1, Introduction to ZooKeeper
ZooKeeper Description: it is a distributed, open source distributed application coordination service
ZooKeeper's goal is to encapsulate complex and error prone key services and provide users with simple and easy-to-use interfaces and systems with efficient performance and stable functions.
ZooKeeper features:
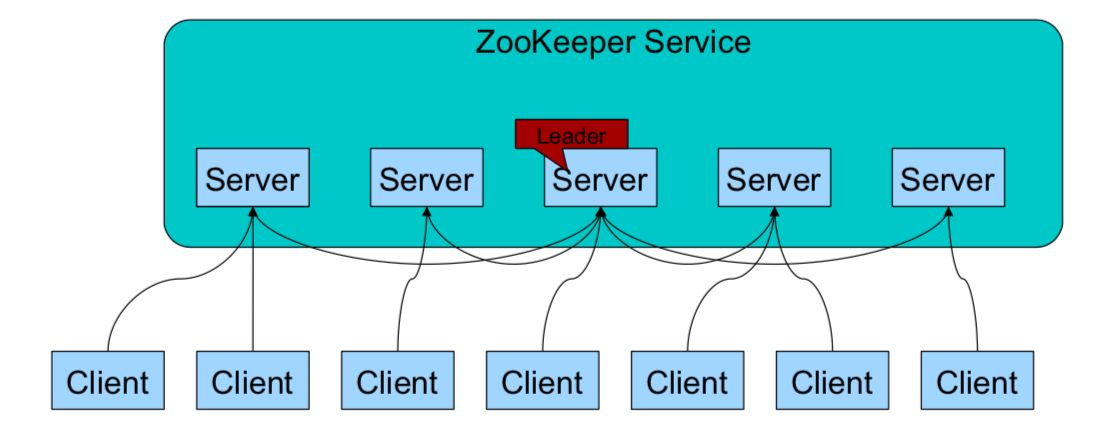
1. Zookeeper: a cluster composed of one leader and multiple followers.
2. As long as more than half of the nodes in the cluster survive, the Zookeeper cluster can serve normally.
3. Global data consistency: each Server saves a copy of the same data. No matter which Server the Client connects to, the data is consistent.
4. The update requests are made in sequence, and the update requests from the same Client are executed in sequence according to their sending order.
5. Data update atomicity. A data update either succeeds or fails.
6. Real time. Within a certain time range, the Client can read the latest data.
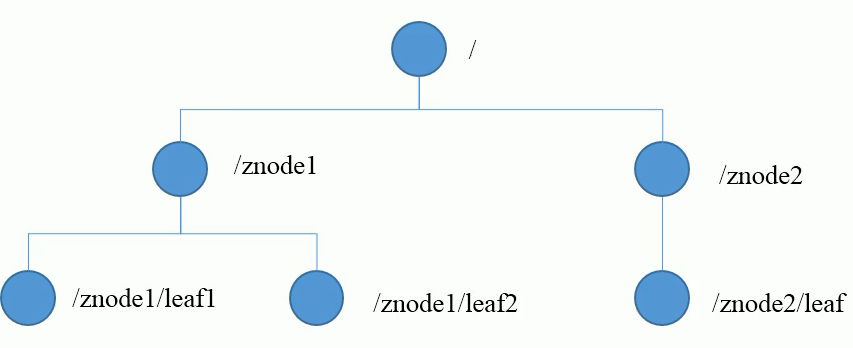
Data structure of ZooKeeper: tree
The structure of ZooKeeper data model is very similar to that of Unix file system. On the whole, it can be regarded as a tree, and each node is called a ZNode.
Each ZNode can store 1MB of data by default, and each ZNode can be uniquely identified through its path.
