1, Introduction to longicorn whisker search algorithm
1. Definition of longicorn whisker search algorithm
Beetle antennae search bas, also known as beetle search, is an efficient intelligent optimization algorithm proposed in 2017. Similar to intelligent optimization algorithms such as genetic algorithm, particle swarm optimization algorithm and simulated annealing, longicorn can achieve efficient optimization without knowing the specific form of function and virtual gradient information. Compared with particle swarm optimization algorithm, there is only one individual, that is, one longicorn, which greatly reduces the amount of computation.
2 principle and code implementation
2.1 bionic principle
The algorithm is developed inspired by the foraging principle of longicorn beetles.
Biological principle: when the cattle forage that day, the longicorn does not know where the food is, but forages according to the strength of the food smell. Longicorn beetles have two long antennae. If the odor intensity received by the left antennae is greater than that on the right, the next step is for longicorn beetles to fly to the left, otherwise they will fly to the right. According to this simple principle, longicorn beetles can find food effectively.
Inspiration from longicorn beetle whisker search: the smell of food is equivalent to a function. Each point value of this function is different in three-dimensional space. The two longicorn beetles can collect the smell values of two points near themselves. The purpose of longicorn beetle is to find the point with the largest global smell value. Following the behavior of longicorn beetles, we can efficiently optimize the function.
2.2 algorithm
Longicorn moves in three-dimensional space, and longicorn search needs to be effective for any dimensional function. Therefore, longicorn beetle whisker search is a generalization of longicorn beetle biological behavior in any dimensional space. The following simplified model assumptions are used to describe longicorn beetles:
The left and right sides of the longicorn must be located on both sides of the center of mass.
The ratio of step length of longicorn beetle to the distance d0 between two whiskers is a fixed constant, that is, step=c*d0, where c is a constant. That is, the big longicorn (the distance between the two whiskers is long) takes a big step and the little longicorn takes a small step.
After the longicorn flies to the next step, the orientation of its head is random.
2.3 modeling: (n-dimensional space function f minimization)
Step 1: for an optimization problem in n-dimensional space, we use XL to represent the left whisker coordinate, XR to represent the right whisker coordinate, X to represent the centroid coordinate, and d0 to represent the distance between the two whiskers. According to hypothesis 3, the orientation of tianniu's head is arbitrary, so the orientation of the vector from tianniu's right whisker to its left whisker is also arbitrary, so a random vector dir=rands(n,1) can be generated to represent it. Normalization: dir=dir/norm(dir); In this way, we can get XL XR = d0dir; Obviously, XL and XR can also be expressed as the expression of the center of mass; xl=x+d0dir/2; xr=x-d0dir/2.
Step 2: for the function f to be optimized, find the left and right values: felft=f(xl); fright=f(xr); Judge the size of the two values. If fleft < fright, in order to find the minimum value of F, the longicorn beetle travels a distance step towards the left whisker, i.e. x = x + stepnormal (XL XR); If flight > fright, in order to find the minimum value of F, longicorn beetles travel a distance step towards the right whisker, i.e. x = x-stepnormal (XL XR); For example, in the above two cases, the sign function sign can be uniformly written as: x = x-stepnormal (XL XR) sign (fleet fry) = x-stepdir * sign (fleet fry).
(Note: where normal is the normalization function)
Loop iteration:
dir=rands(n,1); dir=dir/norm(dir);% Direction of whisker
xl=x+d0dir/2; xr=x-d0dir/2;% Required coordinates
felft=f(xl); fright=f(xr);% Odor intensity of whiskers
x=x-stepdirsign(fleft-fright). % Next position
About step size:
Two recommendations:
Step = etatep is used in each iteration, where eta is between 0 and 1, close to 1, and eta=0.95 is usually taken;
Introduce a new variable temp and final resolution step0, temp=etatemp, step=temp+step0
About the initial step size: the initial step size can be as large as possible, preferably equivalent to the maximum length of the independent variable.
