Transmission model
hierarchical model
| Description of each layer | OSI seven layer network model | TCP/IP four layer network model | Corresponding protocol |
|---|---|---|---|
| Standard interface for network communication of operating system or application | application layer | application layer | Telnet,FTP,SMTP,DNS,HTTP |
| Convert different coding methods into standard forms used in network communication (e.g. UTF-8) | Presentation layer | application layer | Telnet,FTP,SMTP,DNS,HTTP |
| Establish or disconnect connections between different processes on different PC s and insert synchronization points | Session layer | application layer | Telnet,FTP,SMTP,DNS,HTTP |
| End to end data connection and transmission between two hosts | Transport layer | Transport layer | TCP,UDP |
| Select the route and find the target host correctly | network layer | network layer | IP,ARP,RARP,ICMP |
| Accurate data transmission between two adjacent nodes | data link layer | data link layer | Network communication hardware and interface |
| Transmission of raw bit data on physical media | physical layer | data link layer | Network communication hardware and interface |
application layer
| name | explain |
|---|---|
| http | Hypertext transfer protocol uses a browser to query the transfer protocol between web servers |
| ftp | File transfer protocol, a protocol for file exchange between network and host |
| smtp | Simple mail transfer protocol, which defines how mail is transmitted between mail servers |
| pop | Mail protocol, which defines the protocol for downloading users from the mail server to the local server |
| Telent | Remote login protocol, which uses the protocol used by other computers on the Internet remotely to obtain the information running or stored on other computers |
| DNS | The domain name system realizes the conversion from domain name to IP address |
Transport layer
Network protocol refers to the set of conventions and communication rules that communication parties must abide by together on how to communicate. Only when the two sides of communication on the network abide by the same protocol can they correctly exchange information
TCP
-
Establish a stable connection through the triple handshake protocol
-
The application data is divided into the most appropriate data blocks for transmission
-
The connection is reliable, and it is not easy to have disorder, loss, etc
-
Connection and inspection take a lot of time, so the efficiency will be reduced
UDP
-
Send all data at once without establishing a connection
-
The server can send to multiple clients at the same time
-
Without inspection, it is easy to lose information
-
Low resource consumption and fast processing speed
network layer
| name | explain |
|---|---|
| IP | Every computer and other device on the Internet has an address called "IP address" |
| ARP | Address translation protocol, which completes the conversion from IP address to physical address |
| RARP | Reverse address translation protocol, which completes the conversion from physical address to IP address |
| ICMP | Control message protocol, send messages, and report packet transmission errors |
IPV4 and IPV6
-
ipv4 is the first widely used IP. IP is the network layer protocol in TCP/IP protocol family and the core protocol of TCP/IP protocol family
The address length of ipv4 is specified as 32 bits, which is divided into four segments. Each segment is 8 bits, separated by dots and expressed in decimal form. Therefore, the value range of each segment is 0 ~ 255, that is, the minimum is 0.0.0.0 and the maximum is 255.255.255.255
The address block 127.0.0.1 is reserved as loopback credit, and 0.0.0.0 is used arbitrarily
- Applicable to general computer networks
- Class A, 1 ~ 127 Lord Lord Primary = = > subnet mask 255.0.0.0
- Class B, 128 ~ 191 Net Lord Primary = = > subnet mask 255.255.0.0
- Class C, 192 ~ 223 Net Net Primary = = > subnet mask 255.255.255.0
- Multicast and scientific research
- Class D, 224 ~ 239 multicast
- Class E, 240 ~ 254 scientific research
- Applicable to general computer networks
-
ipv6 is four times the length of ipv4, expressed in hexadecimal form. It is divided into eight segments, each separated by a colon
Due to the 4 bits of ipv6, the address resources have been allocated, so ipv6 is generated
port
When multiple programs use the network at the same time, ports are added to ensure that the information is sent to the correct place. Different software uses different ports. Although the same network is used, because the ports are different, it can also ensure that the information is sent to the correct person
The port number ranges from 0 to 65535 (2 ^ 16-1), such as port 80 for web browsing service, port 21 for FTP service, etc
ip address is used to distinguish different hosts, while port number is used to distinguish different network services under a host
TCP protocol
Establish connection
-
Step 1: the client sends SYN message to the server and enters SYN_SEND status.