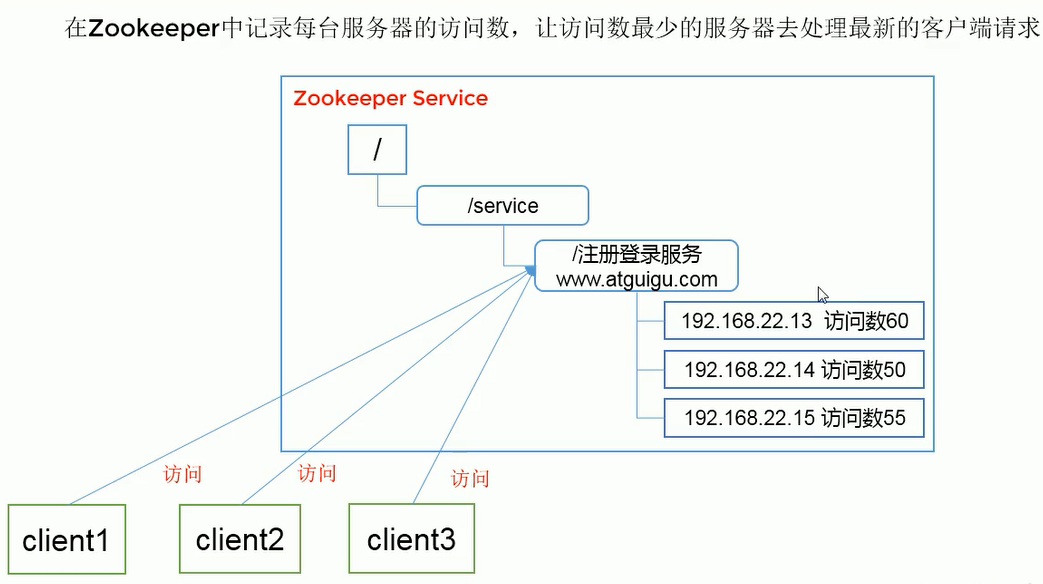
Application scenario of ZooKeeper: the services provided include: unified naming service, unified configuration management, unified cluster management, dynamic uplink and downlink of server nodes, soft load balancing, etc.,
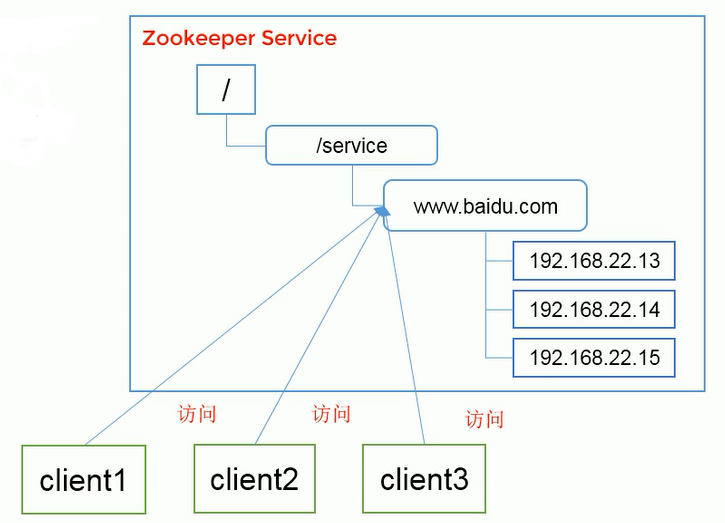
Unified naming service
In the distributed environment, it is often necessary to uniformly name applications / services for easy identification.
For example: IP is not easy to remember, while domain name is easy to remember.
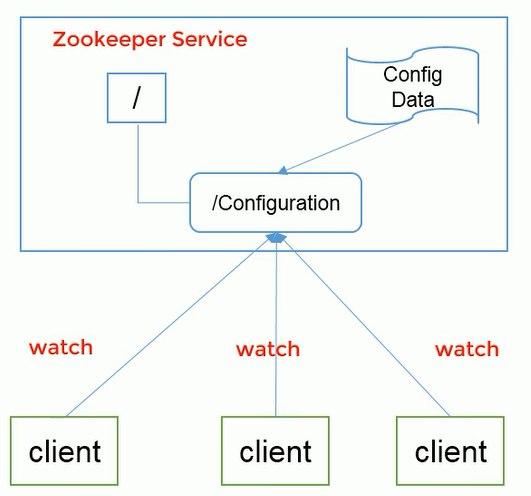
Unified configuration management
1) In distributed environment, profile synchronization is very common.
(1) Generally, the configuration information of all nodes in a cluster is consistent, such as Kafka cluster.
