1, Introduction to speech processing
1 Characteristics of voice signal
Through the observation and analysis of a large number of voice signals, it is found that voice signals mainly have the following two characteristics:
① In the frequency domain, the spectral components of speech signals are mainly concentrated in the range of 300 ~ 3400Hz. Using this feature, we can use an anti aliasing band-pass filter to take out the frequency component of the speech signal in this range, and then sample the speech signal according to the sampling rate of 8kHz to obtain the discrete speech signal.
② In the time domain, the speech signal has the characteristics of "short-term", that is, in general, the characteristics of the speech signal change with time, but the speech signal remains stable in a short time interval. It shows the characteristics of periodic signal in voiced segment and random noise in voiced segment.
2 voice signal acquisition
Before digitizing the speech signal, anti aliasing pre filtering must be carried out first. The purpose of pre filtering is two: ① suppress all components whose frequency exceeds fs/2 in all fields of input signal guidance (fs is the sampling frequency) to prevent aliasing interference. ② Suppress 50Hz power frequency interference. In this way, the pre filter must be a band-pass filter. If the upper and lower cut-off color ratios are fH and fL respectively, for most human speech coders, fH=3400Hz, fL = 60~100Hz and the sampling rate is fs = 8kHz; For Ding speech recognition, when used for telephone users, the index is the same as that of speech codec. When the application requirements are high or very high, fH = 4500Hz or 8000Hz, fL = 60Hz, fs = 10kHz or 20kHz.
In order to change the original analog speech signal into digital signal, it must go through two steps: sampling and quantization, so as to obtain the digital speech signal which is discrete in time and amplitude. Sampling, also known as sampling, is the discretization of the signal in time, that is, the instantaneous value is taken on the analog signal x(t) point by point according to a certain time interval △ t. When sampling, we must pay attention to the Nyquist theorem, that is, the sampling frequency fs must be sampled at a speed more than twice the highest frequency of the measured signal in order to correctly reconstruct the wave. It is realized by multiplying the sampling pulse and the analog signal.
In the process of sampling, attention should be paid to the selection of sampling interval and signal confusion: for analog signal sampling, the sampling interval should be determined first. How to choose △ t reasonably involves many technical factors that need to be considered. Generally speaking, the higher the sampling frequency, the denser the number of sampling points, and the closer the discrete signal is to the original signal. However, too high sampling frequency is not desirable. For signals with fixed length (T), too much data (N=T / △ T) is collected, which adds unnecessary calculation workload and storage space to the computer; If the amount of data (N) is limited, the sampling time is too short, which will lead to the exclusion of some data information. If the sampling frequency is too low and the sampling points are too far apart, the discrete signal is not enough to reflect the waveform characteristics of the original signal, and the signal cannot be restored, resulting in signal confusion. According to the sampling theorem, when the sampling frequency is greater than twice the bandwidth of the signal, the sampling process will not lose information. The original signal waveform can be reconstructed without distortion from the sampled signal by using the ideal filter. Quantization is to discretize the amplitude, that is, the vibration amplitude is expressed by binary quantization level. The quantization level changes in series, and the actual vibration value is a continuous physical quantity. The specific vibration value is rounded to the nearest quantization level.
After pre filtering and sampling, the speech signal is transformed into two address digital code by A / D converter. This anti aliasing filter is usually made in an integrated block with analog-to-digital converter. Therefore, at present, the digital quality of speech signal is still guaranteed.
After the voice signal is collected, the voice signal needs to be analyzed, such as time domain analysis, spectrum analysis, spectrogram analysis and noise filtering.
3 speech signal analysis technology
Speech signal analysis is the premise and foundation of speech signal processing. Only by analyzing the parameters that can represent the essential characteristics of speech signal, it is possible to use these parameters for efficient speech communication, speech synthesis and speech recognition [8]. Moreover, the sound quality of speech synthesis and the speech recognition rate also depend on the accuracy and accuracy of speech signal bridge. Therefore, speech signal analysis plays an important role in the application of speech signal processing.
