1 Linux overview
1.1 introduction to Linux operating system architecture
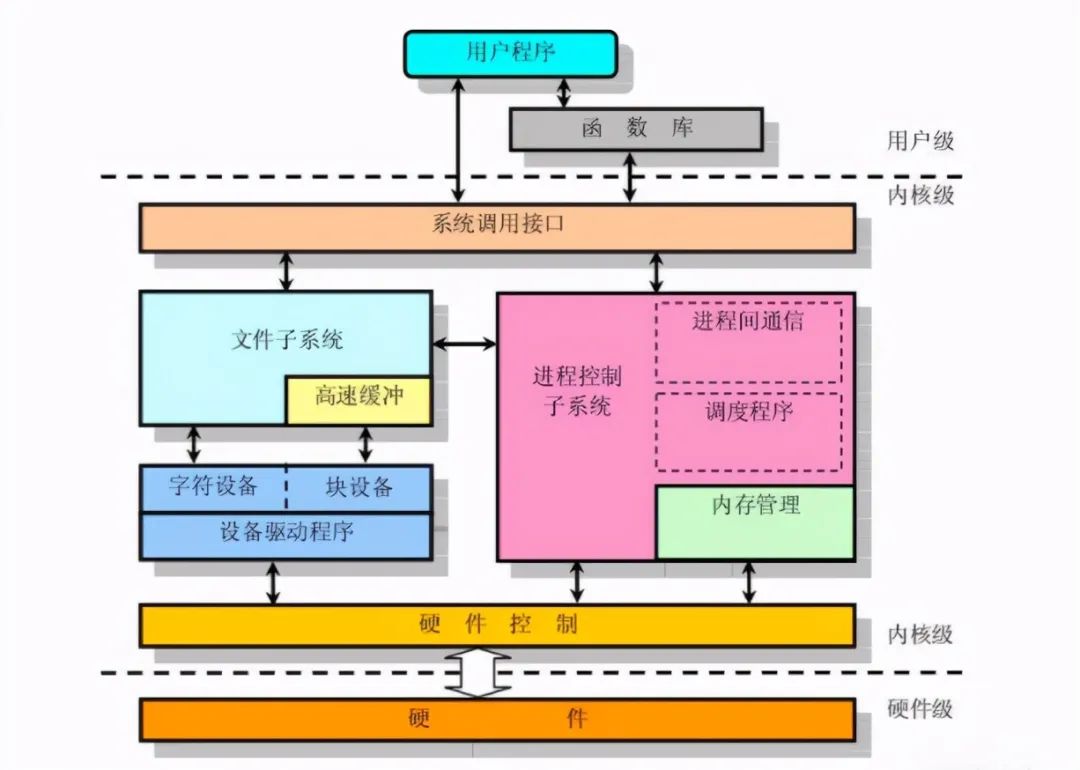
Linux operating system is generally composed of Linux kernel and GNU system. Specifically, it is composed of four main parts, namely Linux kernel, Shell, file system and application program. Kernel, Shell and file system constitute the basic structure of the operating system, so that users can run programs, manage files and use the system.
The kernel is the core of the operating system and has many basic functions, such as virtual memory, multitasking, shared library, demand loading, executable programs and TCP/IP network functions. Our research work is to analyze at the Linux kernel level.
1.2 introduction to protocol stack
OSI (Open System Interconnect), that is, open system interconnection. Generally called OSI reference model, it is the network interconnection model studied by ISO (International Organization for Standardization) in 1985.
In order to make network applications more popular, ISO has launched the OSI reference model. The implication is that all companies are recommended to use this specification to control the network. In this way, all companies have the same specifications and can be interconnected.
OSI defines the seven layer framework of network interconnection (physical layer, data link layer, network layer, transport layer, session layer, presentation layer and application layer), that is, ISO open interconnection system reference model. As shown below.