(2) After modifying the configuration file, you want to be able to quickly synchronize to each node.
2) Configuration management can be implemented by ZooKeeper.
(1) The configuration information can be written to a Znode on the ZooKeeper.
(2) Each client server listens to this Znode.
(3) Once the data in Znode is modified, ZooKeeper will notify each client server.
Unified cluster management
1) In distributed environment, it is necessary to master the state of each node in real time.
(1) Some adjustments can be made according to the real-time status of the node.
2)ZooKeeper can monitor node status changes in real time
(1) Node information can be written to a ZNode on the ZooKeeper.
(2) Monitoring this ZNode can obtain its real-time state changes.
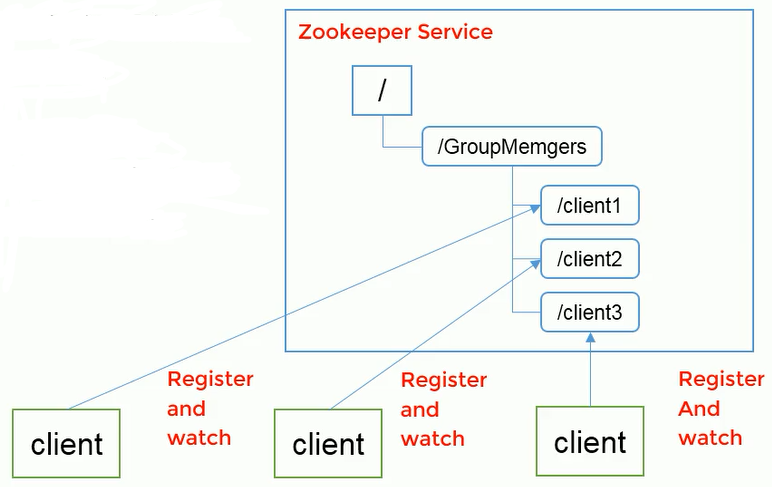
Server node dynamic uplink and downlink
Soft load balancing.
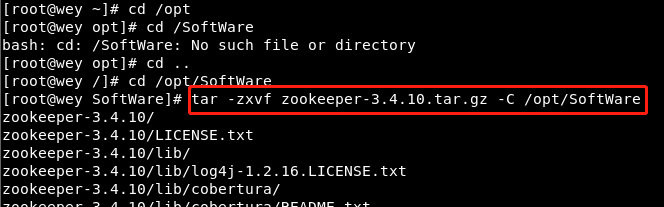
2, Download and installation of ZooKeeper
Download address of ZooKeeper
https://zookeeper.apache.org/releases.html#download
or
http://archive.apache.org/dist/zookeeper/
decompression
Modify profile name
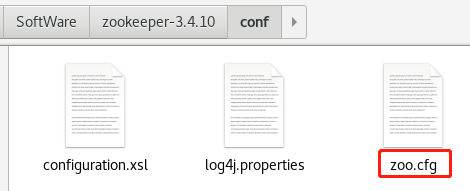
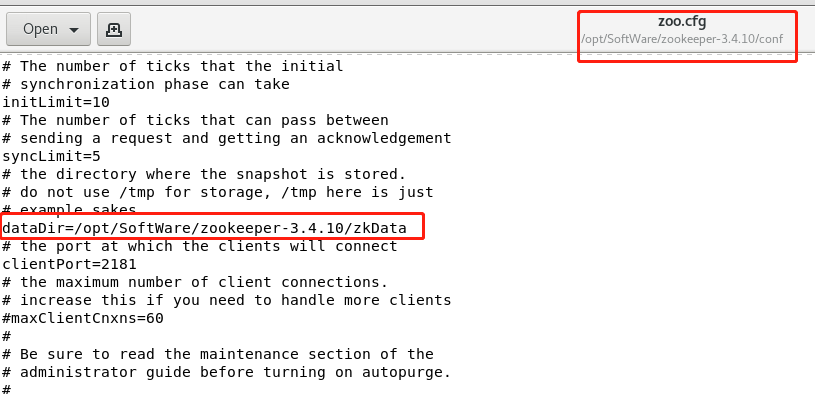
Modify storage path
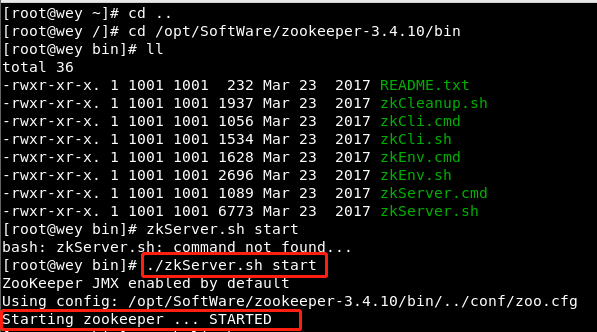
Start service
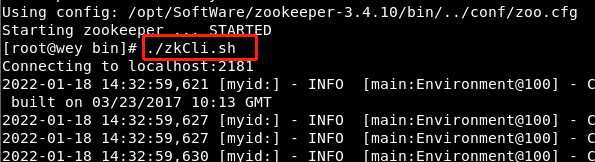
Start client
Close client
Close the server

3, Interpretation of configuration parameters
The configuration file zoo. In Zookeeper The meaning of parameters in CFG is interpreted as follows:
1. Ticketime = 2000: Communication heartbeat, heartbeat time between Zookeeper server and client, unit: Ms
The basic time used by Zookeeper, the time interval between servers or between clients and servers to maintain heartbeat, that is, one heartbeat will be sent every tickTime, and the time unit is milliseconds.
It is used for the heartbeat mechanism and sets the minimum session timeout to twice the heartbeat time. (the minimum timeout of session is 2*tickTime)
2. initLimit =10: initial communication time limit of LF
