Chapter 2 basic Python syntax
Writing rules for Python programs
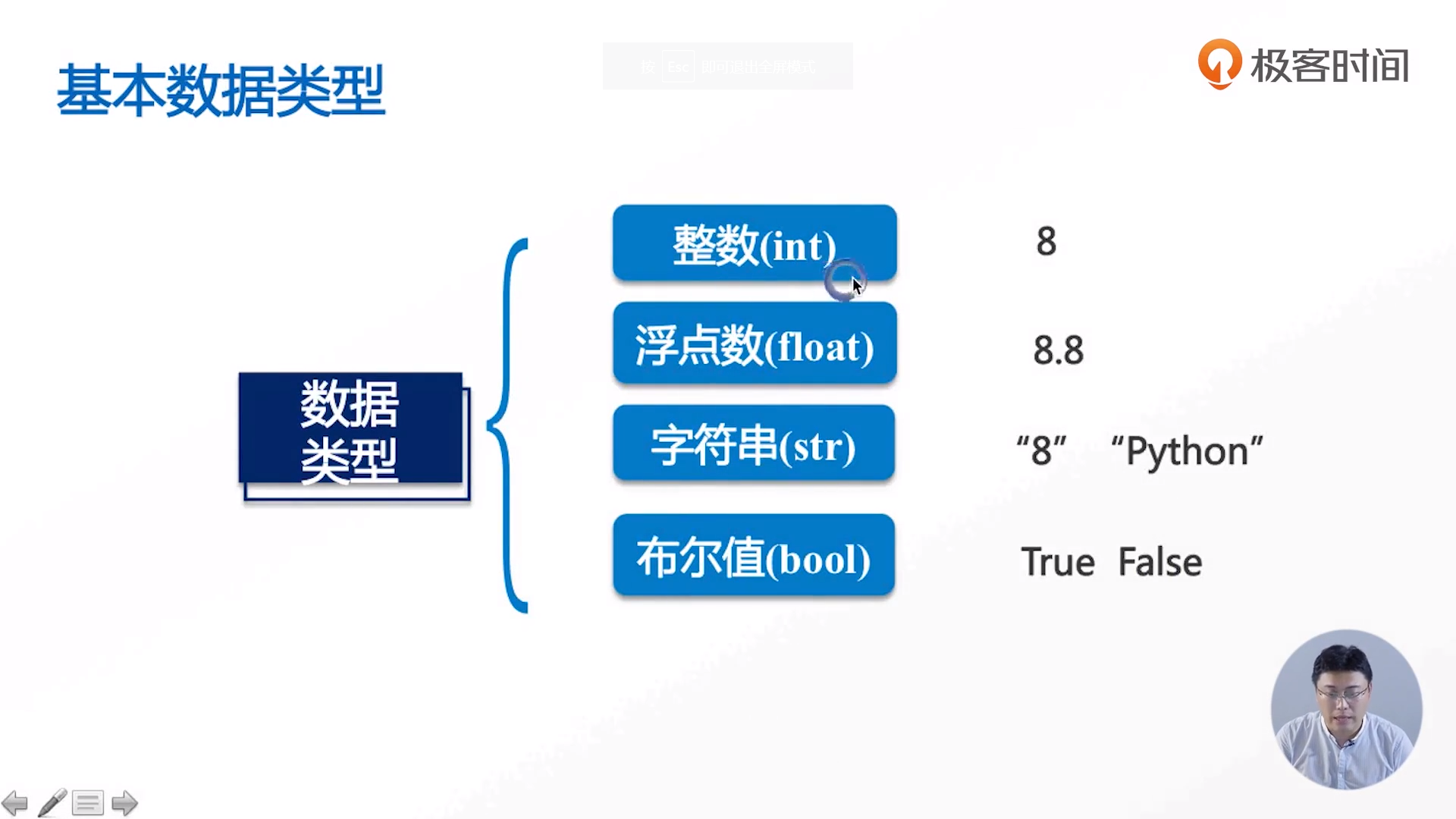
Basic data type
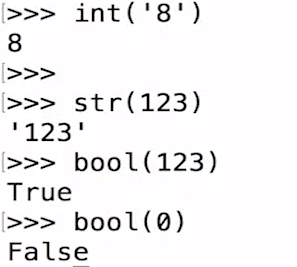
Type judgment
type()

Cast type
Target type (data to convert)
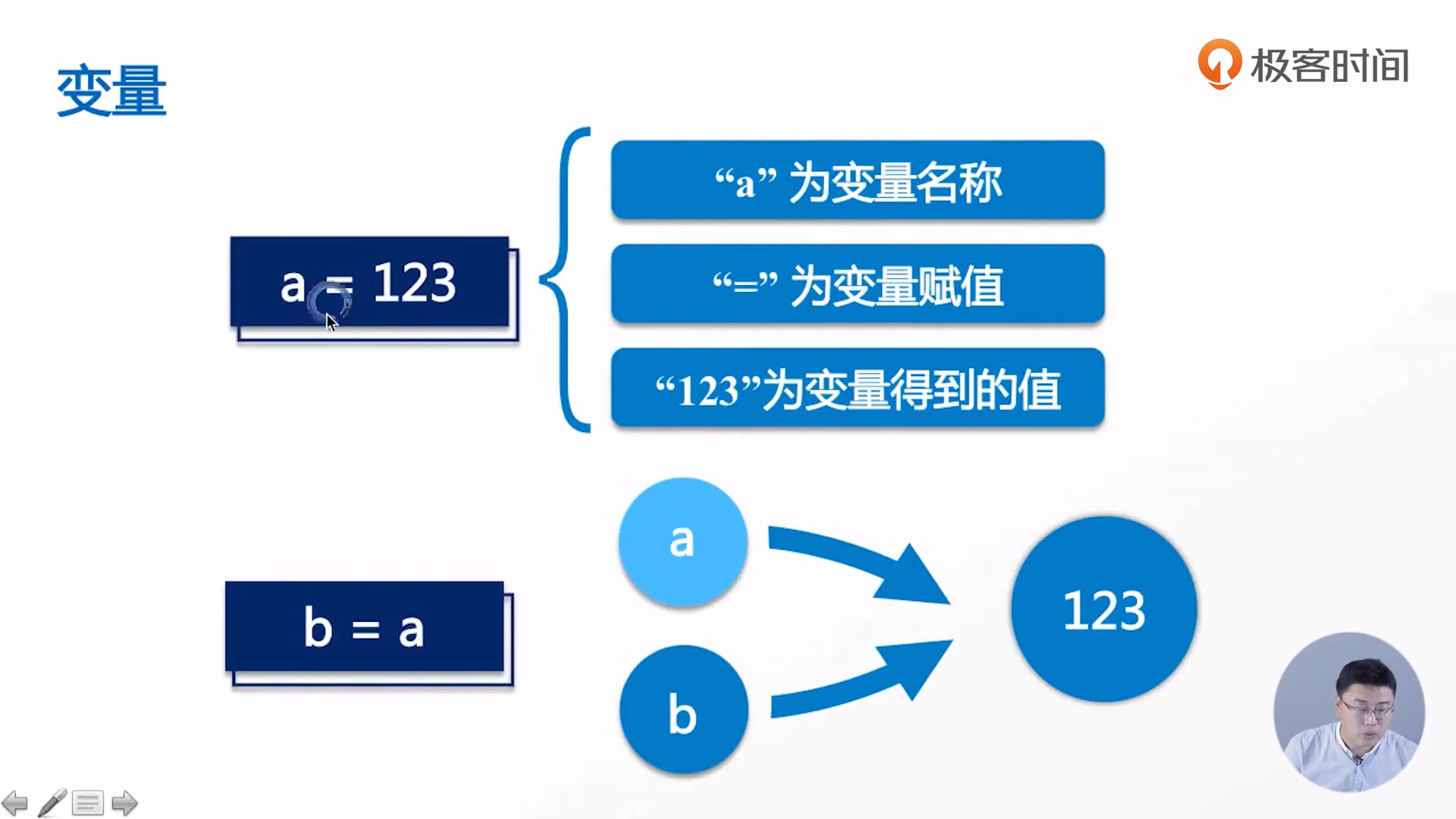
Definition and common operations of variables

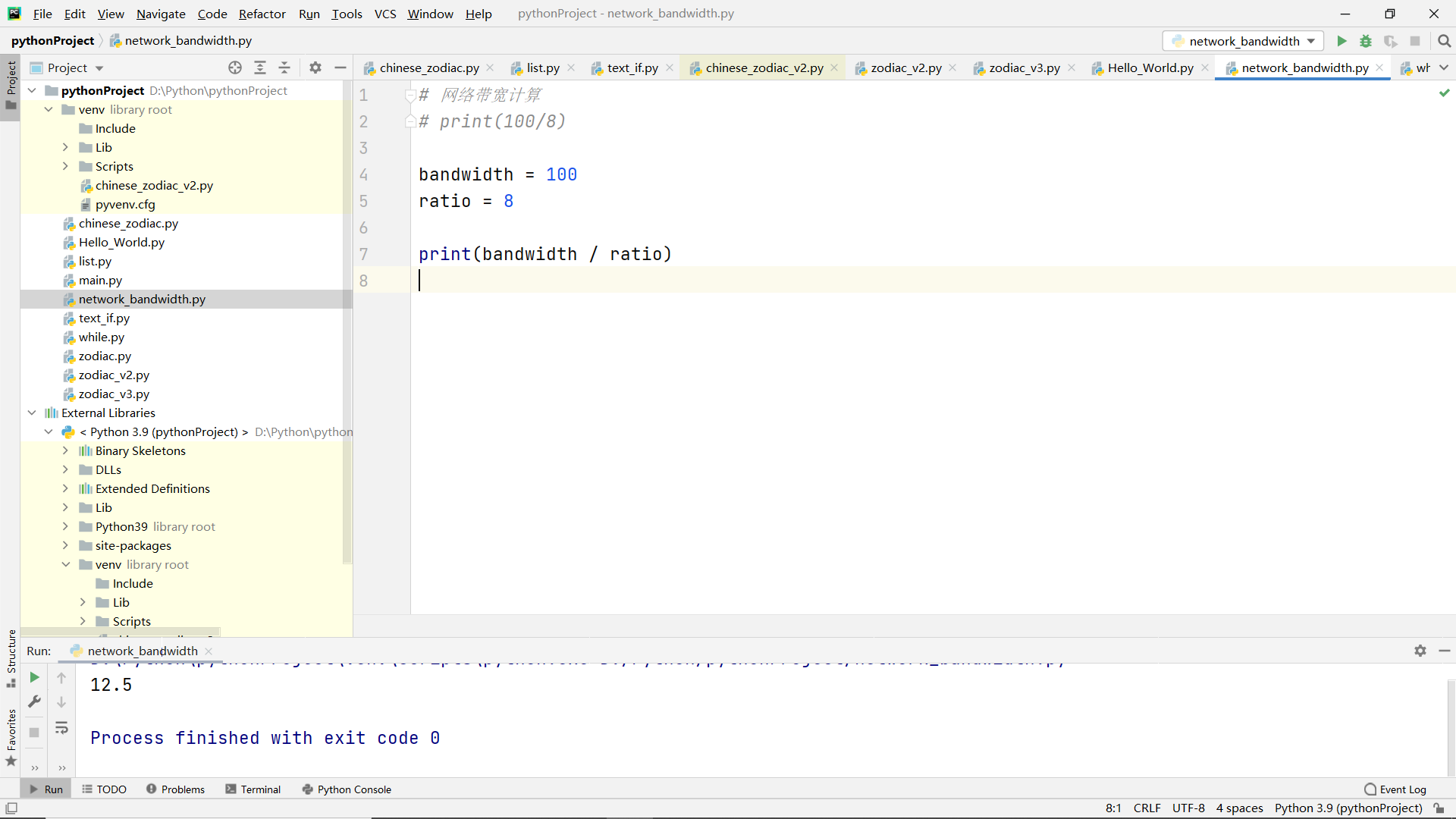
exercises
Title:
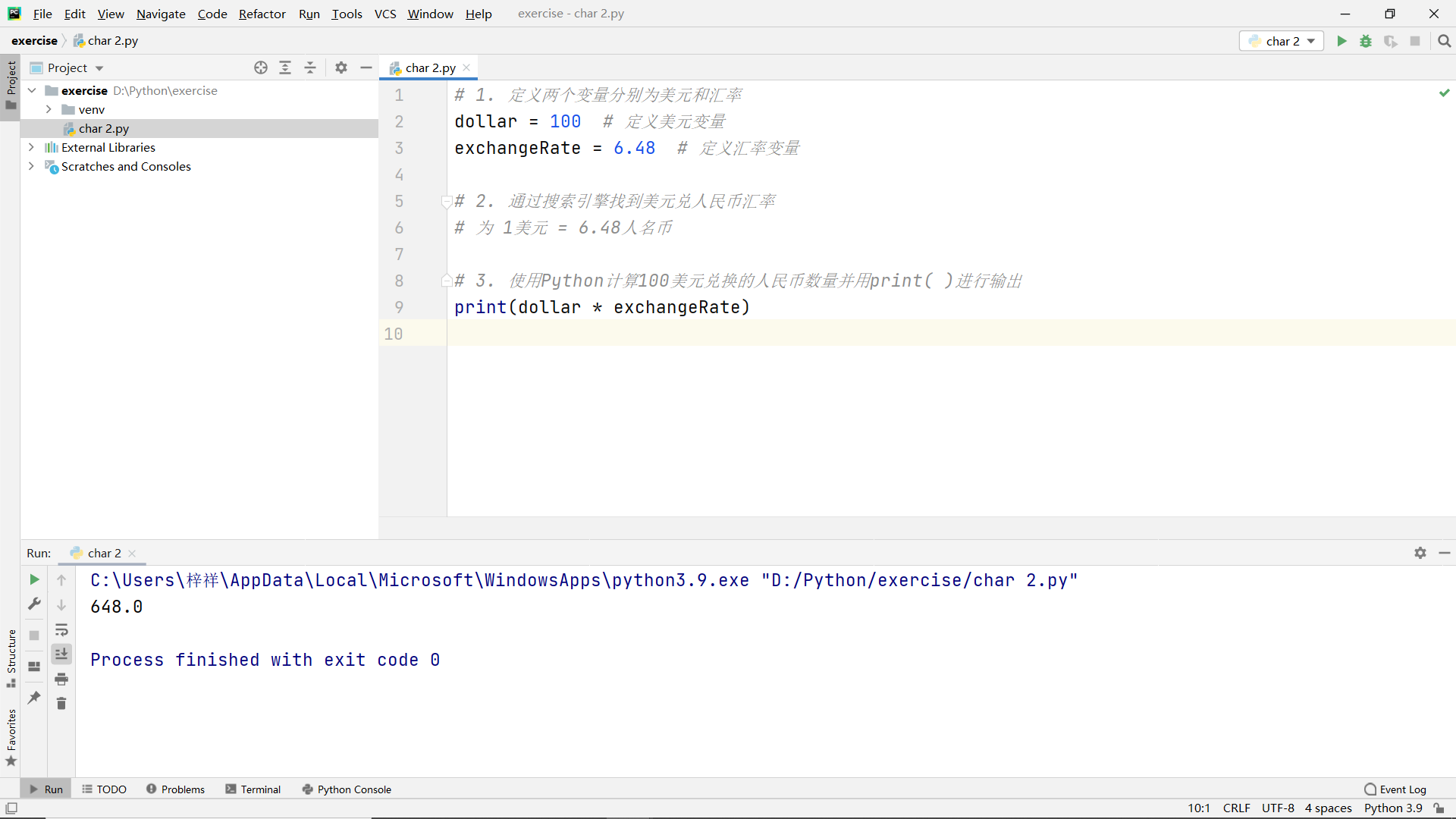
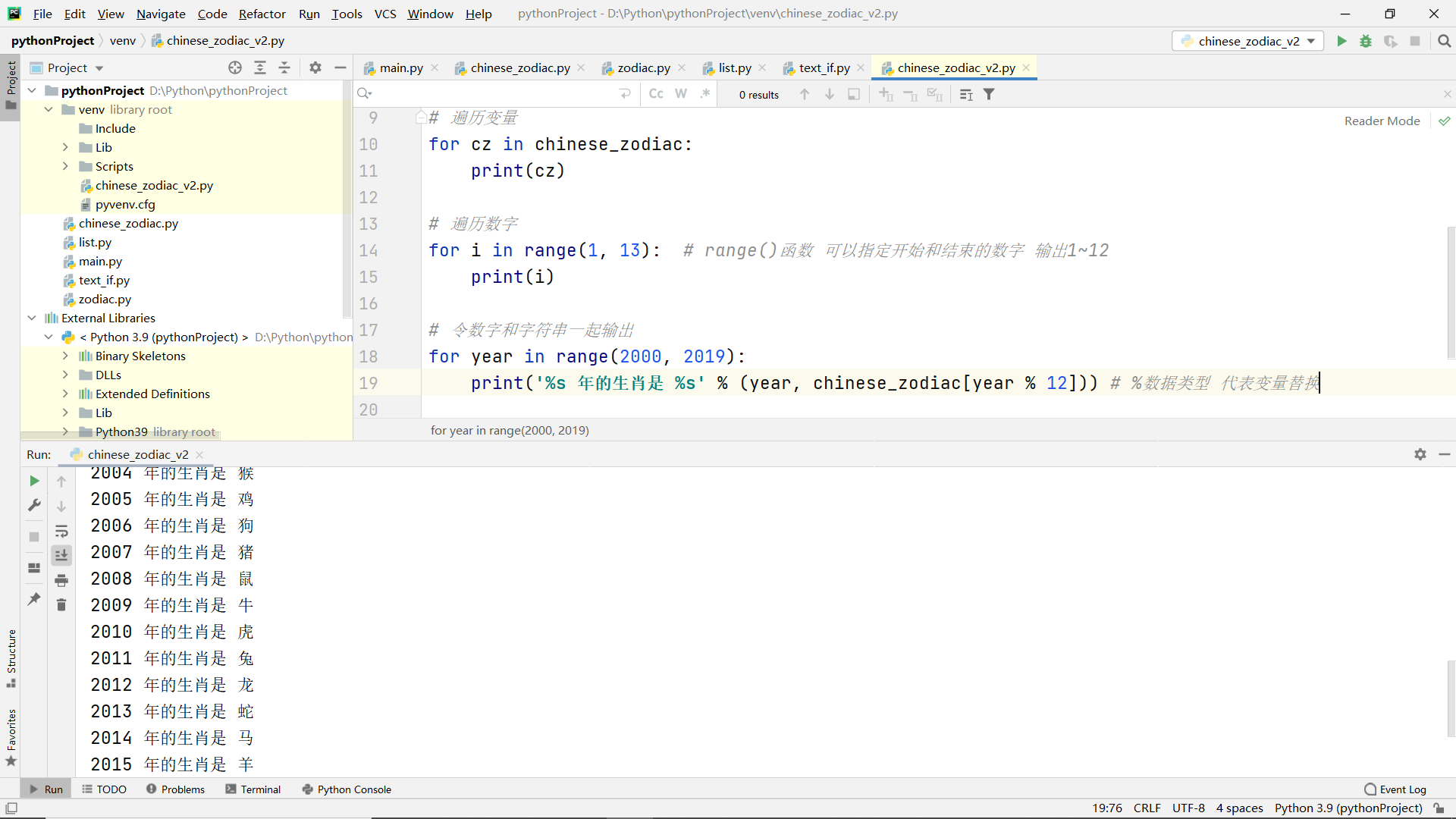
Exercise 1 Definition and use of variables
- Two variables are defined as US dollar and exchange rate
- Find the exchange rate of US dollar to RMB through search engine
- Use Python to calculate the amount of RMB converted into US $100 and output it with print()
code:
Chapter III sequence
Concept of sequence
case

concept
code
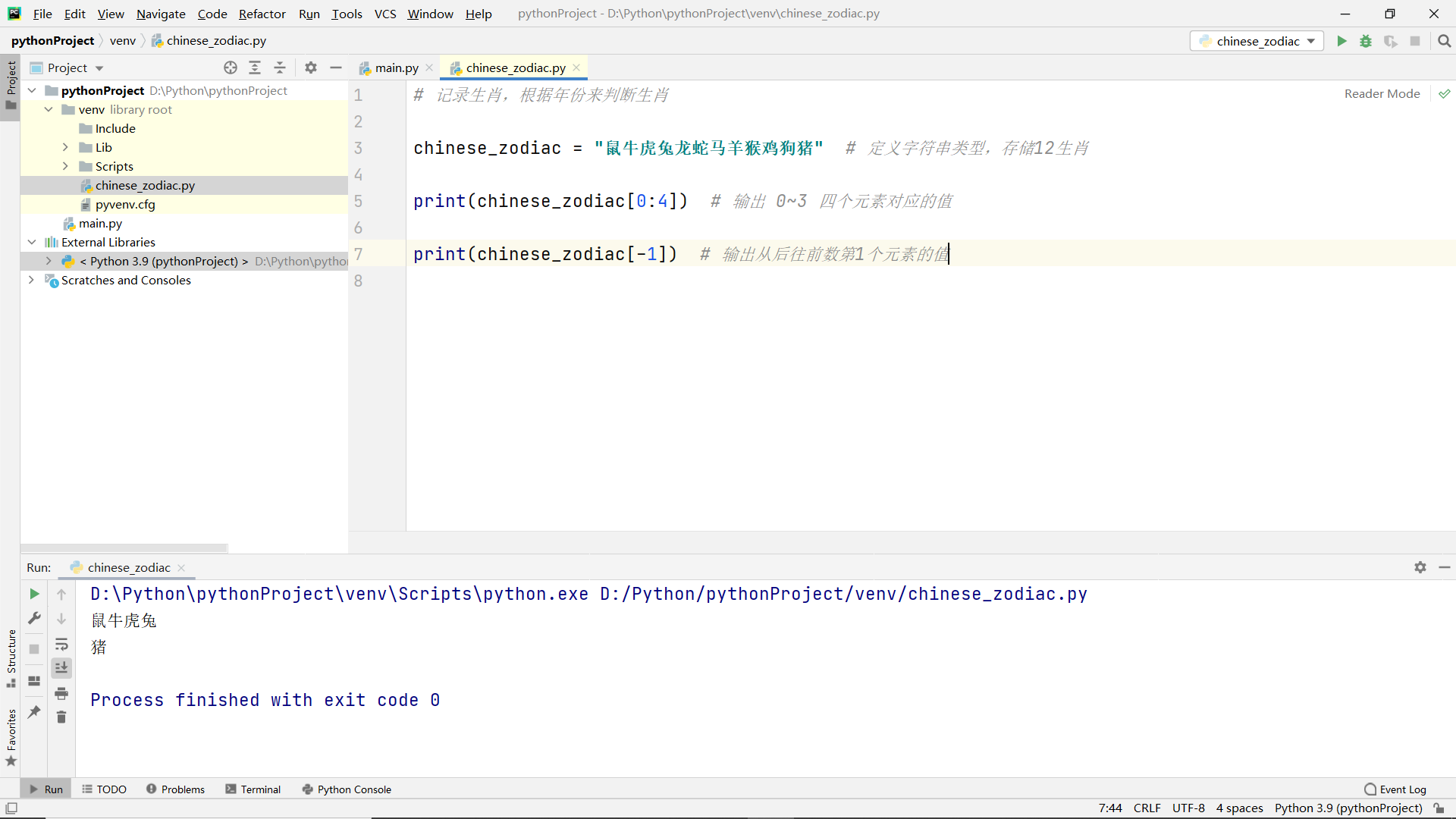
Definition and use of strings
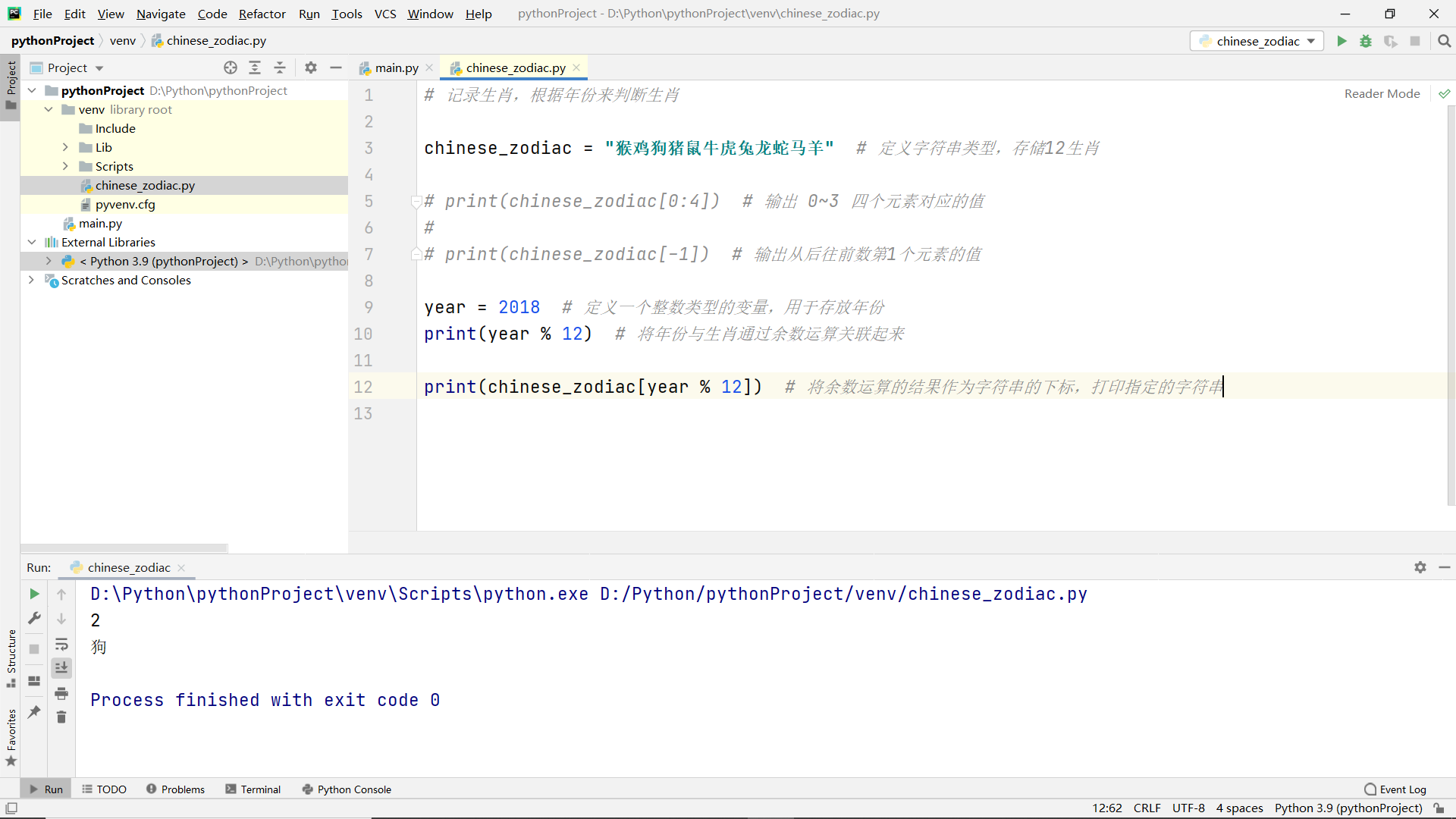
Common operations of string
Basic operation of sequence