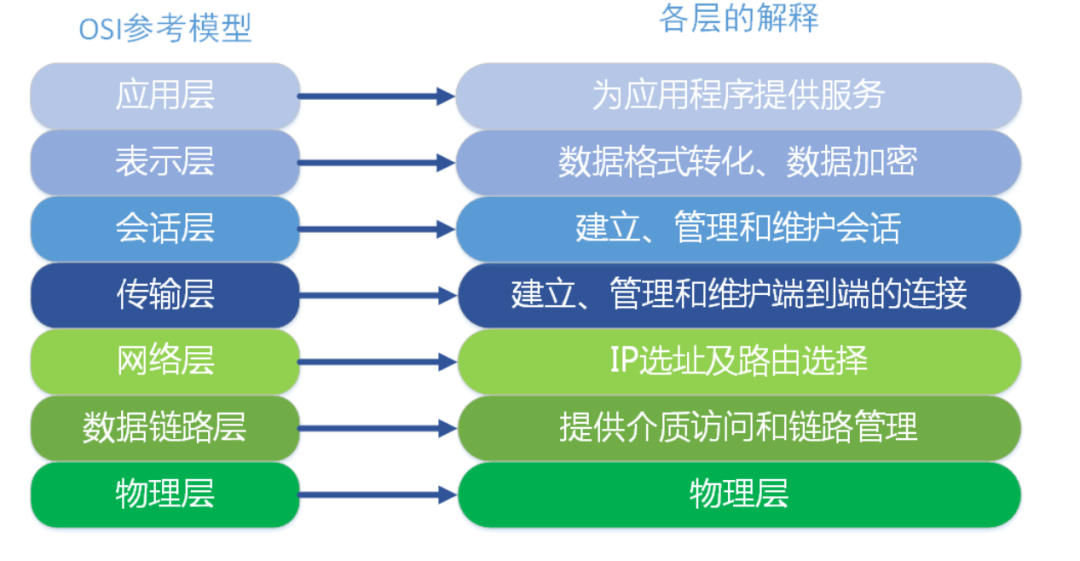
Each layer implements its own functions and protocols, and completes the interface communication with adjacent layers. The service definition of OSI specifies the services provided by each layer. The service of a layer is a capability of the layer and its lower layers, which is provided to a higher layer through an interface. The services provided by each layer have nothing to do with how these services are implemented.
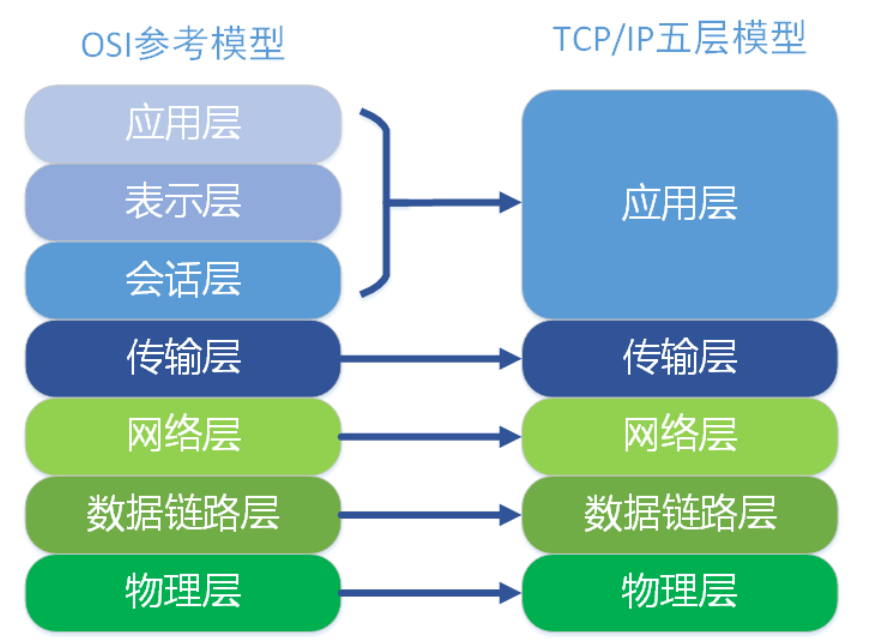
osi seven layer model has become a theoretical standard, but it is the TCP/IP five layer model that is really used in practice.
The corresponding relationship between TCP/IP five layer protocol and osi seven layer protocol is as follows:
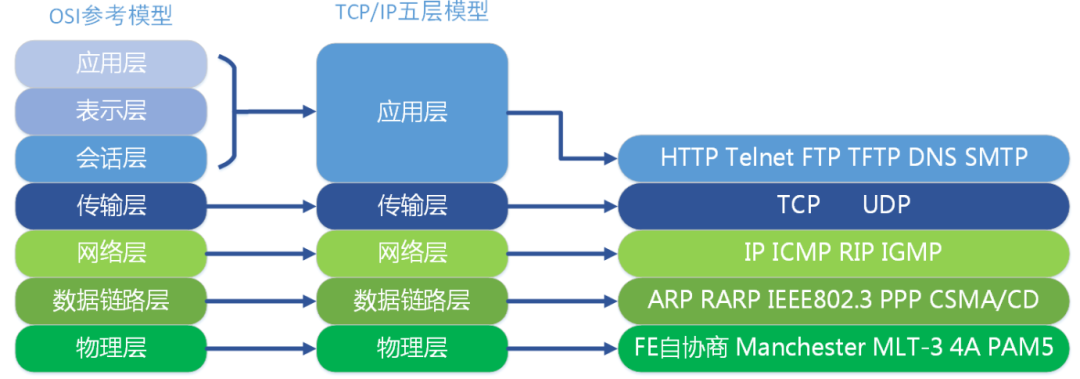
The protocols implemented in each layer are also different, that is, the services of each layer are also different The following figure lists the main protocols of each layer.
