Introduction to ZooKeeper
ZooKeeper(wiki,home,github ) is an open source distributed coordination service for distributed applications.By exposing simple primitives, distributed applications can build higher-level services on top of them, such as synchronization, configuration management, and group membership management.The design is easy to program and the data model uses a well-known file system directory tree structure [doc ].
Consensus and Paxos
Before introducing ZooKeeper, it is important to understand Paxos and Chubby.In 2006, Google published an update on OSDI Bigtable and Chubby Two conference papers, followed by a paper at the 2007 PODC conference. Paxos Made Live "To introduce the consensus on Chubby's underlying implementation ( consensus ) Multi-Paxos protocol, which improves Lamport's original Paxos algorithm and improves its efficiency [ref ].Chubby is used by Google in GFS and Bigtable as a lock service.Influenced by Chubby, Benjamin Reed and Flavio Junqueira from Yahoo Institute developed ZooKeeper, an industry-known open source version of Chubby (internal implementations are actually slightly different) [ref ]), the underlying consensus protocol is ZAB.Lamport's Paxos algorithm is notoriously difficult to understand. How to make the algorithm understandable has become a research topic for Dr. Stanford's Diego Ongaro.Diego Ongaro introduced in 2014 Raft The algorithm paper, "In search of an understandable consensus algorithm".Raft is an understandable version of Paxos and soon became one of the popular protocols for resolving consensus issues.The relationship between these Paxos-like protocols and Paxos systems is as follows [Ailijiang2016 ]:
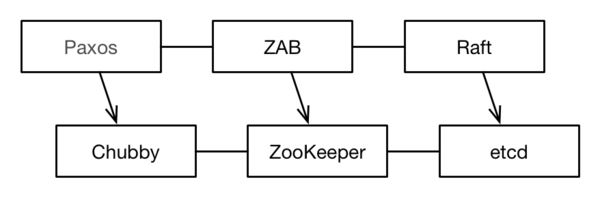
Google's Hubby has no open source, and Yahoo's open source ZooKeeper has become popular in the industry with cloud computing and big data technology.ZooKeeper's important timelines are as follows:
- ZooKeeper 1.0 was released on SourceForge in November 2007 [ref ]
- Migration to Apache from SourceForge started in June 2008 [ref ], released in October at Zookeeper 3.0 and became a subproject of Hadoop [ref1 ref2 ]
Flavio Junqueira and Benjamin Reed describe the source of ZooKeeper names ZooKeeper's book There are the following explanations:
ZooKeeper was developed by Yahoo Research.Our group started recommending ZooKeeper to other groups after a while, so we need to give our project a name.At the same time, the team is working on the Hadoop project and has participated in many animal nomenclature projects, including the well-known Apache Pig project. http://pig.apache.org ).When we were discussing a variety of names, one of the team members mentioned that we could no longer use animal names because our supervisors felt that if we went on like this, we would be living in a zoo.It resonates that a distributed system is like a zoo, chaotic and difficult to manage, and ZooKeeper makes it manageable.
Architecture
The ZooKeeper service consists of several servers, one of which is elected as the master server through the ZAB Atomic Broadcasting Protocol and the other as the follower.Clients can connect to any server through the TCP protocol.If the client is a read operation request, either server can respond directly to the request; if it is an update data operation (write data or update data).Update operations can only be coordinated by the master server; if the client connects to a dependent server, the dependent server forwards the request for update data to the master server, which completes the update operation.The master server serializes all update operations, uses the ZAB protocol to notify all dependent servers of data update requests, and ZAB guarantees update operations.