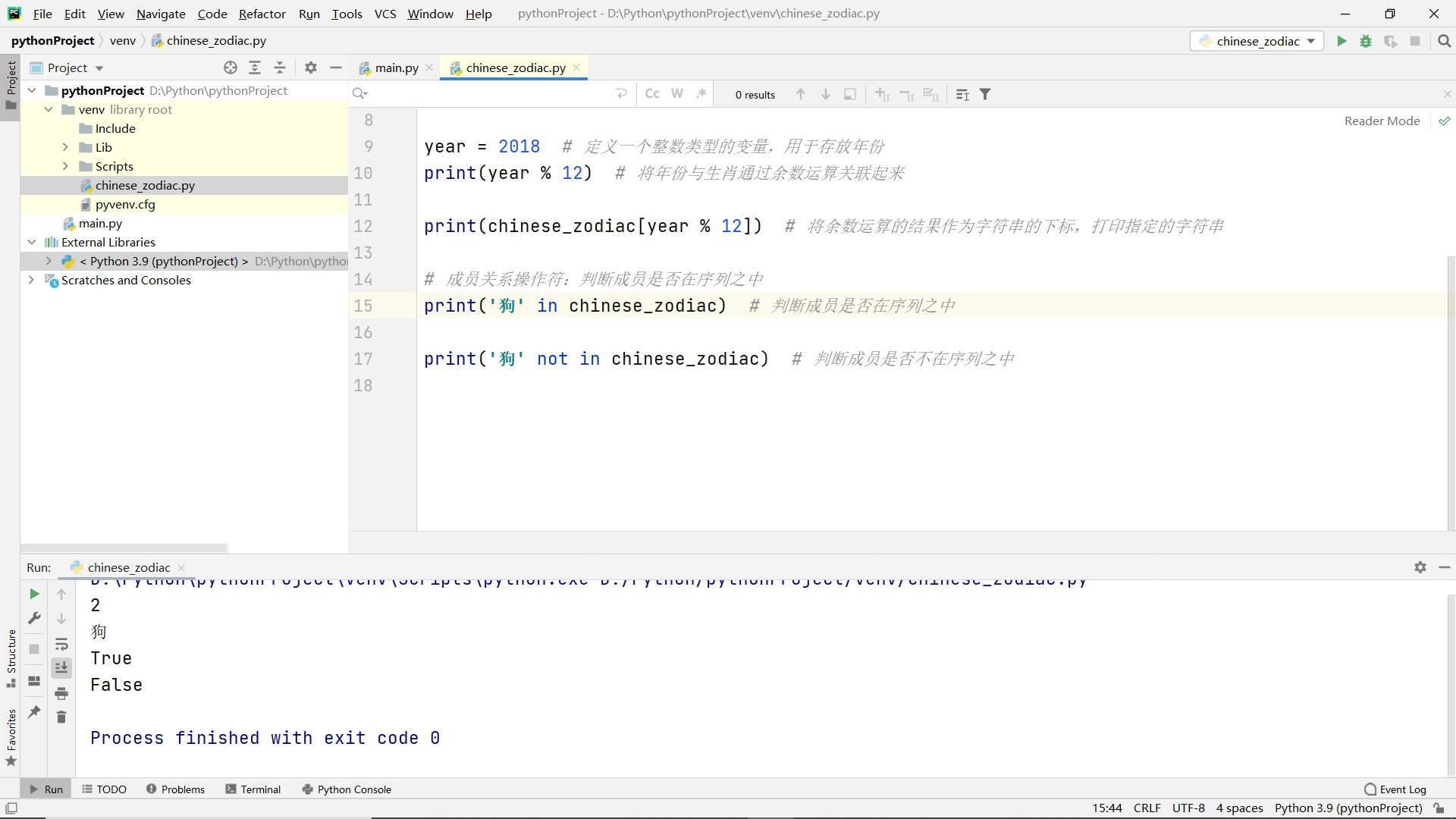
Membership operator
Join operator
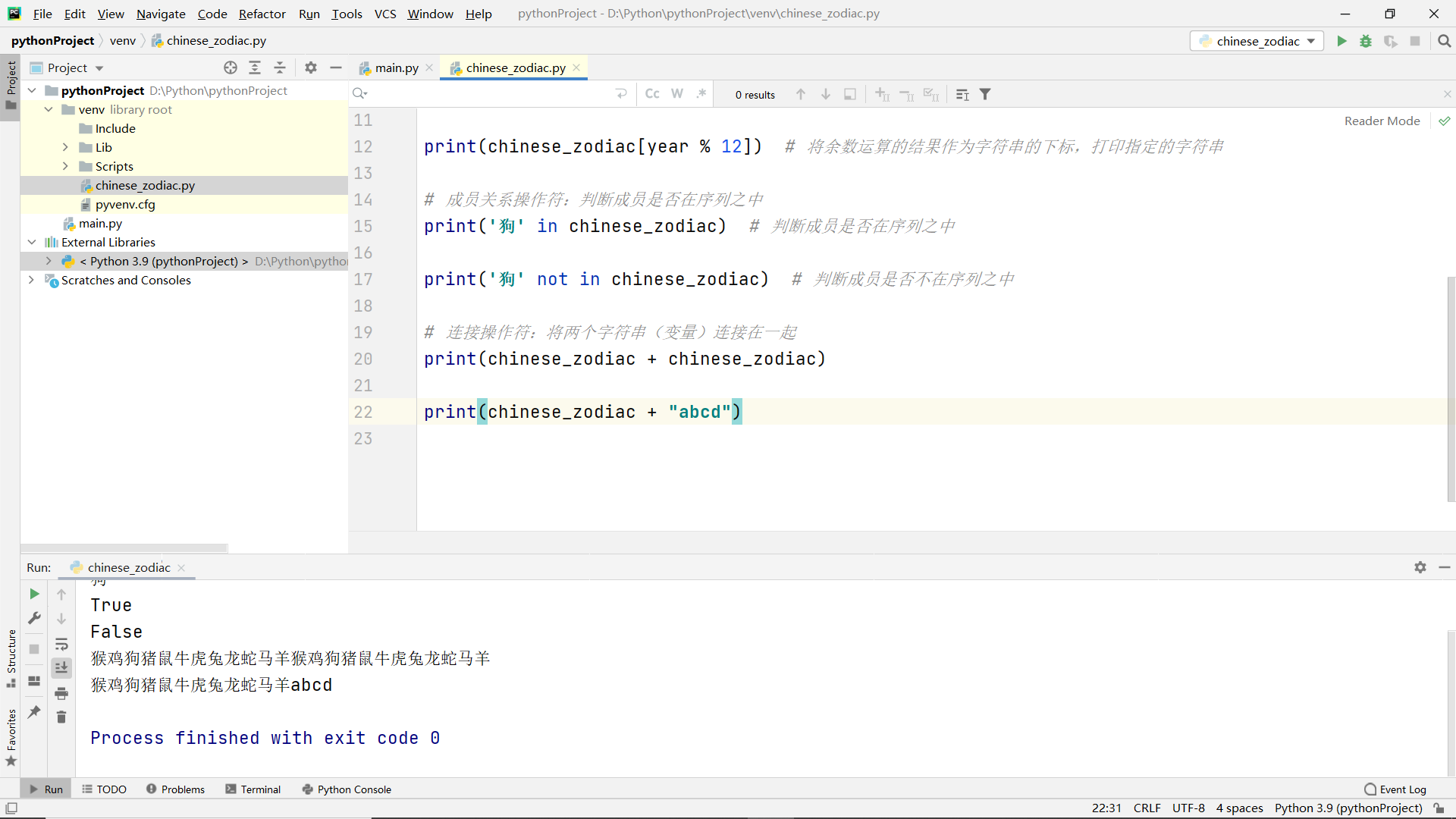
Repeat operator
Definition and common operations of tuples
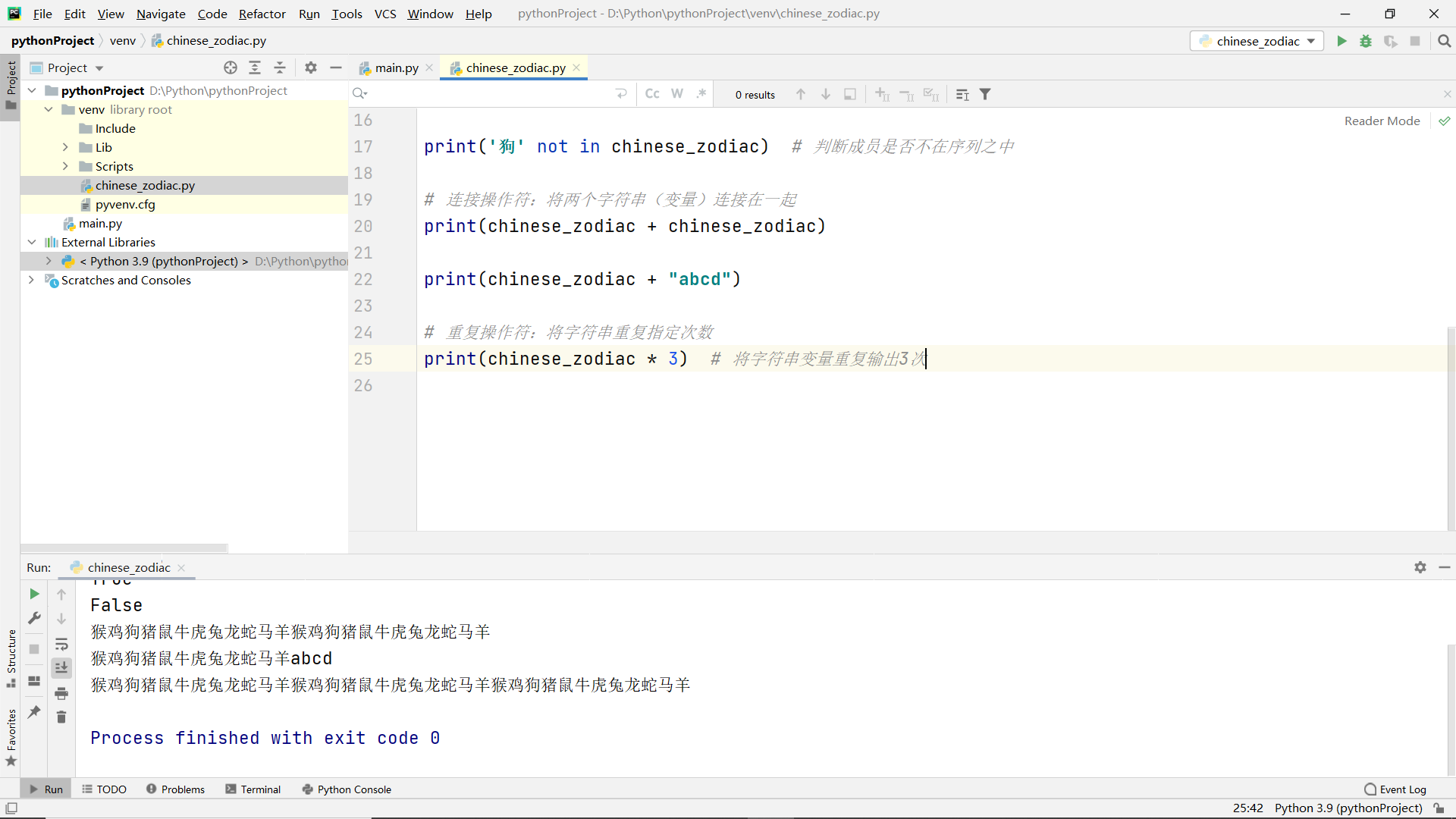
Comparison of number sizes in tuples
Single number:
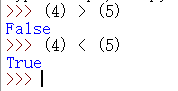
Two numbers:
It can be regarded as the superposition of two numbers
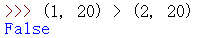
120 < 220, so the result is False.
The difference between lists and tuples
- The list is parenthesis [], and the tuple is parenthesis ()
- The contents in the list can be changed, and the contents in the tuple cannot be changed
Functions of fliter
Format:
filter(lambda x: x < b, a)
Take out the elements smaller than b in a
Show extracted elements
list(filter(lambda x: x < b, a))
example:

Count the number of extracted elements:
Format:
len (list (filter(lambda x: x < b, a)))
Take out the number of elements less than b in a
example:

Realize the zodiac search function
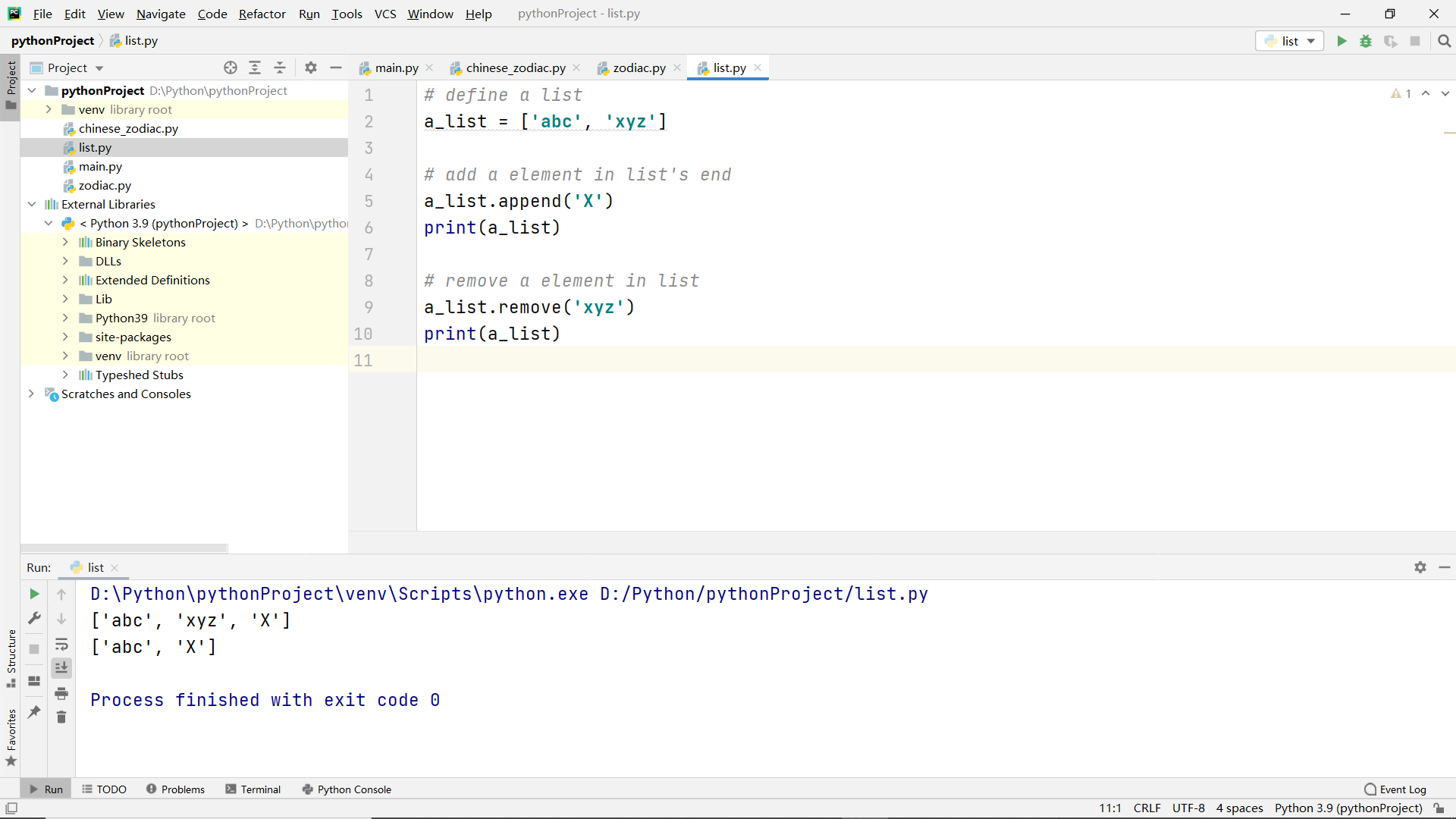
List definition and common operations
Basic operation:
- Add an element
- Remove an element

exercises
Practice a string
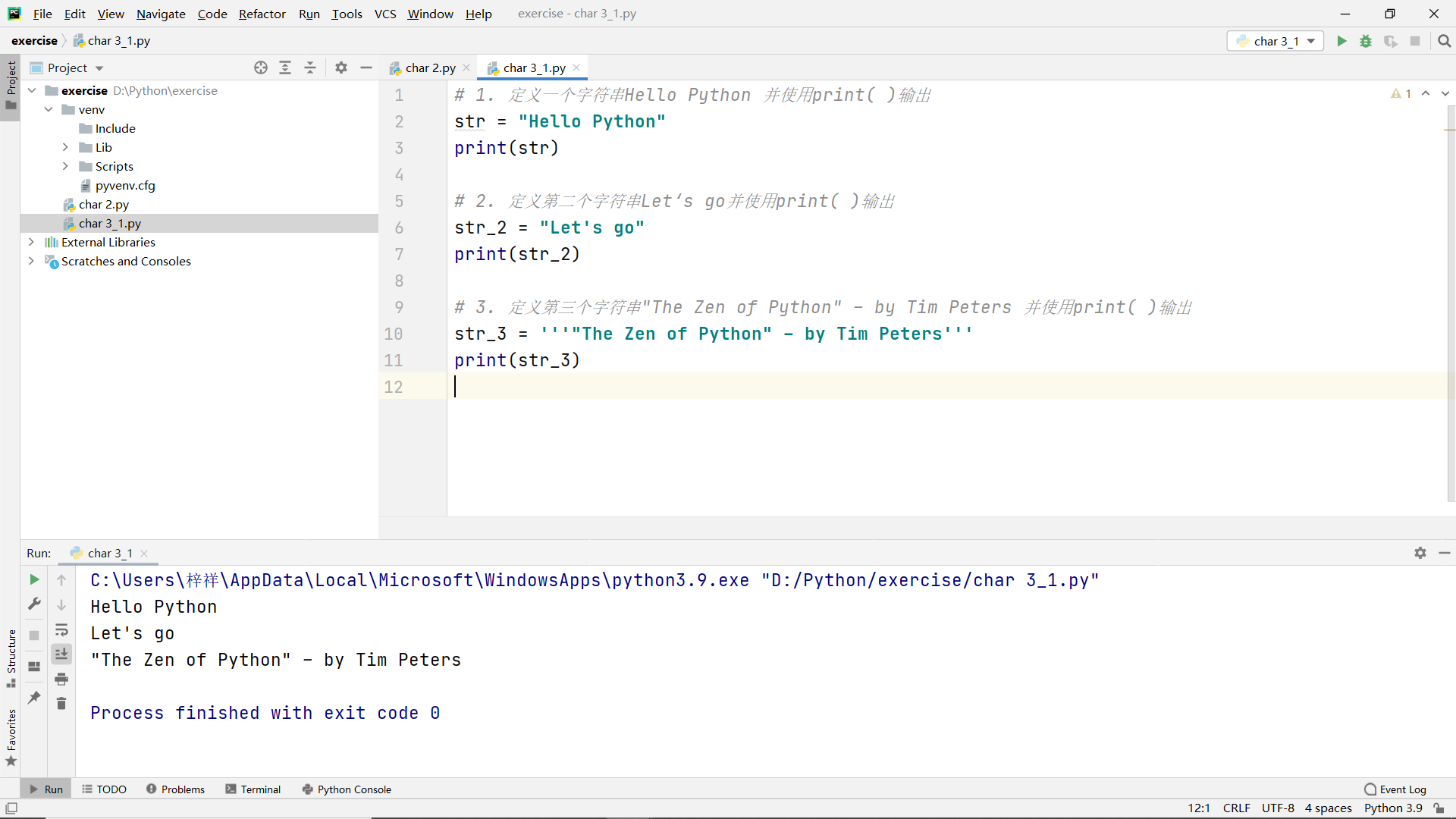
Title:
- Define a string Hello Python and output it using print()
- Define the second string Let's go and output it using print()
- Define the third string "The Zen of Python" – by Tim Peters and output it using print()
code:
Exercise 2 basic operation of string
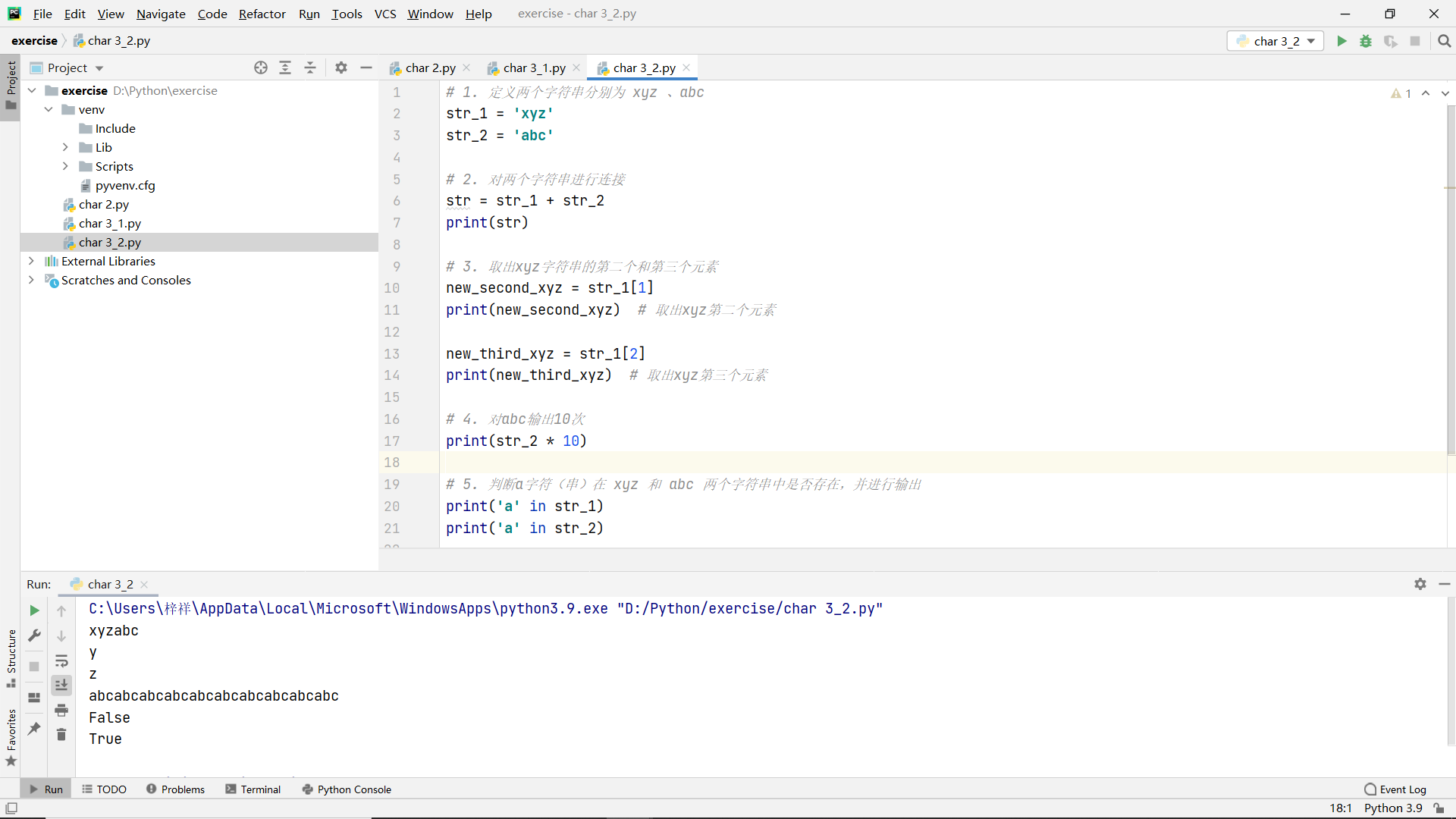
Title:
- Define two strings: xyz and abc
- Concatenate two strings
- Takes the second and third elements of the xyz string
- Output 10 times to abc
- Judge whether the a character (string) exists in xyz and abc strings and output it
code:
Exercise 3 basic operation of list
- Define a list of 5 numbers
- Add an element 100 to the list
- Observe the change of the list after deleting an element with remove()
- Use the slice operation to extract the first three elements of the list and the last element of the list
Practice the basic operation of quads
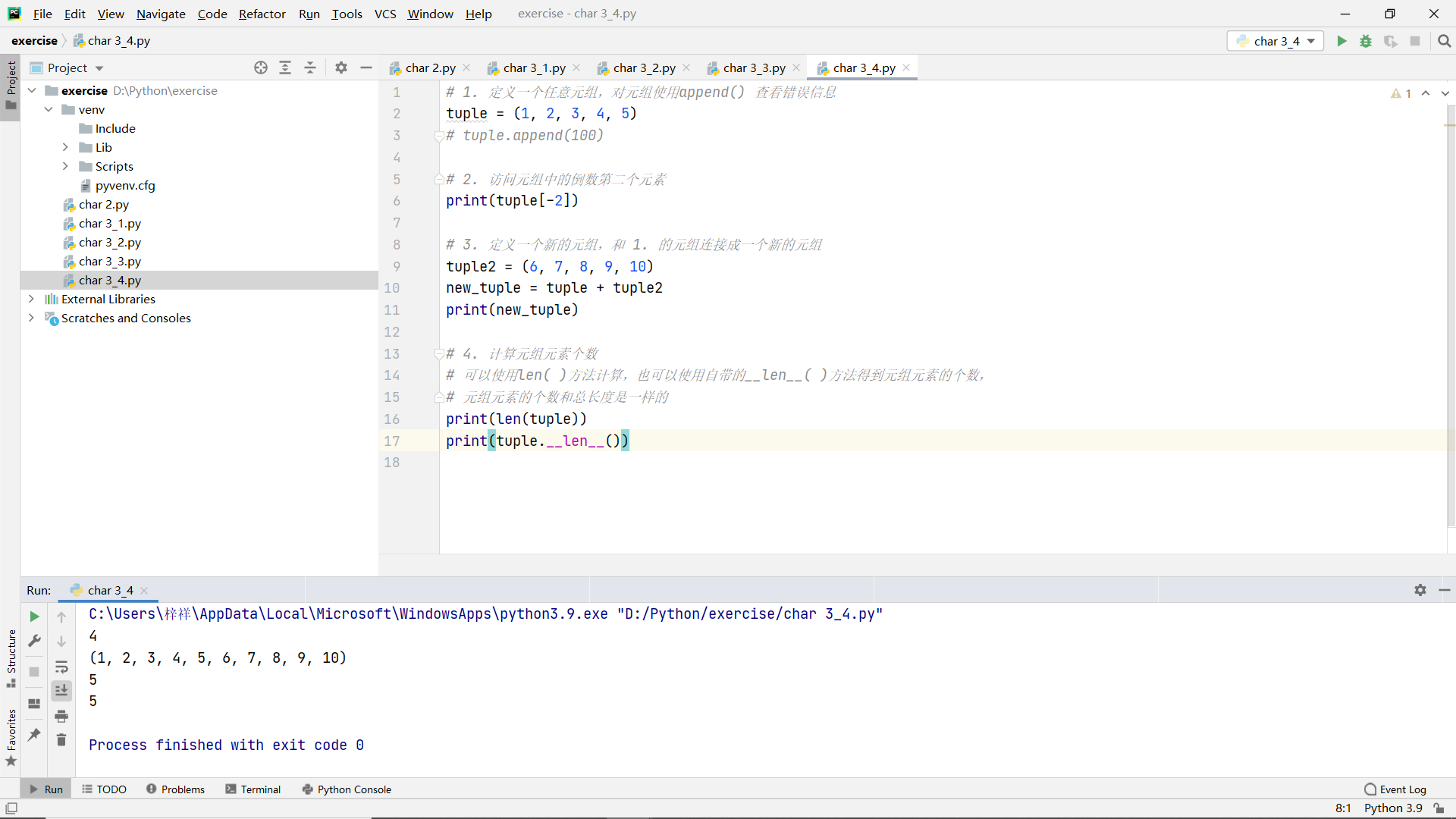
Title:
- Define an arbitrary tuple, and use append() to view the error information for the tuple
- Access the penultimate element in the tuple
- Define a new tuple, and 1 The tuple of is concatenated into a new tuple
- Calculate the number of tuple elements
code:
Chapter IV conditions and cycles
Conditional statement
grammar
code
for loop