1.3 Linux kernel protocol stack
The protocol stack of Linux actually originates from the protocol stack of BSD. Its upward and downward interfaces and the software layered organization of the protocol stack itself are very good.
Based on the layered design idea, the protocol stack of Linux is divided into four layers, from bottom to top: physical layer, link layer, network layer and application layer.
The physical layer mainly provides various connected physical devices, such as various network cards, serial port cards, etc; The link layer mainly refers to the drivers of various interface cards that provide access to the physical layer, such as network card drivers; The role of the network layer is to transmit network packets to the correct location. Of course, the most important network layer protocol is IP protocol. In fact, there are other protocols in the network layer, such as ICMP, ARP, RARP, etc., but they are not familiar to most people like IP; The role of the transport layer is mainly to provide end-to-end communication. To put it bluntly, it provides communication between applications. The most famous protocols of the transport layer are not TCP and UDP; The application layer, as the name suggests, is of course the "man-machine interface" layer provided by the application program for semantic interpretation of the transmitted data, such as HTTP, SMTP, FTP, etc. in fact, the application layer is not the layer that people finally see. The top layer should be the "interpretation layer", which is responsible for presenting the data to people in various forms of table items.
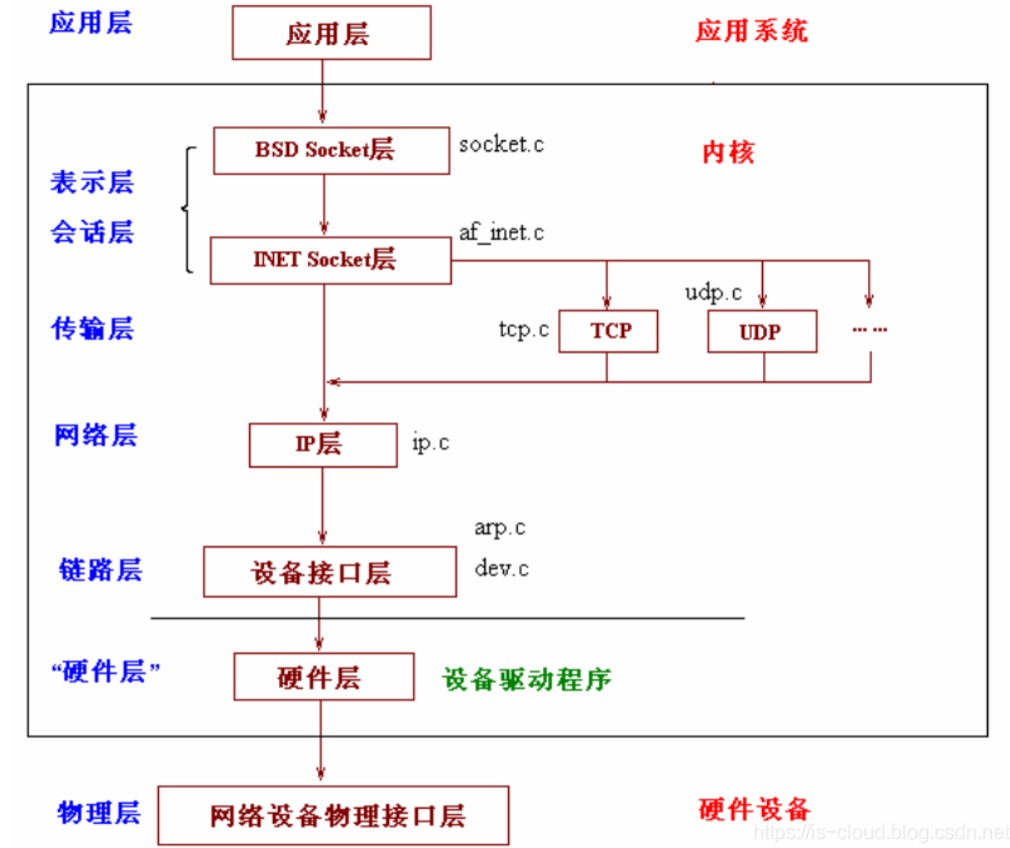
Linux network core architecture the network architecture of Linux can be divided into three layers from top to bottom, namely:
Application layer of user space.