Throughout the whole process of speech analysis is "short-term analysis technology". Because, as a whole, the characteristics of speech signal and the parameters characterizing its essential characteristics change with time, it is an unsteady process, which can not be analyzed and processed by the digital signal processing technology for processing the unstable signal. However, since different speech is a response generated by the movement of human oral muscle forming a certain shape of the vocal tract, and this movement of oral muscle is very slow relative to the speech frequency, on the other hand, although the speech multiple has time-varying characteristics, it is in a short time range (generally considered to be in a short time range of 10 ~ 30ms), Its characteristics remain basically unchanged, that is, relatively stable, because it can be regarded as a quasi steady process, that is, the speech signal has short-term stability. Therefore, the analysis and processing of any speech signal must be based on "short-time", that is, carry out "short-time analysis", divide the speech signal into segments to analyze its characteristic parameters, each segment is called a "frame", and the frame length is generally 10 ~ 30ms. In this way, for the whole speech signal, what is analyzed is the characteristic parameter time series composed of the characteristic parameters of each frame.
According to the different properties of the analyzed parameters, speech signal analysis can be divided into time domain analysis, frequency domain analysis, inverted domain analysis and so on; Time domain analysis method has the advantages of simplicity, small amount of calculation and clear physical meaning. However, because the most important perceptual characteristics of speech signal are reflected in the power spectrum, and the phase change only plays a small role, frequency domain analysis is more important than time domain analysis.
4 time domain analysis of speech signal
The time domain analysis of speech signal is to analyze and extract the time domain parameters of speech signal. When analyzing speech, the first and most intuitive thing is its time domain waveform. Speech signal itself is a time-domain signal, so time-domain analysis is the earliest and most widely used analysis method. This method directly uses the time-domain waveform of speech signal. Time domain analysis is usually used for the most basic parameter analysis and applications, such as speech segmentation, preprocessing, large classification and so on. The characteristics of this analysis method are: ① the speech signal is more intuitive and has clear physical meaning. ② The implementation is relatively simple and less computation. ③ Some important parameters of speech can be obtained. ④ Only general equipment such as oscilloscope is used, which is relatively simple to use.
The time domain parameters of speech signal include short-time energy, short-time zero crossing rate, short-time white correlation function and short-time average amplitude difference function, which are the most basic short-time parameters of speech signal and should be applied in various speech signal digital processing technologies [6]. Square window or Hamming window is generally used in calculating these parameters.
5 frequency domain analysis of speech signal