Read and write operations, as illustrated below [Haloi2015 ]:

Any server on ZooKeeper can respond to client reads, which can improve throughput.Chubby differs from ZooKeeper in that all read/write operations are performed by the master server, which simply improves the usability of the entire coordination system by allowing the master server to quickly elect a new master server from the dependent server after a failure.Along with the high throughput benefits, ZooKeeper has the potential problem of reading out-of-date data to clients because the ZAB protocol has not yet broadcast it to dependent servers even though the master server has updated some memory data.To solve this problem, a sync operation is provided in ZooKeeper's interface API function, which can be called before the application reads the data as needed. This means that the slave server that receives the sync command synchronizes state information from the master server to ensure that they are identical.This way, if you invoke the sync operation before the read operation, you can ensure that the client can read the latest state of the data.
data model
The namespace provided by ZooKeeper is very similar to a standard file system.A series of elements in a path are separated by slashes (/).Each node is identified by a path in the ZooKeper namespace.In ZooKeeper terms, a node is called a znode.By default, each znode can only store up to 1M of data (which can be modified by configuration parameters), just like Chubby, to avoid using the coordinating system as a storage system for applications.Znode can only use absolute paths, relative paths cannot be recognized by ZooKeeper.The znode name can be any Unicode character.The only exception is the name'/zookeeper'.A znode named'/zookeeper'is automatically generated by the ZooKeeper system and managed by quota s.
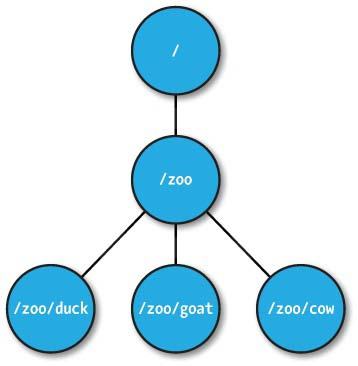
ZooKeeper uses
Installation and Configuration
ZooKeeper installation and startup:
$ brew info zookeeper zookeeper: stable 3.4.10 (bottled), HEAD Centralized server for distributed coordination of services https://zookeeper.apache.org/ ... ellipsis $ brew install zookeeper $ zkServer start # start-up $ zkServer stop # termination $ zkServer help ZooKeeper JMX enabled by default Using config: /usr/local/etc/zookeeper/zoo.cfg Usage: ./zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
If you do not modify the configuration file, the default is to start in single-machine mode.To use cluster mode, you need to modify/usr/local/etc/zookeeper/zoo.cfg (the default path).Example zoo.cfg [doc ]:
tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=192.168.211.11:2888:3888 server.2=192.168.211.12:2888:3888 server.3=192.168.211.13:2888:3888
clientPort: The port on which the client connects to the Zookeeper server, which Zookeeper listens for and accepts client access requests.
server.X=YYY:A:B
- X: The server number represented;
- YYY: Represents the ip address of the server;
- A: Represents the communication port between server nodes for communication between follower and leader nodes;
- B: Represents the election port. Represents the port where the servers communicate with each other when a new leader is elected. When the leader hangs up, the rest of the servers communicate with each other and a new leader is selected.
If you want to experiment with cluster mode on a single host, you can modify both YYY Y to localhost and make the two ports A:B different from each other (e.g., 2888:3888, 2889:3889, 2890:3890) to implement pseudo cluster mode.The example zoo.cfg is as follows [doc ]:
server.1=localhost:2888:3888 server.2=localhost:2889:3889 server.3=localhost:2890:3890
All commands supported by zkCli:
$ zkCli help ZooKeeper -server host:port cmd args stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:port
Node types and their operations
Zookeeper supports two types of nodes: persistent znode and ephemeral znode.Persistent nodes persist regardless of client session, and disappear only when the client explicitly invokes the delete operation.Temporary nodes, on the other hand, are automatically cleaned up by the ZooKeeper system at the end of a client session or when a failure occurs.In addition, both types of nodes can add whether or not they are sequential, which results in persistent and temporary sequential nodes.