2, Introduction to BP neural network
1 overview of BP neural network
BP (Back Propagation) neural network was proposed by the scientific research team headed by Rumelhart and McCelland in 1986. See their paper learning representations by Back Propagation errors published in Nature.
BP neural network is a multilayer feedforward network trained by error back propagation algorithm. It is one of the most widely used neural network models at present. BP network can learn and store a large number of input-output mode mapping relationships without revealing the mathematical equations describing this mapping relationship in advance. Its learning rule is to use the steepest descent method and continuously adjust the weight and threshold of the network through back propagation to minimize the sum of squares of the network error.
2 basic idea of BP algorithm
Last time we mentioned that multilayer perceptron encountered a bottleneck in how to obtain the weight of hidden layer. Since we can't get the weight of the hidden layer directly, can we indirectly adjust the weight of the hidden layer by getting the error between the output result and the expected output from the output layer? BP algorithm is designed with this idea. Its basic idea is that the learning process consists of two processes: forward propagation of signal and back propagation of error.
During forward propagation, the input samples are transmitted from the input layer, processed layer by layer by hidden layer, and then transmitted to the output layer. If the actual output of the output layer is inconsistent with the expected output (teacher signal), it will turn to the back propagation stage of error.
During back propagation, the output is transmitted back to the input layer layer by layer through the hidden layer in some form, and the error is allocated to all units of each layer, so as to obtain the error signal of each layer unit, which is used as the basis for correcting the weight of each unit. The specific processes of these two processes will be introduced later.
The signal flow diagram of BP algorithm is shown in the figure below
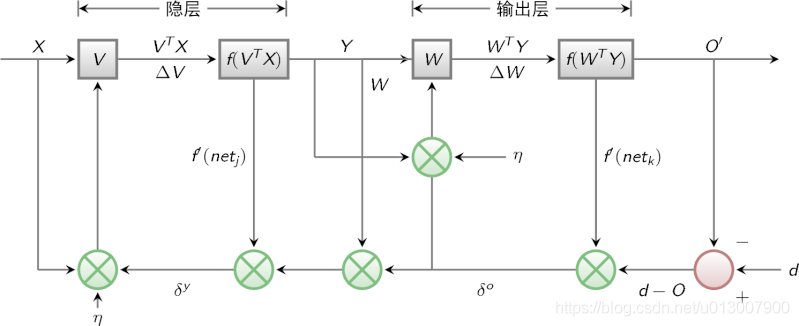
3 characteristic analysis of BP Network - three elements of BP
When we analyze an ANN, we usually start with its three elements, namely
1) Network topology;
2) Transfer function;
3) Learning algorithm.
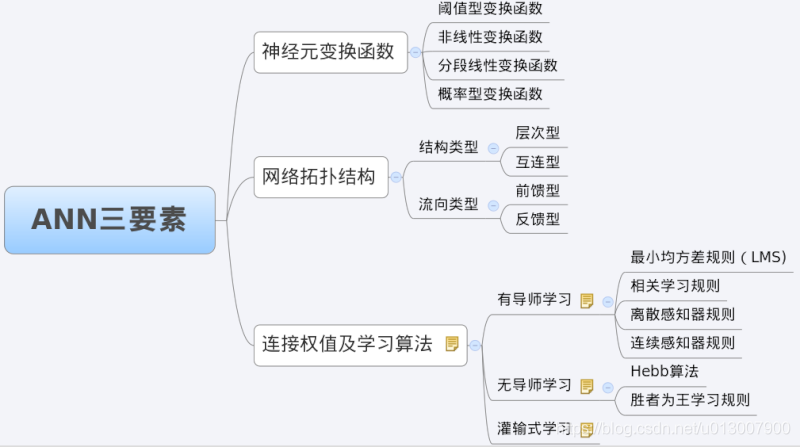
The characteristics of each element together determine the functional characteristics of the ANN. Therefore, we also study BP network from these three elements.