Purpose:
The for loop is often used to traverse sequences
code:
while Loop

usage
It is usually used with if conditional judgment statements
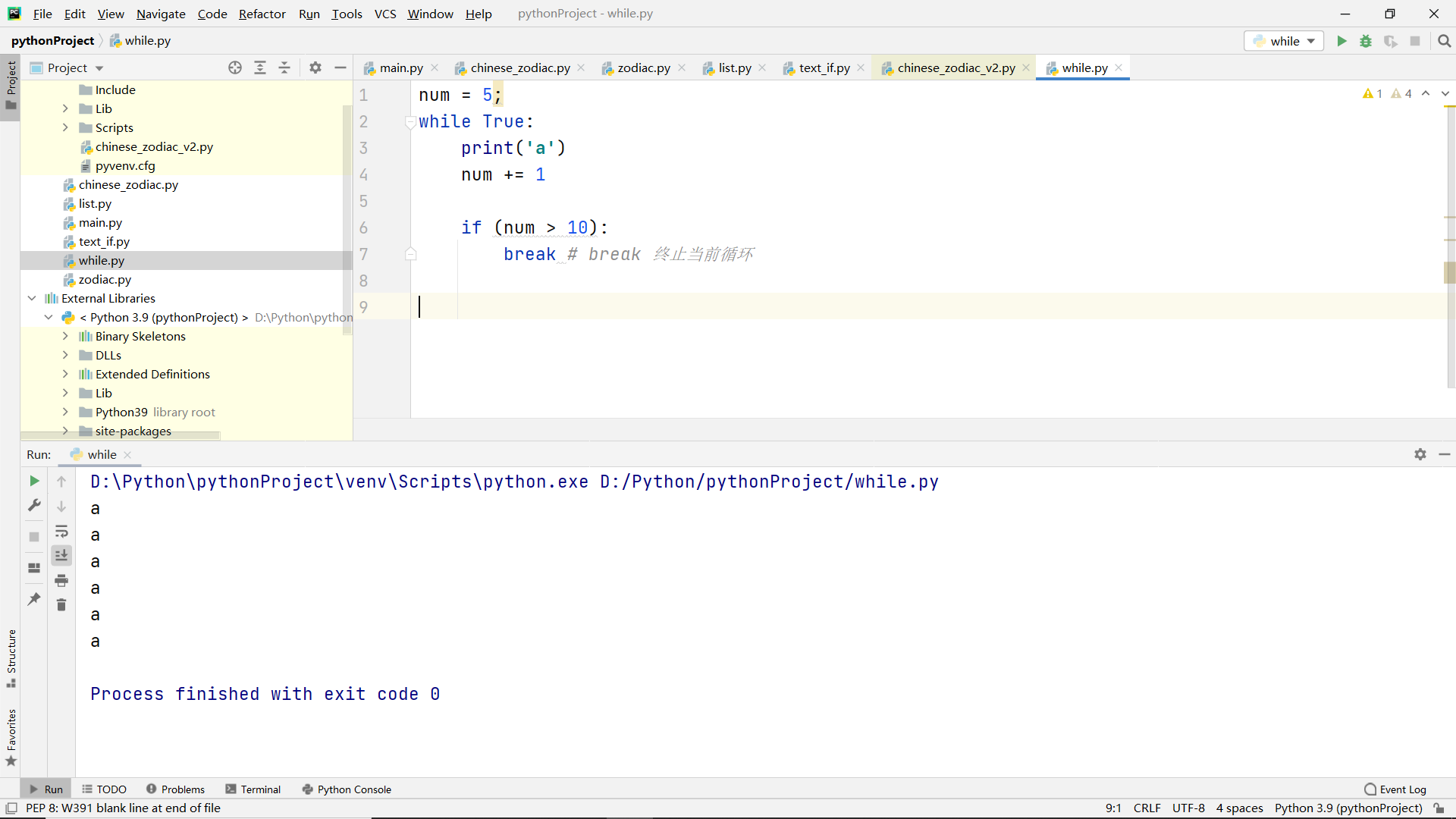
break statement
Function:
Terminates the current cycle
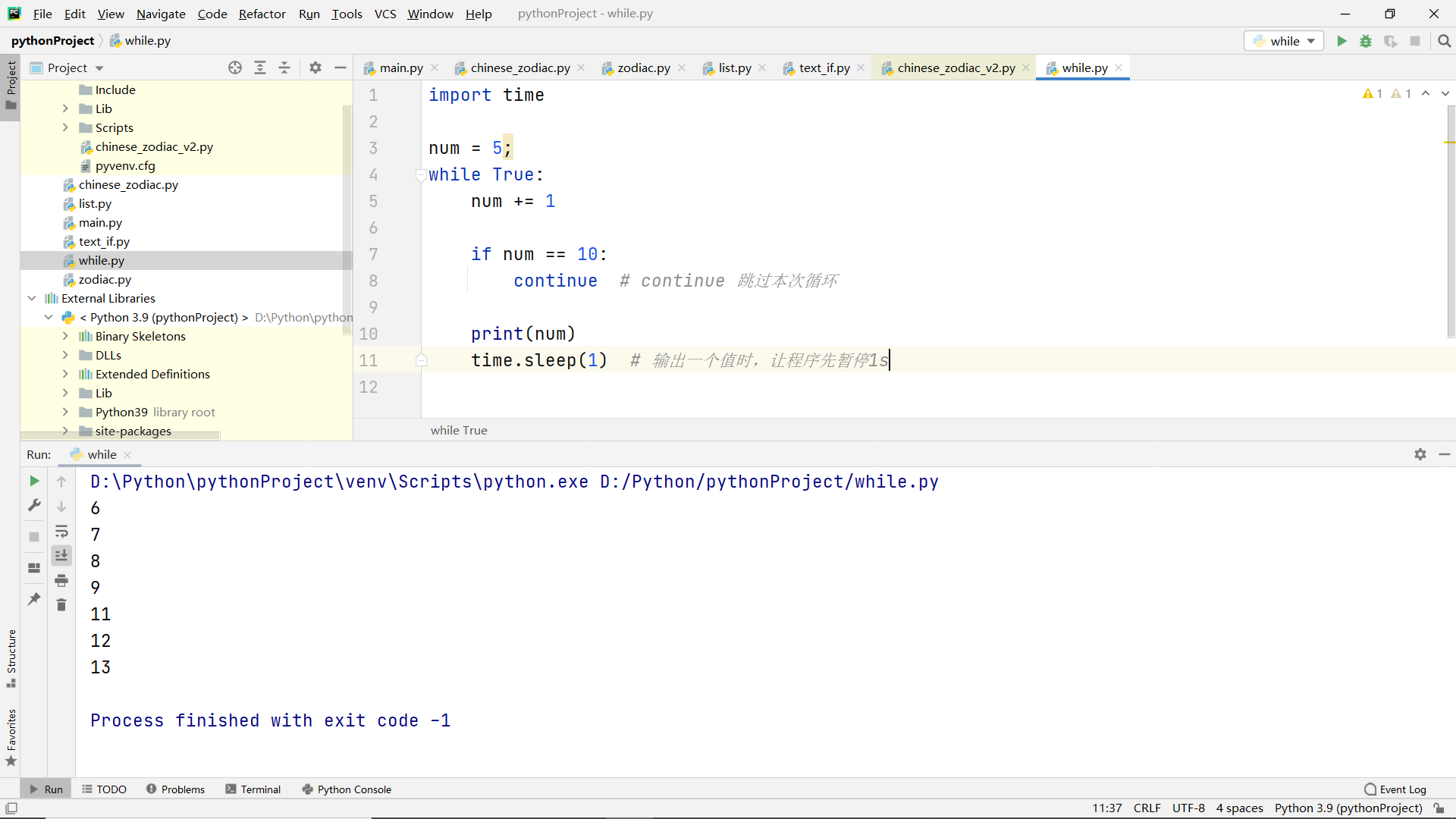
continue Statement
Function:
Skip this cycle
summary
if nesting in for statement
Judgment constellation realized by for loop:
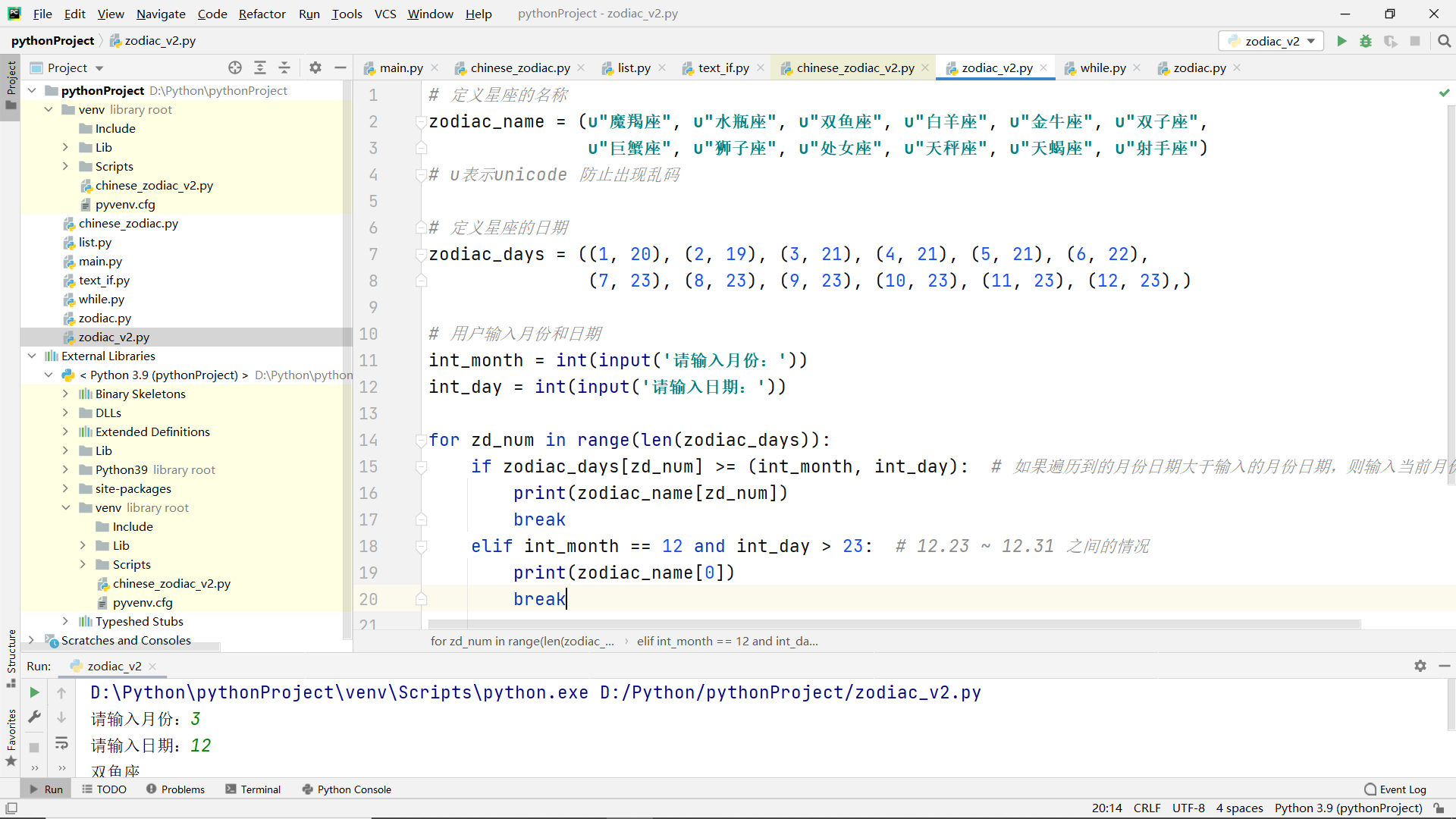
if nesting in while loop statements
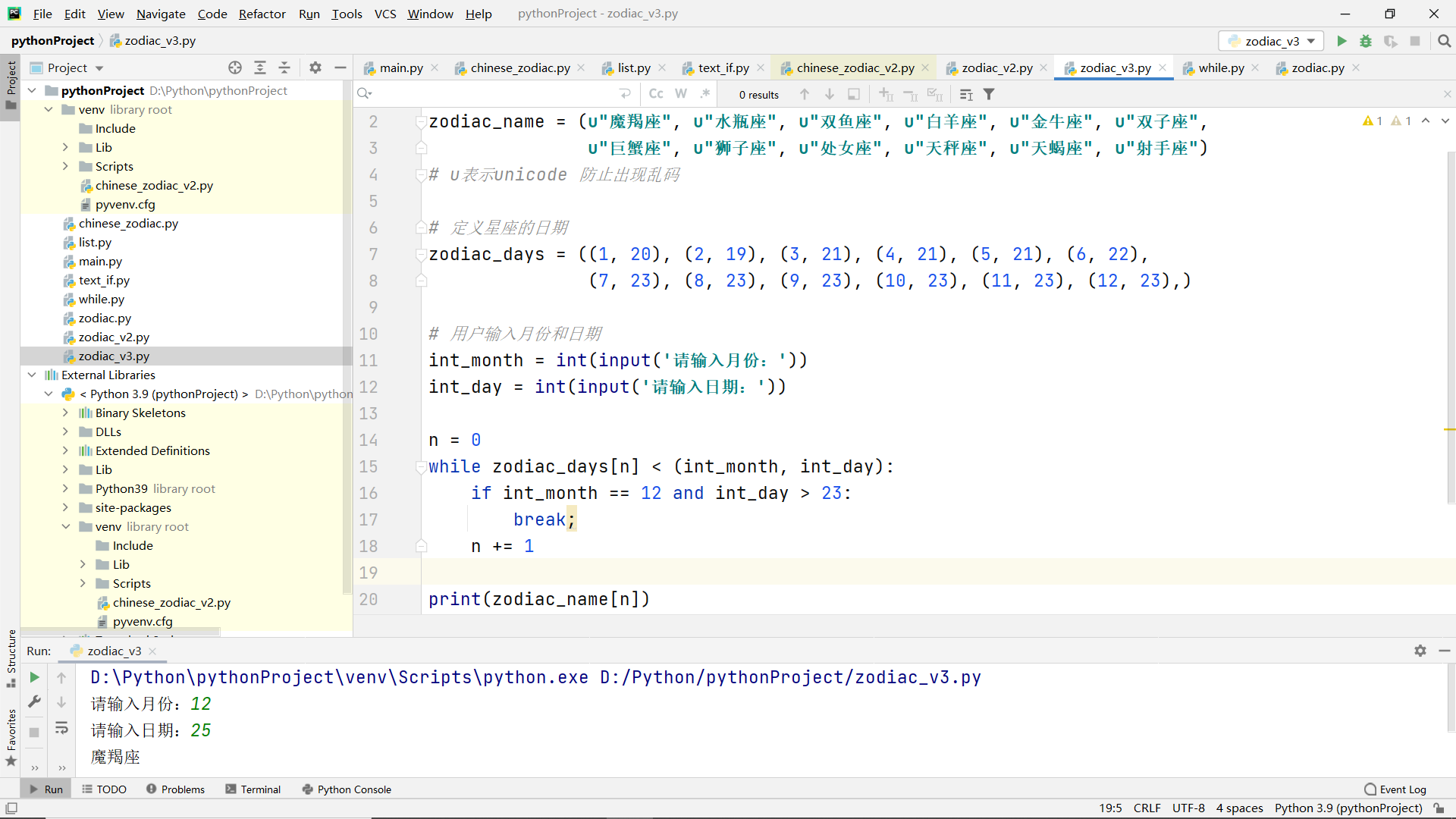
exercises
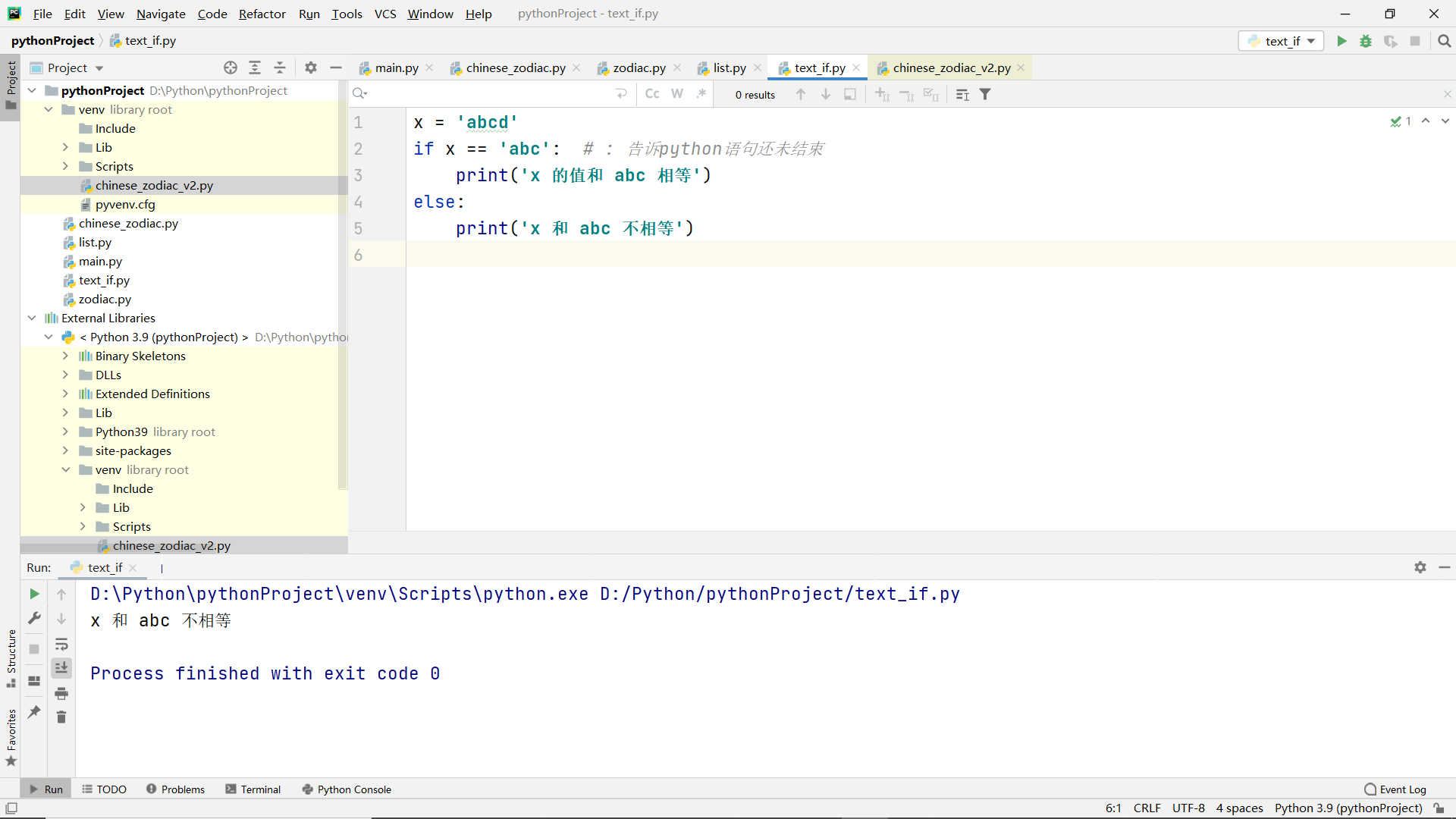
Exercise 1 use of conditional statements
Title:
- Use the if statement to judge whether the length of the string is equal to 10, and output different results according to the judgment results
- Prompt the user to input a number between 1-40. Use the if statement to judge according to the size of the input number. If the input number is 1-10, 11-20, 21-30 and 31-40, output different numbers respectively
code:
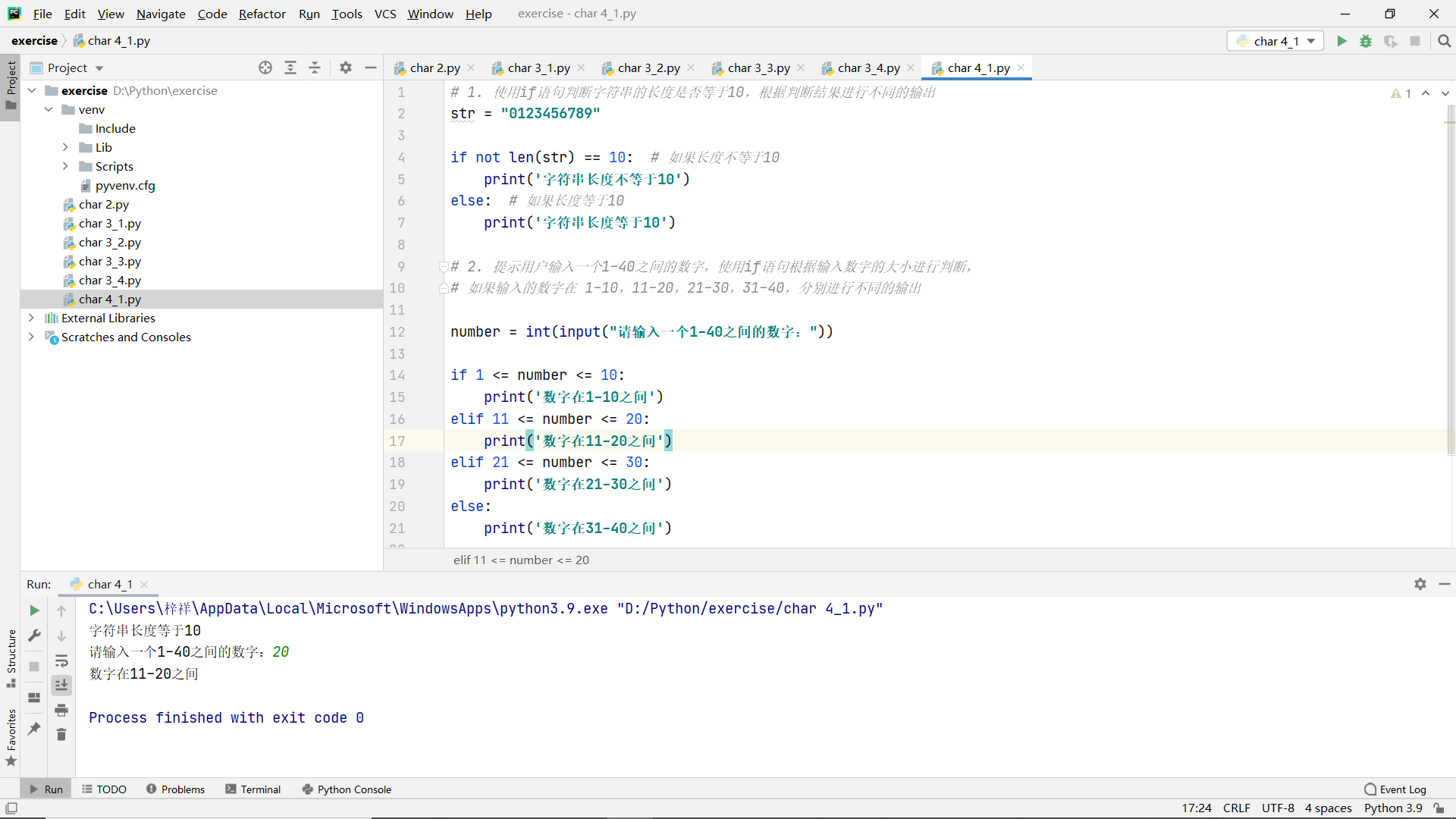
Exercise 2 use of circular statements
Title:
- Use the for statement to output all even numbers between 1 and 100
- Use the while statement to output a number between 1 and 100 that can be divided by 3
code:
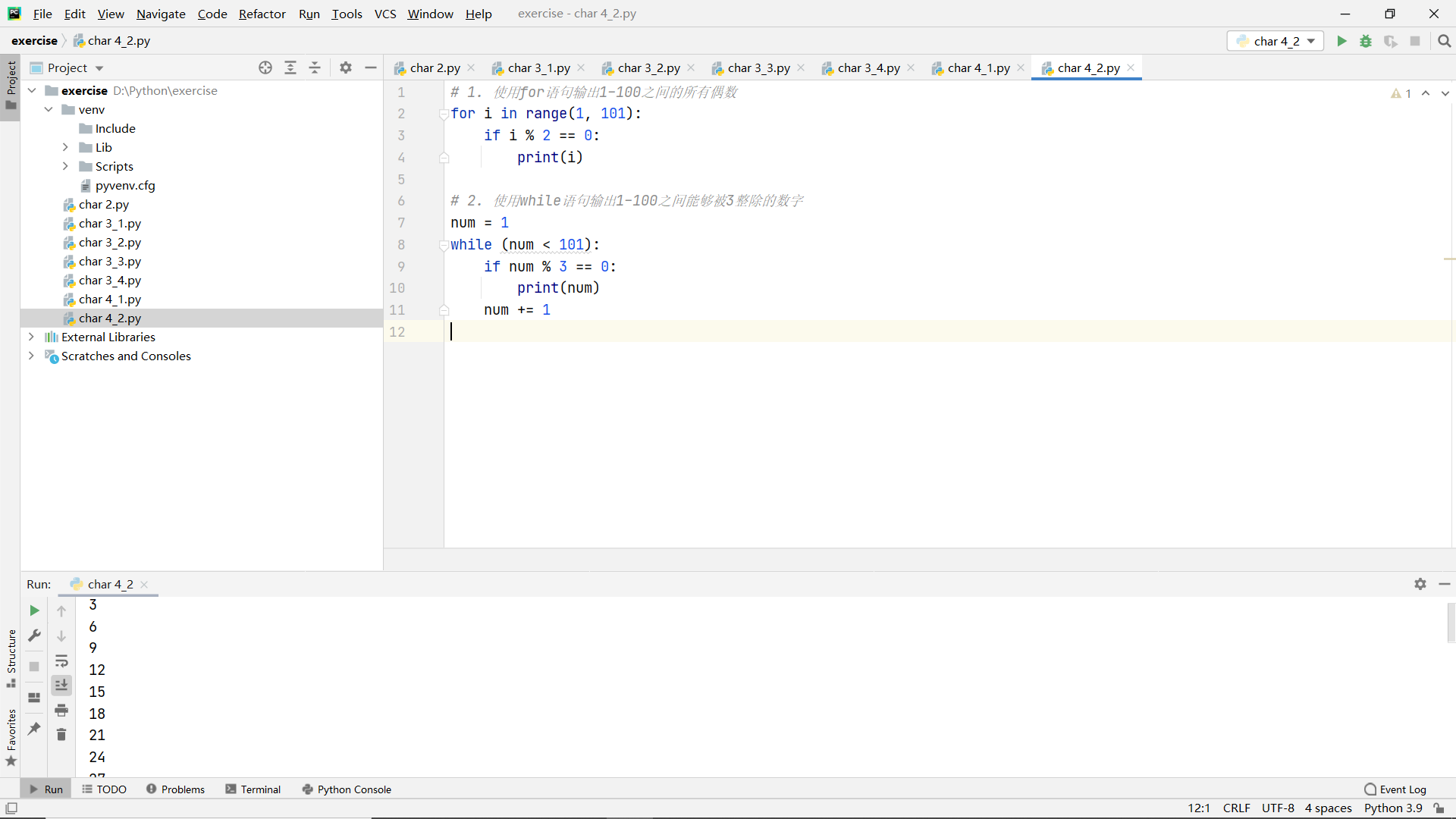
Chapter 5: mapping and dictionary
Dictionary definition and common operations

