1, Must see content!!!
1) Brief introduction
XPath is a language for addressing parts of XML documents. It is used in XSLT and is a subset of XQuery. This library can also be used in most other programming languages.
2) Necessary knowledge
- Understand the basic html and xml syntax and format
- No, if you can't html and xml, more than 2000 collections, I'll give a detailed html tutorial. As for how to achieve 2000 praise, it depends on your fans.
3) Why should I write this article?
In my previous dozens of articles, I have written millions of words to make all the foundations of python very clear. No matter whether you are Xiaobai or not, you can learn it by following. At the same time, in my fan group, I will answer the questions in the tutorial, so I never blow the slogan of Baojiao Baohui.
Here is my basic tutorial column: python full stack foundation detailed tutorial column series
Of course, if you are interested in qq robot production, please check the column: qq robot production detailed tutorial column
Why do I put these two columns together? The first column is a basic tutorial, and the second column is an advanced one, so please don't rush to learn robot making until you don't know the basics.
After talking for a long time, I haven't said why I wrote this article. I've almost finished the previous foundation. I won't go to my column and write the foundation in millions of words. I've taught you very hard. After the foundation, we will begin to learn crawlers, so you have to master xpath. Follow me carefully and watch it for a few more days.
4) Highly recommended tutorial column
- python full stack basic tutorial series
- qq robot Xiaobai tutorial series
- matlab mathematical modeling Xiaobai to proficient series
- Linux operating system tutorial
- SQL getting started to proficient tutorial series
Other columns, depending on your personal interests, these five columns are my main ones and I strongly recommend them.
2, Start using xpath
2.1 common HTML operations
If there is a paragraph of html as follows:
<html>
<body>
<a>link</a>
<div class='container' id='divone'>
<p class='common' id='enclosedone'>Element One</p>
<p class='common' id='enclosedtwo'>Element Two</p>
</div>
</body>
</html>
Find elements with specific IDS throughout the page:
//*[@ id='divone '] # returns < div class ='container' id='divone '>
Find an element with a specific id in a specific path:
/html/body/div/p[@id='enclosedone'] # Return < p class ='common 'id ='enclosedone' > element one</p>
Select an element with a specific id and class:
//P [@ id ='enclosedone 'and @ class ='common'] # returns < p class ='common 'id ='enclosedone' > element one</p>
Select the text for a specific element:
//*[@ id='enclosedone']/text() # returns Element One
2.2 common XML operations
For example, there is the following xml:
<r>
<e a="1"/>
<f a="2" b="1">Text 1</f>
<f/>
<g>
<i c="2">Text 2</i>
Text 3
<j>Text 4</j>
</g>
</r>
2.2.1 select an element
Using xpath
/r/e
This element will be selected:
<e a="1"/>
2.2.2 select text
Use xpath:
/r/f/text()
The text node with this string value will be selected:
"Text 1"
And this XPath:
string(/r/f)
The return is also:
"Text 1"
2.3 browser debugging using xpath
The steps are as follows:
- Press F12 to enter the console
- Press ctrl+F to enter the search box
- Enter your own xpath and press enter to see if it matches
2.3.1 demonstration case I
Take my own homepage as an example:
https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343
analysis:
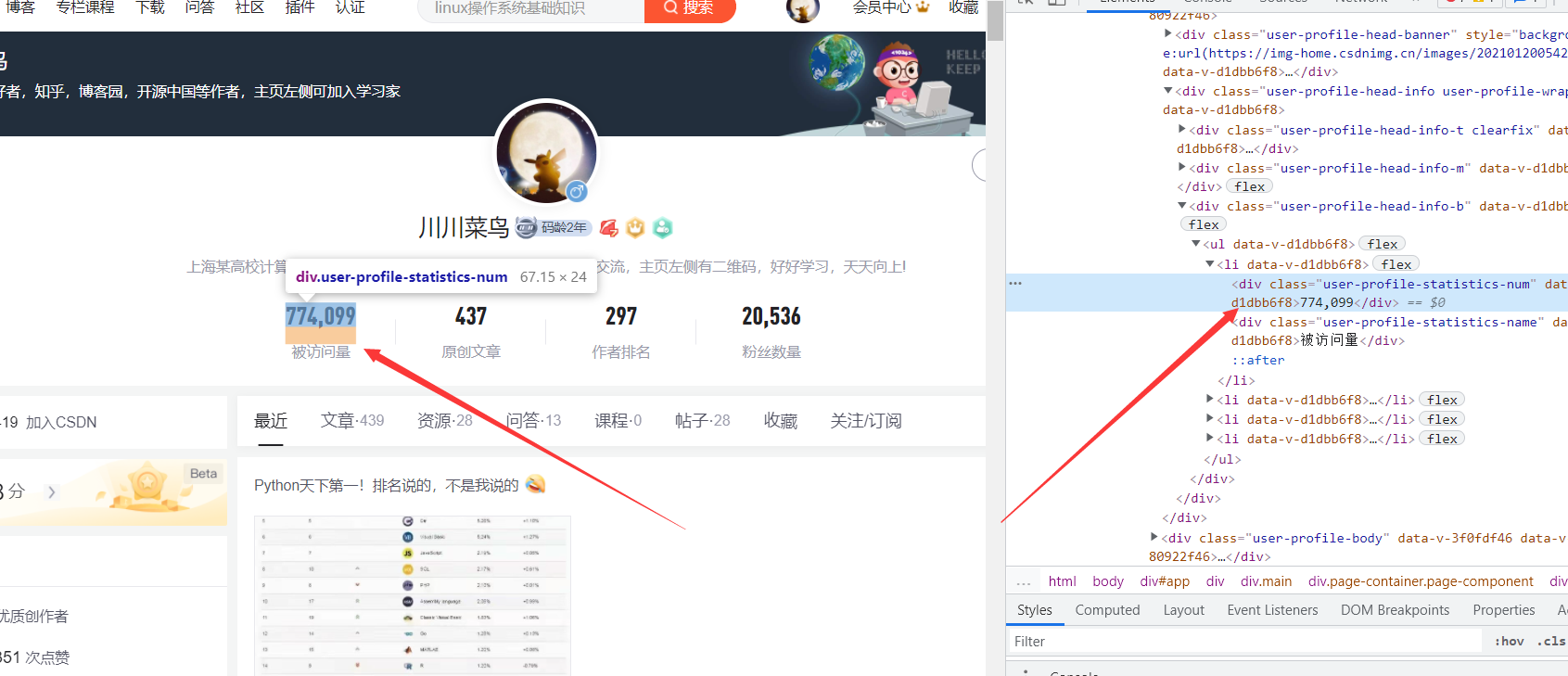
The locking position is:
user-profile-statistics-num
The xpath is written as:
//div[@class="user-profile-statistics-num"]
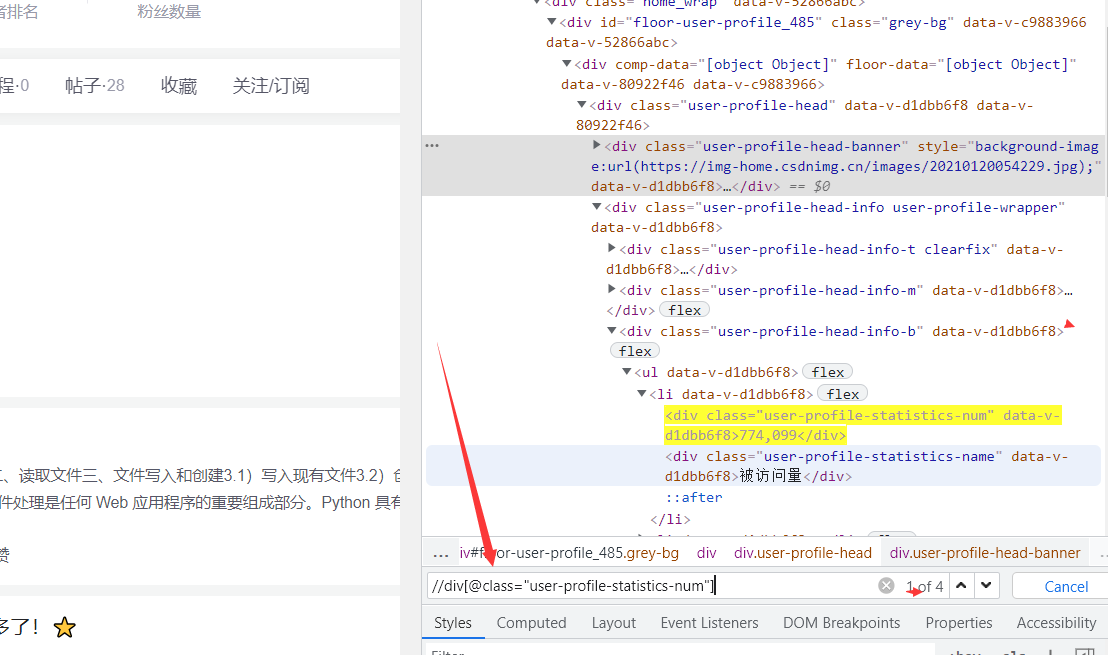