3.1 topology of BP network
As I said last time, BP network is actually a multilayer perceptron, so its topology is the same as that of multilayer perceptron. Because the single hidden layer (three-layer) perceptron can solve simple nonlinear problems, it is most widely used. The topology of the three-layer perceptron is shown in the figure below.
The simplest three-layer BP:
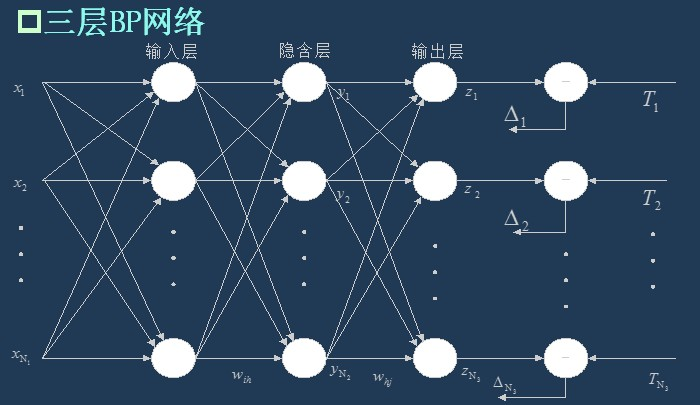
3.2 transfer function of BP network
The transfer function used in BP network is a nonlinear transformation function - Sigmoid function (also known as S function). Its characteristic is that the function itself and its derivatives are continuous, so it is very convenient in processing. Why should we choose this function? I will give a further introduction when introducing the learning algorithm of BP network.
Unipolar S-type function curve is shown in the figure below.
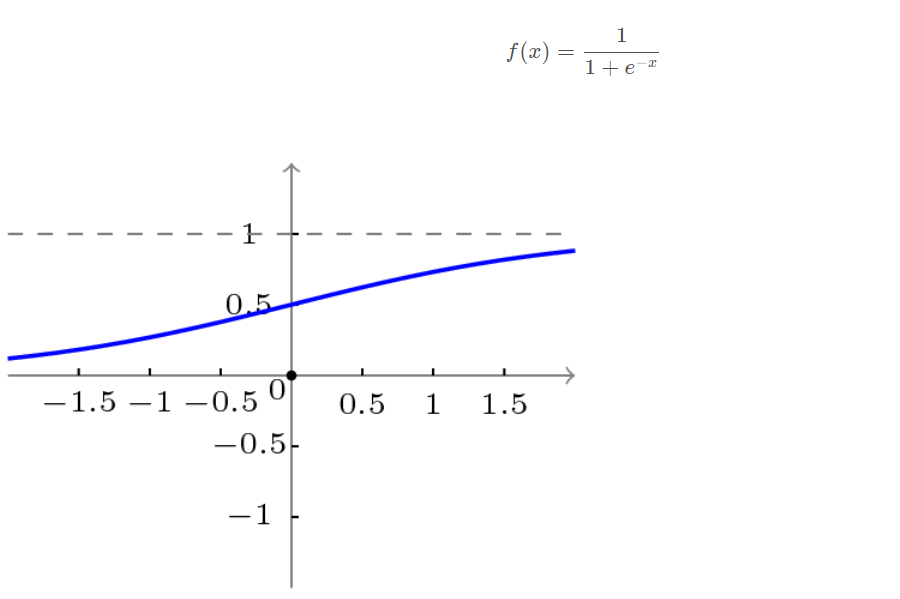
Bipolar S-type function curve is shown in the figure below.