Define and add elements
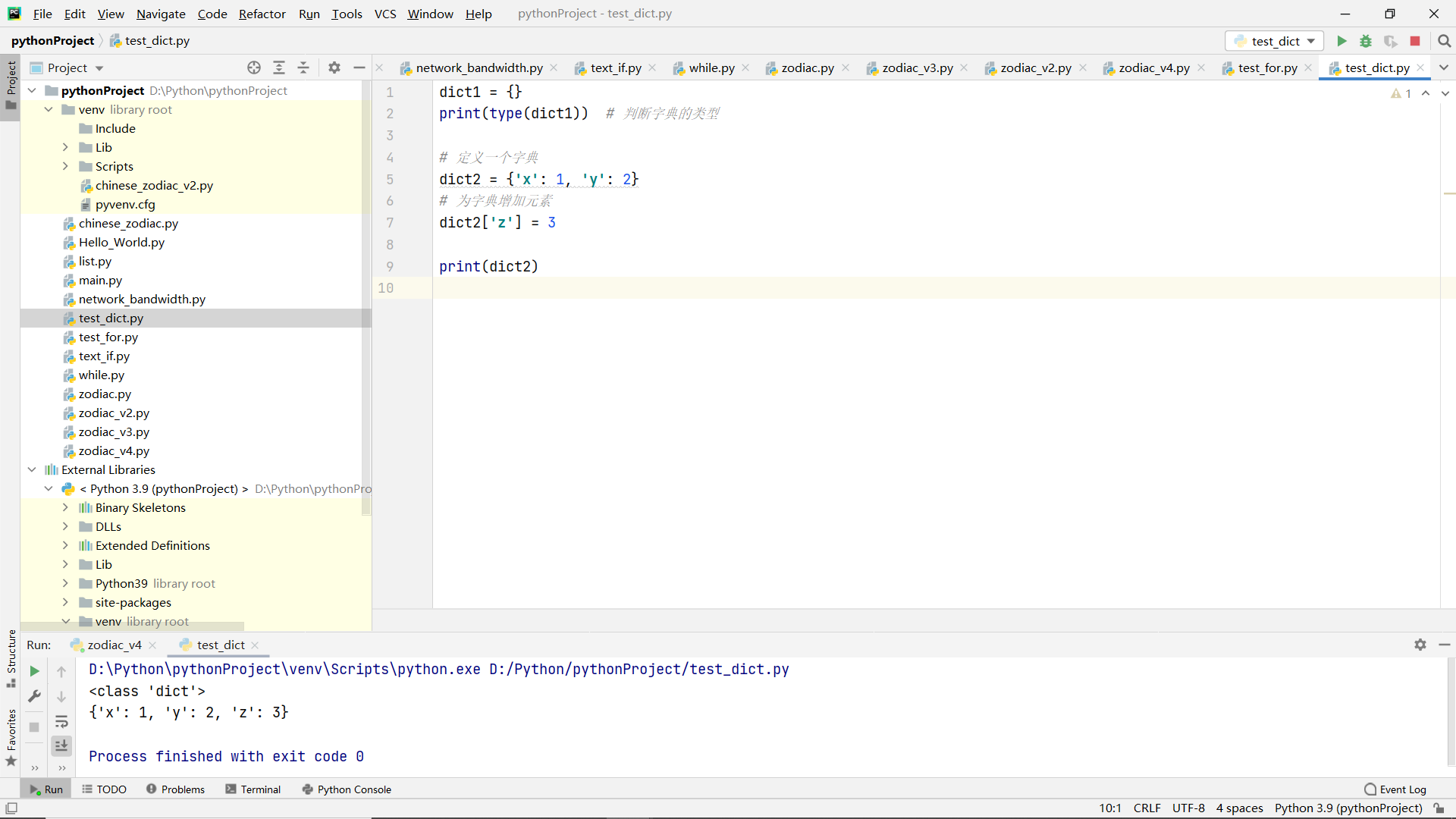
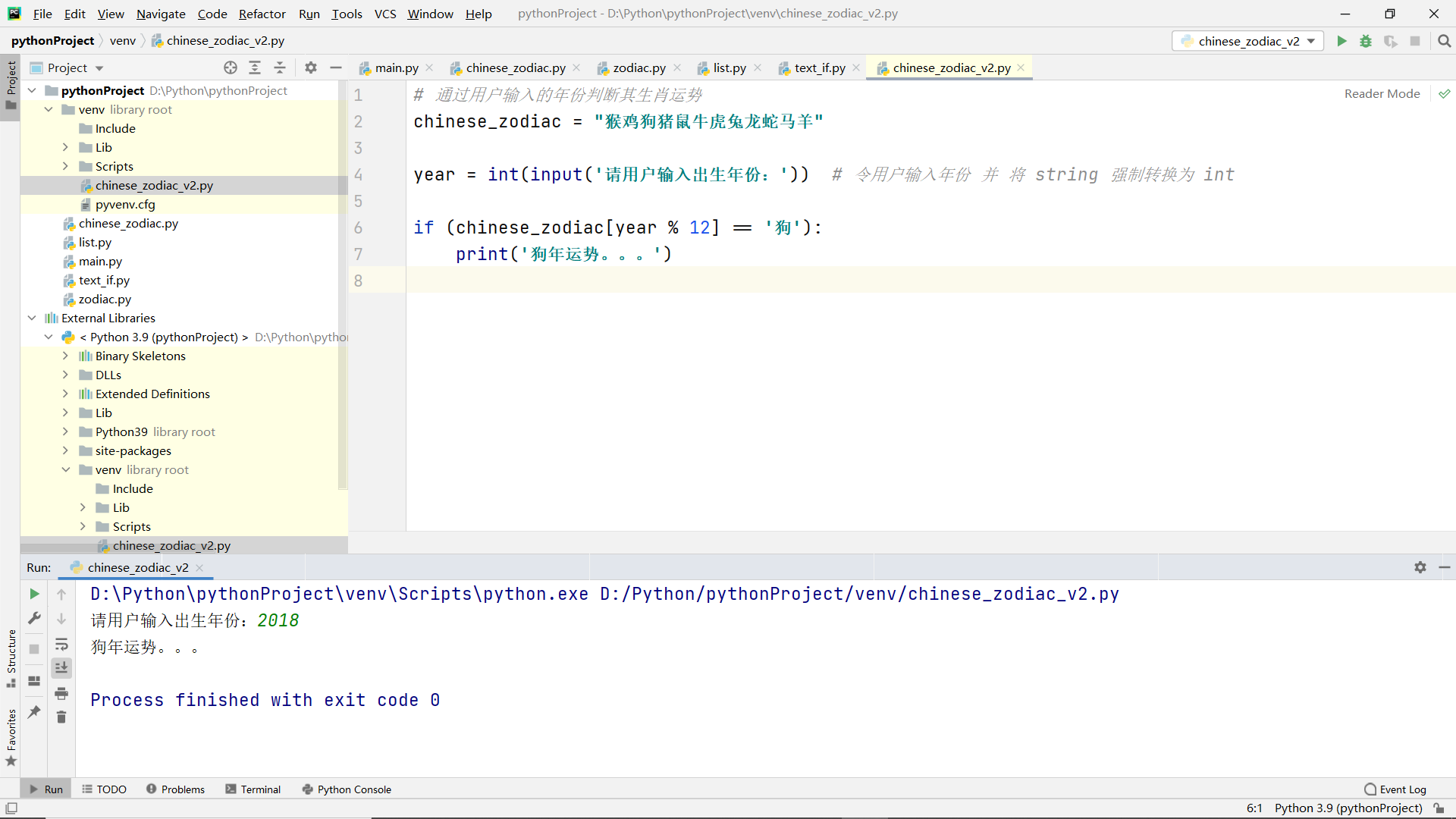
Case improvement of zodiac and constellation
code:
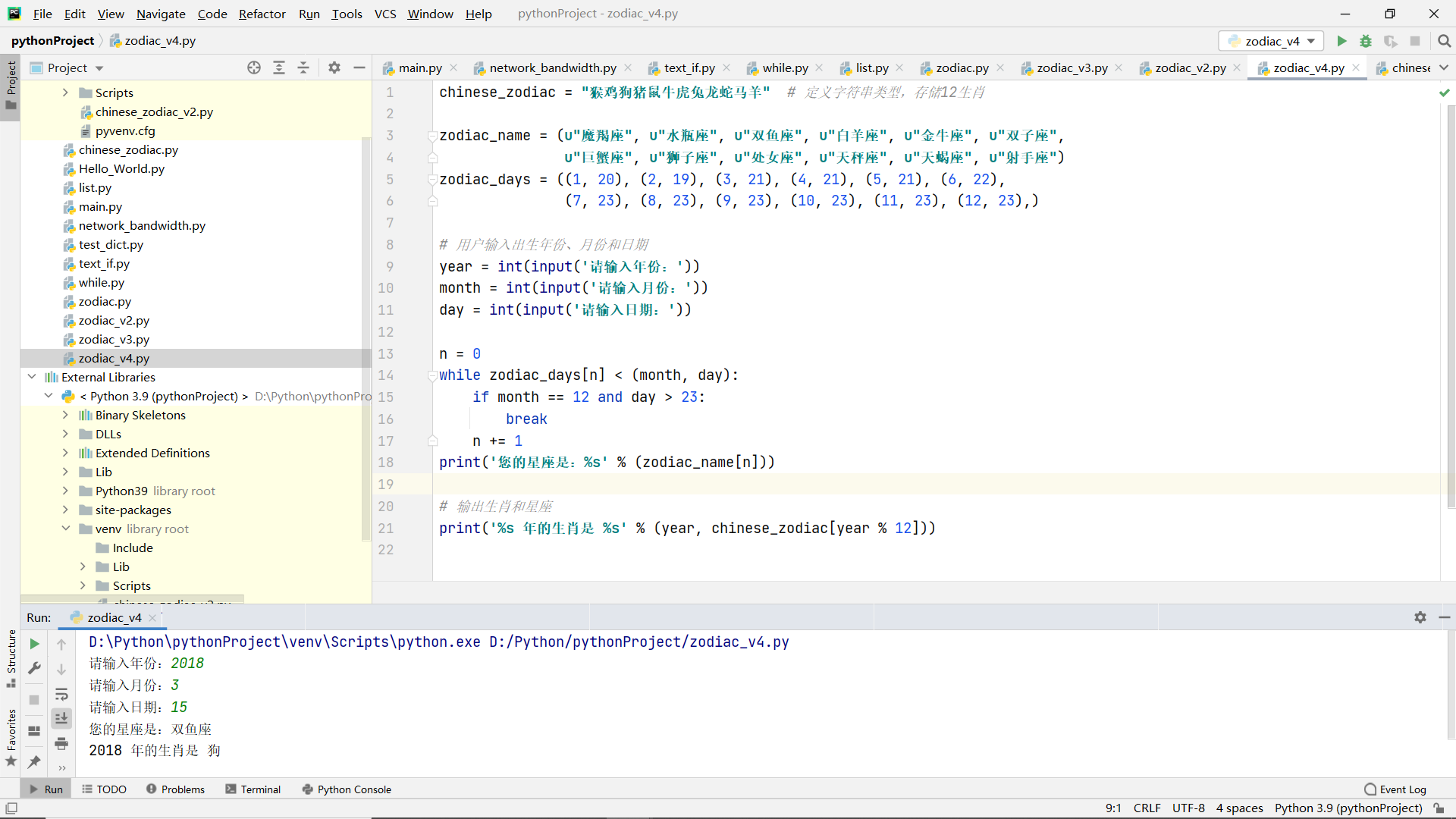
chinese_zodiac = "Monkey chicken dog pig rat ox tiger rabbit dragon snake horse sheep" # Define string type and store 12 zodiac characters
zodiac_name = (u"Capricorn", u"aquarius", u"Pisces", u"Aries", u"Taurus", u"Gemini",
u"Cancer", u"leo", u"Virgo", u"libra", u"scorpio", u"sagittarius")
zodiac_days = ((1, 20), (2, 19), (3, 21), (4, 21), (5, 21), (6, 22),
(7, 23), (8, 23), (9, 23), (10, 23), (11, 23), (12, 23),)
# Definition dictionary
cz_num = {}
z_num = {}
# Initialization key
for i in chinese_zodiac:
cz_num[i] = 0 # Chinese_ The zodiac keyword is assigned to 0 in turn
for i in zodiac_name:
z_num[i] = 0 # Zodiac_ The name keyword is assigned to 0 in turn
while True:
# The user enters the year, month, and date of birth
year = int(input('Please enter the year:'))
month = int(input('Please enter month:'))
day = int(input('Please enter date:'))
n = 0
while zodiac_days[n] < (month, day):
if month == 12 and day > 23:
break
n += 1
# Output zodiac and constellation
print('Your constellation is:%s' % (zodiac_name[n]))
print('%s What is the zodiac sign in %s' % (year, chinese_zodiac[year % 12]))
# Assign a value to the initialized dictionary
cz_num[chinese_zodiac[year % 12]] += 1 # The current zodiac of the user will be increased by one when it appears, and the value corresponding to the name of the Zodiac will be increased by one
z_num[zodiac_name[n]] += 1 # The user's current constellation will be incremented once it appears, and the value corresponding to the constellation name will be incremented by one
# Output statistics of zodiac and constellation
for each_key in cz_num.keys(): # . keys() retrieves all keys in the dictionary
print('the Chinese zodiac %s have %d individual' % (each_key, cz_num[each_key]))
for each_key in z_num.keys():
print('constellation %s have %d individual' % (each_key, z_num[each_key]))
result:
Please enter year: 2018 Please enter month: 1 Please enter date: 3 Your constellation is Capricorn 2018 The zodiac sign in is dog There are 0 Zodiac monkeys There are 0 Zodiac chickens Zodiac dog has 1 There are 0 Zodiac pigs There are 0 Zodiac rats There are 0 Zodiac cattle There are 0 Zodiac tigers There are 0 Zodiac rabbits There are 0 Zodiac dragons Zodiac snakes have 0 There are 0 Zodiac horses There are 0 Zodiac sheep Capricorn has one constellation There are 0 constellations in Aquarius There are 0 constellations in Pisces Aries has 0 constellations There are 0 constellations in Taurus There are 0 constellations in Gemini There are 0 constellations in cancer There are 0 constellations in Leo Virgo has 0 constellations There are 0 constellations in Libra There are 0 constellations in Scorpio There are 0 constellations in Sagittarius Please enter year: 2021 Please enter month: 3 Please enter date: 25 Your constellation is Aries 2021 The zodiac sign in is ox There are 0 Zodiac monkeys There are 0 Zodiac chickens Zodiac dog has 1 There are 0 Zodiac pigs There are 0 Zodiac rats The zodiac cow has one There are 0 Zodiac tigers There are 0 Zodiac rabbits There are 0 Zodiac dragons Zodiac snakes have 0 There are 0 Zodiac horses There are 0 Zodiac sheep Capricorn has one constellation There are 0 constellations in Aquarius There are 0 constellations in Pisces There is one constellation in Aries There are 0 constellations in Taurus There are 0 constellations in Gemini There are 0 constellations in cancer There are 0 constellations in Leo Virgo has 0 constellations There are 0 constellations in Libra There are 0 constellations in Scorpio There are 0 constellations in Sagittarius Please enter the year:
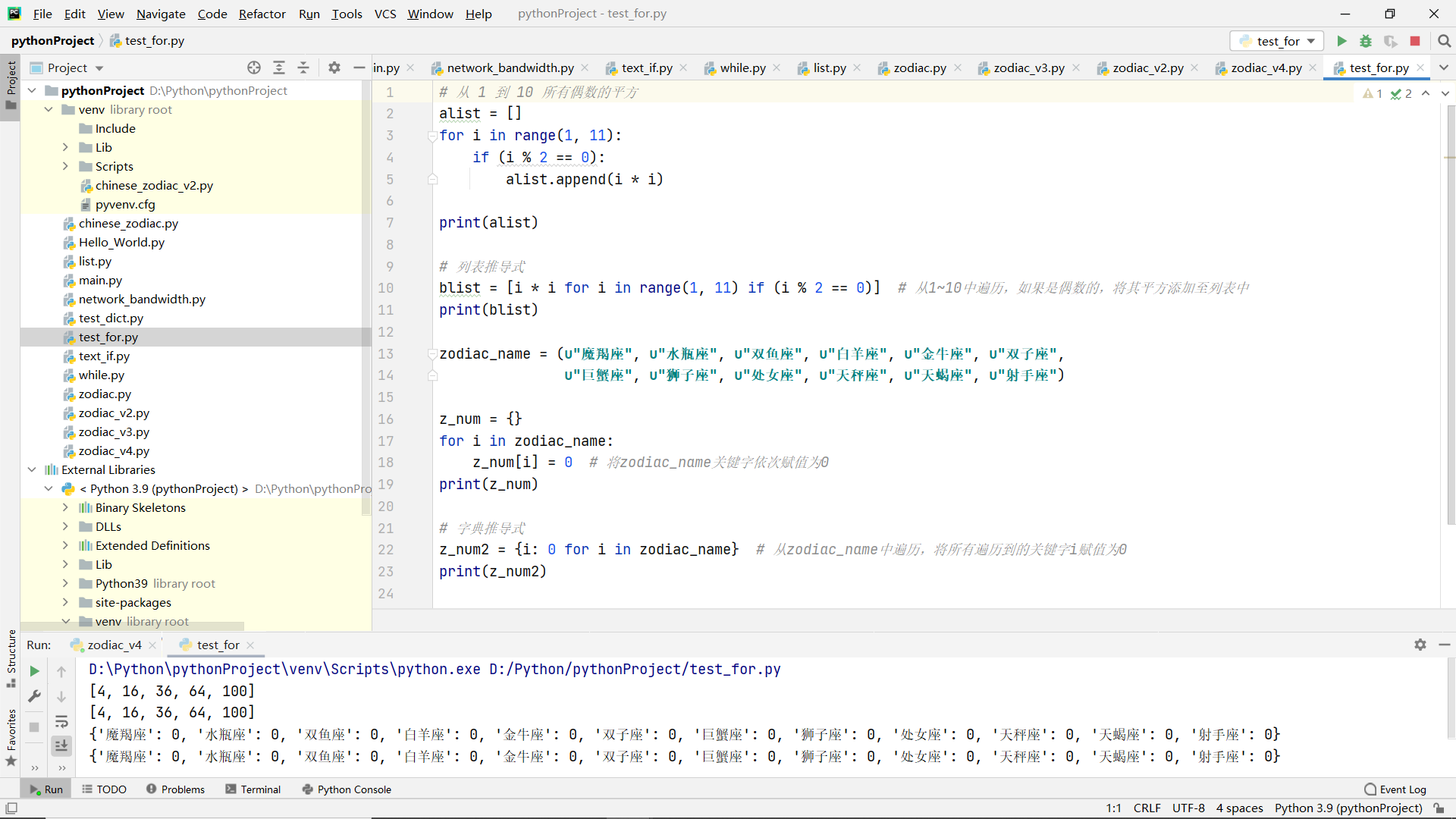
List derivation and dictionary derivation
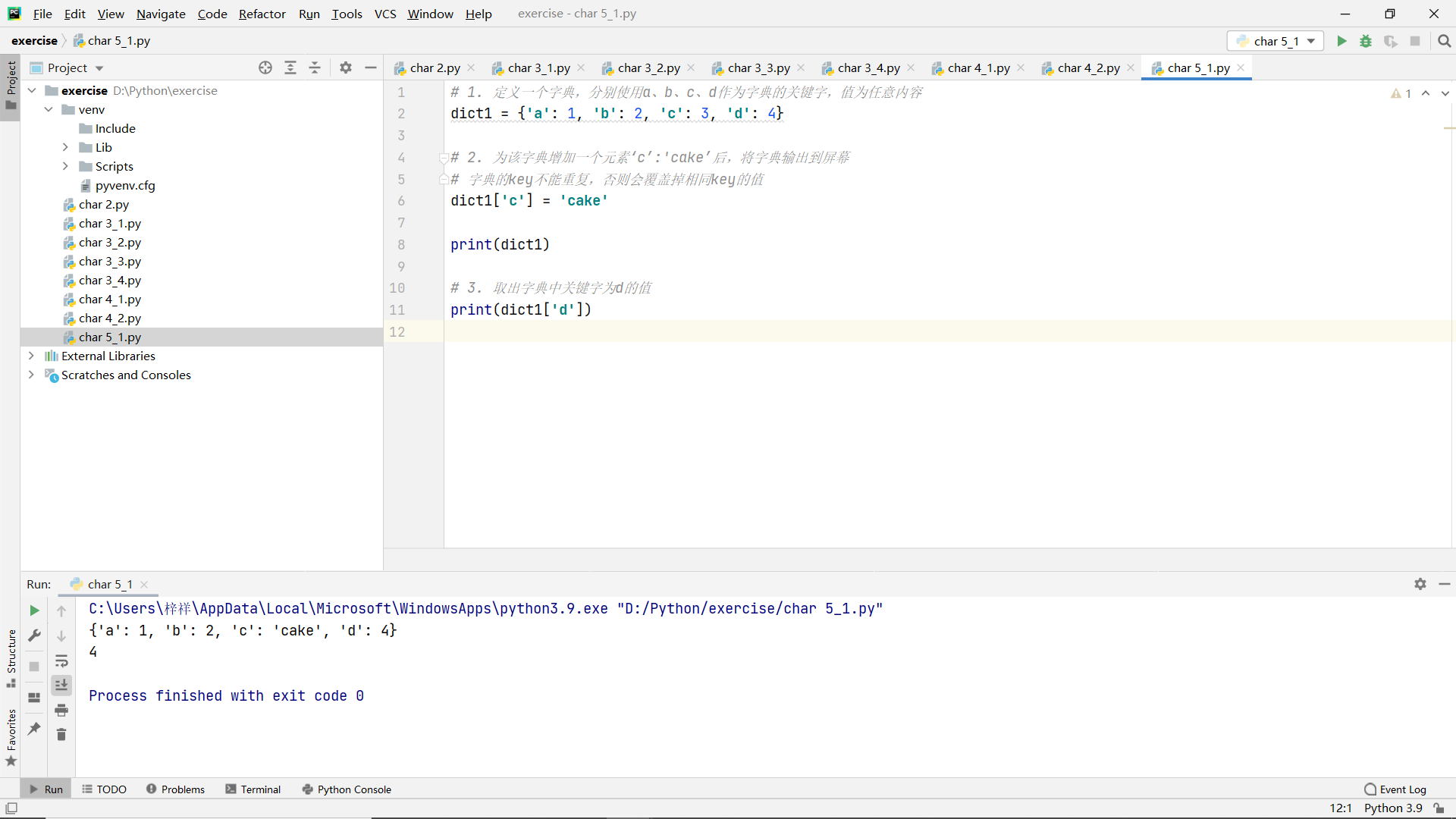
exercises
Practice using a dictionary
Title:
- Define a dictionary. Use a, b, c and d as the keywords of the dictionary, and the value is any content
- After adding an element 'c': 'cake' to the dictionary, output the dictionary to the screen
- Take out the value with keyword d in the dictionary
code:
Exercise 2 use of sets
Title:
- Assign each character in the string hello to a set and output the set to the screen '
code:
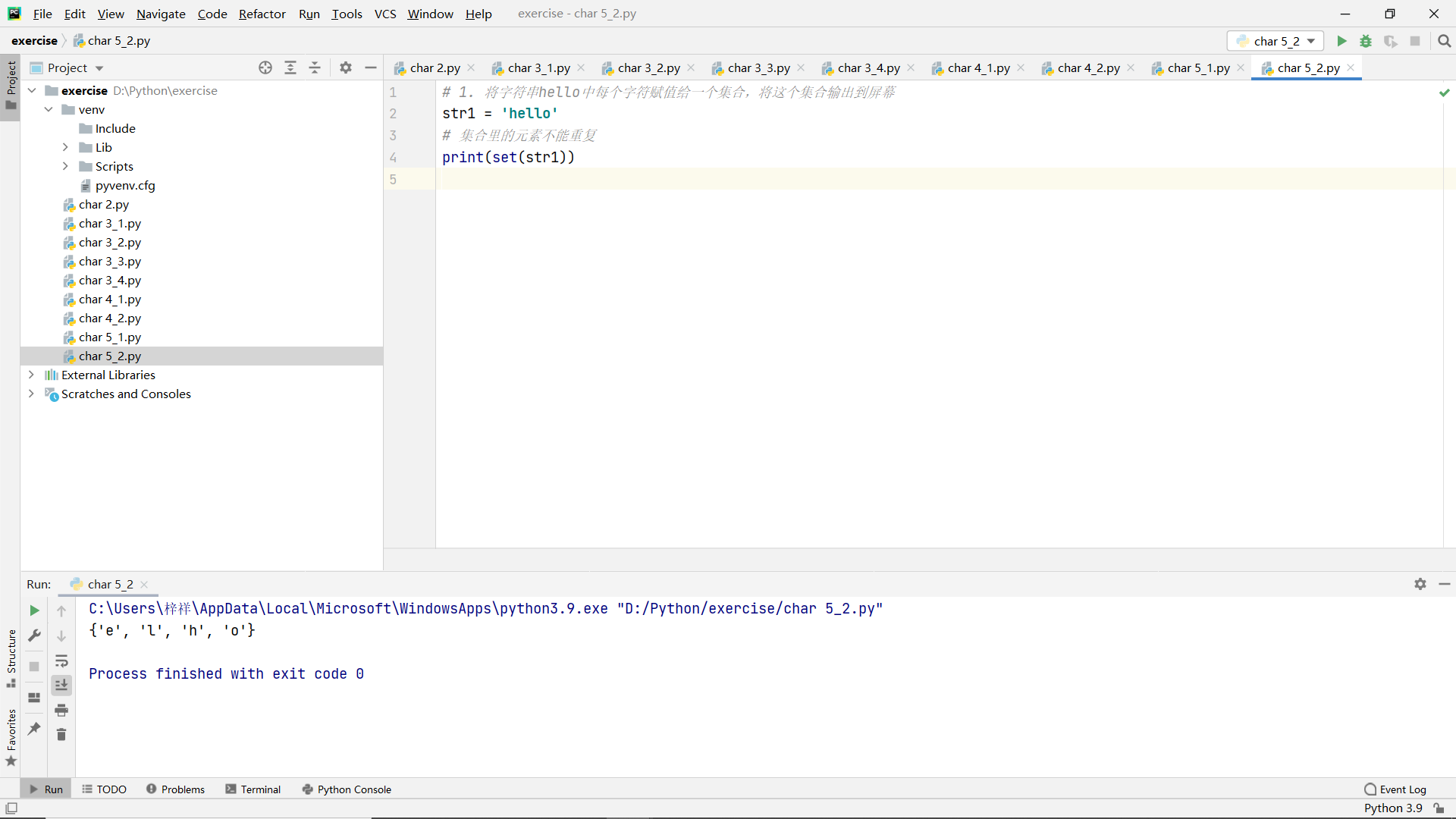
Chapter VI input and output of documents