The above is a simple way to debug xpath. I won't introduce it if it's difficult. It's not necessary. If you feel it's necessary, leave a message in the comment area. There are many people, I'll edit and supplement it again.
3, Check whether the node exists
We use Boolean to check whether the xpath we write exists. Boolean is really a good thing.
3.1 case 1
Here I will construct an xml as follows:
<House>
<LivingRoom>
<plant name="rose"/>
</LivingRoom>
<TerraceGarden>
<plant name="passion fruit"/>
<plant name="lily"/>
<plant name="golden duranta"/>
</TerraceGarden>
</House>
Use Boolean to judge:
boolean(/House//plant)
Output:
true
Indicates that the path is correct.
3.2 case 2
Suppose there is such an xml:
<Animal>
<legs>4</legs>
<eyes>2</eyes>
<horns>2</horns>
<tail>1</tail>
</Animal>
Use Boolean judgment:
boolean(/Animal/tusks)
Output:
false
This means that this path is wrong.
4, Check whether the text of the node is empty
Syntax:
- Boolean (path to node / text)
- String (path node)! = '"
Other uses:
- Check whether the node exists
- Check whether the parameter is not a number (NaN) or 0
4.1 case 1
Suppose I construct such an xml:
<Deborah>
<address>Dark world</address>
<master>Babadi</master>
<ID>#0</ID>
<colour>red</colour>
<side>evil</side>
</Deborah>
Boolean judgment:
boolean(/Deborah/master/text())
Or use string to judge:
string(/Deborah/master) != ''
The outputs are:
true
Description text is not empty.
4.2 case 2
Suppose I construct such an xml:
<Dobby>
<address>Hogwartz</address>
<master></master>
<colour>wheatish</colour>
<side>all good</side>
</Dobby>
Boolean judgment:
boolean(/Dobby/master/text())
Or use string to judge:
string(/Dobby/master) != ''
Output:
false
The description text is empty.
5, Query by attributes
Say some common grammar:
- /Select direct child node from current node
- //Select descendant node from current node
- . select the current node
- ... select the parent node of the current node
- @Select Properties
- *On behalf of all
For example:
//title[@lang='chuan']
This is an XPath rule, which means to select all nodes with the name of title and the value of lang as chuan.
5.1 finding nodes with specific attributes
Suppose there is such an xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
The paths match as follows:
/Galaxy/*[@name]
Or:
//*[@name]
Output:
<CelestialObject name="Earth" type="planet" /> <CelestialObject name="Sun" type="star" />
5.2 find nodes through substring matching of attribute values
Suppose there are the following examples:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
route:
/Galaxy/*[contains(@name,'Ear')]
It is worth adding that the contains function here means include. Here is to find all nodes with Ear in the name attribute under the Galaxy path.
As above, we can also match in the following ways:
//*[contains(@name,'Ear')]
Double quotation marks can also be used instead of single quotation marks:
/Galaxy/*[contains(@name, "Ear")]
Output:
<CelestialObject name="Earth" type="planet" />
5.3 finding nodes by substring matching of attribute values (case insensitive)
Suppose there is xml as follows:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
route
/Galaxy/*[contains(lower-case(@name),'ear')]
There is something new here. The lower case () function is added to ensure that we can include all cases.
route
/Galaxy/*[contains(lower-case(@name),'ear')]
perhaps
//*[contains(lower-case(@name),'ear')]
Alternatively, use a string in double quotes:
//*[contains(lower-case(@name), "ear")]
output
<CelestialObject name="Earth" type="planet" />
5.4 finding nodes by matching substrings at the end of attribute values
Suppose there is xml as follows:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
route
/Galaxy/*[ends-with(lower-case(@type),'tar')]
Add: a new function appears here. Ends with matches ends with xx.