Network protocol stack layer in kernel space.
Physical hardware layer.
Of course, the most important and core is the protocol stack layer in kernel space.
Linux network protocol stack structure the whole network protocol stack of Linux is built in the Linux Kernel. The whole stack is also designed in strict accordance with the idea of layering. The whole stack is divided into five layers, namely:
1. The system call interface layer is essentially an interface call library for user space applications, which provides user space applications with an interface to use network services.
2. The protocol independent interface layer is the SOCKET layer. The purpose of this layer is to shield different protocols at the bottom (more accurately, TCP and UDP, of course, RAW IP, SCTP, etc.) so that the interface with the system call layer can be simple and unified. In short, no matter what protocol we use in the application layer, we should establish a SOCKET through the system call interface. This SOCKET is actually a huge SOCKET structure. It is connected with the network protocol layer of the lower layer to shield the differences of different network protocols. Only the data part is presented to the application layer (presented through the system call interface).
3. Network protocol implementation layer, which is undoubtedly the core of the whole protocol stack. This layer mainly implements various network protocols, the most important of course are IP, ICMP, ARP, RARP, TCP, UDP, etc. This layer contains many design skills and algorithms, which is quite good.
4. Driver interface layer independent of specific equipment. The purpose of this layer is to unify the interfaces between drivers of different interface cards and network protocol layer. It abstracts the functions of various drivers into several special actions, such as open, close, init, etc. this layer can shield different drivers at the bottom.
5. Driver layer. The purpose of this layer is very simple, which is to establish the interface layer with hardware.
It can be seen that the Linux network protocol stack is a strictly layered structure, in which each layer performs relatively independent functions, and the structure is very clear.
The design of two "irrelevant" layers is very good. Through these two "irrelevant" layers, the protocol stack can be easily extended. In our own software design, we can absorb this design method.
2 code introduction
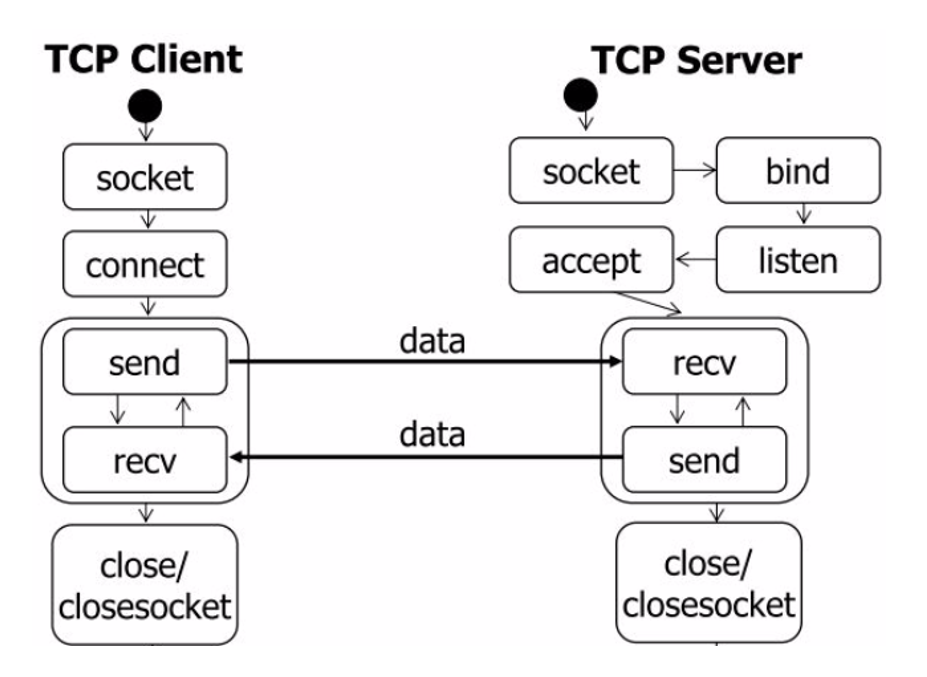
The test code used in this paper is a very simple socket based client server program. Open the server and run it, and then open a terminal to run the client. The two establish a connection and send hello\hi information. The server code is as follows:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
#define true 1
#define false 0
#Define myport 3490 / * listening port*/
#Define backup log 10 / * length of the request receiving queue of listen*/
#define BUF_SIZE 1024
int main()
{
int sockfd;
if ((sockfd = socket(PF_INET, SOCK_DGRAM, 0)) == -1)
{
perror("socket");
exit(1);
}
struct sockaddr_in sa; /* Own address information */