Built in functions for files
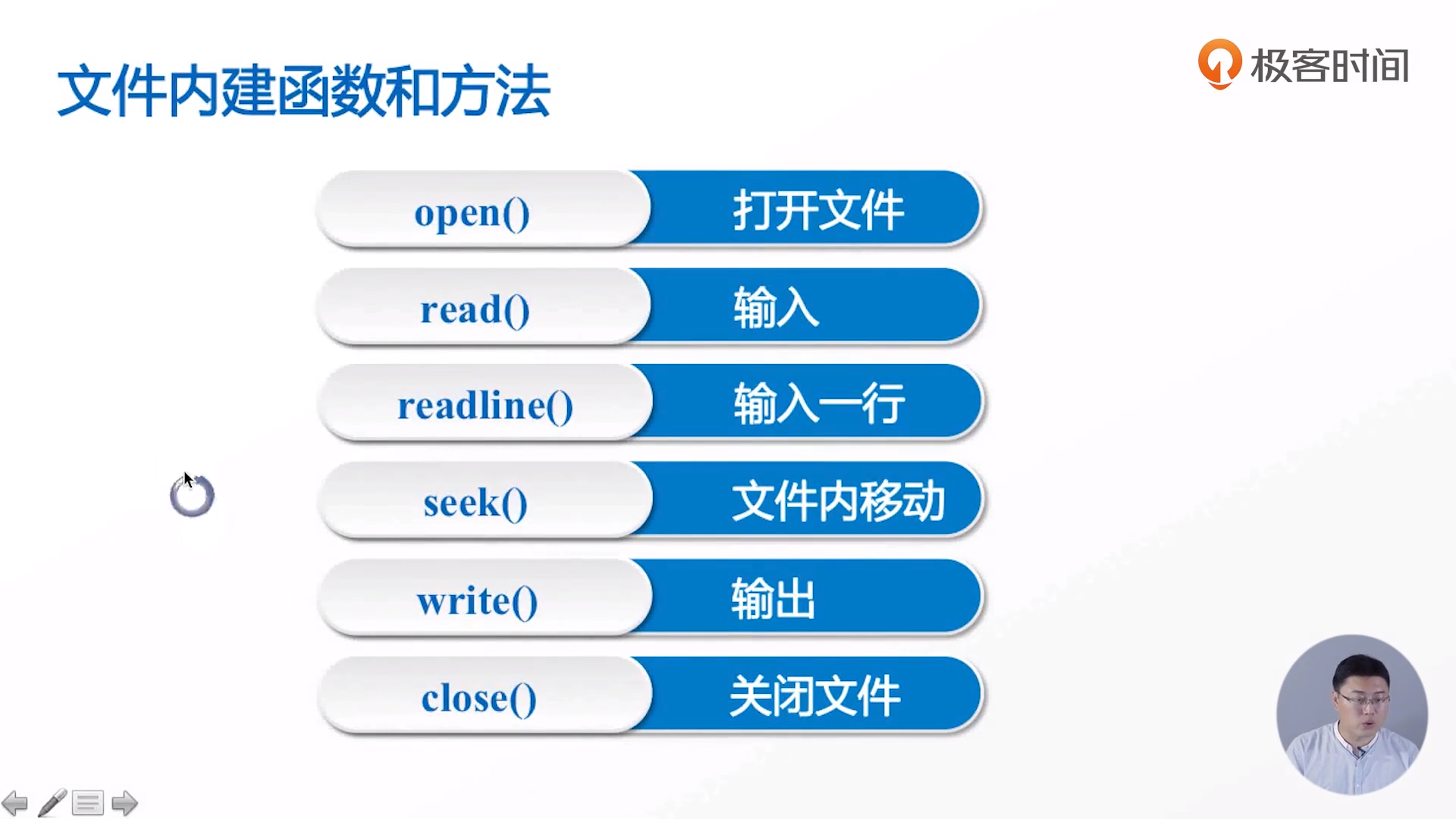
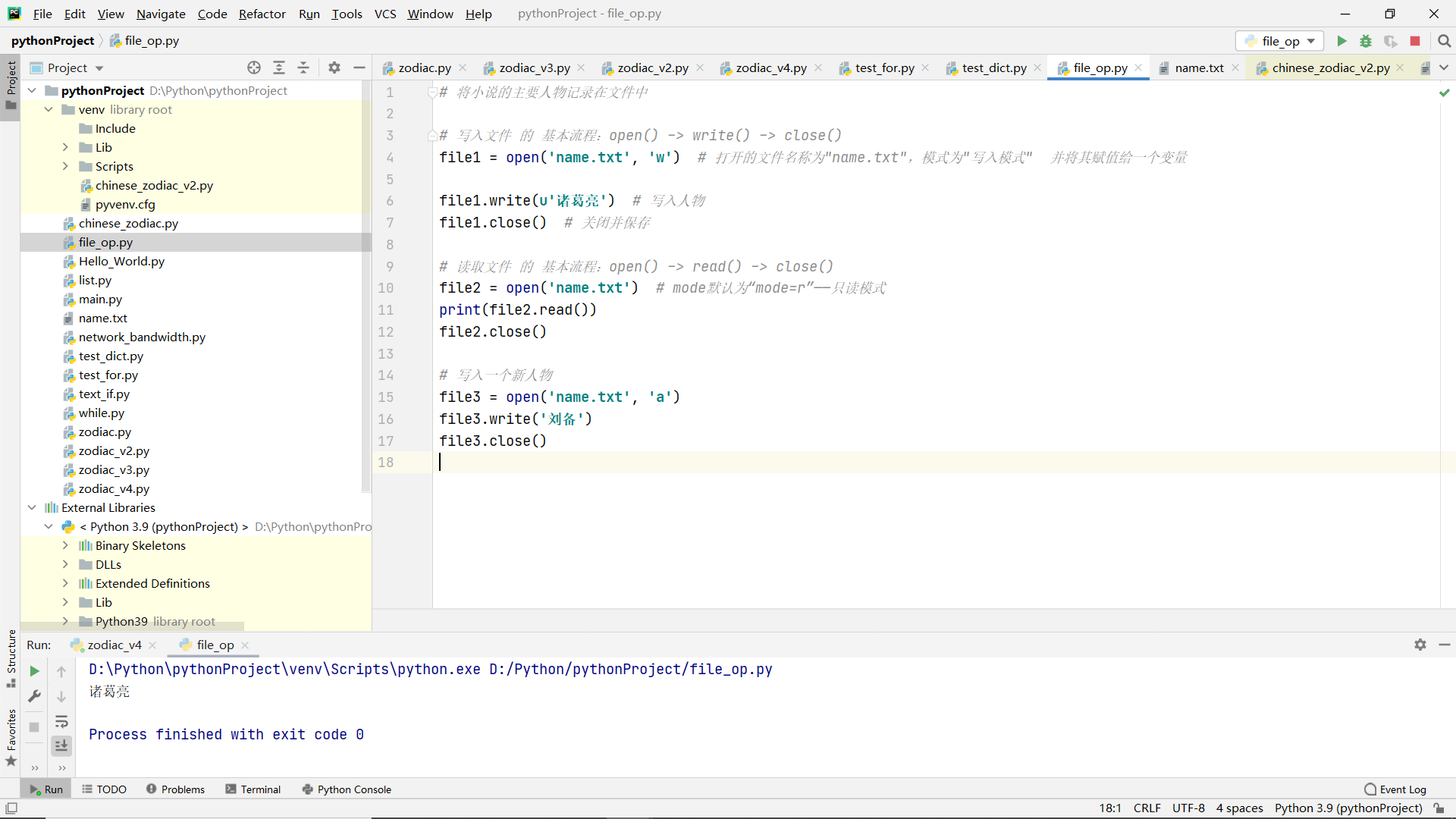
Common operations of files
code:
# # Record the main characters of the novel in a file
#
# # Basic process of writing files: open() - > write() - > close()
# file1 = open('name.txt', 'w') # The open file name is "name.txt", the mode is "write mode", and it is assigned to a variable
#
# file1.write(u'Zhuge Liang') # Write character
# file1.close() # Close and save
#
# # Basic process of reading files: open() - > read() - > close()
# file2 = open('name.txt') # Mode defaults to "mode=r" - read-only mode
# print(file2.read())
# file2.close()
#
# # Write a new character
# file3 = open('name.txt', 'a')
# file3.write('liu Bei ')
# file3.close()
# # Read one of multiple rows
# file4 = open('name.txt')
# print(file4.readline())
#
# # Read each line and operate at the same time (read in line mode and operate line by line)
# file5 = open('name.txt')
# for line in file5.readlines(): # readlines read line by line
# print(line)
# print('=====')
# Perform an operation, return to the beginning of the file after the operation is completed, and then operate on the file again
file6 = open('name.txt')
file6.tell() # Tell the user where the "file pointer" is
# Pointer function: when there is no manual operation, the program will record the current operation position, and then continue to operate backward
print('The location of the current file pointer %s' % file6.tell())
print('A character is currently read. The content of the character is %s' % file6.read(1)) # Only 1 character of the file is read
print('The location of the current file pointer %s' % file6.tell())
# Requirement: after the operation is completed, go back to the beginning of the file and operate again
# Manipulation pointer
# The first parameter: offset position (offset). The second parameter: 0 -- offset from the beginning of the file, 1 -- offset from the current position, and 2 -- offset from the end of the file
file6.seek(0) # file6.seek(5, 0) is offset 5 positions backward from the beginning of the file
print('We did seek operation')
print('The location of the current file pointer %s' % file6.tell())
# Read one character again
print('A character is currently read. The content of the character is %s' % file6.read(1)) # Only 1 character of the file is read
print('The location of the current file pointer %s' % file6.tell())
file6.close()
result:
Current file pointer position 0 A character is currently read. The content of the character is a Current file pointer position 1 We did seek operation Current file pointer position 0 A character is currently read. The content of the character is a Current file pointer position 1
Exercise 1 creating and using files
Title:
- Create a file and write the current date
- Open the file again, read the first 4 characters of the file and exit
code:
# 1. Create a file and write the current date
import datetime
now = datetime.datetime.now() # The now variable stores the current time
new_file = open('date.txt', 'w')
new_file.write(str(now))
new_file.close()
# 2. Open the file again, read the first 4 characters of the file and exit
again_file = open('date.txt')
print(again_file.read(4)) # Print read 4 characters
print(again_file.tell()) # File pointer, indicating that 4 characters have been read
again_file.close()
result:
2021 4
Chapter VII errors and exceptions
Anomaly detection and handling

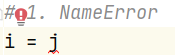
Common errors
1. NameError

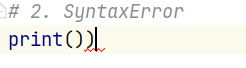
2. SyntaxError

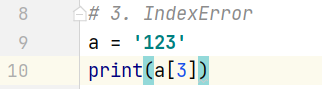
3. IndexError

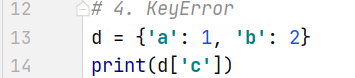
4. KeyError

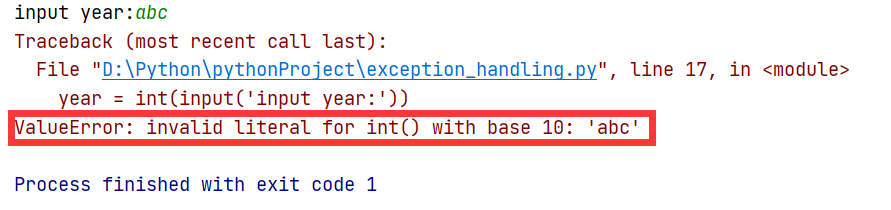
5. ValueError

6. AttributeError


7. ZeroDivisionError

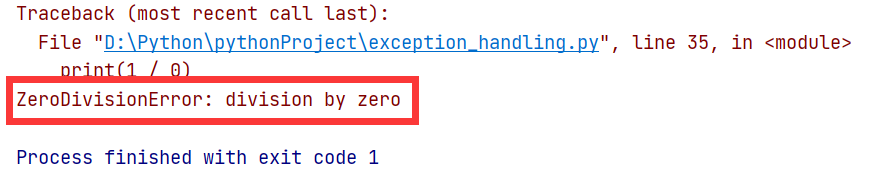
8. TypeError


Catch all errors
except Exception

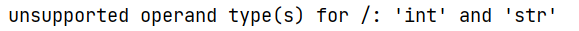
exception handling


except can catch multiple exceptions
Format:

be careful:
Multiple errors should be enclosed in parentheses as a parameter.
Additional error messages are displayed after successful capture


Note: it is generally used when debugging programs
Throw exception manually
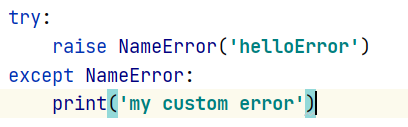
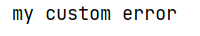
finally
No matter whether there is an error or not, it should be executed.

summary

exercises
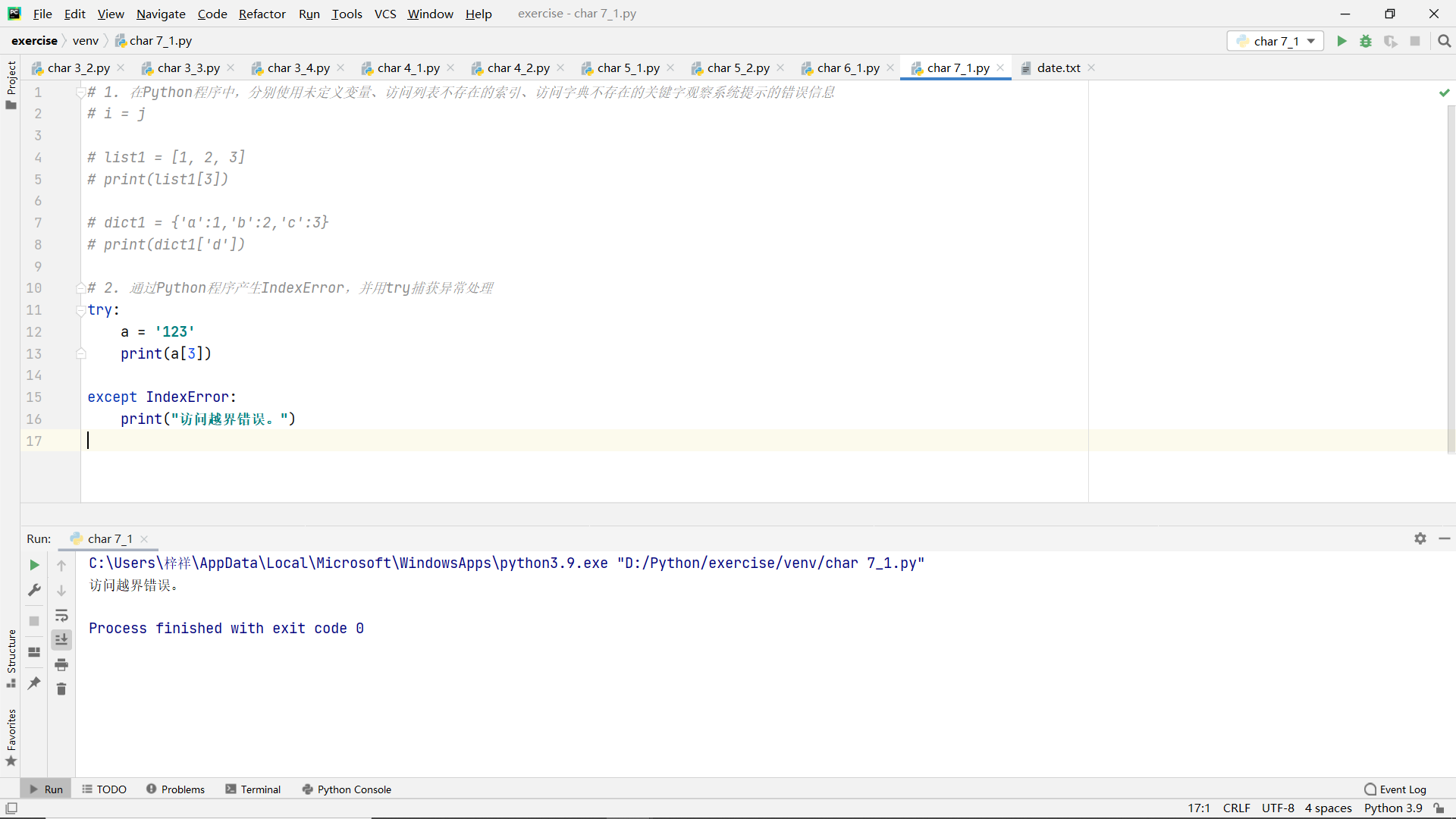
Exercise 1 exception
Title:
- In Python programs, use undefined variables, indexes that do not exist in the access list, and keywords that do not exist in the access dictionary to observe the error messages prompted by the system
- Generate IndexError through Python program and catch exception handling with try
code:
Chapter 8 function
Function definition and common operations
No function version:
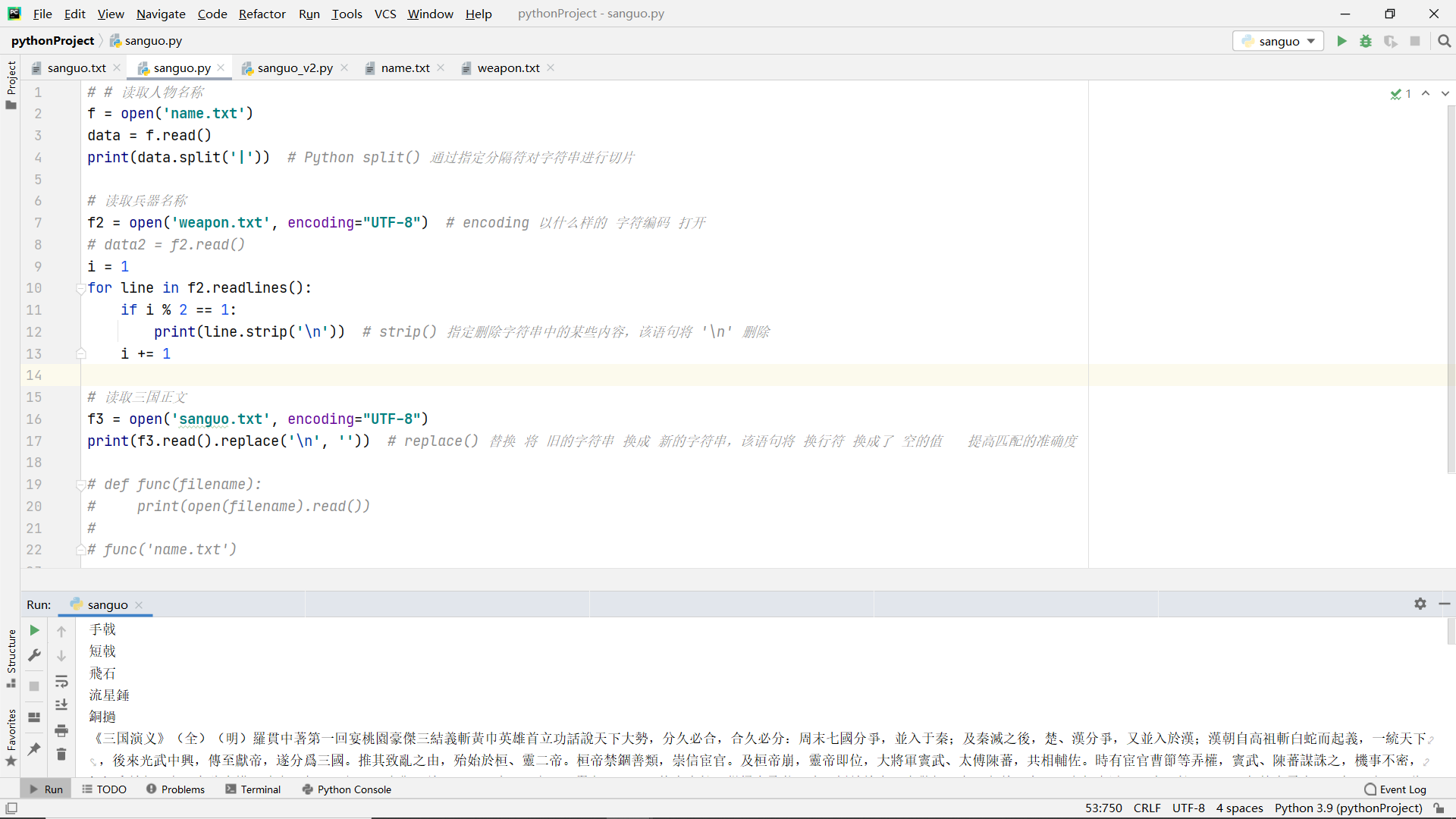
Function version:
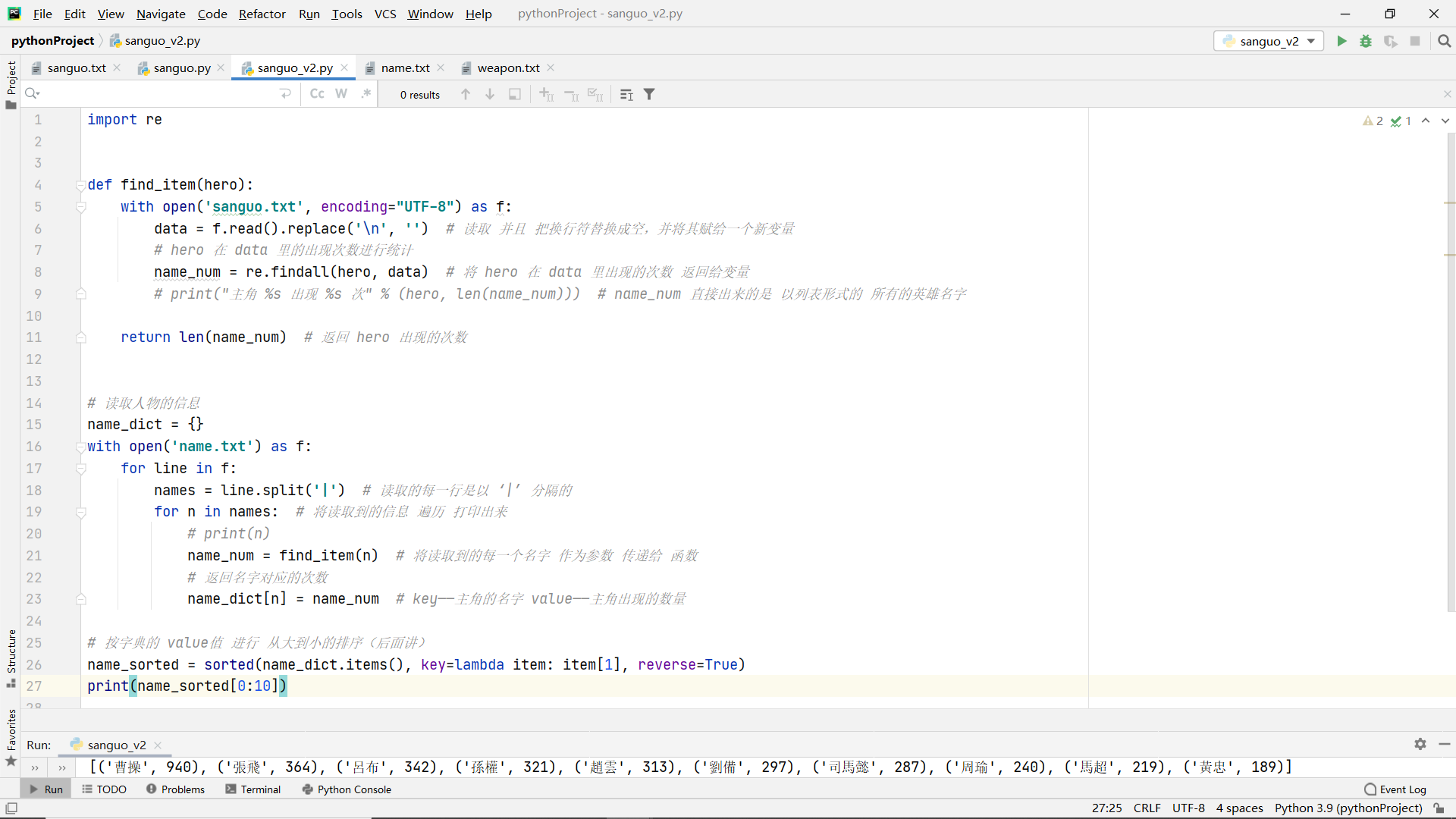
Full version:
import re
def find_main_characters(character_name):
with open('sanguo.txt', encoding='UTF-8') as f:
data = f.read().replace("\n", "")
name_num = re.findall(character_name,data)
return character_name, len(name_num)
name_dict = {}
with open('name.txt') as f:
for line in f:
names = line.split('|')
for n in names:
char_name, char_number = find_main_characters(n)
name_dict[char_name] = char_number
weapon_dict = {}
with open('weapon.txt', encoding="UTF-8") as f: # Read by row by default
i = 1
for line in f:
if i % 2 == 1:
weapon_name, weapon_number = find_main_characters(line.strip('\n')) # Read delete this line of '\ n'
weapon_dict[weapon_name] = weapon_number
i = i + 1
name_sorted = sorted(name_dict.items(), key=lambda item: item[1], reverse=True)
print(name_sorted[0:10])
weapon_sorted = sorted(weapon_dict.items(), key=lambda item: item[1], reverse=True)
print(weapon_sorted[0:10])
result:

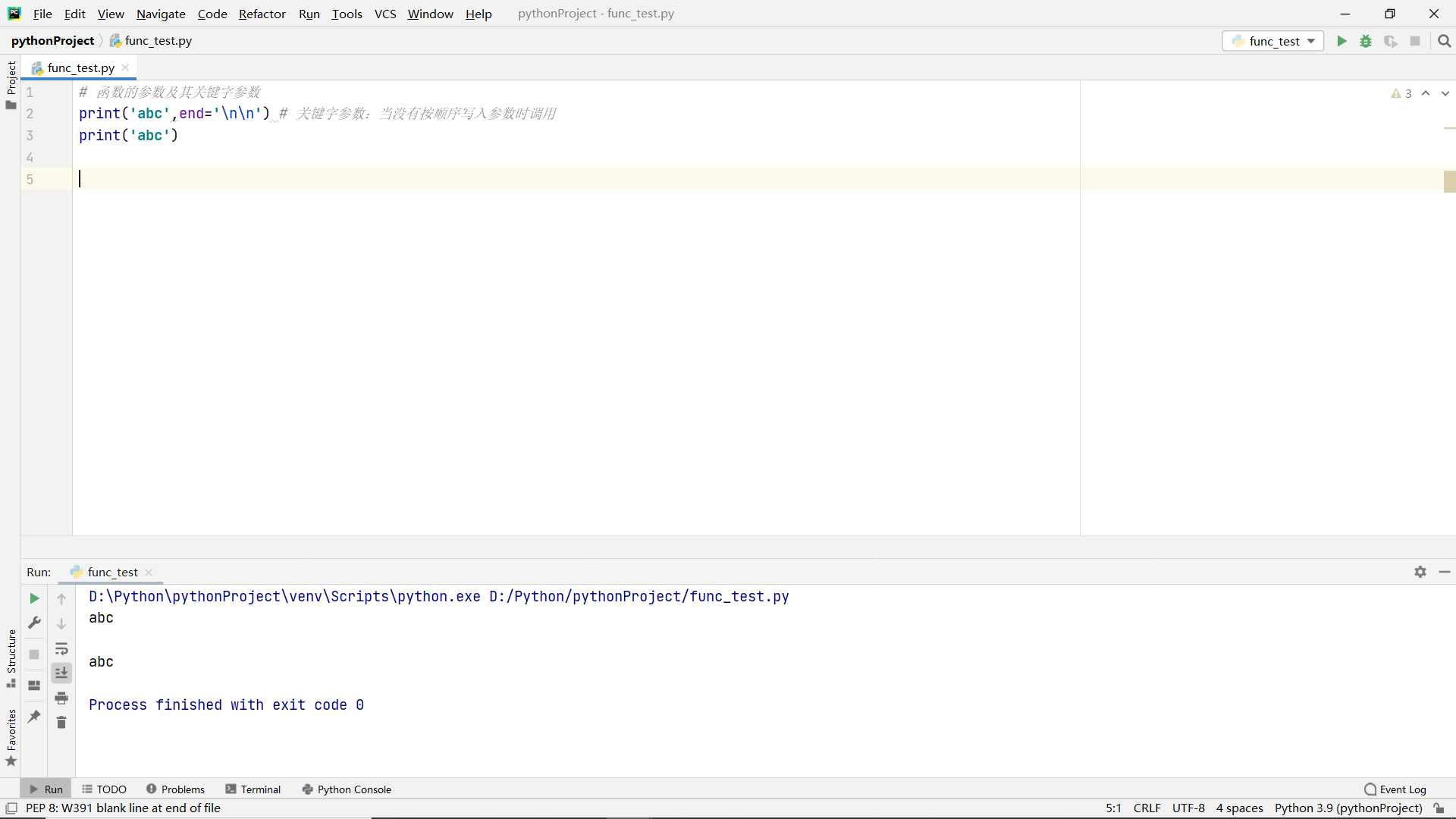
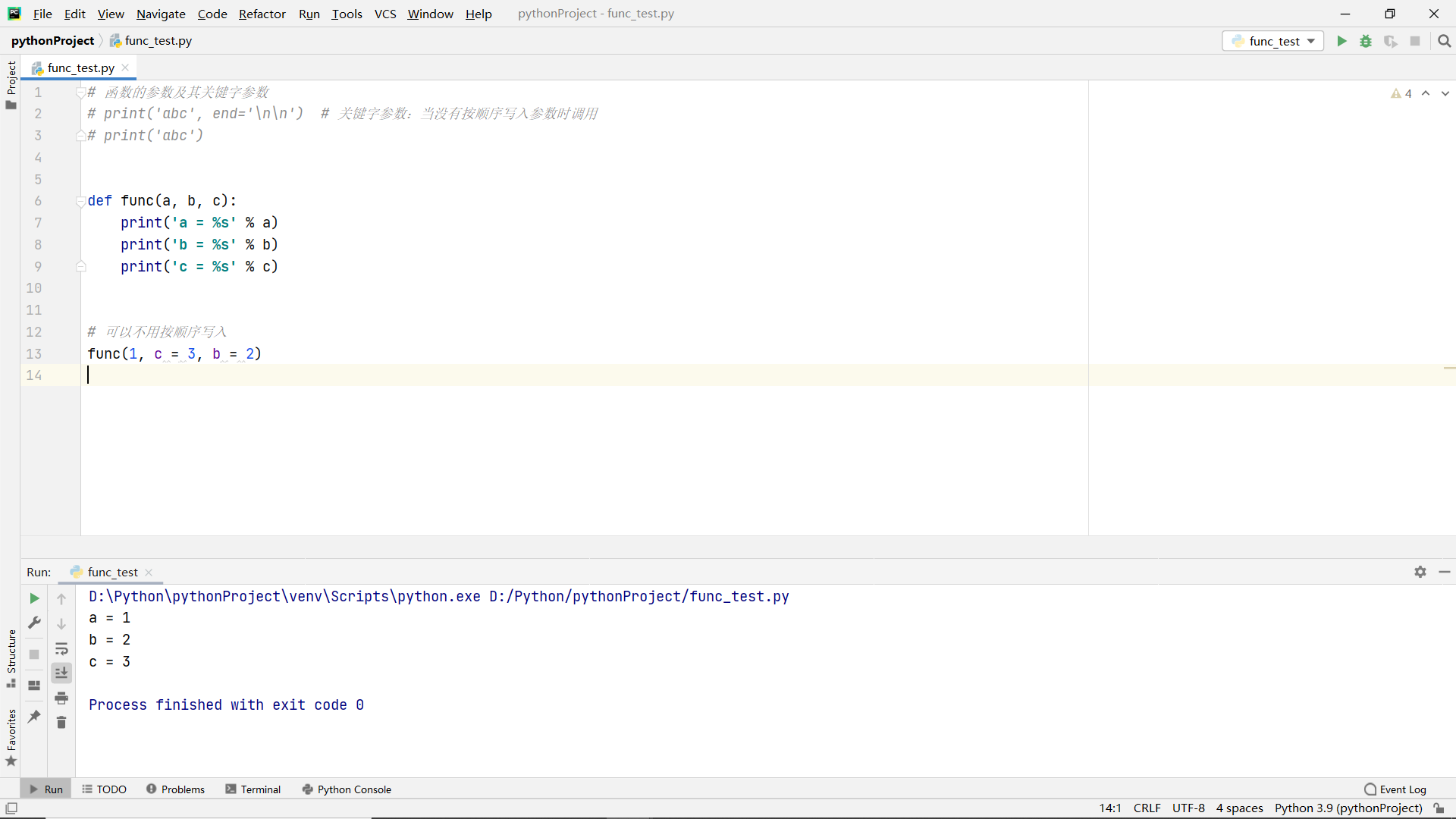
Variable length arguments to functions
Keyword parameters
effect:
Called when parameters are not written in order.
advantage:
- It is not necessary to write parameters in order
- More specifically, what is the meaning of the input parameters
code:
Variable length parameter
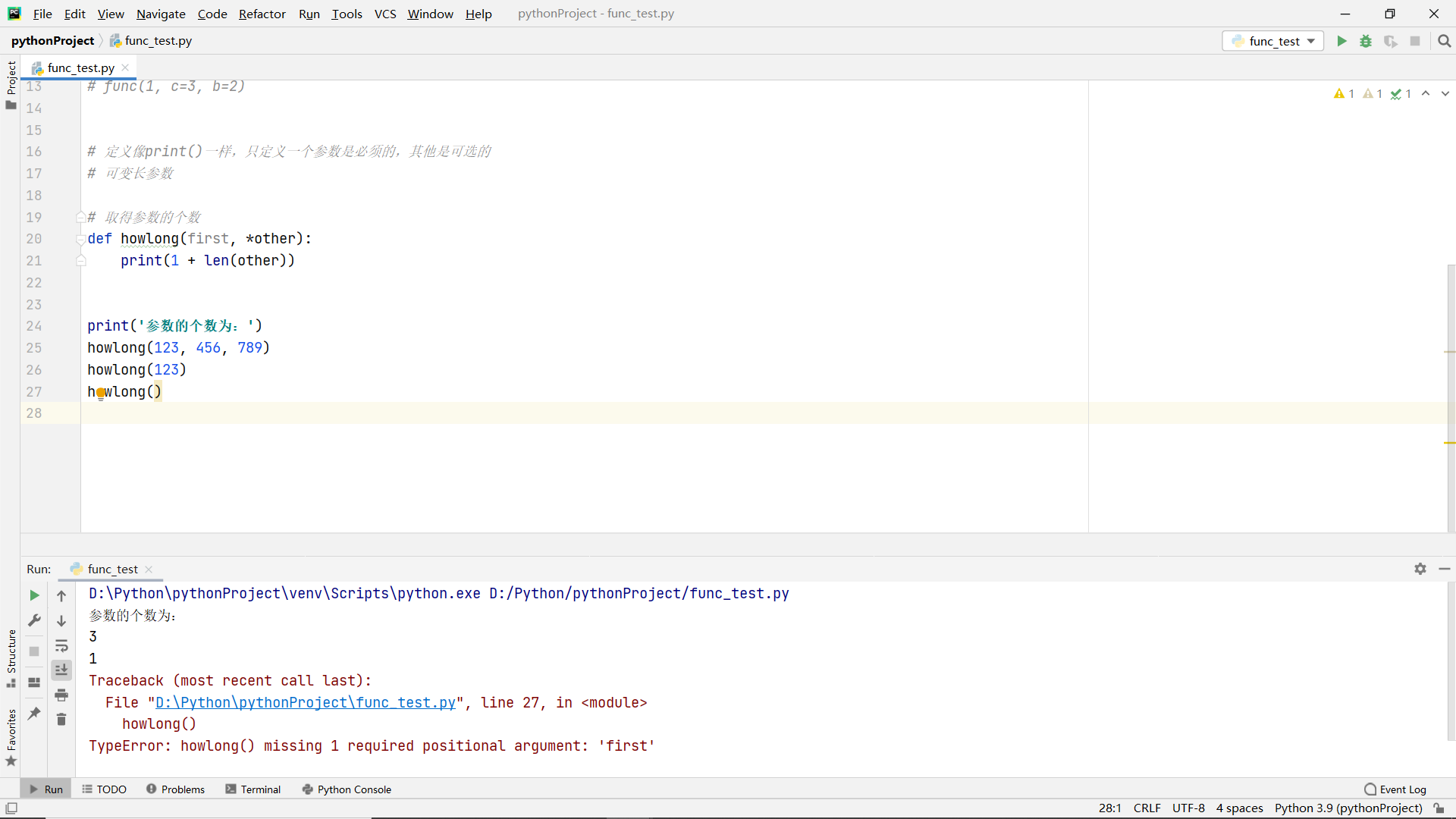
Variable scope of function
global variable
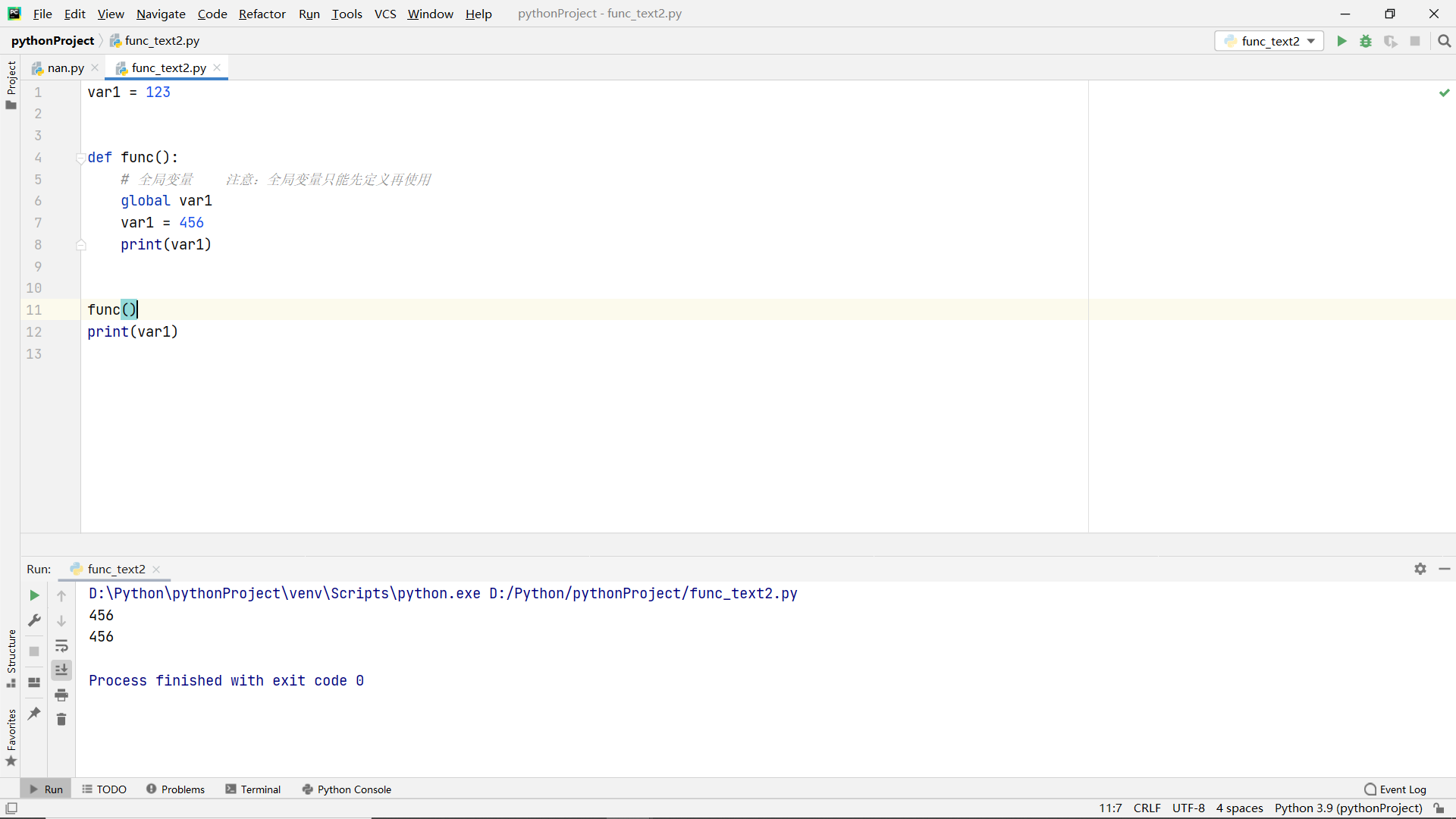
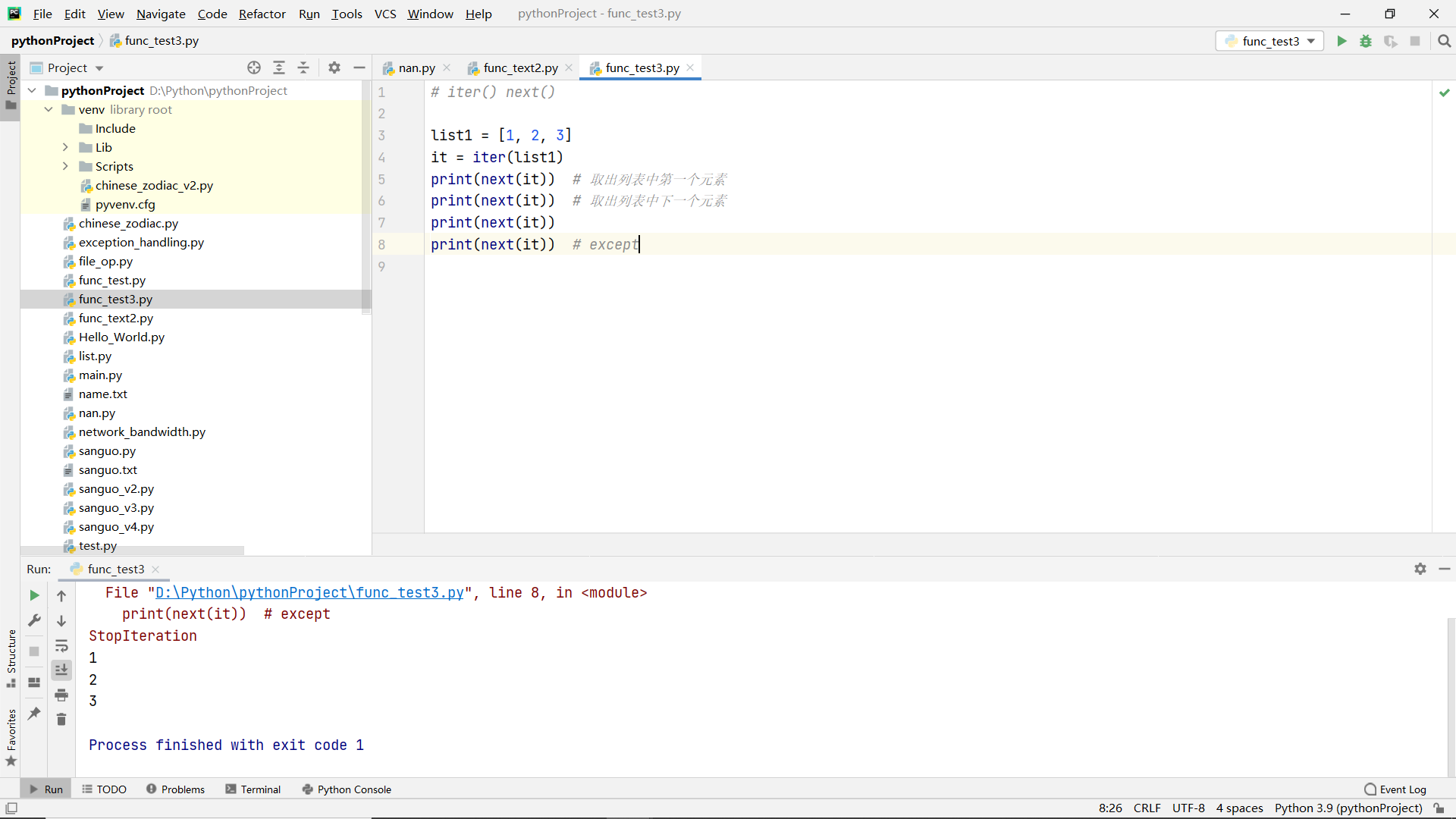
Iterators and generators for functions
iterator
function
Take each element in the list and process each element in turn. This method is called iteration. The function that can implement this method is called iterator
Two functions (Methods)
iter() and next()
generator
definition
An iterator made by yourself is called a generator.
Iterator with yield
Custom iterator
Code 1:
for i in range(10, 20, 0.5):
print(i)
An error will be reported. The range() function does not allow the float number as its step size.
Code 2:
# Implement a range that supports decimal step growth
def frange(start, stop, step):
x = start
while x < stop:
yield x # When yield runs to yield, it will pause and record the current position. When next() is called again, it will return a value through the current position
x += step
for i in frange(10, 20, 0.5):
print(i)
result:
10 10.5 11.0 11.5 12.0 12.5 13.0 13.5 14.0 14.5 15.0 15.5 16.0 16.5 17.0 17.5 18.0 18.5 19.0 19.5
Lambda expression
effect
Simplify functions.
code:
def true(): return True # be equal to def true():return True # be equal to lambda: True
def add(x, y): return x + y # be equal to def add(x, y):return x + y # be equal to lambda x, y:x + y # The parameter is x and Y returns x+y
Lambda returns the expression of lambda:
<function at 0x0000015D077E20D0>
purpose
Code 1:
lambda x: x <= (month, day) # The parameter is: X, and the returned value is: x < = (month, day)
# Convert to function
def find(x):
return x <= (month, day)
Code 2:
lambda item: item[1] # The parameter is: item, and the returned value is: item[1]
# Convert to function
def find2(item): # Pass in a dictionary element and take the value of the dictionary
return item[1]
adict = {'a': '123', 'b': '456'}
for i in adict.items():
print(find2(i)) # Take dictionary value
Usage of the Python dictionary items() function.
Python built-in functions
filter
Function:
filter(function, sequence)
Filter the number of funciton s in the sequence
code:
a = [1, 2, 3, 4, 5, 6, 7] b = list(filter(lambda x: x > 2, a)) # The number in filter a that satisfies more than 2 print(b)
result:
[3, 4, 5, 6, 7]
It must be converted to list, otherwise lambda will not be executed
map
Function:
map(function, sequence)
Press function to process the values in sequence
Code 1:
c = [1, 2, 3] map(lambda x: x, c) # Return the values in c to x in turn d = list(map(lambda x: x, c)) print(d) map(lambda x: x + 1, c) # Return the values in c + 1 in turn e = list(map(lambda x: x + 1, c)) print(e)
result:
[1, 2, 3] [2, 3, 4]
Code 2:
a = [1, 2, 3] b = [4, 5, 6] map(lambda x, y: x + y, a, b) c = list(map(lambda x, y: x + y, a, b)) print(c)
result:
[5, 7, 9]
The corresponding items are added and output in turn.
reduce
Function:
reduce(function, sequence[, initial])
Operate the elements of the sequence and the initial value in a functional way.
code:
from functools import reduce total = reduce(lambda x, y: x + y, [2, 3, 4], 1) # 1 and the first element in the list operate according to func print(total) # ((1+2)+3)+4
result:
10
zip
Function 1: vertical integration
code:
exchange = zip((1, 2, 3), (4, 5, 6))
for i in exchange:
print(i)
# The vertical integration is compared with the "matrix transformation" in linear algebra
result:
(1, 4) (2, 5) (3, 6)
(1, 2, 3)
(4, 5, 6)
(1, 4)
(2, 5)
(3, 6)
Function 2: key and value exchange in the dictionary
code:
dicta = {'a': '123', 'b': '456'}
dictb = zip(dicta.values(), dicta.keys())
# ('a', 'b'), ('1', '2') --> ('a', '1'), ('b', '2')
print(dictb)
print(dict(dictb)) # Its type needs to be cast to dict
result:
<zip object at 0x0000016A531F7E40>
{'123': 'a', '456': 'b'}
Definition of closure
closure
definition:
The variables in the external function are referenced by the internal function, which is called "closure"
code:
def func():
a = 1
b = 2
return a + b
def sum(a):
def add(b):
return a + b # int returned
# Returns the function name of the inner function
return add # The returned function is function, add is the function name of the internal function, and refers to the function of add
num1 = func()
num2 = sum(2) # num2 is equivalent to the internal function add in the sum external function
print(num2(4)) # Call num2 as a function (equivalent to add()) and pass in the second parameter
# print(type(num1)) --- int
# print(type(num2)) --- function
result:
6
add is the function name or a reference to the function
add() is a call to a function
Counter
Function:
Implement a counter, which counts + 1 every time it is called
Code 1:
# Implement a counter, which counts + 1 every time it is called
def counter():
cnt = [0] # Define a list, only one element is 0
def add_one():
cnt[0] += 1 # The counter is + 1 each time the function is called
return cnt[0] # Returns the added value
return add_one # Return inner function
num1 = counter() # Assign the result returned by the counter() function to the variable num1
print(num1) # Output num1. This function is equivalent to add_one
print(num1()) # Output add_ Call the one function
print(num1())
print(num1())
print(num1())
print(num1())
result:
1 2 3 4 5
Code 2:
# Implement a counter. According to the specified initial value, the count will be + 1 every time it is called
def counter(FIRST=0): # If no parameter is passed in, it starts with 0 by default
cnt = [FIRST] # Define a list, and only one element is FIRST
def add_one():
cnt[0] += 1 # The counter is + 1 each time the function is called
return cnt[0] # Returns the added value
return add_one # Return inner function
num5 = counter(5)
num10 = counter(10)
print(num5())
print(num5())
print(num5())
print(num10())
print(num10())
result:
6 7 8 11 12
Use of closures
Case: mathematical operation
Closure:
# a * x + b = y
# To ensure that a and B remain unchanged, closures can be used only when x changes
def a_line(a, b):
def arg_y(x):
return a * x + b
return arg_y
# a = 3, b = 5
# x = 10, y = ?
# x = 20, y = ?
line1 = a_line(3, 5) # line1 is equivalent to arg_y
print(line1(10)) # line1(10) is equivalent to arg_y(10)
print(line1(20)) # line1(20) is equivalent to arg_y(20)
# Find another line
# a = 5, b = 10
line2 = a_line(5, 10)
print(line2(10))
print(line2(20))
result:
35 65 60 110
The external function is a constant quantity, and the internal function is a variable quantity.
Common function writing method:
def func1(a,b,x): return a * x + b
The three values of a, B and X need to be passed in every time, which is not concise and elegant enough
lambda:
def a_line2(a, b):
return lambda x: a * x + b
# a = 3, b = 5
# x = 10, y = ?
# x = 20, y = ?
new_line1 = a_line2(3, 5)
print(new_line1(10))
print(new_line1(20))
More concise and elegant!
The difference between closure and function
- Function transfer variable, closure transfer function;
- Closures have fewer arguments than function calls;
- Closure code is more elegant.
Definition of decorator
Description:
If you want to add some functions to the function, but do not want to add corresponding code inside the function, you can use the "decorator".
time library
sleep() method
Function: stop for a few seconds during operation
import time time.sleep(3) # Stop for 3s
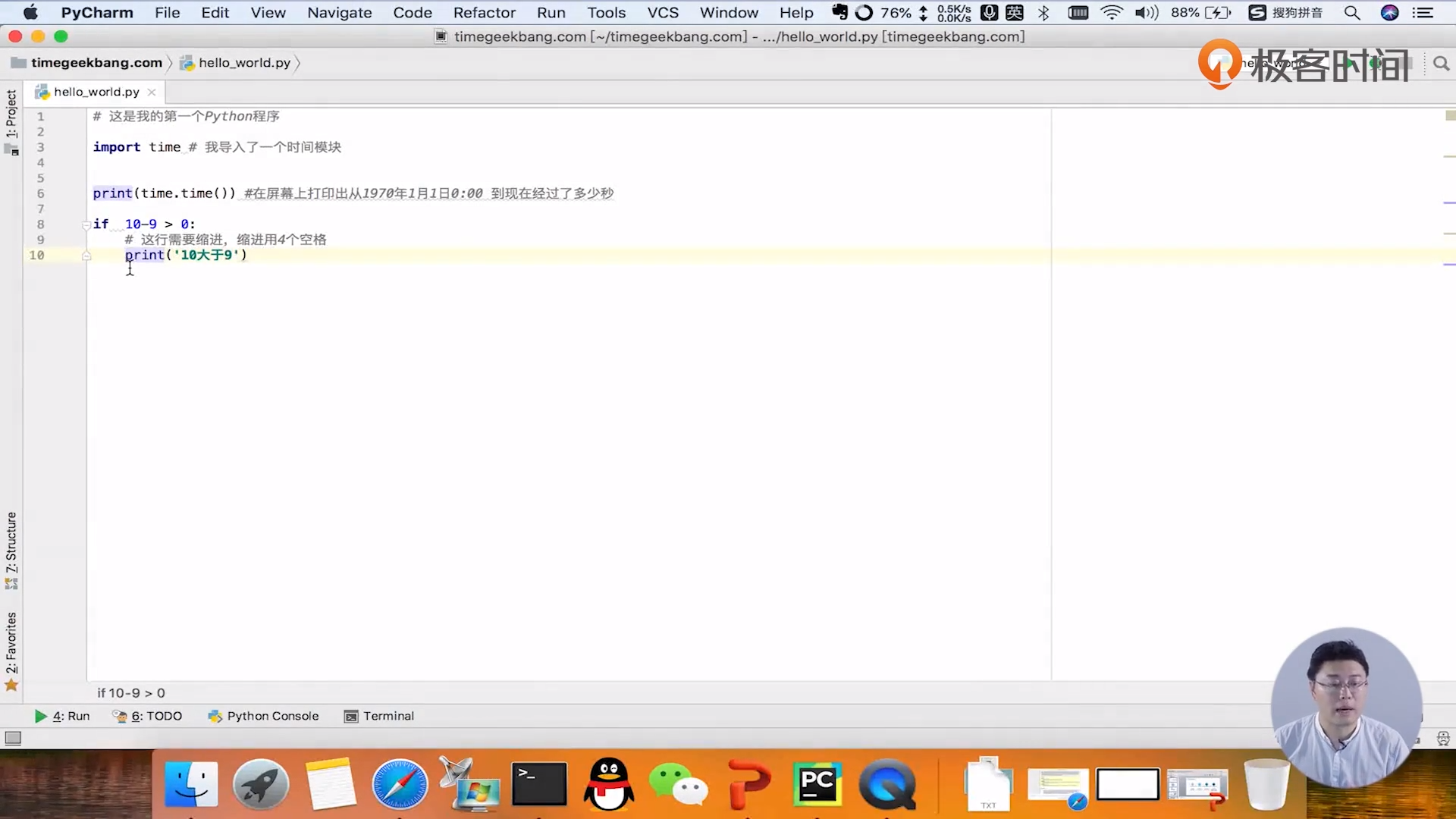
time() method
Function:
Count the time from January 1, 1970 to now.
code:
import time print(time.time()) # How many seconds have you walked since January 1, 1970
result:
1611718601.273848
case
Statistical function running time:
# How long did the statistical function run
def i_can_sleep():
time.sleep(3)
start_time = time.time()
i_can_sleep()
stop_time = time.time()
print('The function is running %s second' % (stop_time - start_time))
Decorator
Function:
Do repetitive things only once.
The difference between closures and decorators:
- Closures pass in variables, and internal functions reference variables
- The decorator passes in a function, and the internal function references a function
code:
def timer(func):
def wrapper():
start_time = time.time()
func()
stop_time = time.time()
print("Run time is %s second" % (stop_time - start_time))
return wrapper
# How long did the statistical function run
@timer # Syntax: sugar, timer -- decorating function i_can_sleep -- decorated function, and additional code is encapsulated in the decorated function
def i_can_sleep():
time.sleep(3)
i_can_sleep() # Equivalent to num = timer (i_can_sleep()) num ()
result:
The running time is 3.0005228519439697 second
Use of decorators
Adding decorators to functions with arguments
code:
# Adding decorators to functions with arguments
def tips(func):
def nei(a, b):
print('start')
func(a, b)
print('stop')
return nei
# Implement addition
@tips
def add(a, b):
print(a + b)
# Implement subtraction
@tips
def sub(a, b):
print(a - b)
print(add(4, 5))
print(sub(4, 5))
result:
start 9 stop None start -1 stop None
Decorator belt parameters
Code 1:
# Decorator belt parameters
# The decorator varies for different functions -- bring parameters to the decorator
def new_tips(argv):
def tips(func):
def nei(a, b):
print('start %s' % argv)
func(a, b)
print('stop')
return nei
return tips
@new_tips('add')
def add(a, b):
print(a + b)
@new_tips('sub')
def sub(a, b):
print(a - b)
print(add(4, 5))
print(sub(4, 5))
result:
start add 9 stop None start sub -1 stop None
Code 2:
# Decorators take not only parameters, but also function names
def new_tips(argv):
def tips(func):
def nei(a, b):
print('start %s %s' % (argv, func.__name__)) # Name of the output function
func(a, b)
print('stop')
return nei
return tips
@new_tips('add_module')
def add(a, b):
print(a + b)
@new_tips('sub_module')
def sub(a, b):
print(a - b)
print(add(4, 5))
print(sub(4, 5))
result:
start add_module add 9 stop start sub_module sub -1 stop
Benefits of decorators
- When calling a function, you don't need to write the corresponding modification code repeatedly, and you can put it in the decorator;
- Decorator code is easy to reuse - @ decorator name.
exercises
Exercise 1 defines a decorator for printing the time of function execution
- Count the time when the function starts and ends execution
- Extension exercise: pass in the timeout for the decorator, and exit after the function execution exceeds the specified time
code:
# 1. Count the time when the function starts and ends execution
import time
def timer(func):
def nei():
print('start time %s' % time.time())
func()
print('end time %s' % time.time())
return nei
@timer
def i_can_sleep():
time.sleep(3)
i_can_sleep()
result:
start time 1612241463.787381 end time 1612241466.787973
Exercise 2 define the decorator to realize the function of displaying the execution results in different colors
- Pass parameters to the decorator, and obtain the output color through the passed parameters
- The print() output of the decorated function is output according to the color obtained by the decorator
code:
# 1. Pass parameters to the decorator and obtain the output color through the passed parameters
# 2. The print() output of the decorated function is output according to the color obtained by the decorator
import sys
def make_color(code):
def decorator(func):
if (code == 0):
s = 'white'
return func(s)
elif (code == 1):
s = 'black'
return func(s)
else:
print('wrong')
return decorator
@make_color(0)
def color_func(s):
print('The color is:%s' % s)
result:
The color is: white
Custom context manager
code:
fd = open('name.txt')
try:
for line in fd:
print(line)
finally:
fd.close()
# Context manager
# If you use with, you don't need to write finally, because when an exception occurs, with will automatically call finally to close the file (described in detail later)
with open('name.txt') as f:
for line in f:
print(line)
result:
Zhuge Liang|Guan Yu|Liu Bei|Cao Cao|Sun Quan|Guan Yu|Fei Zhang|Lv Bu|Zhou Yu|Zhao Yun|Pang Tong|Sima Yi|Huang Zhong|Ma Chao Zhuge Liang|Guan Yu|Liu Bei|Cao Cao|Sun Quan|Guan Yu|Fei Zhang|Lv Bu|Zhou Yu|Zhao Yun|Pang Tong|Sima Yi|Huang Zhong|Ma Chao
summary
exercises
Practice a function
- Create a function to receive the number entered by the user and calculate the sum of the number entered by the user
- Create a function, pass in n integers, and return the maximum number and the minimum number
- Create a function, pass in a parameter n and return the factorial of n
code:
# 1. Create a function to receive the number entered by the user and calculate the sum of the number entered by the user
def func1():
two_num = input('Please enter two numbers separated by spaces:')
# Check whether the user input is legal
func2(two_num)
# print(type(two_num))
num1, *_, num2 = two_num
print('%s and %s The sum is:' % (num1, num2))
print(int(num1) + int(num2))
def func2(check_number):
pass
func1()
# 2. Create a function, pass in n integers, and return the maximum number and the minimum number
def func3(*nums):
print('The maximum number is: %s' % max(nums))
print('The smallest number is: %s' % min(nums))
func3(1, 5, 8, 32, 654, 765, 4, 6, 7)
# 3. Create a function, pass in a parameter n and return the factorial of n
def func4(n):
if n == 0 or n == 1:
return 1
else:
return n * func4(n - 1)
num = input('Please enter the number to factorize:')
print('%s The factorial result of is:%s' % (num, func4(num)))
Chapter IX module
Definition of module