perhaps
//*[ends-with(lower-case(@type),'tar')]
output
<CelestialObject name="Sun" type="star" />
5.5 find the node by matching the substring at the beginning of the attribute value
Suppose you have this xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
route
/Galaxy/*[starts-with(lower-case(@name),'ear')]
Add: a new function appears here. Starts with is what matches begin with.
perhaps
//*[starts-with(lower-case(@name),'ear')]
output
<CelestialObject name="Earth" type="planet" />
5.6 finding nodes with specific attribute values
Suppose you have this xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
route
/Galaxy/*[@name='Sun']
Add: here is what I said at the beginning. The asterisk represents all, @ is used to select attributes
perhaps
//*[@name='Sun']
output
<CelestialObject name="Sun" type="star" />
6, Find elements that contain specific attributes
6.1 find all elements with specific attributes (1)
Suppose there is xml as follows:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
xpath matching:
/root/element[@foobar]
return:
<element foobar="hello_world" />
6.2 find all elements with specific attribute values (2)
Suppose there is xml as follows:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
The following XPath expression:
/root/element[@foobar = 'hello_world']
Will return
<element foobar="hello_world" />
You can also use double quotation marks:
/root/element[@foobar="hello_world"]
Fan base: 970353786
7, Find elements that contain specific text
Suppose there is xml as follows:
<root>
<element>hello</element>
<another>
hello
</another>
<example>Hello, <nested> I am an example </nested>.</example>
</root>
The following XPath expression:
//*[text() = 'hello']
The < element > hello < / element > element is returned, but no element is returned. This is because the < other > element contains spaces around the hello text.
To retrieve both < element > and < other >, you can use:
//*[normalize-space(text()) = 'hello']
Add: a new function is added here. The function of normalize space is to remove whitespace.
To find elements that contain specific text, you can use the contains function. The following expression returns the < example > element:
//example[contains(text(), 'Hello')]
If you want to find text that spans multiple child / text nodes, you can use. Instead of text() Refers to the entire text content of an element and its child elements.
For example:
//example[. = 'Hello, I am an example .']
To view multiple text nodes, you can use:
//example//text()
This will return:
- "hello, "
- "I am an example"
- "."
In order to see the whole text content of an element more clearly, you can use the string function:
string(//example[1])
Or
string(//example)
Still return:
Hello, I am an example .
8, Multiple emphasis grammar
8.1 syntax of XPath axis
Now we need to add something new and start remembering:
ancestor Select all ancestors (parents, grandfathers, etc.) of the current node. ancestor-or-self Select all ancestors (parents, grandfathers, etc.) of the current node and the current node itself. attribute Select all properties of the current node. child Selects all child elements of the current node. descendant Select all descendant elements (children, grandchildren, etc.) of the current node. descendant-or-self Select all descendant elements (children, grandchildren, etc.) of the current node and the current node itself. following Select all nodes in the document after the end tag of the current node. namespace Selects all namespace nodes for the current node. parent Select the parent node of the current node. preceding Select all nodes in the document before the start label of the current node. preceding-sibling Select all siblings before the current node. self Select the current node.
8.2 XPath pick node syntax
Why should I emphasize it here? Because it's important!
nodename Select all children of this node. / Select from the root node. // Selects nodes in the document from the current node that matches the selection, regardless of their location. . Select the current node. .. Select the parent node of the current node. @ Select properties.
In the following table, some path expressions and the results of the expressions are listed:
bookstore selection bookstore All child nodes of the element. /bookstore Select root element bookstore. Note: if the path starts with a forward slash( / ),Then this path always represents the absolute path to an element! bookstore/book Select belong to bookstore All child elements of book Element. //book Select all book child elements regardless of their location in the document. bookstore//book Select all book elements that are descendants of the bookstore element, regardless of where they are located under the bookstore. //@lang Select all properties named Lang.
8.3 Xpath predicate
Predicates are used to find a specific node or a node containing a specified value. The predicate is embedded in square brackets.
Just look at some examples:
Path expression result /bookstore/book[1] Select belong to bookstore The first of the child elements book Element. /bookstore/book[last()] Select belong to bookstore The last of the child elements book Element. /bookstore/book[last()-1] Select belong to bookstore The penultimate child element book Element. /bookstore/book[position()<3] Select the first two that belong to bookstore Of child elements of element book Element. //title[@lang] Select all title elements that have an attribute named Lang. //title[@lang='eng'] Select all title elements that have a lang attribute with a value of Eng. /bookstore/book[price>35.00] selection bookstore All of the elements book Element, and price The value of the element must be greater than 35.00. /bookstore/book[price>35.00]/title selection bookstore In element book All of the elements title Element, and price The value of the element must be greater than 35.00.
8.4 select unknown node with XPath
XPath wildcards can be used to pick unknown XML elements.
wildcard describe * Matches any element node. @* Matches any attribute node. node() Matches any type of node.
In the following table, we list some path expressions and the results of these expressions:
Path expression result /bookstore/* selection bookstore All child elements of the element. //* Select all elements in the document. //title[@*] Select all title elements with attributes.
8.5 select several paths for XPath
You can select several paths by using the "|" operator in the path expression.
In the following table, some path expressions and the results of these expressions are listed:
Path expression result //book/title | //book/price Select all the title and price elements of the book element. //title | //price Select all title and price elements in the document. /bookstore/book/title | //price Select all the title elements of the book element belonging to the bookstore element and all the price elements in the document.
9, Gets the node relative to the current node
Suppose we have xml as follows:
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
9.1 basic grammar
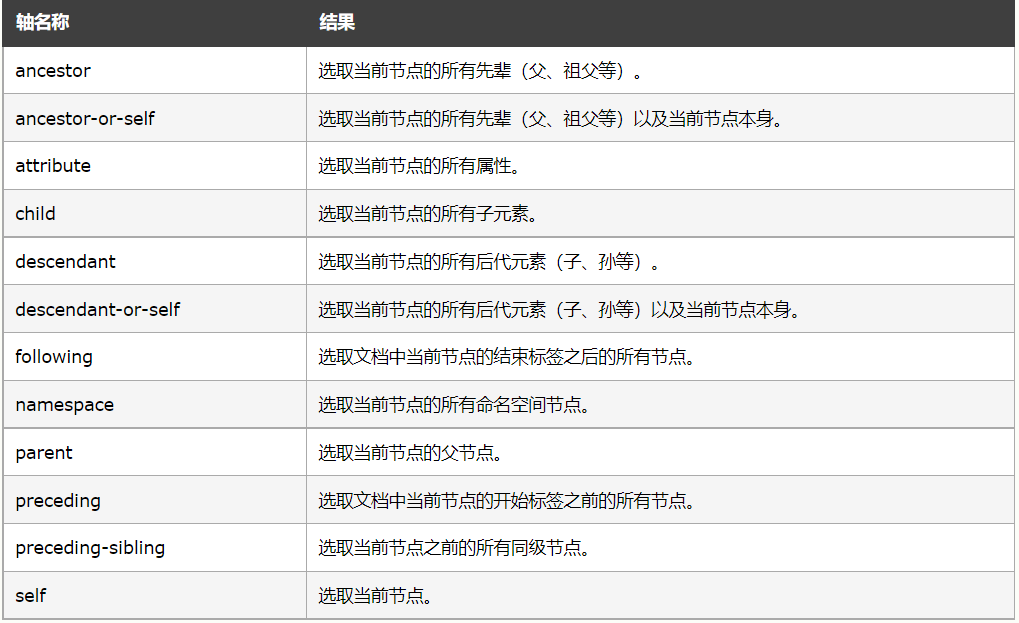
In fact, you don't have to master all these contents, but you must know that when you want to use them, you can check them in this article and use them.