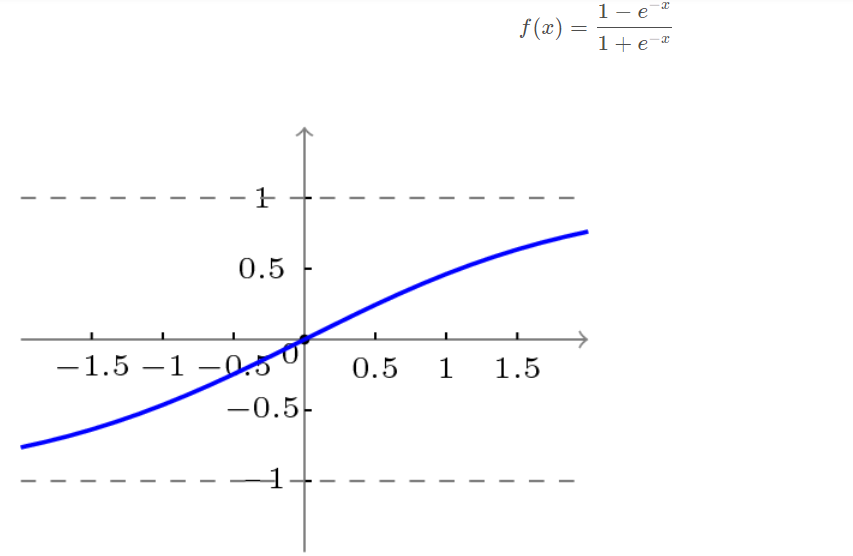
3.3 learning algorithm of BP network
The learning algorithm of BP network is BP algorithm, also known as BP algorithm δ Algorithm (we will find many terms with multiple names in the learning process of ANN). Taking the three-layer perceptron as an example, when the network output is different from the expected output, there is an output error E, which is defined as follows



Next, we will introduce the specific process of BP network learning and training.
4 training decomposition of BP network
Training a BP neural network is actually adjusting the weight and bias of the network. The training process of BP neural network is divided into two parts:
Forward transmission, wave transmission output value layer by layer;
Reverse feedback, reverse layer by layer adjustment of weight and bias;
Let's look at forward transmission first.
Forward transmission (feed forward feedback)
Before training the network, we need to initialize weights and offsets randomly, take a random real number of [− 1,1] [- 1,1] [− 1,1] for each weight, and a random real number of [0,1] [0,1] [0,1] for each offset, and then start forward transmission.
The training of neural network is completed by multiple iterations. Each iteration uses all records of the training set, while each training network uses only one record. The abstract description is as follows:
while Termination conditions not met:
for record:dataset:
trainModel(record)

4.1 back propagation


4.2 training termination conditions
Each round of training uses all records of the data set, but when to stop, the stop conditions are as follows:
Set the maximum number of iterations, such as stopping training after 100 iterations with the dataset
Calculate the prediction accuracy of the training set on the network, and stop the training after reaching a certain threshold
5. Specific process of BP network operation
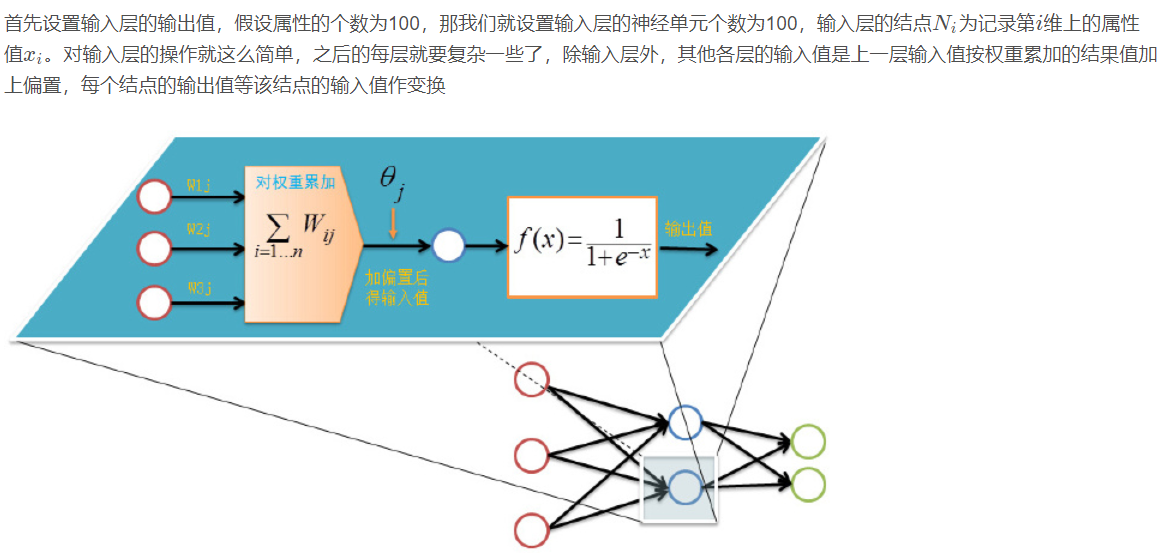
5.1 network structure
There are n nn neurons in the input layer, p pp neurons in the hidden layer and q qq neurons in the output layer.