(1) persistent znode
Create a node using create (the default persistent node) and view it using get:
$ zkCli # Start Client [zk: localhost:2181(CONNECTED) 1] create /zoo 'hello zookeeper' Created /zoo [zk: localhost:2181(CONNECTED) 2] get /zoo hello zookeeper cZxid = 0x8d ctime = Thu Nov 08 20:42:55 CST 2017 mZxid = 0x8d mtime = Thu Nov 08 20:42:55 CST 2017 pZxid = 0x8d cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 15 numChildren = 0
create creates child nodes and uses ls to view all child nodes:
[zk: localhost:2181(CONNECTED) 3] create /zoo/duck '' Created /zoo/duck [zk: localhost:2181(CONNECTED) 4] create /zoo/goat '' Created /zoo/goat [zk: localhost:2181(CONNECTED) 5] create /zoo/cow '' Created /zoo/cow [zk: localhost:2181(CONNECTED) 6] ls /zoo [cow, goat, duck]
Delete to delete nodes and use rmr to recursively delete:
[zk: localhost:2181(CONNECTED) 7] delete /zoo/duck [zk: localhost:2181(CONNECTED) 8] ls /zoo [cow, goat] [zk: localhost:2181(CONNECTED) 9] delete /zoo Node not empty: /zoo [zk: localhost:2181(CONNECTED) 10] rmr /zoo [zk: localhost:2181(CONNECTED) 11] ls /zoo Node does not exist: /zoo
(2) temporary node (ephemeral znode)
Unlike persistent nodes, temporary nodes cannot create child nodes:
$ zkCli # Start First Client [zk: localhost:2181(CONNECTED) 0] create -e /node 'hello' Created /node [zk: localhost:2181(CONNECTED) 40] get /node hello cZxid = 0x97 ctime = Thu Nov 08 21:01:25 CST 2017 mZxid = 0x97 mtime = Thu Nov 08 21:01:25 CST 2017 pZxid = 0x97 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x161092a0ff30000 dataLength = 5 numChildren = 0 [zk: localhost:2181(CONNECTED) 1] create /node/child '' Ephemerals cannot have children: /node/child
Temporary nodes are automatically cleared by the ZooKeeper system at the end of a client session or when a failure occurs.Now under the pilot monitoring for temporary node auto-cleanup:
$ zkCli # Start 2nd Client [zk: localhost:2181(CONNECTED) 0] create -e /node 'hello' Node already exists: /node [zk: localhost:2181(CONNECTED) 1] stat /node true cZxid = 0x97 ctime = Thu Nov 08 21:01:25 CST 2017 mZxid = 0x97 mtime = Thu Nov 08 21:01:25 CST 2017 pZxid = 0x97 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x161092a0ff30000 dataLength = 5 numChildren = 0
If Client 1 quit s or crashes, Client 2 receives a monitoring event:
[zk: localhost:2181(CONNECTED) 2] WATCHER:: WatchedEvent state:SyncConnected type:NodeDeleted path:/node
(3) sequential znode
ZooKeeper automatically appends a sequence number to the znode name when a sequential node is created.Sequential number maintained by parent znode and monotonically increasing.A sequential number consisting of 4 bytes of signed integers and formatted as a 10-digit number filled with 0.
[zk: localhost:2181(CONNECTED) 1] create /test '' Created /test [zk: localhost:2181(CONNECTED) 2] create -s /test/seq '' Created /test/seq0000000000 [zk: localhost:2181(CONNECTED) 3] create -s /test/seq '' Created /test/seq0000000001 [zk: localhost:2181(CONNECTED) 4] create -s /test/seq '' Created /test/seq0000000002 [zk: localhost:2181(CONNECTED) 5] ls /test [seq0000000000, seq0000000001, seq0000000002]
Client API
The main znode operation API s provided by ZooKeeper are as follows:
| API operations | describe | CLI Command |
|---|---|---|
| create | Create znode | create |
| delete | Delete znode | delete/rmr/delquota |
| exists | Check if znode exists | stat |
| getChildren | Read all child nodes of znode | ls/ls2 |
| getData | Reading znode data | get/listquota |
| setData | Setting znode data | set/setquota |
| getACL | ACL to read znode | getACL |
| setACL | Setting ACL for znode | setACL |
| sync | synchronization | sync |
Java ZooKeeper Class implements the API provided above.