This is a related example:
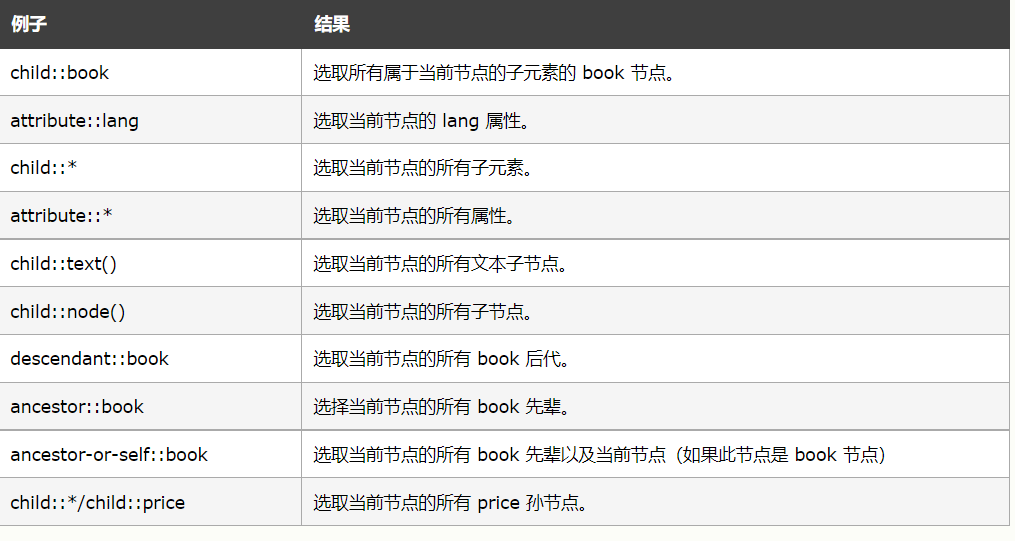
The question is: do you know the ancestors, children, brothers, parents and nodes mentioned here? If you can html, you should know. More than 2000 praise, I can publish an html tutorial, and I will default to you for the time being.
9.2 finding ancestor nodes
Suppose there is xml as follows: (the relationship among ancestors, children, brothers and parents has been vividly explained here. Take a closer look.)
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male"/>
<brother name="Goten" gender="male"/>
</Dad>
</GrandFather>
route
//Me/ancestor::node()
Output:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
9.4 finding sibling nodes
Suppose there is xml as follows:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<brother name="Goten" gender="male" />
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
route:
//Me/following-sibling::brother
Output:
<brother name="Goten" gender="male" />
9.5 finding grandfather nodes (2)
Suppose there is xml as follows:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
route
//Me/ancestor::GrandFather
perhaps
//Me/parent::node()/parent::node()
Output:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
9.6 finding parent nodes
Or suppose the xml is as follows:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male"/>
<brother name="Goten" gender="male"/>
</Dad>
</GrandFather>
route
//Me/ancestor::Dad
perhaps
//Me/parent::node()
Output:
<Dad name="Goku" gender="male" spouse="Chi Chi"> <Me name="Gohan" gender="male" /> <brother name="Goten" gender="male" /> </Dad>
9.7 find all nodes after the current node
Suppose there is xml as follows:
<Dashavatar>
<Avatar name="Matsya"/>
<Avatar name="Kurma"/>
<Avatar name="Varaha"/>
<Avatar name="Narasimha"/>
<Avatar name="Vamana"/>
<Avatar name="Balabhadra"/>
<Avatar name="Parashurama"/>
<Avatar name="Rama"/>
<Avatar name="Krishna"/>
<Avatar name="Kalki"/>
</Dashavatar>
route
//Avatar[@name='Parashurama']/following-sibling::node()
Output:
<Avatar name="Rama" /> <Avatar name="Krishna" /> <Avatar name="Kalki" />
9.8 find all nodes before the current node
Suppose there is xml as follows:
<Dashavatar>
<Avatar name="Matsya"/>
<Avatar name="Kurma"/>
<Avatar name="Varaha"/>
<Avatar name="Narasimha"/>
<Avatar name="Vamana"/>
<Avatar name="Balabhadra"/>
<Avatar name="Parashurama"/>
<Avatar name="Rama"/>
<Avatar name="Krishna"/>
<Avatar name="Kalki"/>
</Dashavatar>
route
//Avatar[@name='Parashurama']/preceding-sibling::node()
Output:
<Avatar name="Matsya"/> <Avatar name="Kurma"/> <Avatar name="Varaha"/> <Avatar name="Narasimha"/> <Avatar name="Vamana"/> <Avatar name="Balabhadra"/>
9.9 example 1
Get all the children named Room in the House.
Suppose there is xml as follows:
<House>
<numRooms>4</numRooms>
<Room name="living"/>
<Room name="master bedroom"/>
<Room name="kids' bedroom"/>
<Room name="kitchen"/>
</House>
route
/House/child::Room
perhaps
/House/*[local-name()='Room']
Output:
<Room name="living" /> <Room name="master bedroom" /> <Room name="kids' bedroom" /> <Room name="kitchen" />
9.10 example II
Get all rooms in the House (regardless of location).
Suppose there is xml as follows:
<House>
<numRooms>4</numRooms>
<Floor number="1">
<Room name="living"/>
<Room name="kitchen"/>
</Floor>
<Floor number="2">
<Room name="master bedroom"/>
<Room name="kids' bedroom"/>
</Floor>
</House>
route
/House/descendant::Room
output
<Room name="living" /> <Room name="kitchen" /> <Room name="master bedroom" /> <Room name="kids' bedroom" />
10, Get the number of nodes
We mainly use the count function. In practice, we will understand it.