5.2 variable definition


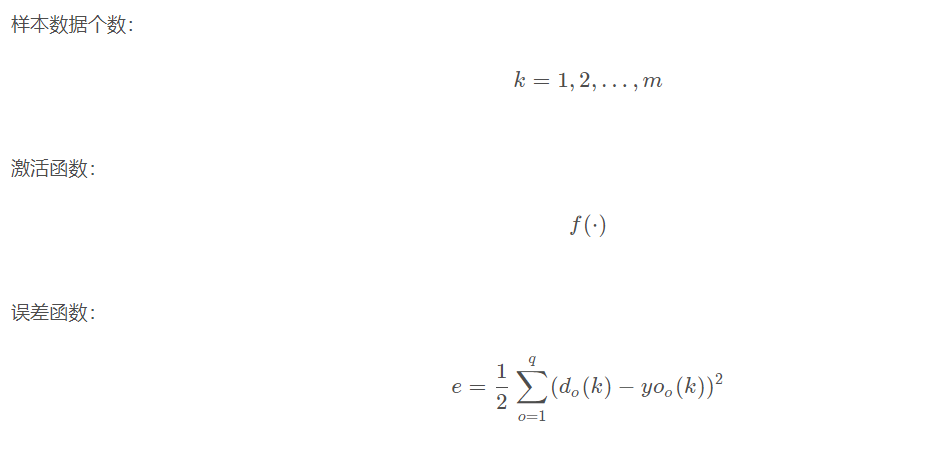


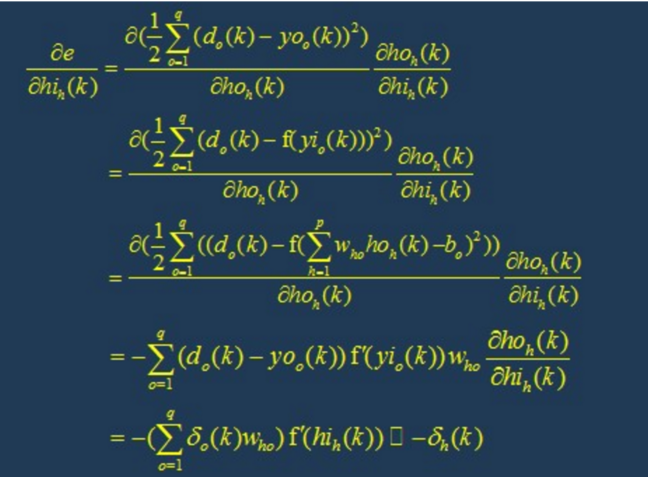


Step 9: judge the rationality of the model
Judge whether the network error meets the requirements.
When the error reaches the preset accuracy or the learning times are greater than the designed maximum times, the algorithm ends.
Otherwise, select the next learning sample and the corresponding output expectation, return to the third part and enter the next round of learning.
