILE num <= 1000000 DO INSERT INTO product VALUES (NULL,rand_string(),num); SET num = num + 1; END WHILE; END$ DELIMITER ; -- Call stored procedure CALL pro_test(); -- Total number of records queried SELECT COUNT(*) FROM product; -- query product Index of table SHOW INDEX FROM product; -- query name by OkIKDLVwtG Data (0.049) SELECT * FROM product WHERE NAME='OkIKDLVwtG'; -- adopt id Column query OkIKDLVwtG Data (1 millisecond) SELECT * FROM product WHERE id=999998; -- by name Add index to column ALTER TABLE product ADD INDEX idx_name(NAME); -- query name by OkIKDLVwtG Data (0.001) SELECT * FROM product WHERE NAME='OkIKDLVwtG'; /* Range query */ -- The inquiry price is 800~1000 All data between (0.052) SELECT * FROM product WHERE price BETWEEN 800 AND 1000; /* Sort query */ -- The inquiry price is 800~1000 All data between,Descending order (0.083) SELECT * FROM product WHERE price BETWEEN 800 AND 1000 ORDER BY price DESC; -- by price Add index to column ALTER TABLE product ADD INDEX idx_price(price); -- The inquiry price is 800~1000 All data between (0.011) SELECT * FROM product WHERE price BETWEEN 800 AND 1000; -- The inquiry price is 800~1000 All data between,Descending order (0.001) SELECT * FROM product WHERE price BETWEEN 800 AND 1000 ORDER BY price DESC;
5. Implementation principle of index
- The index is implemented in the MySQL storage engine, so the index of each storage engine is not necessarily the same, and not all engines support all index types. Here we mainly introduce the B+Tree index implemented by InnoDB engine.
- B+Tree is a tree data structure and a variant of B-Tree. The file system, which is usually used in database and operating system, is characterized by maintaining the stability and order of data. Let's take a step-by-step look.
5.1 disk storage
- When the system reads data from disk to memory, it takes disk block as the basic unit
- The data in the same disk block will be read out at one time, rather than what you need.
- InnoDB storage engine has the concept of Page, which is the smallest unit of disk management. The default size of each Page in InnoDB storage engine is 16KB.
- The InnoDB engine connects several addresses to disk blocks to achieve a page size of 16KB. When querying data, if each data in a page can help locate the location of data records, it will reduce the number of disk I/O and improve the query efficiency.
5.2BTree
- The data of BTree structure allows the system to efficiently find the disk block where the data is located. To describe BTree, first define a record as a binary [key, data], key is the key value of the record, corresponding to the primary key value in the table, and data is the data in a row of records except the primary key. For different records, the key values are different from each other. Each node in the BTree can contain a large amount of keyword information and branches according to the actual situation, as shown in the following figure, which is a third-order BTree:
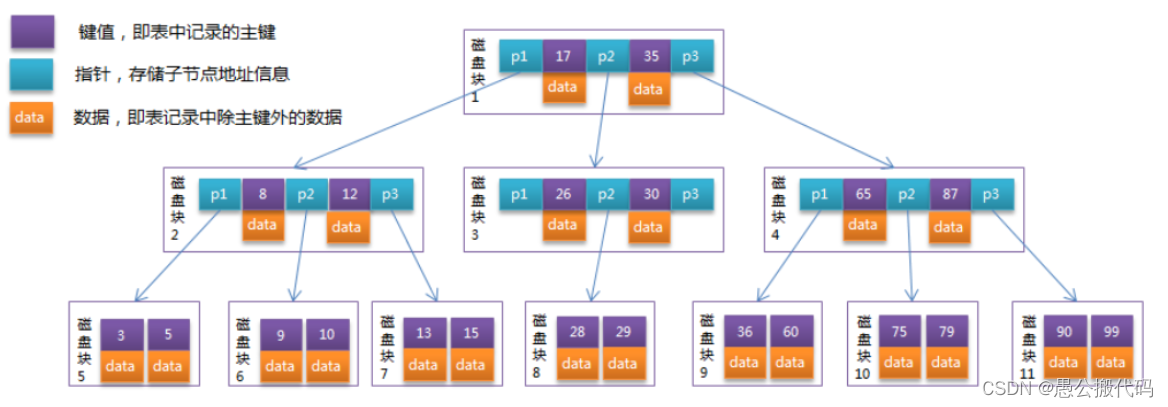
- According to the structure in the figure, each node occupies the disk space of a disk block. There are two ascending keywords and three pointers to the root node of the sub tree on a node. The pointer stores the address of the disk block where the sub node is located. The three range fields divided by the two keywords correspond to the range fields of the data of the subtree pointed to by the three pointers. Take the root node as an example. The keywords are 17 and 35. The data range of the subtree pointed to by P1 pointer is less than 17, the data range of the subtree pointed to by P2 pointer is 17 ~ 35, and the data range of the subtree pointed to by P3 pointer is greater than 35.