The maximum number of heartbeats that can be tolerated during the initial connection between the Follower server and the Leader leader server in the cluster (the number of ticktimes), which is used to limit the time limit for the Zookeeper server in the cluster to connect to the Leader.
3. syncLimit =5: LF synchronous communication time limit
The maximum response time unit between the Leader and the Follower in the cluster. If the response exceeds syncLimit * tickTime, the Leader thinks the Follower is dead and deletes the Follower from the server list.
4. dataDir: data file directory + data persistence path
It is mainly used to save the data in Zookeeper.
5. clientPort =2181: client connection port
Listen to the port of the client connection.
4, Zookeeper internal principle
3.1 election mechanism (key points of interview)
1) Half mechanism: more than half of the machines in the cluster survive and the cluster is available. Therefore, Zookeeper is suitable for installing an odd number of servers.
2) Zookeeper does not specify Master and Slave in the configuration file. However, when zookeeper works, one node is a Leader and the other is a Follower. The Leader is temporarily generated through the internal election mechanism.
3) A simple example is given to illustrate the whole election process.
Suppose there is a Zookeeper cluster composed of five servers. Their IDs range from 1 to 5. At the same time, they are all newly started, that is, there is no historical data. The amount of data stored is the same. Suppose these servers start up in sequence to see what happens,
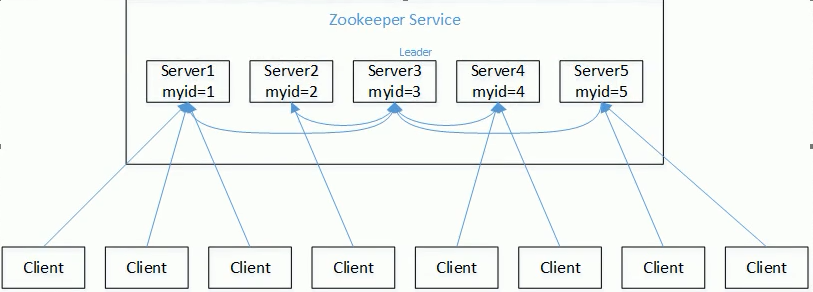
(1) Server 1 is started. At this time, only one server is started. There is no response to the message sent by it, so its election state is always LOOKING.
(2) Server 2 is started. It communicates with the server 1 started at the beginning and exchanges its election results with each other. Since both have no historical data, server 2 with a large id value wins. However, since more than half of the servers do not agree to elect it (more than half of the servers in this example are 3), Therefore, servers 1 and 2 continue to keep LOOKING.