6 design of BP network
In the design of BP network, we should generally consider the number of layers of the network, the number of neurons and activation function in each layer, initial value and learning rate. The following are some selection principles.
6.1 network layers
Theory has proved that the network with deviation and at least one S-type hidden layer plus a linear output layer can approach any rational function. Increasing the number of layers can further reduce the error and improve the accuracy, but it is also the complexity of the network. In addition, the single-layer network with only nonlinear activation function can not be used to solve the problem, because the problems that can be solved with single-layer network can also be solved with adaptive linear network, and the operation speed of adaptive linear network is faster. For the problems that can only be solved with nonlinear function, the single-layer accuracy is not high enough, and only increasing the number of layers can achieve the desired results.
6.2 number of neurons in the hidden layer
The improvement of network training accuracy can be obtained by using a hidden layer and increasing the number of neurons, which is much simpler in structure than increasing the number of network layers. Generally speaking, we use accuracy and training network time to measure the quality of a neural network design:
(1) When the number of neurons is too small, the network can not learn well, the number of training iterations is relatively large, and the training accuracy is not high.
(2) When the number of neurons is too large, the more powerful the function of the network is, the higher the accuracy is, and the number of training iterations is also large, which may lead to over fitting.
Therefore, we get that the selection principle of the number of hidden layer neurons of neural network is: on the premise of solving the problem, add one or two neurons to speed up the decline of error.
6.3 selection of initial weight
Generally, the initial weight is a random number with a value between (− 1,1). In addition, after analyzing how the two-layer network trains a function, wedrow et al. Proposed a strategy to select the initial weight order as s √ r, where r is the number of inputs and S is the number of neurons in the first layer.
6.4 learning rate
The learning rate is generally 0.01 − 0.8. A large learning rate may lead to the instability of the system, but a small learning rate leads to too slow convergence and requires a long training time. For more complex networks, different learning rates may be required at different positions of the error surface. In order to reduce the training times and time to find the learning rate, a more appropriate method is to adopt the variable adaptive learning rate to make the network set different learning rates at different stages.
6.5 selection of expected error
In the process of designing the network, the expected error value should also determine an appropriate value after comparative training, which is determined relative to the required number of hidden layer nodes. Generally, two networks with different expected error values can be trained at the same time, and finally one of them can be determined by comprehensive factors.
7 limitations of BP network
BP network has the following problems:
(1) Long training time is required: This is mainly caused by the small learning rate, which can be improved by changing or adaptive learning rate.
(2) Completely unable to train: This is mainly reflected in the paralysis of the network. Generally, in order to avoid this situation, first, select a smaller initial weight, but use a smaller learning rate.
(3) Local minimum value: the gradient descent method adopted here may converge to the local minimum value, and better results may be obtained by using multi-layer network or more neurons.
8 improvement of BP network
The main goal of the improvement of P algorithm is to speed up the training speed and avoid falling into local minimum. The common improvement methods include the algorithm with momentum factor, adaptive learning rate, changing learning rate and action function contraction method. The basic idea of momentum factor method is to add a value proportional to the previous weight change to each weight change on the basis of back propagation, and generate a new weight change according to the back propagation method. The method of adaptive learning rate is aimed at some specific problems. The principle of the method of changing the learning rate is that if the sign of the objective function for the reciprocal of a weight is the same in several consecutive iterations, the learning rate of this weight will increase, on the contrary, if the sign is opposite, the learning rate will decrease. The contraction rule of the action function is to translate the action function, that is, add a constant.