Search order:
Simulate the process of finding 15 : 1.The root node finds disk block 1 and reads it into memory. [disk I/O First operation] Comparison keyword 15 in interval(<17),A pointer to disk block 1 was found P1. 2.P1 The pointer finds disk block 2 and reads it into memory. [disk I/O [2nd operation] Comparison keyword 15 in interval(>12),Pointer to disk block 2 found P3. 3.P3 The pointer finds disk block 7 and reads it into memory. [disk I/O [3rd operation] Keyword 15 was found in disk block 7. -- After analyzing the above process, it is found that the disk is required for 3 times I/O Operation, and 3 memory lookup operations. -- Because the keywords in memory are an ordered table structure, dichotomy can be used to improve the efficiency. And 3 disk I/O Operation affects the whole BTree Find the determinants of efficiency. BTree Use fewer nodes to make each disk I/O The data fetched to the memory has played a role, thus improving the query efficiency.
5.3B+Tree
- B+Tree is an optimization based on BTree, which makes it more suitable for implementing external storage index structure. InnoDB storage engine uses B+Tree to implement its index structure.
- From the BTree structure diagram in the previous section, we can see that each node contains not only the key value of the data, but also the data value. The storage space of each page is limited. If the data data is large, the number of keys that can be stored by each node (i.e. one page) will be very small. When the amount of data stored is large, the depth of B-Tree will also be large, increasing the disk I/O times during query, and further affecting the query efficiency. In B+Tree, all data record nodes are stored on leaf nodes of the same layer according to the order of key values, instead of only storing key value information on leaf nodes, which can greatly increase the number of key values stored in each node and reduce the height of B+Tree.
- Difference between B+Tree and BTree:
- Non leaf nodes only store key value information.
- There is a connection pointer between all leaf nodes.
- Data records are stored in leaf nodes.
- Optimize the BTree in the previous section. Since the non leaf node of B+Tree only stores key value information, assuming that each disk block can store 4 key values and pointer information, its structure after becoming B+Tree is shown in the following figure:
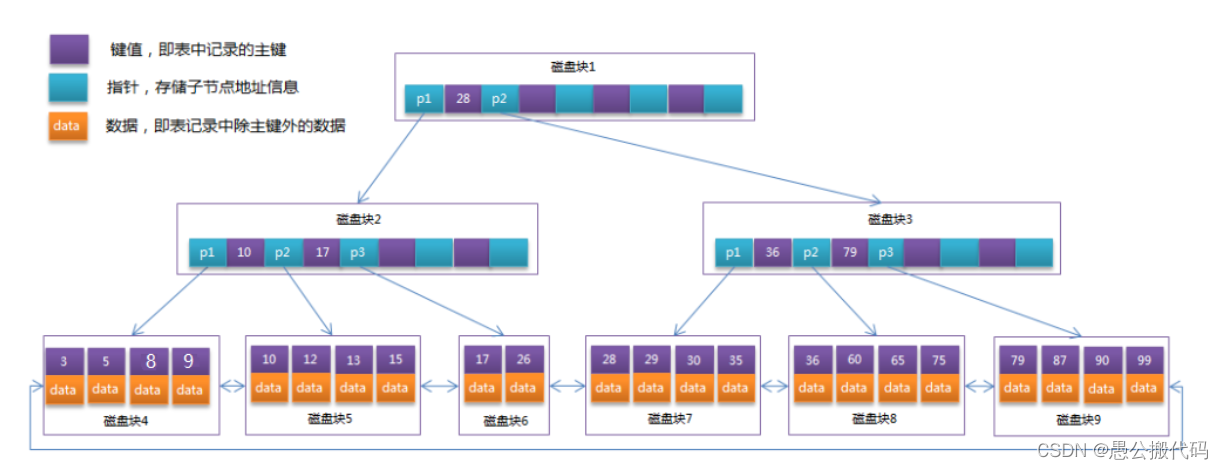
Usually, there are two header pointers on B+Tree, one pointing to the root node and the other pointing to the leaf node with the smallest keyword, and there is a chain structure between all leaf nodes (i.e. data nodes). Therefore, two search operations can be performed on B+Tree:
- [with range] range search and paging search for primary keys
- [sequential] start from the root node and perform random search
In practice, each node may not be full, so in the database, the height of B+Tree is generally 24 floors. MySQL's InnoDB storage engine is designed to resident the root node in memory, that is, only 13 disk I/O operations are required to find the row record of a key value.
6. Summary: design principles of index
The design of the index can follow some existing principles. Please try to comply with these principles when creating the index, so as to improve the efficiency of the index and use the index more efficiently.