The frequency domain analysis of speech signal is to analyze the frequency domain characteristics of speech signal. In a broad sense, the frequency domain analysis of speech signal includes the spectrum, power spectrum, cepstrum and spectrum envelope analysis of speech signal, while the commonly used frequency domain analysis methods include band-pass filter bank method, Fourier transform method, line prediction method and so on.
2, Partial source code
clear all;
clc;
[filename,filepath]=uigetfile('.wav','Open wav file');
[y,fs,nbits]=wavread([filepath,filename]); %Select from PC folder wav Audio file
b=menu('Please select an option','Time domain diagram and spectrum diagram of original signal after sampling','FIR wave filter','IIR wave filter','sign out');
while(b~=4)
if b==1
temp=menu('Please select an option','Play original voice','Original speech time domain diagram','Original voice do FFT Transformed spectrum','return');
if temp==1
%Play voice
sound(y);
elseif temp==2
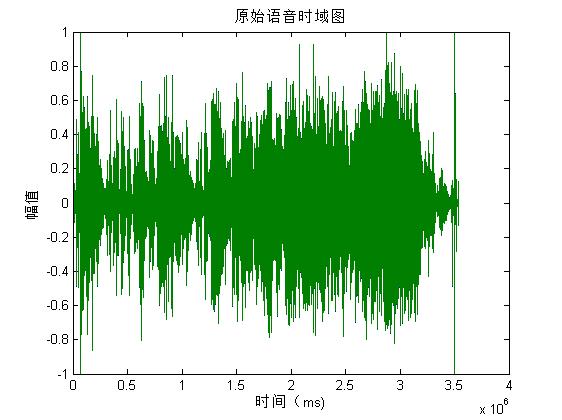
%Draw the time domain diagram of the original voice
figure(11)
plot(y);
xlabel('Time( ms)');
ylabel('amplitude');
title('Original speech time domain diagram');
elseif temp==3
%Draw the original voice FFT Transformed spectrum
Y1=fft(y);
Y=abs(Y1);
figure(12)
plot(Y);
xlabel('frequency');
ylabel('amplitude');
title('Original voice do FFT Transformed spectrum');
else
end
end
if b==2
temp=menu('Please select an option','FIR low pass filter ','FIR High pass filter','FIR Bandpass filter','return');
if temp==1
%FIR low pass filter
fs=10000;
wp=2*pi*1000/fs;
wst=2*pi*1200/fs;
Rp=1;
Rs=100;
wdelta=wst-wp;
N=ceil(8*pi/wdelta); %Rounding
wn=(wp+wst)/2;
[b,a]=fir1(N,wn/pi,hamming(N+1)); %Select the window function and normalize the cut-off frequency
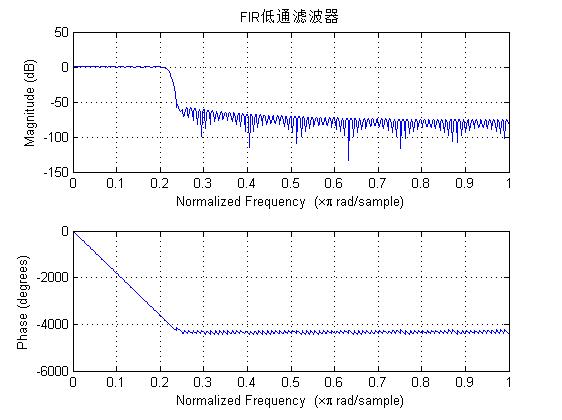
figure(21)
freqz(b,a,512);
title('FIR low pass filter ');
y1=filter(b,a,y);
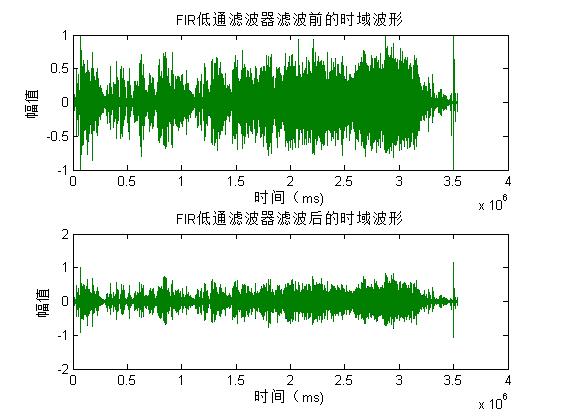
figure(22)
subplot(2,1,1)
plot(y)
title('FIR Time domain waveform before low-pass filter filtering');
xlabel('Time( ms)');
ylabel('amplitude');
subplot(2,1,2)
plot(y1);
title('FIR Time domain waveform filtered by low-pass filter');
xlabel('Time( ms)');
ylabel('amplitude');
sound(y1,8000); %Play the filtered speech signal
F0=fft(y1,1024);
f=fs*(0:511)/1024;
figure(23)
y2=fft(y,1024);
subplot(2,1,1);
plot(f,abs(y2(1:512)));
title('FIR Spectrum before band pass filter')
xlabel('frequency/Hz');
ylabel('amplitude');
subplot(2,1,2)
F2=plot(f,abs(F0(1:512)));
title('FIR Spectrum filtered by low-pass filter');
xlabel('frequency/Hz');
ylabel('amplitude');
elseif temp==2
%FIR High pass filter
fs=22050;
wp=2*pi*5000/fs;
wst=2*pi*3000/fs;
Rp=1;
Rs=100;
wdelta=wp-wst;
N=ceil(8*pi/wdelta); %Rounding
wn=(wp+wst)/2;
[b,a]=fir1(N,wn/pi,'high');
figure(24)
freqz(b,a,512);
title('FIR High pass filter');
y1=filter(b,a,y);
figure(25)
subplot(2,1,1)
plot(y)
title('FIR Time domain waveform before high pass filter');
xlabel('Time( ms)');
ylabel('amplitude');
subplot(2,1,2)
plot(y1);
title('FIR Time domain waveform filtered by high pass filter');
xlabel('Time( ms)');
ylabel('amplitude');
3, Operation results
4, matlab version and references
1 matlab version
2014a
2 references
[1] Han Jiqing, Zhang Lei, Zheng tieran Speech signal processing (3rd Edition) [M] Tsinghua University Press, 2019
[2] Liu ruobian Deep learning: Practice of speech recognition technology [M] Tsinghua University Press, 2019
[3] Song Yunfei, Jiang zhancai, Wei Zhonghua Speech processing interface design based on MATLAB GUI [J] Scientific and technological information 2013,(02)