10.1 example 1
Suppose there is xml as follows:
<Goku>
<child name="Gohan"/>
<child name="Goten"/>
</Goku>
route
count(/Goku/child)
output
2.0
10.2 example 2
Suppose you have the following xml
<House>
<LivingRoom>
<plant name="rose"/>
</LivingRoom>
<TerraceGarden>
<plant name="passion fruit"/>
<plant name="lily"/>
<plant name="golden duranta"/>
</TerraceGarden>
</House>
route
count(/House//plant)
output
4.0
11, Select nodes according to the number of child nodes
11.1 example 1
Suppose there is xml as follows:
<Students>
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
<Student>
<Name>
<First>Bill</First>
<Last>Edwards</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
</Grades>
</Student>
</Students>
Select all students who have recorded at least 2 grades
//Student[count(./Grades/*) > 1]
output
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
11.2 example II
Suppose there is xml as follows:
<Students>
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
<Student>
<Name>
<First>Bill</First>
<Last>Edwards</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
</Grades>
</Student>
</Students>
Select all students who have recorded their Exam2 scores
//Student[./Grades/Exam2]
perhaps
//Student[.//Exam2]
output
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
12, Select a node whose name is equal to or contains a string
The syntax is as follows:
1. Within a specific node:
{path-to-parent}/name()='Search string']
2. Anywhere in the document:
//*[name() = 'search string']
12.1 search for nodes whose names contain Light
Suppose there is xml as follows:
<Data>
<BioLight>
<name>Firefly</name>
<model>Insect</model>
</BioLight>
<ArtificialLight>
<name>Fire</name>
<model>Natural element</model>
<source>flint</source>
</ArtificialLight>
<SolarLight>
<name>Sun</name>
<model>Star</model>
<source>helium</source>
</SolarLight>
</Data>
route
/Data/*[contains(local-name(),"Light")]
perhaps
//*[contains(local-name(),"Light")]
Output:
<BioLight> <name>Firefly</name> <model>Insect</model> </BioLight> <ArtificialLight> <name>Fire</name> <model>Natural element</model> <source>flint</source> </ArtificialLight> <SolarLight> <name>Sun</name> <model>Star</model> <source>helium</source> </SolarLight>
12.2 search for nodes with names ending in Ball
Assume that the xml is as follows:
<College>
<FootBall>
<Members>20</Members>
<Coach>Archie Theron</Coach>
<Name>Wild cats</Name>
<StarPlayer>David Perry</StarPlayer>
</FootBall>
<VolleyBall>
<Members>24</Members>
<Coach>Tim Jose</Coach>
<Name>Avengers</Name>
<StarPlayer>Lindsay Rowen</StarPlayer>
</VolleyBall>
<FoosBall>
<Members>22</Members>
<Coach>Rahul Mehra</Coach>
<Name>Playerz</Name>
<StarPlayer>Amanda Ren</StarPlayer>
</FoosBall>
</College>
route
/College/*[ends-with(local-name(),"Ball")]
perhaps
//*[ends-with(local-name(),"Ball")]
Output:
<FootBall> <Members>20</Members> <Coach>Archie Theron</Coach> <Name>Wild cats</Name> <StarPlayer>David Perry</StarPlayer> </FootBall> <VolleyBall> <Members>24</Members> <Coach>Tim Jose</Coach> <Name>Avengers</Name> <StarPlayer>Lindsay Rowen</StarPlayer> </VolleyBall> <FoosBall> <Members>22</Members> <Coach>Rahul Mehra</Coach> <Name>Playerz</Name> <StarPlayer>Amanda Ren</StarPlayer> </FoosBall>
12.3 search for nodes with names beginning with Star
Assume that the xml is as follows:
<College>
<FootBall>
<Members>20</Members>
<Coach>Archie Theron</Coach>
<Name>Wild cats</Name>
<StarFootballer>David Perry</StarFootballer>
</FootBall>
<Academics>
<Members>100</Members>
<Teacher>Tim Jose</Teacher>
<Class>VII</Class>
<StarPerformer>Lindsay Rowen</StarPerformer>
</Academics>
</College>
route
/College/*/*[starts-with(local-name(),"Star")]
perhaps
//*[starts-with(local-name(),"Star")]
output
<StarFootballer>David Perry</StarFootballer> <StarPerformer>Lindsay Rowen</StarPerformer>
12.4 search for nodes named Light, Device or Sensor
Assume that the xml is as follows:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
route
/Galaxy/*[local-name()='Light' or local-name()='Device' or local-name()='Sensor']
To put it bluntly, it's just a few more or.
perhaps
//*[local-name()='Light' or local-name()='Device' or local-name()='Sensor']
output
<Light>sun</Light> <Device>satellite</Device> <Sensor>human</Sensor>
12.5 search for nodes named light (case insensitive)
Assume that the xml is as follows:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
route
/Galaxy/*[lower-case(local-name())="light"]
perhaps
//*[lower-case(local-name())="light"]
output
<Light>sun</Light>
12.6 search for nodes named light (case insensitive)
Assume that the xml is as follows:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
route
/Galaxy/*[lower-case(local-name())="light"]
perhaps
//*[lower-case(local-name())="light"]
output
<Light>sun</Light>
13, Actual combat drill (Urban second-hand house price crawling)
There are some contents, such as requests module and lxml module. I haven't talked about them in detail. If you have a little foundation, you can understand them. In the follow-up, I will explain the specific use methods of the module. If you really don't understand it here, you can support my article for three times. If you are motivated, I will continue to explain it in a new article.