- Guidelines for creating indexes
- Index tables with high query frequency and large amount of data.
- Using a unique index, the higher the discrimination, the higher the efficiency of using the index.
- For the selection of index fields, the best candidate columns should be extracted from the conditions of the where clause. If there are many combinations in the where clause, the combination of the most commonly used columns with the best filtering effect should be selected.
- Using a short index also uses a hard disk to store the index after it is created. Therefore, improving the I/O efficiency of index access can also improve the overall access efficiency. If the total length of the fields constituting the index is relatively short, more index values can be stored in the storage block of a given size, which can effectively improve the I/O efficiency of MySQL accessing the index.
- Index can effectively improve the efficiency of query data, but the number of indexes is not the more the better. The more indexes, the higher the cost of maintaining the index. For tables with frequent DML operations such as insert, update and delete, too many indexes will introduce a high maintenance cost, reduce the efficiency of DML operations and increase the time consumption of corresponding operations. In addition, if there are too many indexes, MySQL will also suffer from selection difficulties. Although an available index will still be found in the end, it undoubtedly increases the cost of selection.
- Characteristics of joint index
When mysql establishes a federated index, it will follow the principle of leftmost prefix matching, that is, leftmost first. When retrieving data, it will match from the leftmost side of the federated index, Create a joint index for the columns name, address, and phone
ALTER TABLE user ADD INDEX index_three(name,address,phone);
Union index_three actually establishes three indexes (name), (name,address), (name,address,phone). Therefore, the following three SQL statements can hit the index.
SELECT * FROM user WHERE address = 'Beijing' AND phone = '12345' AND name = 'Zhang San'; SELECT * FROM user WHERE name = 'Zhang San' AND address = 'Beijing'; SELECT * FROM user WHERE name = 'Zhang San';
The above three query statements will be executed according to the leftmost prefix matching principle, and the indexes will be used respectively during retrieval
(name,address,phone) (name,address) (name)
Perform data matching.
The fields of the index can be in any order, such as:
-- The optimizer will help us adjust the order, as shown below SQL Statements can hit the index SELECT * FROM user WHERE address = 'Beijing' AND phone = '12345' AND name = 'Zhang San';
The Mysql optimizer will help us adjust the order in the where condition to match the index we build.
The leftmost column in the union index is not included in the conditional query, so according to the above principles, the following SQL statements will not hit the index.
-- The leftmost column in the union index is not included in the conditional query SQL Statement will not hit the index SELECT * FROM user WHERE address = 'Beijing' AND phone = '12345';