The bottom level of Zookeeper is a Java implementation, and the bottom level of the zkCli command line tool is a Java implementation, with the corresponding Java implementation class being org.apache.zookeeper.ZooKeeperMain [src1 src2 ].Under ZooKeeper 3.5.x, CLI commands correspond to the underlying implementation API:
| Name CLI | Java API (ZooKeeper Class) |
|---|---|
| addauth scheme auth | public void addAuthInfo(String scheme, byte[] auth) |
| close | public void close() |
| create [-s] [-e] path data acl | public String create(final String path, byte data[], List<ACL> acl, CreateMode createMode) |
| delete path [version] | public void delete(String path, int version) |
| delquota [-n|-b] path | public void delete(String path, int version) |
| get path [watch] | public byte[] getData(String path, boolean watch, Stat stat) |
| getAcl path | public List<ACL> getACL(final String path, Stat stat) |
| listquota path | public byte[] getData(String path, boolean watch, Stat stat) |
| ls path [watch] | public List<String> getChildren(String path, Watcher watcher, Stat stat) |
| ls2 path [watch] | - |
| quit | public void close() |
| rmr path | public void delete(final String path, int version) |
| set path data [version] | public Stat setData(String path, byte[] data, int version) |
| setAcl path acl | public Stat setACL(final String path, List<ACL> acl, int aclVersion) |
| setquota -n|-b val path | public Stat setData(String path, byte[] data, int version) |
| stat path [watch] | public Stat exists(String path, boolean watch) |
| sync path | public void sync(String path, AsyncCallback.VoidCallback cb, Object ctx) |
watch
ZooKeeper provides an important mechanism for dealing with change: watch.Through a monitoring point, clients can register a notification request for a specified znode node and receive a single notification when a change occurs.When an application registers a monitoring point to receive notifications, the first event matching the monitoring point condition triggers the monitoring point's notification, at most once.For example, when a znode node is also deleted, the client needs to be aware of the change. The client performs exists operations on the / z node and sets the monitoring point flag bits, waits for notification, and the client receives notification as a callback function.
Read operations in ZooKeeper's API: getData, getChildren, and exists, all have the option of setting a monitoring point on the read znode.Using the monitoring point mechanism, we need to implement Watcher An interface class whose only method is process:
void process(WatchedEvent event)
WatchedEvent The data structure includes the following information:
- ZooKeeper Session State: Disconnected, SyncConnected, AuthFailed, ConnectedReadOnly, SaslAuthenticated, Expired.
- EventType: NodeCreated, NodeDeleted, NodeDataChanged, NodeChildrenChanged, and None.
- If the event type is not None, the znode path is also included.
If a WatchedEvent is received, the following results will be output in zkCli:
WatchedEvent state:SyncConnected type:NodeDeleted path:/node
There are two types of monitoring points: data monitoring point and child node monitoring point.Creating, deleting, or setting data for a znode node triggers a data monitoring point, which can be set by two operations, exists and getData.Only getChildren operations can set child node watchpoints, which are triggered only when a znode child node is created or deleted.For each event type, we set the monitoring point by calling:
NodeCreated
Set up a monitoring point through the exists call.
NodeDeleted
Set up monitoring points through exists or getData calls.
NodeDataChanged
Set up monitoring points through exists or getData calls.
NodeChildrenChanged
Set up a monitoring point through a getChildren call.