-
Step 2: the server receives a SYN message, responds to a SYN ACK message, and enters SYN_RECV status.
-
Step 3: the client receives the SYN message from the server, responds to an ACK message and enters the Established state.
-
After the three steps are completed, the TCP client and server successfully establish a connection and can start transmitting data
Long connection and short connection
- Short link
- Establish connection - data transfer - close connection... Establish connection - data transfer - close connection
- Long link
- Establish connection - data transfer... (keep connection)... Data transfer - close connection
Disconnect
-
Step 1: first, the client sends a FIN to the server to request to close the data transmission.
-
Step 2: when the server receives the FIN of the client, it sends an ACK to the client, where the value of ACK is equal to FIN+SEQ
-
Step 3: then the server sends a FIN to the client to tell the client application to close.
-
Step 4: when the client receives the FIN from the server, it replies an ACK to the server. Where ack is equal to FIN+SEQ
Create socket
Server

client
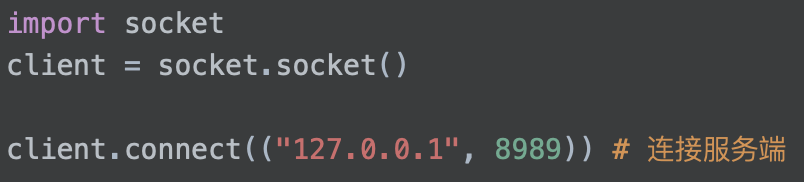
Peer to peer connection socket

Data interaction
clinet.send(b"hello") # Must be byte type data client.recv(1024) # To receive data, specify the maximum length of the data client.close() # Close connection
block
When the client is not connected or sends data, the server will block the execution of accept and recv
Simplex: broadcast, only receive each other's information, only send but not receive
Half duplex: only one person can speak at a time
Full duplex: it can talk and receive at the same time
Basic IO model
Data flow concept
-
data stream is an ordered sequence of bytes with start and end points. Is an ordered sequence of points that can only be read once or a few times. It includes input stream and output stream
-
Data streams are divided into input stream and output stream. The input stream can only read but not write, while the output stream can only write but not read. Usually, the program uses the input stream to read data and the output stream to write data, just as the data flows into and out of the program. Data flow is used to make the input and output operation of the program independent of related equipment
-
The input stream can obtain data from the keyboard or file, and the output stream can transfer data to the display, printer or file
IO interpretation and IO interaction
-
IO is input and output. In the unix world, everything is a file. And what is the file? A file is a string of binary streams. No matter socket, FIFO, pipeline or terminal, everything is a file and everything is a stream. In the process of information exchange, send and receive data to these streams, which is referred to as I/O operation (input and output)
-
Read the data into the stream, and the system calls read. To write data, the system calls write. But there are so many streams in the computer, how do you know which stream to operate? This descriptor is what fd usually does. An fd is an integer, so the operation on this integer is the operation on this file (stream). When a socket is created, a file descriptor will be returned through the system call, and the remaining operations on the socket will be transformed into operations on this descriptor
Blocking IO
In the actual situation summary, many times the data has not arrived at the beginning. At this time, the kernel has to wait for enough data to arrive
On the user process side, the whole process will be blocked. When the kernel waits until the data is ready, it will copy the data from the kernel to the user memory, and then return the results. The user process will unblock and run again
Non blocking IO model and non blocking socket
Non blocking IO model
-
From the perspective of the user process, after initiating a read operation, it does not need to wait, but immediately gets a result. When the user process judges that the result is an error, it knows that the data is not ready
-
So it can send the read operation again. Once the data in the kernel is ready and the system call of the user process is received again, it immediately copies the data to the user memory and returns. The significant difference between the non blocking interface and the blocking interface is that it returns immediately after being called
non-blocking IO
Use exception handling to handle exceptions generated by non blocking IO

Concurrency and parallelism
Concurrent
It refers to that several programs in a period of time are in the period from Startup to completion, and these programs are running on the same processor, but only one program runs on the processor at any time point

The code implementation is very simple, but we should understand the process
Mainly use the idea of circulation to solve the problem
parallel
It refers to that several programs in a period of time are running from Startup to completion, and these programs are running on different processors, and multiple programs are running on different processors at any time point
IO multiplexing
In the previous non blocking IO model, you can check whether there is data through continuous query, which will cause a waste of resources
The viewing process is changed from active query to multiplexer, which can save system resources and have better performance