(3) Server 3 starts. According to the previous theoretical analysis, server 3 becomes the Leader of servers 1, 2 and 3. Different from the above, three servers elect it at this time, so it becomes the Leader of this election.
(4) Server 4 starts. According to the previous analysis, theoretically, server 4 should be the largest of servers 1, 2, 3 and 4. However, since more than half of the previous servers have elected server 3, it can only accept the life of a younger brother.
(5) Server 5 starts, just like 4.
5, Node type
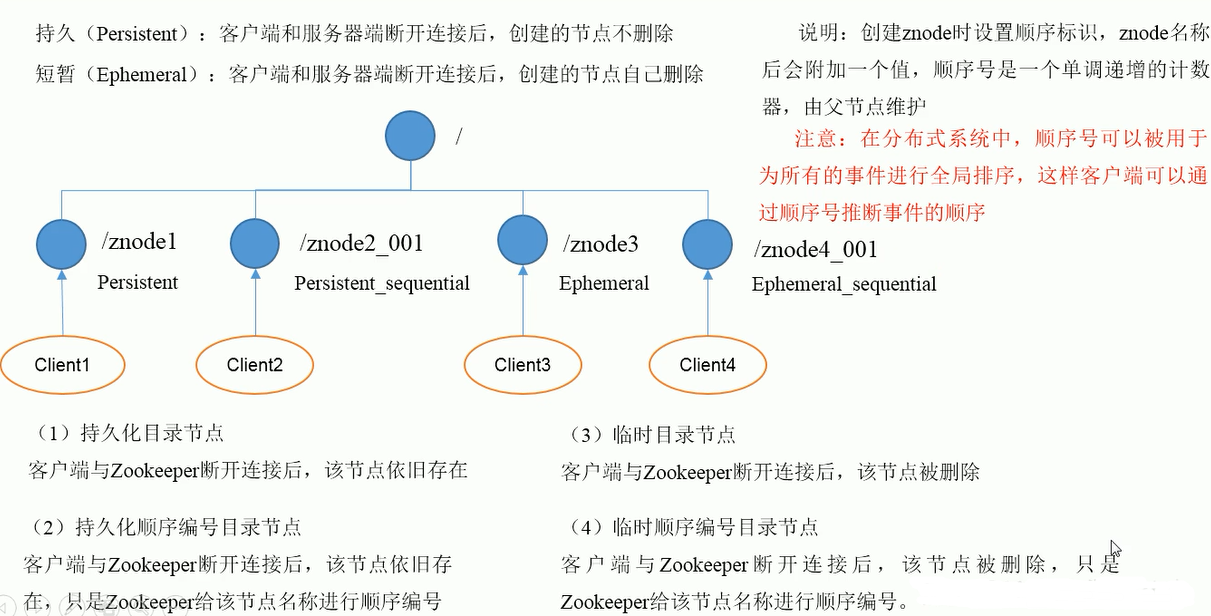
6, Stat structure
1) C zxid - create a transaction for the node
Each time you modify the ZooKeeper state, you will receive a zxid form of timestamp, that is, the ZooKeeper transaction ID.
The transaction ID is the total order of all modifications in ZooKeeper. Each modification has a unique zxid. If zxid1 is less than zxid2, zxid1 occurs before zxid2.
2) CTime - the number of milliseconds in which a znode was created (since 1970)
3) Mzxid - transaction zxid last updated by znode
4) Mtime - number of milliseconds last modified by znode (since 1970)
5) Pzxid znode last updated child node zxid
6) Cversion - change number of znode child node, and modification times of znode child node
7) dataversion - znode data change number
8) Aclversion - change number of znode access control list
9) Ephemeral owner - if it is a temporary node, this is the session id of the znode owner. 0 if it is not a temporary node.