Java sample code
Using ZooKeeper in Java requires adding the following first maven Dependency:
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.11</version> <type>pom</type> </dependency>
The ZookeeperDemo example shows how to set up a connection session and create, read, modify, delete, and set a monitoring point for a znode:
import java.io.IOException; import org.apache.commons.lang3.time.DateFormatUtils; import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; public class ZookeeperDemo { public static void main(String[] args) throws KeeperException, InterruptedException, IOException { // Create a server connection ZooKeeper zk = new ZooKeeper("127.0.0.1:2181", 100, new Watcher() { // Monitor all triggered events public void process(WatchedEvent event) { System.out.printf("WatchedEvent state:%s type:%s path:%s\n", event.getState(), event.getType(), event.getPath()); } }); // Create Node zk.create("/zoo", "hello ZooKeeper".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); // Read Node Data Stat stat = new Stat(); System.out.println(new String(zk.getData("/zoo", false, stat))); printStat(stat); // Create Child Node zk.create("/zoo/duck", "hello duck".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); zk.create("/zoo/goat", "hello goat".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); zk.create("/zoo/cow", "hello cow".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); // Read the list of child nodes and set monitoring points System.out.println(zk.getChildren("/zoo", true)); // Read child node data and set monitoring points System.out.println(new String(zk.getData("/zoo/duck", true, null))); // Modify child node data zk.setData("/zoo/duck", "hi duck".getBytes(), -1); // Read modified child node data System.out.println(new String(zk.getData("/zoo/duck", true, null))); // Delete child nodes zk.delete("/zoo/duck", -1); zk.delete("/zoo/goat", -1); zk.delete("/zoo/cow", -1); // Delete parent node zk.delete("/zoo", -1); // Close Connection zk.close(); } private static void printStat(Stat stat) { System.out.println("cZxid = 0x" + Long.toHexString(stat.getCzxid())); System.out.println("ctime = " + DateFormatUtils.format(stat.getCtime(), "yyyy-MM-dd HH:mm:ss")); System.out.println("mZxid = 0x" + Long.toHexString(stat.getMzxid())); System.out.println("mtime = " + DateFormatUtils.format(stat.getMtime(), "yyyy-MM-dd HH:mm:ss")); System.out.println("pZxid = 0x" + Long.toHexString(stat.getPzxid())); System.out.println("cversion = " + stat.getCversion()); System.out.println("dataVersion = " + stat.getVersion()); System.out.println("aclVersion = " + stat.getAversion()); System.out.println("ephemeralOwner = 0x" + Long.toHexString(stat.getEphemeralOwner())); System.out.println("dataLength = " + stat.getDataLength()); System.out.println("numChildren = " + stat.getNumChildren()); } }
Output results:
WatchedEvent state:SyncConnected type:None path:null hello ZooKeeper cZxid = 0x1e1 ctime = 2017-11-20 12:18:36 mZxid = 0x1e1 mtime = 2017-11-20 12:18:36 pZxid = 0x1e1 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 15 numChildren = 0 [cow, goat, duck] hello duck WatchedEvent state:SyncConnected type:NodeDataChanged path:/zoo/duck hi duck WatchedEvent state:SyncConnected type:NodeDeleted path:/zoo/duck WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/zoo
ZooInspector
ZooInspector is an official tool for visualizing and editing ZooKeeper instances starting with ZooKeeper 3.3.0 [ZOOKEEPER-678 ].The source code is located in the directory src/contrib/zooinspector with GitHub address: link .You can run it according to the instructions in README.txt.Or you can use the executable jar package provided under ZOOKEEPER-678 directly.

Reference material
- Official Document: ZooKeeper http://zookeeper.apache.org/d...
- Schilling Wave 2010-11: Zookeeper, Distributed Services Framework https://www.ibm.com/developer...
- ZooKeeper: Detailed Distributed Process Collaboration Technology, Benjamin Reed & Flavio Junqueira, 2013, Douban
- Apache ZooKeeper Essentials, Haloi 2015,Douban
- From Paxos to Zookeeper, Ali Ni Chao 2015, Douban
- Daily Record of Big Data: Architecture and Algorithms, Zhang Junlin 2014, Chapter 5 Distributed Coordination System, Douban
- 2010,Patrick Hunt, Mahadev Konar, Flavio Paiva Junqueira, Benjamin Reed: ZooKeeper: Wait-free Coordination for Internet-scale Systems. USENIX ATC 2010,dblp,msa,usenix