epoll
-
Non blocking socket and multiplexing
- The non blocking socket needs to traverse each peer connection socket by itself, and each time it is an IO operation
The multiplexer does not need to perform a lot of IO operations. The multiplexer will tell you which peer connection socket has data, and then process it
- The non blocking socket needs to traverse each peer connection socket by itself, and each time it is an IO operation
-
epoll is a lazy event callback, that is, the callback process is called by the user, and the operating system only plays the role of notification
-
epoll is the best IO multiplexer on Linux, but it is only available on Linux and not elsewhere

Multitasking
CPU time slice
Switching priority scheduling algorithm based on time slice
In single core, the basic of parallelism is concurrency. Only multi-core can truly realize parallelism
process
Running programs
- Each process has its own independent address space, memory, data lines, and other auxiliary data used to track execution
- Each process is independent and does not affect each other
Multi process
Use multiple processes to share time-consuming tasks and run time-consuming tasks in another process. In this way, the main process will not be affected.
When the subprocess is completed, the running results of the subprocess are returned
import multiprocessing, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
def func1(a):
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print(a)
print("Internal end:", time.time())
# Simulate what needs to be done outside the process
print("External start", time.time())
p1 = multiprocessing.Process(target=func) # Instantiate a new process object, child process
p2 = multiprocessing.Process(target=func1, args=("nihao",)) # Instantiate a child process and pass parameters through args
p1.start() # Start the process and use it to help us share the task
p2.start() # Start process
time.sleep(5) # Simulate time-consuming operations
print("External end", time.time())
# Output: total time: 5 seconds
The first is multiprocessing Process instantiation, and specify callback function and parameter list
After instantiation, the run can be called directly, which realizes multi process running and saves running time
Parallelism here is only Python level, not actual level
When the total number of processes is more than the number of cores, there is no effect
Multiple processes are scheduled by the operating system
Multithreading
If the process is compared to a factory, the thread is the worker in the factory, that is, a process can contain multiple threads
The workshop space is shared by workers. For example, many rooms are accessible to every worker. This means that the memory space of a process is shared, and each thread can use these shared memory
A thread can be preempted (interrupted) or temporarily suspended (sleep), etc
Threads are scheduled by the Python interpreter, while processes are scheduled by the operating system
code implementation
import threading, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
def func1(a):
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print(a)
print("Internal end:", time.time())
print("External start", time.time())
t1 = threading.Thread(target=func) # Instantiate a thread object to share the task
t2 = threading.Thread(target=func1, args=("nihao",)) # Instantiate a child process and pass parameters through args
t1.start()
t2.start() # Open thread
time.sleep(5) # Simulate time-consuming operations
print("External end:", time.time())
# The output time is still 5 seconds
GIL global interpretation lock
At the beginning of Python's invention, there was no concept of multi-core CPU. To take advantage of multicore, python began to support multithreading. The simplest way to solve the data integrity and state synchronization between multithreads is naturally locking. So there was the GIL super lock
GIL lock requires that only one thread can execute in any process at a time. Therefore, multiple CPU s cannot be allocated to multiple threads. Therefore, threads in Python can only achieve concurrency, not true parallelism
Multitask operation control
Wait for the subtask to end
join method
After a process or thread adds a join method, it will wait for the subtask to end. If it does not end, it will block until the subtask ends,
Therefore, the join is usually placed at the end of the program
import threading, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
def func1(a):
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print(a)
print("Internal end:", time.time())
print("External start", time.time())
t1 = threading.Thread(target=func) # Instantiate a thread object to share the task
t2 = threading.Thread(target=func1, args=("nihao",)) # Instantiate a child process and pass parameters through args
t1.start()
t2.start() # Open thread
time.sleep(5) # Simulate time-consuming operations
t1.join()
t2.join() # Control the main process to wait for the child thread to end and then end
print("External end:", time.time())
# The output time is still 5 seconds
Terminate task
Under normal circumstances, the end of the main process will not affect the child process, but the child process can also be forcibly terminated after the end of the main process.