10) Datalength - the data length of znode
11) Numchildren - number of znode child nodes
7, Principle of listener (key points of interview)
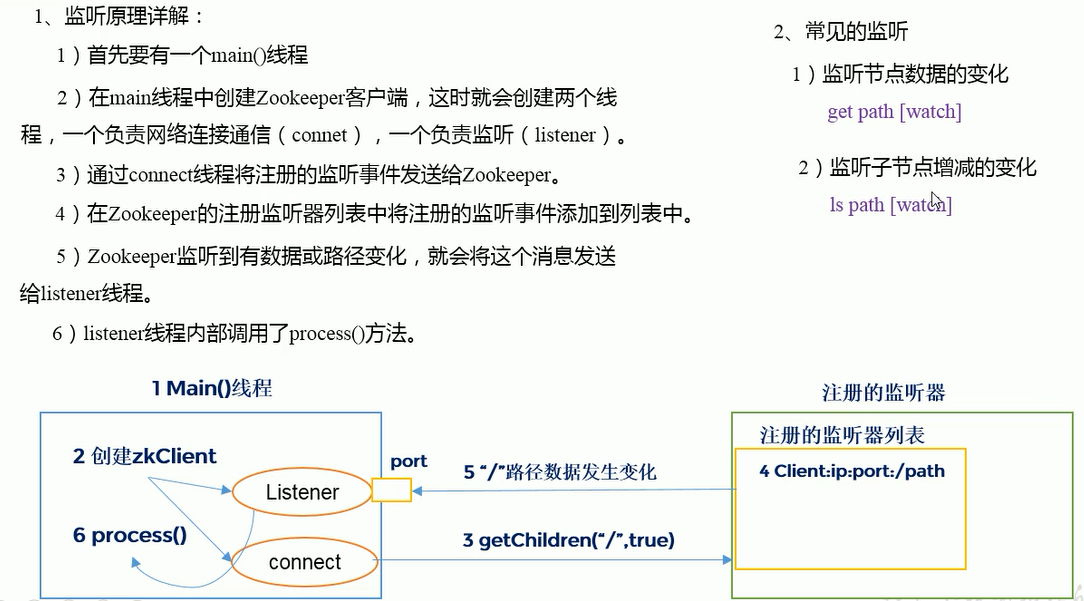
8, Write data flow
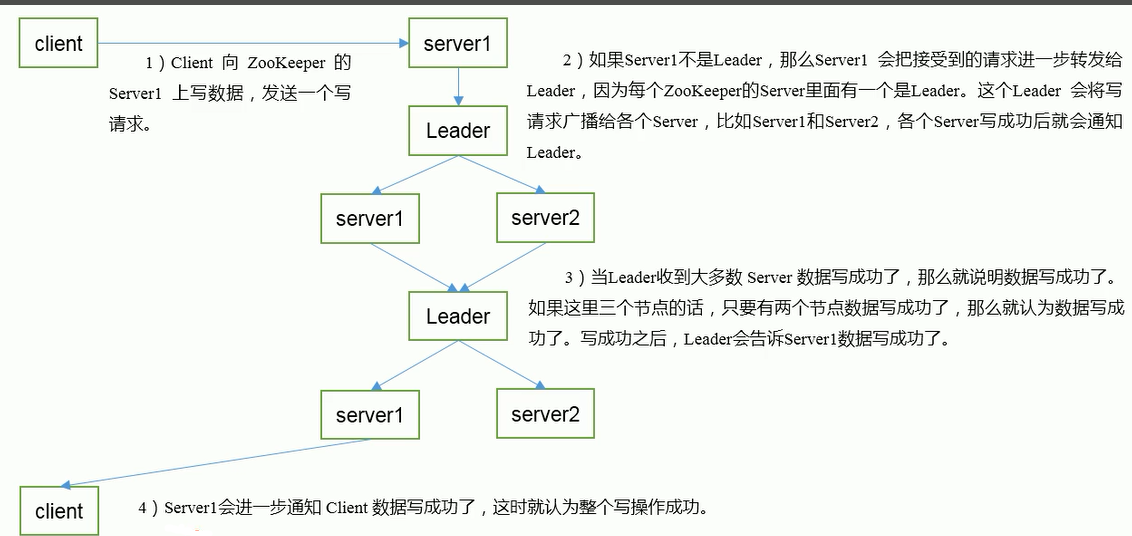
9, Zookeeper actual combat (development focus)
1. Cluster planning
Deploy Zookeeper on Hadoop 102, Hadoop 103 and Hadoop 104 nodes.