Rename module
Rename the long module name to simplify the name.
import time as t # Rename module t.time() # Reference functions in the time file
Method of not writing module name:
from time import sleep # This is not recommended for fear of renaming sleep()
Custom module and its call
Own module:
def print_me():
print('me')
# print_me() is rarely called directly. It is usually the definition of a function
Calling module:
import mymod # Import is not added py suffix mymod.print_me() # Reference the functions in this file
exercises
Practice a module the first one the next.
- Import the os module and use help(os) to view the help documentation for the os module
# 1. Import the os module and use help(os) to view the help document of the os module import os print(help(os))
Chapter 10 grammatical norms
PEP8 coding specification
Relevant instructions in class:
https://www.python.org/dev/peps/pep-0008/
pycharm install PEP8
cmd Window input: pip install autopep8
Tools→Extends Tools→Click the plus sign
Name: Autopep8((you can take it at will)
- Tools settings:
- Programs: `autopep8` (If you have installed it)
- Parameters:`--in-place --aggressive --aggressive $FilePath$`
- Working directory:`$ProjectFileDir$`
- click Output Filters→Add, in the dialog box: Regular expression to match output Enter in:`$FILE_PATH$\:$LINE$\:$COLUMN$\:.*`
If unsuccessful, please refer to the following:
pycharm setting autopep8
Chapter 11 object oriented programming
Classes and instances
Process oriented programming
characteristic:
- Write corresponding functions from top to bottom according to the sequence of program execution
code:
# Process oriented
user1 = {'name': 'tom', 'hp': 100}
user2 = {'name': 'jerry', 'hp': 80}
def print_role(rolename):
print('name is %s , hp is %s' % (rolename['name'], rolename['hp']))
print_role(user1)
object-oriented programming
definition:
The same features of different objects are extracted, and the extracted things are called classes.
code:
# object-oriented
class Player(): # Define a class. The class name should start with an uppercase letter
def __init__(self, name, hp): # __ init__ Is a special method that executes automatically after class instantiation
self.name = name # Self means that after the Player class is instantiated, is the self of the instance equivalent to this in java
self.hp = hp
def print_role(self): # Define a method
print('%s: %s' % (self.name, self.hp))
user1 = Player('tom', 100) # Class instantiation
user2 = Player('jerry', 90)
user1.print_role()
user2.print_role()
# Note: in a class, the first parameter of all functions (Methods) must take self
be careful:
- In a class, the first parameter of all functions (Methods) must take self
- Class names should start with uppercase letters
How to add class properties and methods
Add a property and method
code:
# object-oriented
class Player():
def __init__(self, name, hp, occu):
self.name = name
self.hp = hp
self.occu = occu # Add a class attribute
def print_role(self):
print('%s: %s %s' % (self.name, self.hp, self.occu))
def updateName(self, newname): # Create a renamed method
self.name = newname
user1 = Player('tom', 100, 'war') # Class instantiation
user2 = Player('jerry', 90, 'master')
user1.print_role()
user2.print_role()
user1.updateName('wilson')
user1.print_role()
class Monster():
'Define monster class'
pass
Class encapsulation
The properties of the class do not want to be accessed by others.
- Precede the properties of the class with two underscores "_"
code:
# object-oriented
class Player():
def __init__(self, name, hp, occu):
self.__name = name
self.hp = hp
self.occu = occu # Add a class attribute
def print_role(self):
print('%s: %s %s' % (self.__name, self.hp, self.occu))
def updateName(self, newname): # Create a renamed method
self.__name = newname
user1 = Player('tom', 100, 'war') # Class instantiation
user2 = Player('jerry', 90, 'master')
user1.print_role()
user2.print_role()
user1.updateName('wilson')
user1.print_role()
result:
name is tom , hp is 100 tom: 100 war jerry: 90 master wilson: 100 war wilson: 100 war
In this way, the properties of the class will not be accessed by the instance of the class.
You can only change the properties of a class through methods.
Class inheritance
inherit
code:
# Cats inherit the methods used by cats
# Cats are called the father of cats, and cats are called the children of cats
class Monster():
'Define monster class'
def __init__(self, hp=100): # There is already life value during initialization
self.hp = hp
def run(self):
print('Move to a location')
class Animals(Monster): # Subclasses inherit the parent class. Subclasses write the name of the parent class in parentheses
'Ordinary monster'
def __init__(self, hp=10):
self.hp = hp
class Boss(Monster):
'Boss Monster like'
pass
# Parent class
a1 = Monster(200)
print(a1.hp)
a1.run()
# Subclass
a2 = Animals(1)
print(a2.hp)
a2.run()
Subclasses can call properties and methods in the parent class.
super
effect:
For the property initialized in the parent class, the child class does not need to be initialized repeatedly.
code:
class Animals(Monster): # Subclasses inherit the parent class. Subclasses write the name of the parent class in parentheses
'Ordinary monster'
def __init__(self,hp=10):
super().__init__(hp) # hp in Animals does not need to be initialized anymore. The parent class has been initialized
Subclass method and parent method have the same name
When a subclass is called, the method of the subclass will overwrite the method with the same name as the parent class.
polymorphic
Only when a method with a duplicate name is actually used can it know whether it is a subclass or parent method that calls it, indicating that the method has multiple states at runtime. This feature is called "polymorphism".
Judge the inheritance relationship of classes
code:
# Judge the inheritance relationship of classes
print('a1 The type of is %s' % type(a1))
print('a2 The type of is %s' % type(a2))
print('a2 The type of is %s' % type(a3))
print(isinstance(a2, Monster)) # Judge whether a2 is a subclass of Monster. If so, output True; if not, output False
result:
a1 The type of is <class '__main__.Monster'> a2 The type of is <class '__main__.Animals'> a2 The type of is <class '__main__.Boss'> True
Additional knowledge
Tuple, list, string and other forms are "class"
# Tuple, list, string and other forms are "class"
print(type(tuple))
print(type(list))
print(type('123'))
<class 'type'> <class 'type'> <class 'str'>
All objects inherit the parent class object
# All objects inherit the parent class object
print(isinstance(tuple, object))
print(isinstance(list, object))
print(isinstance('123', object))
True True True
summary
- A class is a collection that describes an object with the same properties and methods;
- Encapsulation, inheritance and polymorphism;
- Class needs to be instantiated before it can be used.
Class - Custom with statement
Function:
- Automatic exception handling
- Exception and object-oriented
Custom with method:
code:
class Testwith():
def __enter__(self): # Called at start
print('run')
def __exit__(self, exc_type, exc_val, exc_tb): # Called at the end
if exc_tb is None: # If exc_ If TB is not abnormal, its value is None. Judge whether it is empty with "is None"
print('Normal end')
else:
print('has error %s' % exc_tb)
# Class and throw exception
# Simplify the writing of exceptions with with
with Testwith():
print('Test is running')
raise NameError('testNameError') # Throw exception manually
result:
run
Test is running
has error <traceback object at 0x000002016D762B80>
Traceback (most recent call last):
File "D:\Python\pythonProject\with_test.py", line 15, in <module>
raise NameError('testNameError') # Throw exception manually
NameError: testNameError
a key:
- with can simplify the writing of throwing exceptions (try... catch...)
Chapter 12: multithreaded programming
Definition of multithreaded programming
Process:
Status of program operation
Multithreaded programming:
At the same time, there are a large number of requests. We need to process these requests. The method of processing these requests is multithreaded programming.
No threads are running
code:
def myThread(arg1, arg2):
print('%s %s' %(arg1, arg2)
for i in range(1, 6, 1):
t1 = myThread(i, i + 1)
result:
1 2 2 3 3 4 4 5 5 6
Multithreaded method run
code:
import threading
def myThread(arg1, arg2):
print('%s %s' %(arg1, arg2)
for i in range(1, 6, 1):
# t1 = myThread(i, i + 1)
t1 = threading.Thread(target = myThread, args = (i, i + 1))
t1.start() # Running multithreaded programs
result:
1 2 2 3 3 4 4 5 5 6
Introducing sleep() to pause multithreading:
code:
import threading
import time
def myThread(arg1, arg2):
print('%s %s' %(arg1, arg2)
time.sleep(1)
for i in range(1, 6, 1):
# t1 = myThread(i, i + 1)
t1 = threading.Thread(target = myThread, args = (i, i + 1))
t1.start() # Running multithreaded programs
result:
1 2 2 3 3 4 4 5 5 6
The program directly prints out all the contents, and waits for 1s after running.
Display the current thread running status:
import threading
import time
from threading import current_thread # The running status of the current thread is displayed
def myThread(arg1, arg2):
print(current_thread().getName(), 'start') # Mark the name of the current thread. The first one: the name of the thread; Second: the comment you want to add
print('%s %s' % (arg1, arg2))
time.sleep(1) # The program does not wait for 1s and outputs directly, indicating that the program is running in parallel
print(current_thread().getName(), 'stop')
for i in range(1, 6, 1):
# t1 = myThread(i, i + 1) # No thread
t1 = threading.Thread(target=myThread, args=(i, i + 1)) # First parameter: function name; Second parameter: the passed in parameter generates 5 new threads
t1.start() # Running multithreaded programs
print(current_thread().getName(), 'end')
# After the main program ends, the thread ends with "MainThread end" and then "stop"
# The main thread ends first and ends after Thread1-5
result:
Thread-1 start 1 2 Thread-2 start 2 3 Thread-3 start 3 4 Thread-4 start 4 5 Thread-5 start 5 6 MainThread end Thread-1 stop Thread-3 stop Thread-2 stop Thread-4 stop Thread-5 stop
After the main program ends, the thread ends with "MainThread end" and then "stop".
Synchronization between threads
When one thread is running, you can wait for another thread to end.
code:
# Implement "stop" before "end"
import threading
from threading import current_thread # Used when the method name is unusual
# threading.Thread().run() # Function calls in threads
# Inherit threading Thread () then overrides run() -- polymorphism
class Mythread(threading.Thread): # Inherit without parentheses
def run(self): # Re implement the run() method
# 1. Get the name of the current thread -- judge whether to wait for the thread
print(current_thread().getName(), 'start')
print('run')
print(current_thread().getName(), 'stop')
t1 = Mythread()
t1.start()
# Thread ends first and main ends later
t1.join()
print(current_thread().getName(), 'end') # Print the display results of the main thread
result:
Thread-1 start run Thread-1 stop MainThread end
Classic producer and consumer issues
When the program runs, it will continuously produce a large amount of data, and users will consume a series of data. This process is the problem of producers and consumers. (analogy with water injection and drainage of water tank)
queue
Synchronize data between different threads.
code:

# Implementation of queue import queue q = queue.Queue() # Generate a queue q.put(1) # Add a data to the queue q.put(2) q.put(3) q.get() # The read queue is read in the order of joining
code implementation
Code 1:
from threading import Thread, current_thread # It can realize the parallel production and consumption of multiple producers and consumers
import time # dormancy
import random # Generate random data
from queue import Queue # Import queue library
queue = Queue(5) # Defines the length of the queue
class ProducerThread(Thread):
def run(self):
name = current_thread().getName() # Gets the name of the producer's thread
nums = range(100)
global queue # Defines a global variable for a queue
while True:
num = random.choice(nums) # Select a number at random
queue.put(num) # Put randomly selected numbers into the queue
print('producer %s Production data %s' % (name, num))
t = random.randint(1, 3) # Random sleep time
time.sleep(t) # Put producers to sleep
print('producer %s Sleep %s second' % (name, t))
class ConsumerThread(Thread):
def run(self):
name = current_thread().getName() # Gets the thread name of the consumer
global queue
while True:
num = queue.get() # Get the desired number in the queue
queue.task_done() # The code of thread waiting and synchronization is encapsulated
print('consumer %s Consumed data %s' % (name, num)) # Random sleep time
t = random.randint(1, 5) # Wait a few seconds at random
time.sleep(t)
print('consumer %s Sleep %s second' % (name, t))
# One producer and two consumers
p1 = ProducerThread(name='p1')
p1.start()
c1 = ConsumerThread(name='c1')
c1.start()
result:
producer p1 Production data 74 consumer c1 Data consumed 74 producer p1 Sleep for 1 second producer p1 Production data 82 producer p1 Sleep for 1 second producer p1 Production data 67 consumer c1 Sleep for 3 seconds consumer c1 Data consumed 82 producer p1 Sleep for 1 second producer p1 Production data 28 producer p1 Sleep for 1 second producer p1 Production data 75
Code 2:
from threading import Thread, current_thread # It can realize the parallel production and consumption of multiple producers and consumers
import time # dormancy
import random # Generate random data
from queue import Queue # Import queue library
queue = Queue(5) # Defines the length of the queue
class ProducerThread(Thread):
def run(self):
name = current_thread().getName() # Gets the name of the producer's thread
nums = range(100)
global queue # Defines a global variable for a queue
while True:
# After a random sleep time, add a random number to the queue
num = random.choice(nums) # Select a number at random
queue.put(num) # Put randomly selected numbers into the queue
print('producer %s Production data %s' % (name, num))
t = random.randint(1, 3) # Random sleep time
time.sleep(t) # Put producers to sleep
print('producer %s Sleep %s second' % (name, t))
class ConsumerThread(Thread):
def run(self):
name = current_thread().getName() # Gets the thread name of the consumer
global queue
while True:
# After random time, random numbers are extracted from the queue
num = queue.get() # Get the desired number in the queue
queue.task_done() # The code of thread waiting and synchronization is encapsulated
print('consumer %s Consumed data %s' % (name, num)) # Random sleep time
t = random.randint(1, 5) # Wait a few seconds at random
time.sleep(t)
print('consumer %s Sleep %s second' % (name, t))
# # One producer and two consumers (slow production and fast consumption)
# p1 = ProducerThread(name='p1')
# p1.start()
# c1 = ConsumerThread(name='c1')
# c1.start()
# Three producers and two consumers (fast production and slow consumption)
p1 = ProducerThread(name='p1')
p1.start()
p2 = ProducerThread(name='p2')
p2.start()
p3 = ProducerThread(name='p3')
p3.start()
c1 = ConsumerThread(name='c1')
c1.start()
c2 = ConsumerThread(name='c2')
c2.start()
# When the queue is full, the producer will no longer produce data and will produce after consumption by consumers
result:
producer p1 Production data 70 producer p2 Production data 33 producer p3 Production data 95 consumer c1 Consumed data 70 consumer c2 Data consumed 33 consumer c1 Sleep for 1 second consumer c1 Consumed data 95
Chapter XIII standard library
Definition of Python standard library
Python standard library official documentation
Key points:
- Text Processing Services
- Data Types
- Generic Operating System Services
- Internet Data Handling
- Development Tools
- Debugging and Profiling
Regular exp re ssion library
matching
code:
import re
# matching
p = re.compile('a') # Define a string to match
print(p.match('a')) # The matched string can be successfully matched
print(p.match('b')) # Cannot match on
# Match a regular string of characters
# Introduce some special characters (representing the regularity of character repetition, etc.), which are called "metacharacters"
p = re.compile('cat')
print(p.match('caaaaat')) # Failed to match, None
# The advantage of regular expressions: some special functions are represented by special symbols
p = re.compile('ca*t') # Repeat a and replace with * a
print(p.match('caaaaat')) # Match successful
result:
<re.Match object; span=(0, 1), match='a'> None None <re.Match object; span=(0, 7), match='caaaaat'>
Metacharacters of regular expressions
Common metacharacters
| Metacharacter | function |
|---|---|
| . | Match any single character |
| ^ | Match a string that begins with what |
| $ | Match a string that ends with what |
| * | Matches the previous character 0 to more than once |
| + | Matches the preceding character 1 to more than once |
| ? | Matches the previous character 0 to 1 times |
| {m} | Indicates that the specified number of occurrences of the preceding character is m times |
| {m,n} | Indicates that the specified number of occurrences of the preceding character is m~n times |
| [] | Indicates that any character in brackets matches successfully |
| Indicates that the character is left or right. It is usually used with parentheses (often used with ()) | |
| \d | Indicates that the matching content is a string of numbers, equivalent to one of [1234567890] + or [0-9] + |
| \D | Indicates that the matching content does not contain numbers |
| \s | Indicates that a string (a-z) matches |
| () | Group |
| ^$ | Indicates that this line is empty. When matching text, one line is empty and nothing is included |
| .*? | Do not use greedy mode |
. metacharacter
Function:
Match any single character
code:
import re
p = re.compile('.')
print(p.match('c'))
print(p.match('d'))
# Match three characters
p = re.compile('...')
print(p.match('abc'))
result:
<re.Match object; span=(0, 1), match='c'> <re.Match object; span=(0, 1), match='d'> <re.Match object; span=(0, 3), match='abc'>
^And $metacharacters
Function:
^: matches a string that starts with what
$: matches a string that ends with what
code:
# ^What kind of content to start with $what kind of content to end with (matching from back to front)
# Search: means to search from the beginning.
import re
p = re.compile('^jpg') # Match strings starting with jpg
print(p.match('jpg'))
p = re.compile('jpg$') # Matches strings ending in jpg to all files with "jpg" extension
print(p.match('jpg'))
result:
<re.Match object; span=(0, 3), match='jpg'> <re.Match object; span=(0, 3), match='jpg'>
*Metacharacter
Function:
Matches the preceding character 0 to more than once.
code:
# *Matches the previous character 0 to more than once
import re
p = re.compile('ca*t')
print(p.match('ct')) # Match cat with 0 occurrences - success
print(p.match('caaaaaat')) # Match cat that occurs multiple times - success
result:
<re.Match object; span=(0, 2), match='ct'> <re.Match object; span=(0, 8), match='caaaaaat'>
+And? Metacharacter
Function:
+: matches the preceding character 1 to more than once
?: Matches the previous character 0 to 1 times
code:
# +Matches the preceding character 1 to more than once
# ? Matches the previous character 0 to 1 times
import re
p = re.compile('c?t')
print(p.match('t')) # Match 0 occurrences of c
print(p.match('ct')) # Matching occurs once in c
q = re.compile('c+t')
print(q.match('ct')) # Matching occurs once in c
print(q.match('cccct')) # Matches c that occurs more than once
result:
<re.Match object; span=(0, 1), match='t'> <re.Match object; span=(0, 2), match='ct'> <re.Match object; span=(0, 2), match='ct'> <re.Match object; span=(0, 5), match='cccct'>
{m} Metacharacter
Function:
Indicates that the specified number of occurrences of the preceding character is m times
code:
import re
p = re.compile('ca{4}t') # a that matches 4 times
print(p.match('caaaat'))
<re.Match object; span=(0, 6), match='caaaat'>
{m,n} metacharacter
Function:
Indicates that the specified number of occurrences of the preceding character is m~n times
code:
import re
p = re.compile('ca{4,6}t') # a matching occurs 4 ~ 6 times
print(p.match('caaaaat'))
result:
<re.Match object; span=(0, 7), match='caaaaat'>
[] metacharacter
Function:
Indicates that any character in brackets matches successfully.
code:
# [] indicates that any character in brackets matches successfully
import re
p = re.compile('c[bcd]t') # Indicates that bcd any character matches successfully
print(p.match('cat')) # Matching failed
print(p.match('cbt')) # Match successful
print(p.match('cct')) # Match successful
print(p.match('cdt')) # Match successful
result:
None <re.Match object; span=(0, 3), match='cbt'> <re.Match object; span=(0, 3), match='cct'> <re.Match object; span=(0, 3), match='cdt'>
|Metacharacter
Function:
Indicates that the character is left or right. It is usually used with parentheses (often used with ())
\d-ary character
Function:
Indicates that the matching content is a string of numbers, equivalent to one of [1234567890] + or [0-9] +
\D-ary character
Function:
Indicates that the matching content does not contain numbers
\s metacharacter
Function:
Indicates that a string (a-z) matches
() metacharacter
Function:
Group
code:
# () group # Withdrawal date (mm / DD / yyyy) # 2018-03-04 # (2018)-(03)-(04) # (2018)-(03)-(04).group() extracts one of the groups # Match different content, but look very similar # 2018-03-04 # 2018-04-12 # Want to withdraw 2018-03 or 2018-04 # (03|04) extract only 03 or 04
^$metacharacter
Function:
Indicates that this line is empty. When matching text, one line is empty and nothing is included
.*? Metacharacter
Function:
Do not use greedy mode
code:
# .*? Do not use greedy mode # Greedy model # abcccccd # abc* # It will match all the c * in front of d. when matching, it will match as long as possible # # Non greedy model # abcccccd # abc*? # # Only match the content of the first match. It is very common to match the content of web pages # <img /img> # <img /img>
Regular expression grouping function example
code:
# Using regularization to realize grouping function
# Do the characters that appear match the characters we want
import re
p = re.compile('.{3}') # Matching three arbitrary characters is equivalent to '...'
print(p.match('bat'))
# Match the year, month and day, and then take the year, month and day
# q = re.compile('....-..-..')
# If it is a judgment number and it is continuous
q = re.compile('\d-\d-\d')
q = re.compile(r'\d-\d-\d') # r tells python to output the content behind the program as it is without escape
q = re.compile(r'(\d)-(\d)-(\d)') # () group the parts you want to take out
q = re.compile(r'(\d+)-(\d+)-(\d+)') # Add a plus sign because the number may match more than once: consecutive numbers (05 and 5 can match)
print(q.match('2018-05-10'))
print(q.match('2018-05-10').group()) # Take out a part group() takes out all the parts
print(q.match('2018-05-10').group(1)) # Take out a part group(1) take out the contents contained in the first bracket
print(q.match('2018-05-10').group(2)) # Take out a part group(2) take out the contents contained in the second bracket
print(q.match('2018-05-10').groups()) # Take it all out
year, month, day = q.match('2018-05-10').groups() # Assign to variable
print(year, month, day)
# It is hoped that special symbols will not be escaped during regular matching
print('\nx\n')
print(r'\nx\n')
result:
<re.Match object; span=(0, 3), match='bat'>
<re.Match object; span=(0, 10), match='2018-05-10'>
2018-05-10
2018
05
('2018', '05', '10')
2018 05 10
x
\nx\n
Process finished with exit code 0
The difference between regular expression library function match and search
match
code:
# match
# The matching string must correspond to the regular one-to-one. Before matching, you should clearly know what form the string appears in
import re
p = re.compile(r'(\d+)-(\d+)-(\d+)')
print(p.match('aa2018-05-10bb').group(2)) # Matching failed, unable to group, and then unable to match
print(p.match('2018-05-10').group())
result:
Traceback (most recent call last):
File "D:\Python\pythonProject\43.py", line 129, in <module>
print(p.match('aa2018-05-10bb').group(2)) # Matching failed, unable to group, and then unable to match
AttributeError: 'NoneType' object has no attribute 'group'
search
code:
import re
p = re.compile(r'(\d+)-(\d+)-(\d+)')
# search
# Incomplete matching does not require an exact match between the metacharacter and the input
print(p.search('aa2018-05-10bb')) # Keep searching for matches until they can be matched successfully. As long as the corresponding regular expression is included, they can be matched successfully
result:
<re.Match object; span=(2, 12), match='2018-05-10'>
The respective usage of match and search
- Search is often used to search the specified string in the function
- Match is often grouped after an exact match
An instance of the regular expression library replacement function sub()
Function:
Replace the string.
code:
# sub # Function: string replacement # Sub (arg1, arg2, arg3) arg1: content to match + matching rule (metacharacter) arg2: target replacement content arg3: replaced string # take#Replace the following contents with empty ones import re phone = '123-456-789 # This is the phone number ' p2 = re.sub(r'#.*$', '', phone) # arg1: matching#The following multiple arbitrary contents and ends with arg2: the target is replaced with an empty string arg3: the replaced string is phone print(p2) # Replace the - in the middle p3 = re.sub(r'\D', '', p2) # Replace all non numeric characters with empty ones print(p3)
code:
<re.Match object; span=(2, 12), match='2018-05-10'> 123-456-789 123456789
a key:
- Match and search can only match and search to the character on the first match
- findall can match multiple times
Date and time library
time module
effect:
View of date and time.
code:
import time
# View of date and time
print(time.time()) # Seconds since January 1, 1970
print(time.localtime()) # specific date
print(time.strftime('%Y-%m-%d %H:%M:%S')) # Output year, month and day in a specific format (custom format)
print(time.strftime('%Y%m%d'))
result:
1612482375.7951758 time.struct_time(tm_year=2021, tm_mon=2, tm_mday=5, tm_hour=7, tm_min=46, tm_sec=15, tm_wday=4, tm_yday=36, tm_isdst=0) 2021-02-05 07:46:15 20210205
datatime module
effect:
Modification of date and time.
code:
# datatime # 1. Modification of date and time # Get the time after 10min import datetime print(datetime.datetime.now()) # Take the present time newtime = datetime.timedelta(minutes=10) # timedelta after 10min -- offset print(datetime.datetime.now() + (newtime)) # Current time + offset # 2. Get the time after the specified date # 10 days after May 27, 2018 one_day = datetime.datetime(2008, 5, 27) new_date = datetime.timedelta(days=10) print(one_day + new_date)
result:
2021-02-05 08:48:36.233056 2021-02-05 08:58:36.233056 2008-06-06 00:00:00
Mathematical correlation Library
random
Function:
Take random numbers according to the limiting conditions
code:
import random # Take random numbers according to the limiting conditions r = random.randint(1, 5) # 1 ~ 5 random integers print(r) s = random.choice(['aa', 'bb', 'cc']) # Random string print(s)
result:
1 aa
Use the command line to manipulate files and folders
File and directory operation Library
os.path Library
code:
Function:
File and directory access.
# File and directory access
import os
# 1. According to the relative path To get the current absolute path
jd = os.path.abspath('.')
print(jd)
# According to the relative path To get the absolute path of the upper level
last_jd = os.path.abspath('..')
print(last_jd)
# 2. Judge whether the file exists
isExise = os.path.exists('/Python') # The corresponding directory is in parentheses
print(isExise)
# 3. Judge whether it is a document
isFile = os.path.isfile('/Python')
print(isFile)
# Determine whether it is a directory
isDir = os.path.isdir('/Python')
print(isDir)
# 4. Path splicing
dirJoint = os.path.join('/tmp/a/', 'b/c') # Followed by the path to be connected
print(dirJoint)
result:
D:\Python\pythonProject D:\Python True False True /tmp/a/b/c
pathlib Library
code:
from pathlib import Path
# 1. Get the relative path Corresponding absolute path
p = Path('.') # Take the first Encapsulated into this type
print(p.resolve()) # The absolute path corresponding to the relative path is equivalent to OS path. abspath('.')
# 2. List all directories under the current path - list derivation
# 3. Determine whether it is a directory
p.is_dir()
# 4. Create a new directory (key)
q = Path('/Python/a/b/c/d/e') # Note that the slash '/' format should not be wrong
Path.mkdir(q, parents=True) # create directory
# arg1: established path arg2: automatically create the upper level directory. parents=True let automatically create parents=False don't let automatically create
Path.rmdir('/Python/a/b/c/d/e') # Delete the specified directory. Non empty directory cannot be deleted
result:
D:\Python\pythonProject Process finished with exit code 0
Chapter 14 machine learning library
General process of machine learning and NumPy installation
General processing steps
Data collection:
- questionnaire
- Collection of network information
Data preprocessing:
- Unit unification
- Format adjustment
Data cleaning:
- Deletion of missing values and outliers of data
- Get quality data
Data modeling:
- Combined with what you want to do, design the corresponding algorithm
- Feed the data to the machine
- The machine obtains the results through data and algorithm
- Results through the test, the algorithm is feasible and the model is established
Data test:
- The model is used to complete the functions of automatic driving, image classification, voice prediction and so on
NumPy Library
Function:
Data preprocessing.