Note that the thread cannot be terminated and can only wait for the end-
import multiprocessing, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
def func1(a):
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print(a)
print("Internal end:", time.time())
# Simulate what needs to be done outside the process
print("External start", time.time())
p1 = multiprocessing.Process(target=func) # Instantiate a new process object, child process
p2 = multiprocessing.Process(target=func1, args=("nihao",)) # Instantiate a child process and pass parameters through args
p1.start() # Start the process and use it to help us share the task
p2.start() # Start process
time.sleep(5) # Simulate time-consuming operations
# p1.join()
# p2.join() # Control the main process and wait for the child process to end
p1.terminate()
p2.terminate() # Main process shutdown is to force the termination of child processes, which is invalid for threads
print("External end", time.time())
# Output: total time: 5 seconds
Task name
Add and change names
import mltiprocessing # Define a name during initialization p1 = multiprocessing.Process(name="processName") print(p1, p1.name) # You can also change the name directly during operation p1.name = "NewName" print(p1.name)
Get current process
- Get the current process in the process content to facilitate problem finding
Use mltiprocessing cuttent_ process()
Multitask identification
pid of process
In Linux, as soon as the process is created, the system will assign a pid, and the pid will not change during the program running
You can use pid to view the process's use of resources, or you can use pid to control the process's operation
import multiprocessing, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
# Simulate what needs to be done outside the process
print("External start", time.time())
p1 = multiprocessing.Process(target=func) # Instantiate a new process object, child process
print("Before startup:", p1.pid)
p1.start() # Start the process and use it to help us share the task
print("After startup:", p1.pid)
time.sleep(5) # Simulate time-consuming operations
# p1.join()
# p1.terminate()
print("External end", time.time())
# Output: total time: 5 seconds
ident of thread
The thread is still in a process, so there will be no pid
Threads are scheduled by the python interpreter. For scheduling convenience, there will be ident, which is similar to pid in the operating system
import threading, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
print("External start", time.time())
t1 = threading.Thread(target=func) # Instantiate a thread object to share the task
print("Before startup:", t1.ident)
t1.start()
print("After startup:", t1.ident)
time.sleep(5) # Simulate time-consuming operations
# t1.join()
print("External end:", time.time())
# The output time is still 5 seconds
Life cycle
The life cycle of a process starts at start. After instantiation, the process does not start. The life cycle starts only after start
import multiprocessing, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
# Simulate what needs to be done outside the process
print("External start", time.time())
p1 = multiprocessing.Process(target=func) # Instantiate a new process object, child process
print("Before startup:", p1.is_alive())
p1.start() # Start the process and use it to help us share the task
print("After startup:", p1.is_alive()) # Check whether there is a life cycle, return a Boolean value, and check whether the process is started
time.sleep(5) # Simulate time-consuming operations
# p1.join()
# p1.terminate()
print("External end", time.time())
# Output: total time: 5 seconds
Guard mode
After the daemon mode is turned on, the main process ends and the child process ends automatically
For the main process, running completion refers to the completion of the main process code
The main process is finished running after its code is finished (the daemon is recycled at this time), and then the main process will wait until the non daemon sub processes are finished running to recycle the resources of the sub processes (otherwise, a zombie process will be generated)
For the main thread, running completion means that all non daemon threads in the process where the main thread is located have finished running, and the main thread is considered to have finished running
The main thread runs only after other non daemon threads run (the daemon thread is recycled at this time). Because the end of the main thread means the end of the process, the overall resources of the process will be recycled, and the process must ensure that all non daemon threads run before it can end
import multiprocessing, time
def func():
print("Internal start:", time.time())
time.sleep(5) # Time consuming simulation operation
print("Internal end:", time.time())
# Simulate what needs to be done outside the process
print("External start", time.time())
p1 = multiprocessing.Process(target=func, daemon=True) # Instantiate a new process object, child process, and enable daemon mode
p1.start() # Start the process and use it to help us share the task
time.sleep(5) # Simulate time-consuming operations
# p1.join()
# p1.terminate()
print("External end", time.time())
# Output: total time: 5 seconds
object-oriented programming
When using multiple processes or threads, the corresponding module can be used directly or customized after inheritance

Processes communicate with each other
Communication isolation
Isolation between processes: it can be seen that in different processes, even if global variables are declared, they still have no effect.