10, API Application
Eclipse environment construction
1. Create a Maven project
2. Add pom file
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.10</version>
</dependency>
</dependencies>
Copy log4j The properties file to the project root directory
You need to create a new file named "log4j.properties" in the src/main/resources directory of the project, and fill in the file.
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
Create ZooKeeper client
private static String connectString =
"hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zkClient = null;
@Before
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Callback function after receiving event notification (user's business logic)
System.out.println(event.getType() + "--" + event.getPath());
// Start listening again
try {
zkClient.getChildren("/", true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
Create child node
// Create child node
@Test
public void create() throws Exception {
// Parameter 1: the path of the node to be created; Parameter 2: node data; Parameter 3: node permission; Parameter 4: type of node
String nodeCreated = zkClient.create("/atguigu", "jinlian".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
Get child nodes and listen for node changes
// Get child nodes
@Test
public void getChildren() throws Exception {
List<String> children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
// Delay blocking
Thread.sleep(Long.MAX_VALUE);
}
Determine whether Znode exists
// Determine whether znode exists
@Test
public void exist() throws Exception {
Stat stat = zkClient.exists("/eclipse", false);
System.out.println(stat == null ? "not exist" : "exist");
}
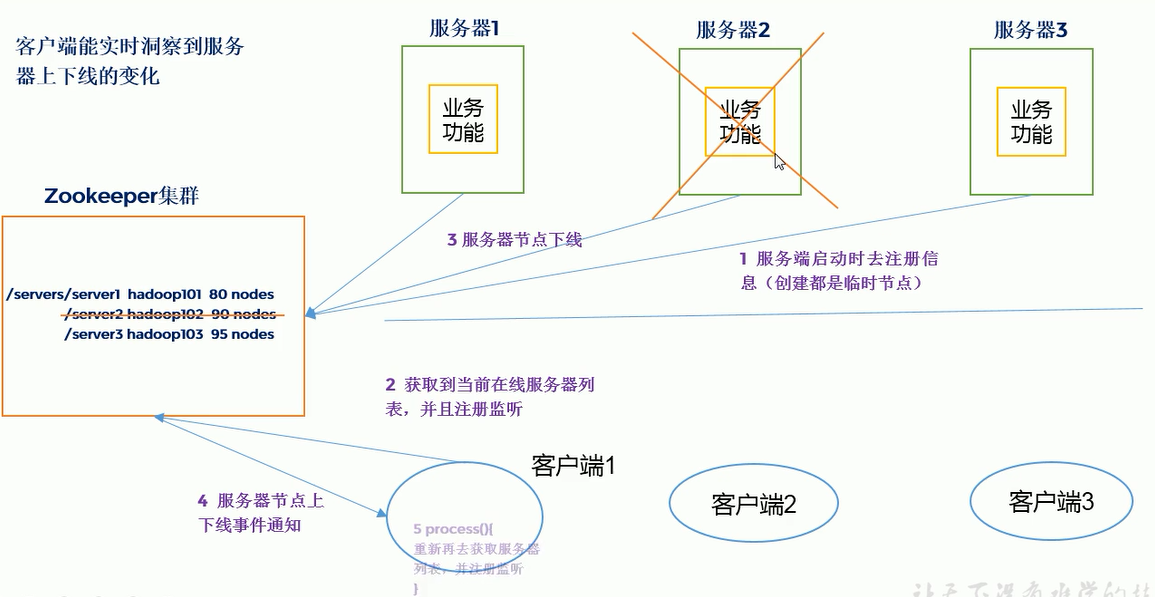
11, Listen for dynamic uplink and downlink cases of server nodes
1. Demand
In a distributed system, there can be multiple master nodes, which can dynamically go online and offline. Any client can sense the online and offline of the master node server in real time.