The analysis is as follows:
(the first step is to find the overall)
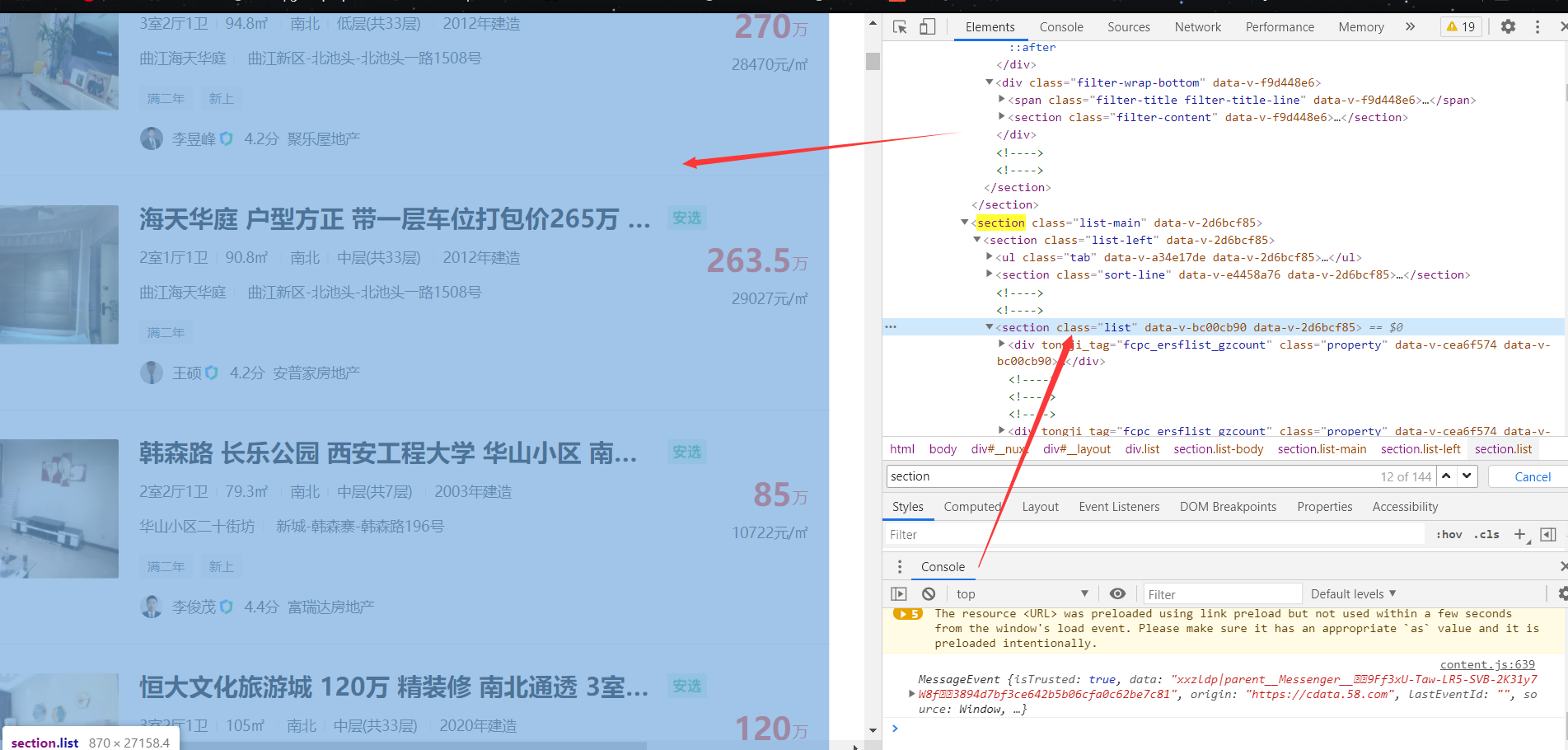
The second step is to look at individual:
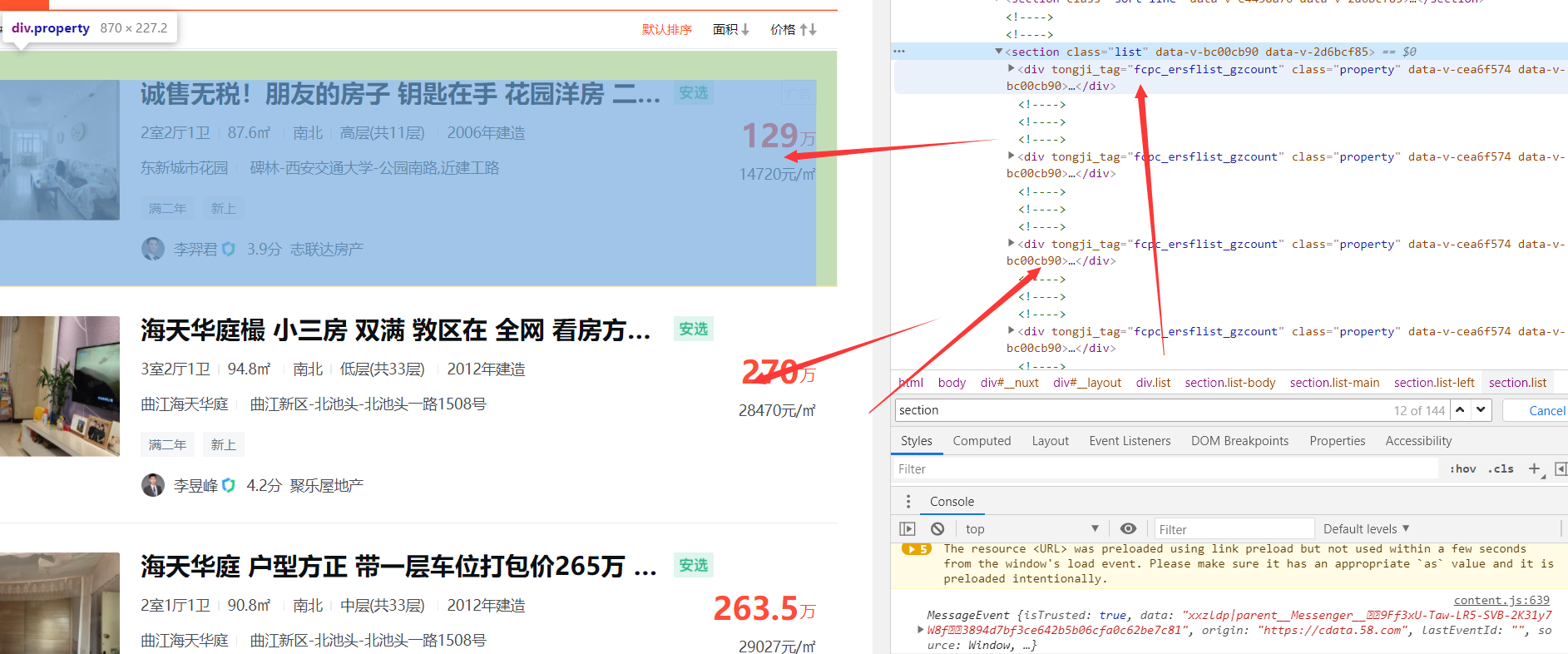
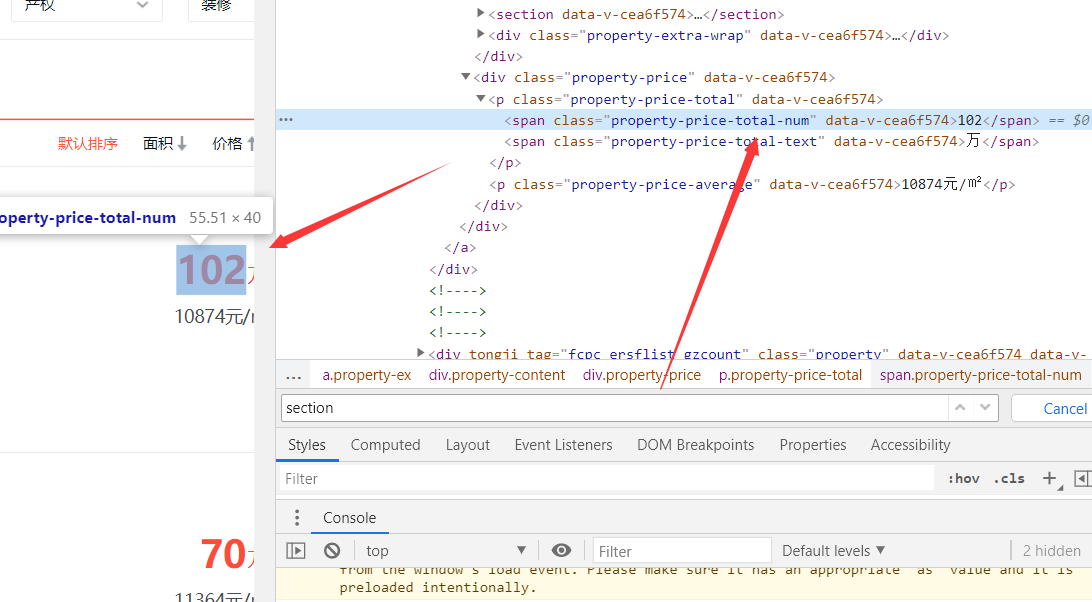
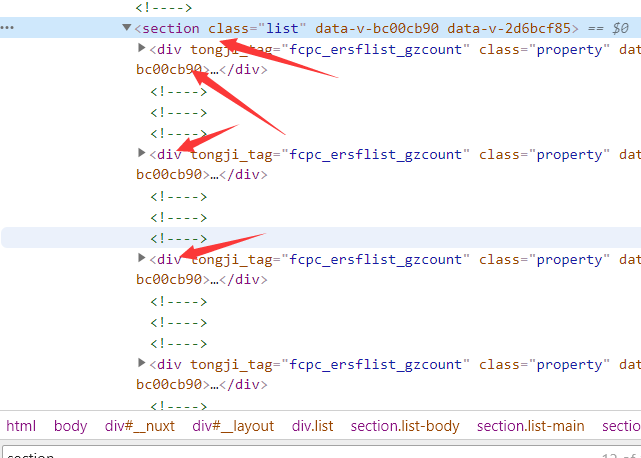
(Law finding) traversable:
#coding=utf-8
"""
Author: Chuan Chuan
Time: 2021/6/26
Group: 428335755
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
url = 'https://xa.58.com/ershoufang/?q=%E4%B8%8A%E6%B5%B7'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
fp = open('./Shanghai second hand house.txt','w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('The total price is'+div.xpath('.