So how to solve it?
Manager is a common solution for inter process communication. It realizes inter process communication through public space
import multiprocessing # Process module
mg = multiprocessing.Manger() # Create a public space and return a manager, communication medium, which can be a dictionary or list
def func():
dict_var.update({"a": 3, "b": 4})
dict_var = mg.dict() # Open and match a dictionary space, return a proxy, and operate the dictionary subspace through the proxy
print(dict_var) # Print dictionary space, empty dictionary
# The main process modifies the dictionary space
dict_var.update({"a": 1, "b": 2})
p1 = multiprocessing.Process(target=func, args= (dict_var, ))
p1.start()
p1.join()
print(dict_var)
Thread communication
Thread sharing
For threads, they are always in the same process, so they share the same memory space, so they can access the data in the main process

Thread resource contention
A resource error occurs at this time, because the CPU calculation is a combination of multiple instructions. Therefore, if other instructions are inserted during the operation, unforeseen results will be caused

mutex
Special resources can be locked to protect resources and ensure the integrity of each operation
import threading
var = 1
# Add a mutex and get the lock
lock = threading.Lock()
# Define the tasks to be used by two threads
def func1():
global var # Declare global variables
for i in range(1000000):
lock.acquire() # Lock before operation
var += i
lock.release() # Release the lock after operation
def func2():
global var # Declare global variables
for i in range(1000000):
lock.acquire() # Lock before operation
var -= i
lock.release() # Release the lock after operation
# Create 2 threads
t1 = threading.Thread(target=func1)
t2 = threading.Thread(target=func2)
t1.start()
t2.start()
t1.join()
t2.join()
print(var)
queue
concept
fifo
realization
- Queue put(item)
- Get out of line ()
- Test empty empty() approximation
- Test full()
- Approximate queue length qsize()
- Task end task_done() thread use
- Wait for the join() thread to complete
import queue q = queue.Queue() # Numbers in parentheses can limit the number of elements q.put(1) q.put(12) q.get() q.get()
Queue counter
import queue
q = queue.Queue(3)
q.join() # It won't block at this time
q.put("a") # After put, it will block, because there is a counter in the queue, and each put will increase by 1
q.get() # The counter will not decrease by one when get
q.task_done() # Call this method to subtract one
Queue counter
- There is a counter inside the queue itself. When the count is 0, the join will not block, otherwise it will block
Producer and consumer model
Main thread: similar to the producer, it is used to generate tasks
Thread: similar to consumer, used to process tasks
import time, queue, threading
class MyThread(threading.Thread):
def __init__(self):
super().__init__()
self.daemon = True # Enable guard mode
self.queue = queue.Queue(3) # Open the queue object and store three tasks
self.start() # When instantiating, the thread is started directly, and there is no need to start the thread manually
def run(self) -> None: # The run method is the method of the thread. It is a built-in method and will be called automatically when the thread runs
while True: # Continuous processing of tasks
func, args, kwargs = self.queue.get()
func(*args, **kwargs) # Call the function to execute the task tuple with variable length. Remember to unpack
self.queue.task_done() # Solve a task by decrementing the counter to avoid blocking
# Producer model
def submit_tasks(self, func, args=(), kwargs={}): # func for the task to be executed, add the variable length parameter (the default parameter is used by default)
self.queue.put((func, args, kwargs)) # Submit task
# Override join method
def join(self) -> None:
self.queue.join() # Check whether the queue timer is 0. If the task is empty, close the queue
def f1():
time.sleep(2) # The task takes two seconds
print("Mission accomplished")
def f2(*args, **kwargs):
time.sleep(2)
print("Task 2 complete", args, kwargs)
print(time.ctime()) # Print thread start time
# Instantiate thread object
mt = MyThread()
# Submit task
mt.submit_tasks(f1)