Array and data type of NumPy
code:
import numpy as np # Automatically convert according to the type of input data arr1 = np.array([2, 3, 4]) # Define a list print(arr1) # This list has been encapsulated by numpy, and its computational efficiency is much higher than that of its own list print(arr1.dtype) # integer arr2 = np.array([1.2, 2.3, 3.4]) print(arr2) print(arr2.dtype) # Mathematical calculation: List accumulation print(arr1 + arr2)
result:
[2 3 4] int32 [1.2 2.3 3.4] float64 [3.2 5.3 7.4]
NumPy array and scalar calculation
code:
import numpy as np # Scalar operation arr = np.array([1.2, 2.3, 3.4]) print(arr * 10) # Define a two-dimensional array (matrix) data = [[1, 2, 3], [4, 5, 6]] # Two lists are nested in one list # A two-dimensional matrix converted to numpy through a list arr2 = np.array(data) print(arr2) print(arr2.dtype) # Make all two-dimensional matrices 0 or 1 one = np.zeros(10) # Defines a one-dimensional array with a length of 10, and initializes the value to 0 print(one) two = np.zeros((3, 5)) # Defines a two-dimensional, 3 × 5, and initializes the value to 0 print(two) # Make the matrix contents all 1 all_one = np.ones((4, 6)) # Defines a two-dimensional, 4 × 6, and initializes the value to 1 print(all_one) # Make the matrix contents null all_empty = np.empty((2, 3, 2)) # Defines a three-dimensional, 2 × three × 2, and initializes the value to "null" print(all_empty) # The result is a random value (because null values are unsafe for program operations)
result:
[12. 23. 34.] [[1 2 3] [4 5 6]] int32 [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] [[1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1.]] [[[0. 0.] [0. 0.] [0. 0.]] [[0. 0.] [0. 0.] [0. 0.]]]
Index and slice of NumPy array
code:
# Slicing operation import numpy as np arr = np.arange(10) print(arr) print(arr[5]) print(arr[5:8]) # Direct assignment to slice arr[5:8] = 10 print(arr) # Reassign without changing the original value arr_slice = arr[5:8].copy() # copy arr_slice[:] = 15 # [:] indicates that all the values have been assigned from the first element to the last element print(arr) print(arr_slice)
result:
[0 1 2 3 4 5 6 7 8 9] 5 [5 6 7] [ 0 1 2 3 4 10 10 10 8 9] [ 0 1 2 3 4 10 10 10 8 9] [15 15 15]
pandas installation and Series structure
pandas function:
Data preprocessing and data cleaning.
code:
from pandas import Series, DataFrame
import pandas as pd
# Align and display the data automatically or in a customized way
# It can flexibly handle missing data (fill in or specify values based on most well-known averages)
# Connection operation
# Related operations of one-dimensional array of pandas
obj = Series([4, 5, 6, -7]) # The array of numpy is encapsulated
print(obj)
# Benefit: the index is automatically added in front, which makes it easier to access the data
# The index of pandas can be repeated
print(obj.index)
# Take out the value
print(obj.values)
# Hash operation (the key in the dictionary cannot be repeated)
# After a simple character is hashed, the only complex character is obtained
# 'a' --> 'asdfasdfasdfasd' # The hash algorithm is the same, and the results are the same
# Internal storage form of hash value -- link form
{'a': 1, 'b': 2, 'c': 3}
# 1. Map abc into a series of complex characters and store them in memory
# a -> asdhfljasdf
# b -> askldjfaisddf
# c -> dofjwoifjife
# The key in the dictionary can be int float string tuple, etc
# Dictionary key Cannot be: list, set # Because they can re assign values
{['a']: 1}
result:
0 4
1 5
2 6
3 -7
dtype: int64
RangeIndex(start=0, stop=4, step=1)
[ 4 5 6 -7]
Traceback (most recent call last):
File "D:\Python\pythonProject\pandas_test.py", line 29, in <module>
{['a']: 1}
TypeError: unhashable type: 'list'
Basic operation of Series
code:
import pandas as pd
from pandas import Series
# Operation on one-dimensional array (Series) in pandas
obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'c', 'a']) # Manually specify index
print(obj2)
# Assign value to index
obj2['c'] = 6
print(obj2)
# See if the index is in the Series
print('a' in obj2)
print('f' in obj2)
# Convert dictionary to Series
sdata = {'beijing': 35000, 'shanghai': 71000, 'guangzhou': 16000, 'shenzhen': 5000}
obj3 = Series(sdata)
print(obj3)
# Modifying the index of a Series
obj3.index = ['bj', 'gz', 'sh', 'sz']
print(obj3)
result:
d 4 b 7 c -5 a 3 dtype: int64 d 4 b 7 c 6 a 3 dtype: int64 True False beijing 35000 shanghai 71000 guangzhou 16000 shenzhen 5000 dtype: int64 bj 35000 gz 71000 sh 16000 sz 5000 dtype: int64
Basic operations of Dataframe
code:
from pandas import Series, DataFrame # Similar to spreadsheet
# Generate dataframe
# Pass in a list of equal length or an array of numpy
# Use the dictionary to create a DataFrame in the dictionary in the form of equal length list
data = {'city': ['shanghai', 'shanghai', 'shanghai', 'beijing', 'beijing'],
'year': [2016, 2017, 2018, 2017, 2018],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
# Assign dictionary to DataFrame
frame = DataFrame(data)
print(frame)
# Sort in the specified order
frame2 = DataFrame(data, columns=['year', 'city', 'pop']) # Display by year city pop
print(frame2)
# Extract one-dimensional data (two-dimensional - > one-dimensional)
print(frame2['city'])
print(frame2.year)
# Add a column
frame2['new'] = 100
print(frame2)
# Generate new columns using calculations
# city is beijing's new column is True, not beijing's new column is False
frame2['cap'] = frame2.city == 'beijing'
print(frame2)
# Dictionary nesting
pop = {'beijing': {2008: 1.5, 2009: 2.0},
'shanghai': {2008: 2.0, 2009: 3.6}
}
frame3 = DataFrame(pop)
print(frame3)
# Row column interchange (transpose of determinant)
print(frame3.T)
# Re index (re modify the current index)
obj4 = Series([4.5, 7.2, -5.3, 3.6], index=['b', 'd', 'c', 'a'])
obj5 = obj4.reindex(['a', 'b', 'c', 'd', 'e'])
print(obj5) # NaN stands for null value
# Filter missing values
# Uniformly fill in null values
obj6 = obj4.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
print(obj6)
# Uniformly fill in null values to the values of adjacent elements
# Populates the values above or below the current value
obj7 = Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
obj7_new = obj7.reindex(range(6))
print(obj7_new)
# Fill with previous values
obj7_newf = obj7.reindex(range(6), method='ffill')
print(obj7_newf)
# Fill with the following values
obj7_newb = obj7.reindex(range(6), method='bfill')
print(obj7_newb)
# Delete missing data
from numpy import nan as NA # Import a missing value from numpy and rename it NA
data = Series([1, NA, 2])
print(data)
print(data.dropna()) # Delete missing values
# Deletion of DataFrame missing data
data2 = DataFrame([[1., 6.5, 3], [1., NA, NA], [NA, NA, NA]])
print(data2)
print(data2.dropna()) # The rows and columns with NA will be deleted
# Delete a row with all missing values and retain a row with some missing values
print(data2.dropna(how='all'))
data2[4] = NA
print(data2)
# Delete a column with all missing values, and retain a column with some missing values
print(data2.dropna(axis=1, how='all'))
# Filling method: fillna fills all missing values with 0
data2.fillna(0) # Only a copy of data2 was modified
print(data2.fillna(0))
print(data2.fillna(0, inplace=True)) # Modify data2 directly
print(data2)
result:
city year pop
0 shanghai 2016 1.5
1 shanghai 2017 1.7
2 shanghai 2018 3.6
3 beijing 2017 2.4
4 beijing 2018 2.9
year city pop
0 2016 shanghai 1.5
1 2017 shanghai 1.7
2 2018 shanghai 3.6
3 2017 beijing 2.4
4 2018 beijing 2.9
0 shanghai
1 shanghai
2 shanghai
3 beijing
4 beijing
Name: city, dtype: object
0 2016
1 2017
2 2018
3 2017
4 2018
Name: year, dtype: int64
year city pop new
0 2016 shanghai 1.5 100
1 2017 shanghai 1.7 100
2 2018 shanghai 3.6 100
3 2017 beijing 2.4 100
4 2018 beijing 2.9 100
year city pop new cap
0 2016 shanghai 1.5 100 False
1 2017 shanghai 1.7 100 False
2 2018 shanghai 3.6 100 False
3 2017 beijing 2.4 100 True
4 2018 beijing 2.9 100 True
beijing shanghai
2008 1.5 2.0
2009 2.0 3.6
2008 2009
beijing 1.5 2.0
shanghai 2.0 3.6
a 3.6
b 4.5
c -5.3
d 7.2
e NaN
dtype: float64
a 3.6
b 4.5
c -5.3
d 7.2
e 0.0
dtype: float64
0 blue
1 NaN
2 purple
3 NaN
4 yellow
5 NaN
dtype: object
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
0 blue
1 purple
2 purple
3 yellow
4 yellow
5 NaN
dtype: object
0 1.0
1 NaN
2 2.0
dtype: float64
0 1.0
2 2.0
dtype: float64
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
0 1 2
0 1.0 6.5 3.0
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
0 1 2 4
0 1.0 6.5 3.0 0.0
1 1.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
None
0 1 2 4
0 1.0 6.5 3.0 0.0
1 1.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
Hierarchical index
code:
# Hierarchical index
# Multilevel index
# Series -- one dimensional data DataFrame -- two dimensional data
from pandas import Series, DataFrame
import numpy as np
data3 = Series(np.random.randn(10),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 2, 3, 1, 2, 2, 3]])
print(data3)
# Extract data under index b
print(data3['b'])
# Extract multiple indexes
print(data3['b':'c'])
# Convert Series into DataFrame one-dimensional data into two-dimensional data
print(data3.unstack())
# Transform DataFrame into Series two-dimensional data into one-dimensional data
print(data3.unstack().stack())
result:
a 1 0.254799
2 1.096555
3 0.283251
b 1 1.009634
2 -0.643421
3 1.774040
c 1 0.550576
2 -0.687114
d 2 0.308054
3 0.788189
dtype: float64
1 1.009634
2 -0.643421
3 1.774040
dtype: float64
b 1 1.009634
2 -0.643421
3 1.774040
c 1 0.550576
2 -0.687114
dtype: float64
1 2 3
a 0.254799 1.096555 0.283251
b 1.009634 -0.643421 1.774040
c 0.550576 -0.687114 NaN
d NaN 0.308054 0.788189
a 1 0.254799
2 1.096555
3 0.283251
b 1 1.009634
2 -0.643421
3 1.774040
c 1 0.550576
2 -0.687114
d 2 0.308054
3 0.788189
dtype: float64
Installation and drawing of Matplotlib
code:
import matplotlib.pyplot as plt
import numpy as np
# # Draw simple curves
# plt.plot([1, 3, 5], [4, 8, 10]) # x-axis y-axis
# plt.show() # Display curve
#
# # Drawing data in numpy
# x = np.linspace(-np.pi, np.pi, 100) # The definition domain of x is -3.14 ~ 3.14, with an interval of 100 elements
# plt.plot(x, np.sin(x)) # Abscissa: x value ordinate: sinx value
# plt.show()
#
# # Draw multiple curves
# x = np.linspace(-np.pi * 2, np.pi * 2, 100) # The definition domain is: - 2pi to 2pi
# plt.figure(1, dpi=50) # Create chart dpi: the higher the precision (the detail of the drawing), the larger the volume of the picture, and the clearer the drawing
# for i in range(1, 5): # Draw four lines
# plt.plot(x, np.sin(x / i))
#
# plt.show()
#
# # Draw histogram
# plt.figure(1, dpi=50) # Create chart 1. dpi represents the picture fineness. The larger the dpi, the larger the file, and the magazine should be more than 300
# data = [1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 4]
# plt.hist(data) # As long as the data is passed in, the histogram will count the number of times the data appears
#
# plt.show()
#
# # Scatter plot
# x = np.arange(1, 10)
# y = x
# fig = plt.figure() # Create chart
# plt.scatter(x, y, c='r', marker='o') # c = 'r' indicates that the color of the scatter is red, and marker indicates that the shape of the specified scatter is circular
# plt.show()
# Combination of pandas and matplotlib
# pandas reading data -- matplotlib drawing
import pandas as pd
#
# iris = pd.read_csv("./iris_training.csv")
# print(iris.head()) # Displays the first five lines of iris information
#
# # Scatter plot based on the first two columns
# iris.plot(kind='scatter', x='120', y='4') # Scatter chart x-axis y-axis
#
# # It's no use, just let pandas's plot() method display on pyCharm
# plt.show()
# A library that encapsulates the matplotlib library
import seaborn as sns
import warnings # Ignore warning
warnings.filterwarnings("ignore") # When warnings are generated, ignore
iris = pd.read_csv("./iris_training.csv")
# Set style
sns.set(style="white", color_codes=True)
# Set the drawing format to scatter chart
# sns.jointplot(x="120", y="4", data=iris, size=5)
# distplot curve
# sns.distplot(iris['120']) # Draw the scatter diagram corresponding to 120
# It's no use, just let pandas's plot() method display on pyCharm
# plt.show()
# Based on different classifications, points are divided into different colors
# FacetGrid general drawing function
# hue color display classification 0 / 1 / 2
# plt.scatter plot with scatter
# add_legend() displays the description of the classification
# sns.FacetGrid(iris, hue="virginica", size=5).map(plt.scatter, "120", "4").add_legend() # hue draws scatter points in different colors based on different values of virginica
# Display the corresponding information in columns 3 and 4
sns.FacetGrid(iris, hue="virginica", size=5).map(plt.scatter, "setosa", "versicolor").add_legend()
# It's no use, just let pandas's plot() method display on pyCharm
plt.show()
result:
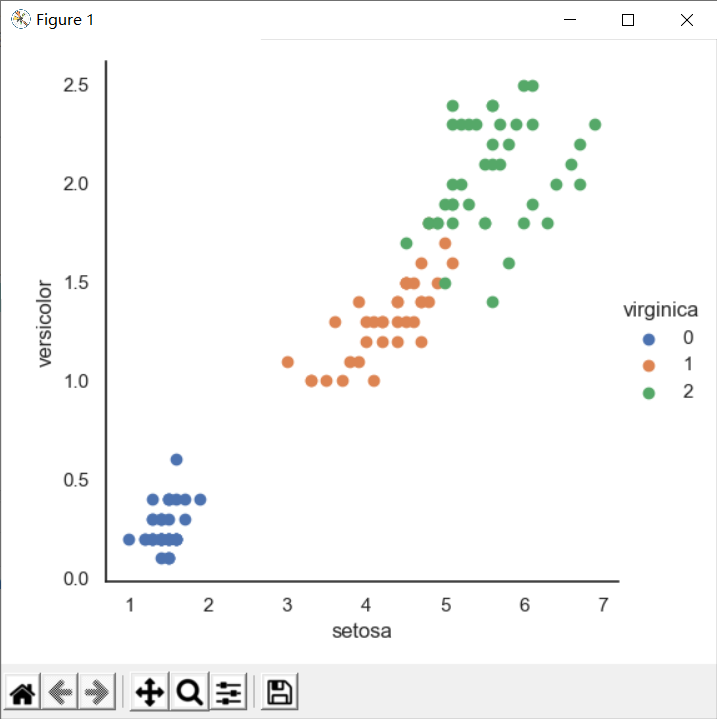
Principles of machine learning classification
working principle:
Input the eigenvalue and corresponding classification result data into the machine learning algorithm - get the model - test the model - input new values for prediction
Installation of Tensorflow
Models and codes classified according to eigenvalues
Chapter 15 reptiles
Web data collection and urllib Library
 code:
code:
# Get web page
from urllib import request
url = 'http://www.baidu. Com '# HTTP protocol
# Parse url
response = request.urlopen(url, timeout=1) # Timeout set the timeout (if you don't open the web page for more than 1s, you will give up opening the web page)
print(response.read().decode('utf-8')) # Direct reading will read out garbled code, which needs to be parsed. The format to be encoded is utf-8
Two common request methods for web pages: get and post
code:
# There are two ways to request web pages
from urllib import parse # parse is used to process post data
from urllib import request
# GET mode
# When entering the web address, it is followed by the parameters to be passed to the web page
# Write the information to be transmitted to the web server in the url address
# httpbin. org/get? A = 123 & BB = 456 tell the server to pass it two values a and b, and the server will display them
# Benefits: it is easy to transfer data to the server; Disadvantages: limitation of transmission data size
response = request.urlopen('http://httpbin.org/get', timeout=1) # followed by no data parameter is get
print(response.read())
# POST mode
# When submitting the user name and password, use post to submit. After entering the user name and password in the web page, they do not appear in the url address bar
data = bytes(parse.urlencode({'word': 'hellp'}), encoding='utf8') # Encapsulate data with data
response2 = request.urlopen('http://httpbin. Org / post ', data = data) # data = data specifies the data to be transferred
print(response2.read().decode('utf-8'))
import urllib
import socket # Socket font library (network timeout usually occurs here)
# Timeout condition
try:
response3 = request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout): # Determine whether the error of error is caused by timeout
print('TIME OUT')
result:
b'{\n "args": {}, \n "headers": {\n "Accept-Encoding": "identity", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.8", \n "X-Amzn-Trace-Id": "Root=1-601f3179-477c6caf31b7d3e6394fe965"\n }, \n "origin": "1.50.125.140", \n "url": "http://httpbin.org/get"\n}\n'
{
"args": {},
"data": "",
"files": {},
"form": {
"word": "hellp"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-601f317a-116916d86dd759e02cda01f4"
},
"json": null,
"origin": "1.50.125.140",
"url": "http://httpbin.org/post"
}
TIME OUT
Simulation of HTTP header information
# url disguises as a browser to request web information
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=259200",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-601f3d71-47afea5509bb17d15ab795ec"
}
dict = {
'name': 'value'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "value"
},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=259200",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"X-Amzn-Trace-Id": "Self=1-601f3dee-7861d78308a6c5be459b26a8;Root=1-601f3d71-47afea5509bb17d15ab795ec"
},
"json": null,
"origin": "1.50.125.140",
"url": "http://httpbin.org/post"
}
Basic use of requests Library
# get request
import requests
url = 'http://httpbin.org/get'
data = {'key': 'value', 'abc': 'xyz'} # Data passed to the server
# . get is to use the get method to request the url, and dictionary type data does not need additional processing
response = requests.get(url, data)
print(response.text)
# post request
url = 'http://httpbin.org/post'
data = {'key': 'value', 'abc': 'xyz'}
# . post is expressed as a post method
response = requests.post(url, data)
# The return type is json format
print(response.json())
Crawling image links with regular expressions
import requests
import re
content = requests.get('http://www.cnu.cc/discoveryPage/hot - portrait ') text
print(content)
# <div class="grid-item work-thumbnail">
# <a href="(http://www.cnu.cc/works/244938)" class = "thumbnail" target="_blank">
# < div class = "title" > (Fashion kids | retro childhood) < / div >
# <div class="author">LynnWei </div>
# <a href="(.*?)" .*?title">( .*? )</div>
pattern = re.compile(r'<a href="(.*?)".*?title">(.*?)</div>', re.S)
results = re.findall(pattern, content)
print(results) # The tuple form in the list is displayed
# Take out each element in the list
for result in results:
url, name = result
print(url, re.sub('\s', '', name)) # \S matches special symbols such as white space characters \ n are matched by \ s and replaced with null ''
Installation and use of Beautiful Soup
# You can match the html language without writing regular
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
# Import the contents of the web page
soup = BeautifulSoup(html_doc, 'lxml') # Parsing html in lxml format
# Process to standard html format
print(soup.prettify())
# Find the title tag
print(soup.title)
# Content in the title tag
print(soup.title.string)
# Find p tag
print(soup.p)
# Find the name of the p tag class
print(soup.p['class'])
# Find the first a tag
print(soup.a)
# Find all a Tags
print(soup.find_all('a'))
# Find the tag with id link3
print(soup.find(id="link3"))
# Find links to all < a > tags
for link in soup.find_all('a'):
print(link.get('href'))
# Find all text content in the document
print(soup.get_text())
Use crawlers to crawl news websites
# requests grabs the text beautiful soup for processing
from bs4 import BeautifulSoup
import requests
# Tell the website that we are a legitimate browser
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8",
"Connection": "close",
"Cookie": "_gauges_unique_hour=1; _gauges_unique_day=1; _gauges_unique_month=1; _gauges_unique_year=1; _gauges_unique=1",
"Referer": "http://www.infoq.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER"
}
url = 'https://www.infoq.com/news/'
# Get the full content of the web page
def craw(url):
response = requests.get(url, headers=headers)
print(response.text)
# craw(url)
# Get news headlines
def craw2(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
for title_href in soup.find_all('div', class_='news_type_block'):
print([title.get('title')
for title in title_href.find_all('a') if title.get('title')])
craw2(url)
# Turn pages
for i in range(15, 46, 15):
url = 'http://www.infoq.com/cn/news/' + str(i)
# print(url)
craw2(url)
Use the crawler to crawl the picture link and download the picture
# Batch download of pictures through requests
# Get the link address of the picture
from bs4 import BeautifulSoup
import requests
import os
import shutil
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8",
"Connection": "close",
"Cookie": "_gauges_unique_hour=1; _gauges_unique_day=1; _gauges_unique_month=1; _gauges_unique_year=1; _gauges_unique=1",
"Referer": "http://www.infoq.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER"
}
url = 'http://www.infoq.com/presentations'
# Download pictures
# The Requests library encapsulates complex interfaces and provides more user-friendly HTTP clients, but does not directly provide functions to download files.
# This needs to be achieved by setting a special parameter stream for the request. When stream is set to True,
# The above request only downloads the HTTP response header and keeps the connection open,
# Until you access response The content of the response body can be downloaded only when the content attribute is
def download_jpg(image_url, image_localpath):
response = requests.get(image_url, stream=True)
if response.status_code == 200:
with open(image_localpath, 'wb') as f:
response.raw.deconde_content = True
shutil.copyfileobj(response.raw, f)
# Get speech pictures
def craw3(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
for pic_href in soup.find_all('div', class_='items__content'):
for pic in pic_href.find_all('img'):
imgurl = pic.get('src')
dir = os.path.abspath('.')
filename = os.path.basename(imgurl)
imgpath = os.path.join(dir, filename)
print('Start downloading %s' % imgurl)
download_jpg(imgurl, imgpath)
# craw3(url)
# Turn pages
j = 0
for i in range(12, 37, 12):
url = 'http://www.infoq.com/presentations' + str(i)
j += 1
print('The first %d page' % j)
craw3(url)