//Div [@ class = "property price"] / P / span [@ class = "property price total num"] / text() '[0]) +' ten thousand yuan '
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
result:
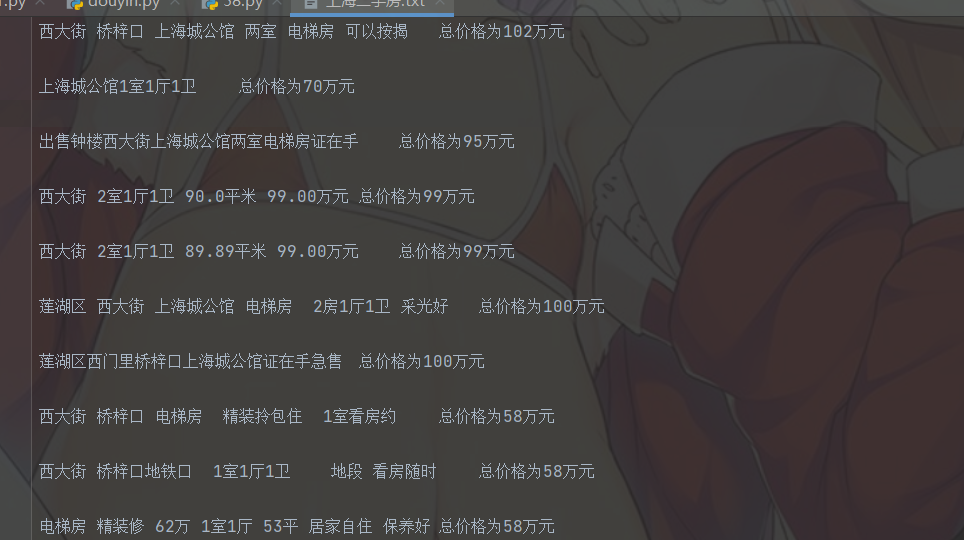
But what? Does this still seem troublesome? Is it difficult for every city to write such a code? No, please see the following analysis:
The code above is the second-hand house price in Shanghai
However, the website is like this:

It's easy to think that if you switch cities, you just need to change Shanghai into another city. After my analysis, the web page structure does not need to change in another city, so the only change is this city.