2. Demand analysis, as shown in the figure
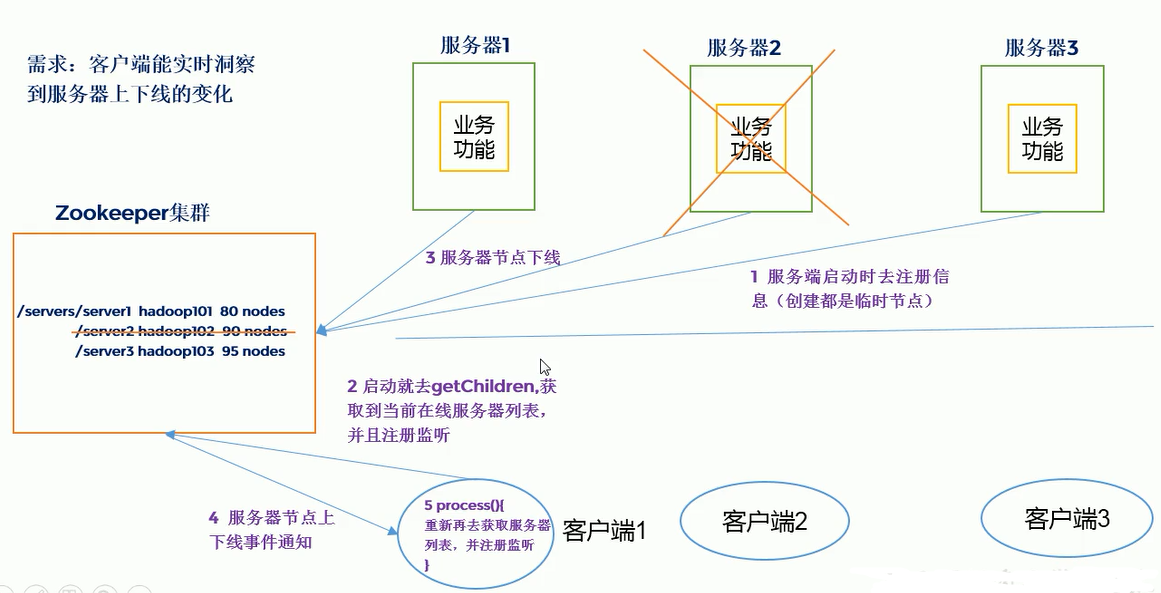
(1) The server side registers the code with Zookeeper
package com.atguigu.zkcase;
import java.io.IOException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.ZooDefs.Ids;
public class DistributeServer {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// Create a client connection to zk
public void getConnect() throws IOException{
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
// Registration server
public void registServer(String hostname) throws Exception{
String create = zk.create(parentNode + "/server", hostname.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname +" is online "+ create);
}
// Business function
public void business(String hostname) throws Exception{
System.out.println(hostname+" is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1 get zk connection
DistributeServer server = new DistributeServer();
server.getConnect();
// 2 use zk connection to register server information
server.registServer(args[0]);
// 3 start business function
server.business(args[0]);
}
}
(2) Client code
package com.atguigu.zkcase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
public class DistributeClient {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// Create a client connection to zk
public void getConnect() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Start listening again
try {
getServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
// Get server list information
public void getServerList() throws Exception {
// 1 obtain the information of the server's child nodes and listen to the parent nodes
List<String> children = zk.getChildren(parentNode, true);
// 2 storage server information list
ArrayList<String> servers = new ArrayList<>();
// 3 traverse all nodes to obtain the host name information in the node
for (String child : children) {
byte[] data = zk.getData(parentNode + "/" + child, false, null);
servers.add(new String(data));
}
// 4 print server list information
System.out.println(servers);
}
// Business function
public void business() throws Exception{
System.out.println("client is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1 get zk connection
DistributeClient client = new DistributeClient();
client.getConnect();
// 2 get the child node information of servers and get the server information list from it
client.getServerList();
// 3. Business process startup
client.business();
}
}
12, Enterprise interview questions
Please briefly describe the election mechanism of ZooKeeper
Half mechanism
What is the monitoring principle of ZooKeeper?
See 7 for details.
5.3 what are the deployment methods of zookeeper? What are the roles in the cluster? How many machines does the cluster need at least?
(1) Deployment mode: stand-alone mode and cluster mode
(2) Roles: Leader and Follower
(3) Minimum number of machines required for cluster: 3
5.4 common commands of zookeeper
ls create get delete set...
Refer to: https://www.cnblogs.com/woju/p/15691349.html