3, Partial source code
%% Optimization of search algorithm based on longicorn whisker BP Research on neural network prediction
%% Clear environment variables
clear all
close all
clc
tic
%% Load data
X=xlsread('data.xlsx');
for i=1:111
Y(i)=X(10*(i-1)+1,2);
end
%% Time series data preprocessing
xx = [];
yy = [];
num_input = 3;
tr_len =round(0.8*length(Y));%Number of training set samples
for i = 1:length(Y)-num_input
xx = [xx; Y(i:i+num_input-1)];
yy = [yy; Y(i+num_input)];
end
%BP Input and output of training set
input_train = xx(1:tr_len, :)';
output_train = yy(1:tr_len)';
%BP Input and output of test set
input_test = xx(tr_len+1:end, :)';
output_test = yy(tr_len+1:end)';
%% BP Network settings
%Number of nodes
[inputnum,N]=size(input_train);%Enter the number of nodes
outputnum=size(output_train,1);%Number of output nodes
hiddennum=10; %Hidden layer node
%% data normalization
[inputn,inputps]=mapminmax(input_train,0,1);
[outputn,outputps]=mapminmax(output_train,0,1);% Normalized to[0,1]between
%% Create network
net=newff(inputn,outputn,hiddennum);
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-3;
net.trainParam.lr = 0.01;
%% Initialization of longicorn whisker algorithm
eta=0.8;
c=5;%Relationship between step size and initial distance
step=10;%Initial step size
n=100;%Number of iterations
k=inputnum*hiddennum+outputnum*hiddennum+hiddennum+outputnum;
x=rands(k,1);
bestX=x;
bestY=fitness(bestX,inputnum,hiddennum,outputnum,net,inputn,outputn);
fbest_store=bestY;
x_store=[0;x;bestY];
display(['0:','xbest=[',num2str(bestX'),'],fbest=',num2str(bestY)])
%% Iterative part
for i=1:n
d0=step/c;
dir=rands(k,1);
dir=dir/(eps+norm(dir));
xleft=x+dir*d0/2;
fleft=fitness(xleft,inputnum,hiddennum,outputnum,net,inputn,outputn);
xright=x-dir*d0/2;
fright=fitness(xright,inputnum,hiddennum,outputnum,net,inputn,outputn);
x=x-step*dir*sign(fleft-fright);
y=fitness(x,inputnum,hiddennum,outputnum,net,inputn,outputn);
if y<bestY
bestX=x;
bestY=y;
end