Therefore, the modified code:
#coding=utf-8
"""
Author: Chuan Chuan
Time: 2021/10/10
Group: 428335755
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
c=input('Here is the second-hand house price crawling. Please enter the city you want to crawl:\n')
url = 'https://xa.58.com/ershoufang/?q=%s'%c
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
fp = open('./Shanghai second hand house.txt','w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('The total price is'+div.xpath('.//Div [@ class = "property price"] / P / span [@ class = "property price total num"] / text() '[0]) +' ten thousand yuan '
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
The effects are as follows:
Enter the city you want to climb

The results are as follows:
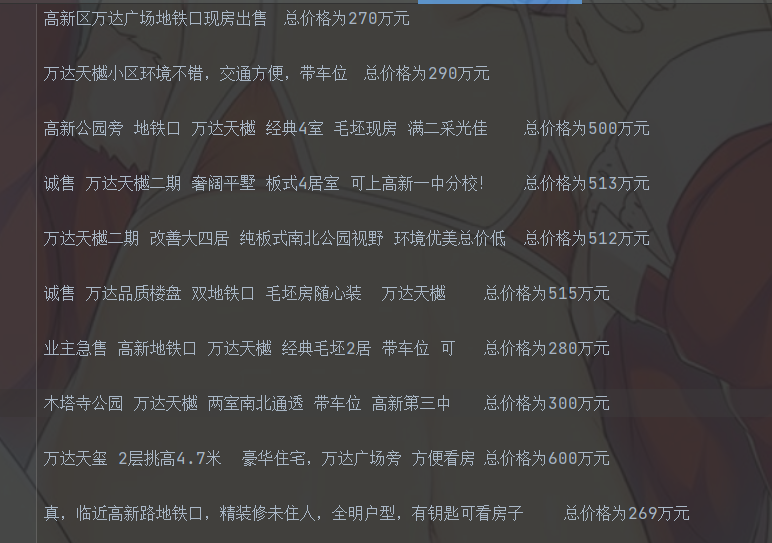
However, even if you can crawl to the second-hand price of each city, the name of the file created each time has not changed, so you have to continue to modify a little. You need to automatically create the document of the corresponding city each time you crawl, so you can modify it again as follows:
#coding=utf-8
"""
Author: Chuan Chuan
Time: 2021/10/10
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
c=input('Here is the second-hand house price crawling. Please enter the city you want to crawl:\n')
url = 'https://xa.58.com/ershoufang/?q=%s'%c
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
wen=c+'Second hand house price.txt'
fp = open(wen,'w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('The total price is'+div.xpath('.//Div [@ class = "property price"] / P / span [@ class = "property price total num"] / text() '[0]) +' ten thousand yuan '
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
Enter city:

result:
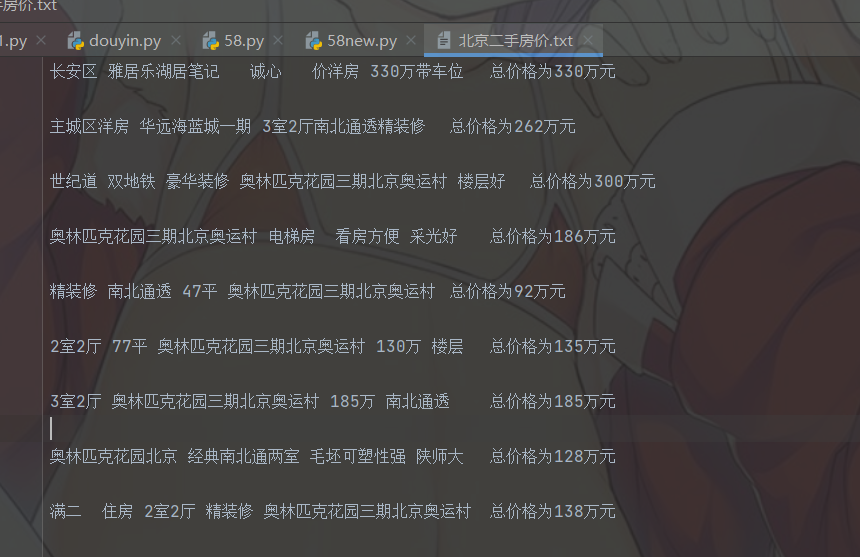
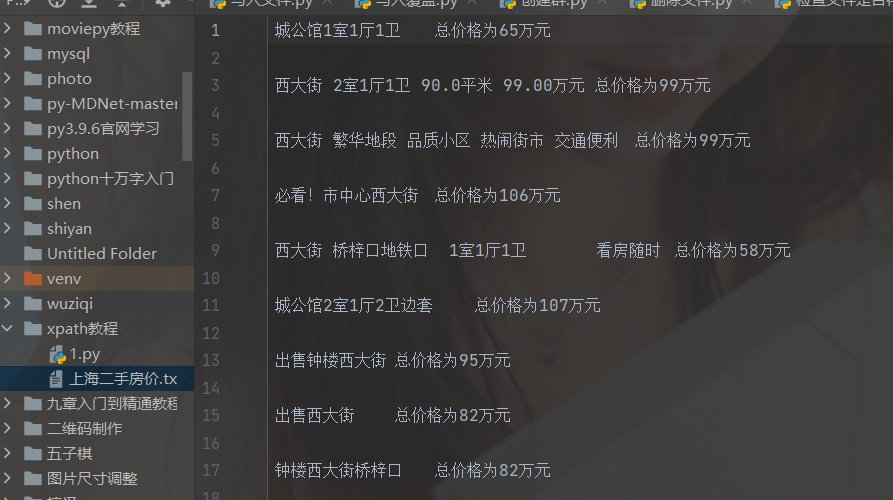
The operation is as follows:
14, Actual combat drill (tiger tooth beauty live crawling)
You can run by yourself. I won't analyze it. Here we use requests, but I haven't talked about this module yet. You can experience it.
Note that you need to change the following path:
path='E://photo//'
Complete code
Group: 428335755
import requests
from lxml import etree
import time
url='https://www.huya.com/g/4079/'
header={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response=requests.get(url=url,headers=header)#Send request
# print(response.text)
data=etree.HTML(response.text)#Convert to html format
image_url=data.xpath('//a//img//@data-original')
image_name=data.xpath('//a//img[@class="pic"]//@alt')
# print(image_url)
path='E://photo//'
for ur,name in zip(image_url,image_name):
url=ur.replace('?imageview/4/0/w/338/h/190/blur/1','')
title=name+'.jpg'
response = requests.get(url=url, headers=header) # Send a new request here
with open(path+title,'wb') as f:
f.write(response.content)
print("Download succeeded" + name)
time.sleep(2)
I just learned xpath recently, so I use xpath. Follow me to learn reptiles, and you will find it very simple and interesting.
Partial results:

13, Fan welfare
Many basic books and data analysis books have been sent in the early stage. The books sent this time are as follows:

The purpose of sending books is only to encourage everyone to learn. Only two books are sent at random. This book is not bad. You can buy it in Jingdong if you like.
14, Summary
The big guy also wrote an xpath: Fifteen minutes to master python crawler XPath Library If you are interested, you can compare it with mine.
I have finished most of the basic columns of the whole stack of python. Now let's enter the crawler. I hope you will master the content of this article. More than 2000 collections, I added an html page foundation. I wrote two all night weekends. I hope you will support me this time. Thank you. As for my book delivery activity, it is genuine and only represents my personal intention. I encourage you to learn.
The official account is sent to xpath: the electronic version of this article can be obtained.