mt.submit_tasks(f2, args=("aa", "aasd"), kwargs={"a": 2, "s": 3})
# Let the main thread wait until the child thread ends
mt.join()
# Thread end time
print(time.ctime())
Thread reuse
The reuse of threads is realized by using the producer and consumer model. The main process can be regarded as a producer, which mainly produces tasks, and the thread is used as a consumer to process tasks
Single threaded reuse
Thread pool
Producer and consumer model
Main thread: similar to the producer, it is used to generate tasks
Thread: similar to consumer, used to process tasks
How to open multiple threads
import time, queue, threading
class MyPool():
def __init__(self, n):
self.queue = queue.Queue(3) # Open the queue object and store three tasks
for i in range(n): # n represents how many threads we need to manually start
threading.Thread(daemon=True).start() # Automatically start the thread without manually starting the thread
# Consumer model
def run(self) -> None:
while True: # Continuous processing of tasks
func, args, kwargs = self.queue.get()
func(*args, **kwargs) # Call the function to execute the task tuple with variable length. Remember to unpack
self.queue.task_done() # Solve a task by decrementing the counter to avoid blocking
# Producer model
def submit_tasks(self, func, args=(), kwargs={}): # func for the task to be executed, add the variable length parameter (the default parameter is used by default)
self.queue.put((func, args, kwargs)) # Submit task
# Override join method
def join(self) -> None:
self.queue.join() # Check whether the queue timer is 0. If the task is empty, close the queue
def f1():
time.sleep(2) # The task takes two seconds
print("Mission accomplished")
def f2(*args, **kwargs):
time.sleep(2)
print("Task 2 complete", args, kwargs)
print(time.ctime()) # Print thread start time
# Instantiate thread object
mt = MyPool(2)
# Submit task
mt.submit_tasks(f1)
mt.submit_tasks(f2, args=("aa", "aasd"), kwargs={"a": 2, "s": 3})
# Let the main thread wait until the child thread ends
mt.join()
# Thread end time
print(time.ctime())
Built in thread pool
import time
from multiprocessing.pool import ThreadPool # Thread pool module
def f1():
time.sleep(2) # The task takes two seconds
print("Mission accomplished")
def f2(*args, **kwargs):
time.sleep(2)
print("Task 2 complete", args, kwargs)
print(time.ctime()) # Print thread start time
# Instantiate thread object
pool = ThreadPool(2)
# Submit task
pool.apply_async(f1)
pool.apply_async(f2, args=("aa", "aasd"), kwds={"a": 2, "s": 3}) # Pay attention to changing to kwds for dictionary variable length parameter transmission
# It is required that the queue must be closed before the join method to make it no longer accept tasks
pool.close()
# Let the main thread wait until the child thread ends
pool.join()
# Thread end time
print(time.ctime())
Process pool
Built in process pool
import time
from multiprocessing.pool import Pool # Process pool module
def f1():
time.sleep(2) # The task takes two seconds
print("Mission accomplished")
def f2(*args, **kwargs):
time.sleep(2)
print("Task 2 complete", args, kwargs)
print(time.ctime()) # Print thread start time
# Instantiate process object
pool = Pool(2)
# Submit task
pool.apply_async(f1)
pool.apply_async(f2, args=("aa", "aasd"), kwds={"a": 2, "s": 3}) # Pay attention to changing to kwds for dictionary variable length parameter transmission
# It is required that the queue must be closed before the join method to make it no longer accept tasks
pool.close()
# Let the main process wait until the child process ends
pool.join()
# Process end time
print(time.ctime())
Pool concurrent server
import socket # Socket module
from multiprocessing.pool import ThreadPool # Thread pool module
from multiprocessing import cpu_count # cpu core number module
# Create server
server = socket.socket() # Server socket object
server.bind(("127.0.0.1", 8989))
server.listen(10)
def socket_recv(conn): # Peer to peer connection socket
# Process data multiple times and join the loop
while True:
recv_data = conn.recv(1024) # receive data
if recv_data: # If there is data, it will be printed and sent to the client
print(recv_data)
else: # If there is no data, the conn socket is closed and the loop ends
conn.colse()
break