function error = fitness(x,inputnum,hiddennum,outputnum,net,P,T)
%This function is used to calculate the fitness value
%% input
%x? ?? ?? ?? ?? ?? ?? ?individual
%inputnum? ?? ???Enter the number of layer nodes
%hiddennum? ???Number of hidden layer nodes
%outputnum? ???Number of output layer nodes
%net? ?? ?? ?? ?? ???network
%P? ?? ?? ?? ?? ?? ???Training input data
%T? ?? ?? ?? ?? ?? ?? ?Training output data
%% output
%error? ?? ? Individual fitness value
%% extract
M=size(P,2);
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
%%
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.mc = 0.8;%Momentum coefficient,[0 1]between
net.trainParam.goal=0.01;
net.trainParam.show=100;
net.trainParam.showWindow=0;
%% Network weight assignment
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=reshape(B2,outputnum,1);
%% Training network
net=train(net,P,T);
%% test
Y=sim(net,P);
error=sum(abs(Y-T).^2)./M;
end
function Result=CalcPerf(Refernce,Test)
% INPUT
% Refernce M x N
% Test M x N
% Output
% Result-struct
% 1.MSE (Mean Squared Error)
% 2.PSNR (Peak signal-to-noise ratio)
% 3.R Value
% 4.RMSE (Root-mean-square deviation)
% 5.NRMSE (Normalized Root-mean-square deviation)
% 6.MAPE (Mean Absolute Percentage Error)
% Developer Abbas Manthiri S
% Mail Id abbasmanthiribe@gmail.com
% Updated 27-03-2017
% Matlab 2014a
%% geting size and condition checking
[row_R,col_R,dim_R]=size(Refernce);
[row_T,col_T,dim_T]=size(Test);
if row_R~=row_T || col_R~=col_T || dim_R~=dim_T
error('Input must have same dimentions')
end
4, Operation results
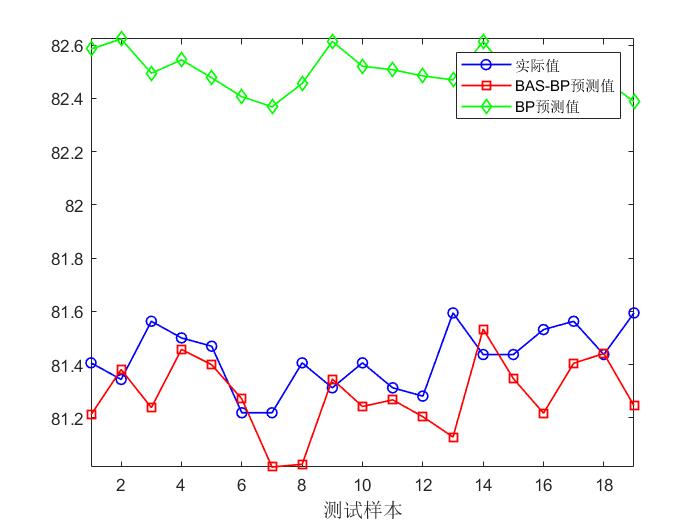
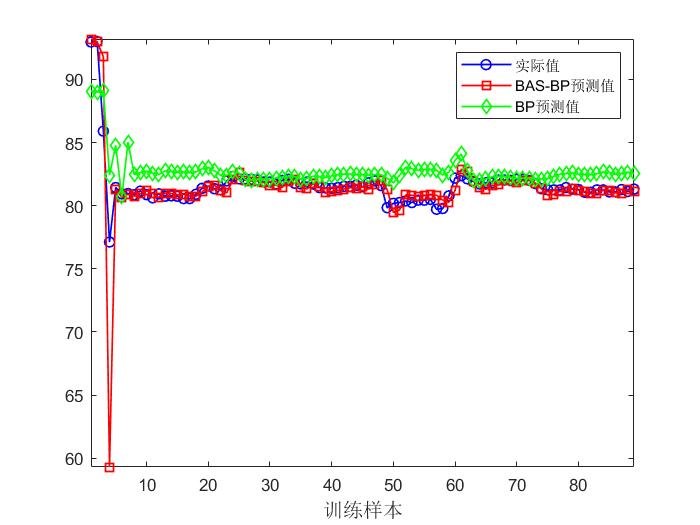
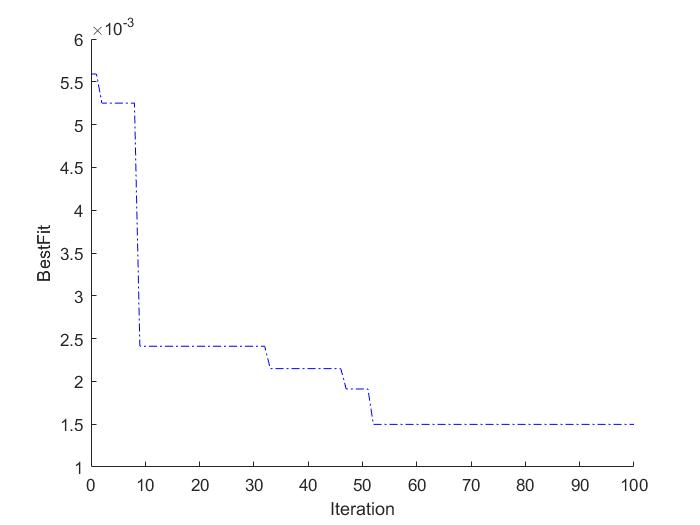
5, matlab version and references
1 matlab version
2014a
2 references
[1] Baoziyang, Yu Jizhou, Yang Shan. Intelligent optimization algorithm and its MATLAB example (2nd Edition) [M]. Electronic Industry Press, 2016
[2] Zhang Yan, Wu Shuigen. MATLAB optimization algorithm source code [M]. Tsinghua University Press, 2017