n = cpu_count() # Get the number of cpu cores
pool = ThreadPool(n) # How many threads are opened according to the number of cpu cores
while True:
conn, addr = server.accept() # Create a peer-to-peer connection socket
pool.apply_async(socket_recv, args=(conn, )) # The task of thread pool is data
import socket # Socket module
from multiprocessing.pool import ThreadPool # Thread pool module
from multiprocessing import cpu_count,Pool # Import the module to get the number of cpu cores and add it to the process pool module
# Create server
server = socket.socket() # Server socket object
server.bind(('127.0.0.1',8989))
server.listen(10)
# Server data processing
def socket_recv(conn): # Peer to peer connection socket
# Process data multiple times and join the loop
while True:
recv_data = conn.recv(1024) # receive data
if recv_data: # If there is data, print and send it to the client
print(recv_data)
conn.send(recv_data)
else: # If there is no data, the conn socket is closed and the loop ends
conn.close()
break
# Define the tasks to be done by a thread
def accpet_process(server):
tp = ThreadPool(cpu_count()*2)
while True:
conn,addr = server.accept() # Create a peer-to-peer connection socket
tp.apply_async(socket_recv,args=(conn,))
n = cpu_count() # Get the number of cpu cores
pool = Pool(n) # Open process pool n is the number of process pools
for i in range(n):
pool.apply_async(accpet_process,args=(server,))
# It is required that the queue must be closed before the join method to admit that it will no longer receive tasks
pool.close()
pool.join()
Synergetic process
concept
Coroutine is concurrency under single thread, also known as micro thread
A coroutine is a lightweight thread in user mode, that is, it is controlled and scheduled by the user program itself
advantage
-
The switching overhead of coroutine is smaller, which belongs to program level switching, which is completely invisible to the operating system, so it is more lightweight
-
The effect of concurrency can be realized in a single thread to maximize the use of cpu
shortcoming
-
The essence of a collaboration process is that under a single thread, multiple cores cannot be used. One program can start multiple processes, multiple threads in each process, and a collaboration process can be started in each thread
-
A coroutine refers to a single thread, so once a coroutine is blocked, the whole thread will be blocked
characteristic
-
Concurrency must be implemented in only one single thread
- No lock is required to modify shared data
- The user program stores the context stack of multiple control flows
-
Additional: when a collaboration process encounters IO operation, it will automatically switch to other collaboration processes (how to detect IO, yield and greenlet cannot be realized, so gevent module (select mechanism) is used)
generator
- Through the multi generator to realize the repeated input and output of the function, such input and output can also be used to transfer data
def func():
print(1)
yield 2
print(3)
yield 4
print(5)
a = func() # Generator object
for i in a: # You can use the for loop to take values
print(i)
print(next(a)) # You can also use the next value
"""Transfer data"""
def func():
while True:
y = yield # Receive values through generator objects
print(y)
a = func() # Generator object
next(a) # Taking the yield object is also used to activate the yield object
a.send(111) # send data
Producer and consumer model
import time
# Define consumer model
def consumer():
while True:
y = yield
time.sleep(1) # Process data in one second
print("Processed data", y)
# Define producer model
def producer():
con = consumer() # Get the consumer object and activate it
next(con)
for i in range(10):
time.sleep(1)
print("send data", i)
con.send(i)
producer() # Call producer model directly
The producers and consumers here are neither process implementation nor thread implementation, but the two generators cooperate with each other. This is called synergetic process
greenlet
Third party module, to be installed
It is very inconvenient for the generator to implement the cooperation process, especially when there are many cooperation processes, it is much more convenient to use the greenlet
This module comes from a derivative version of Python Stackless Python's native coroutine (usually CPython in standard Python). Its coroutine is separately packaged into a module, so its performance is much better than that of the generator
import time
from greenlet import greenlet # Import greenlet module
# Define consumer model
def consumer():
while True:
var = pro.switch() # Switch the task to the producer, enter wait, and receive data
print("consume:", var)
# Define producer model
def producer():
for i in range(10):
time.sleep(1)
print("produce:", i)
con.switch(i) # Pass value to yield
print(f"{i}Completion of production and consumption")
# Let our greenlet module do our collaborative tasks
con = greenlet(consumer)
pro = greenlet(producer) # producer
# The greenlet module switches tasks through the switch method. When there are five parameters in the switch, the task will be switched and is in the state of waiting to receive data. If there are parameters, the parameters will be sent to the switch without parameters as data
con.switch()
The IO blocking problem is not solved here, but we use this time to do other things. Generally, in our work, we implement concurrency in the way of process + thread + CO process to achieve the best concurrency effect
gevent
gevent concurrent server
# The third-party module needs to be downloaded: pip install gevent
# monkey patch
from gevent import monkey;monkey.patch_all() # Monkey patch is required when using gevent module
import gevent, socket # Co process module, socket module
# Create server
server = socket.socket() # Server socket
server.bind(("127.0.0.1", 8989))
server.listen(10)
# Server data processing
def socket_recv(conn): # Peer to peer connection socket
# Process data multiple times and join the loop
while True:
recv_data = conn.recv(1024) # receive data
if recv_data: # If there is data, print and send it to the client
print(recv_data)
conn.send(recv_data)
else: # If there is no data, the conn socket is closed and the loop ends
conn.close()
break
while True:
conn, addr = server.accept()
# Instantiate a coroutine object
gevent.spawn(socket_recv, conn)
gevent encapsulates epoll and greenlet, which is more convenient to use
At the same time, it realizes the automatic switching when IO is blocked
Producer and consumer model
# The third-party module needs to be downloaded: pip install gevent
# monkey patch
from gevent import monkey;monkey.patch_all() # Monkey patch is required when using gevent module
import gevent # Synergetic module
from gevent.queue import Queue # gevent's own queue module
que = Queue(3)
# Producer model
def producer():
for i in range(20):
print("produce:", i)
que.put(i)
# Consumer model
def consumer():
for i in range(20):
var = que.get()
print("consume:", var)
# gevent module is used to do our collaborative tasks
pro = gevent.spawn(producer, que)
con = gevent.spawn(consumer, que)
# Wait until all cooperation processes are completed
gevent.joinall([pro, con])
Implement asynchrony
Synchronization: all methods are executed in sequence, and the total time spent is the sum of all methods
Asynchrony: corresponding to synchronization, asynchrony means that the CPU temporarily suspends the response of the current request, processes the next request, and starts running after receiving the callback notification through polling or other methods. Multitasking is done asynchronously in subtasks
# gevent implements synchronization and asynchrony
# monkey patch
from gevent import monkey;monkey.patch_all() # Monkey patch is required when using gevent module
import gevent, time # Synergetic module
# Define what a task needs to do both synchronously and asynchronously
def task(i):
time.sleep(1) # Analog blocking
print(f"{i}task over")
# Define a synchronization method to simulate synchronous submission of tasks
def syn():
for i in range(10):
task(i)
# Define an asynchronous method to simulate asynchronous task submission
def asy():
gl = [gevent.spawn(task, i) for i in range(10)] # List derivation takes less time and is more efficient
gevent.joinall(gl)
print("Start running")
start = time.time() # At the beginning of the code
# syn()
asy()
end = time.time() # At the end of the code
print(f"Running time{start-end}")