sa.sin_family = AF_INET;
sa.sin_port = htons(MYPORT); /* Network byte order */
sa.sin_addr.s_addr = INADDR_ANY; /* Automatically fill in local IP */
memset(&(sa.sin_zero), 0, 8); /* Set the rest to 0 */
if (bind(sockfd, (struct sockaddr *)&sa, sizeof(sa)) == -1)
{
perror("bind");
exit(1);
}
struct sockaddr_in their_addr; /* Address information of the connected party */
unsigned int sin_size = 0;
char buf[BUF_SIZE];
int ret_size = recvfrom(sockfd, buf, BUF_SIZE, 0, (struct sockaddr *)&their_addr, &sin_size);
if(ret_size == -1)
{
perror("recvfrom");
exit(1);
}
buf[ret_size] = '\0';
printf("recvfrom:%s", buf);
}The client code is as follows:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
#define true 1
#define false 0
#Define port 3490 / * port of server*/
#Define MAXDATA Size 100 / * maximum number of bytes that can be read at one time*/
int main(int argc, char *argv[])
{
int sockfd, numbytes;
char buf[MAXDATASIZE];
struct hostent *he; /* Host information */
struct sockaddr_in server_addr; /* Opposite address information */
if (argc != 2)
{
fprintf(stderr, "usage: client hostname\n");
exit(1);
}
/* get the host info */
if ((he = gethostbyname(argv[1])) == NULL)
{
/* Note: when getting DNS information, an error is displayed. You need to use herror instead of perror */
/* herror Warnings will appear in the new version, which has been recommended not to use */
perror("gethostbyname");
exit(1);
}
if ((sockfd = socket(PF_INET, SOCK_DGRAM, 0)) == -1)
{
perror("socket");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT); /* short, NBO */
server_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]);
memset(&(server_addr.sin_zero), 0, 8); /* Set the rest to 0 */
if ((numbytes = sendto(sockfd,
"Hello, world!\n", 14, 0,
(struct sockaddr *)&server_addr,
sizeof(server_addr))) == -1)
{
perror("sendto");
exit(1);
}
close(sockfd);
return true;
}In short, the main process is shown in the figure below:
3. Application layer process
3.1 sender
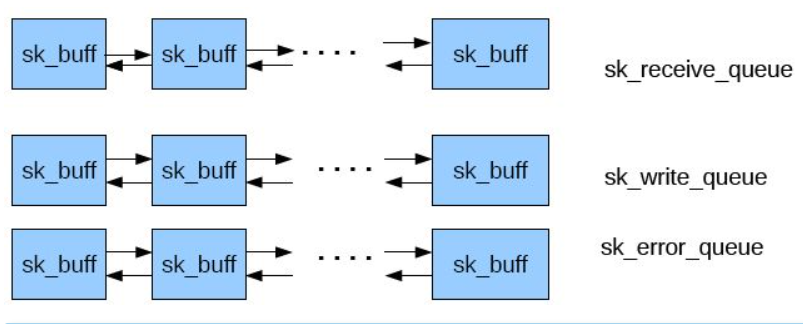
The network application calls Socket API socket (int family, int type, int protocol) to create a socket, which will eventually call Linux system call socket() and finally call the socket of Linux Kernel_ Create() method. This method returns the file descriptor of the socket created. For each socket created by userspace network application, there is a corresponding struct socket and struct socket in the kernel. Among them, struct sock has three queues, Rx, TX and err. When the sock structure is initialized, these buffer queues are also initialized; During receipt receiving and sending, the Linux network stack SK corresponding to each packet to be sent or received is saved in each queue_ Instance skb of buffer data structure.
For TCP socket, the application calls the connect () API to make the client and server establish a virtual connection through the socket. In this process, the TCP protocol stack will establish a TCP connection through three handshakes. By default, the API will wait until the TCP handshake is completed and the connection is established before returning. An important step in establishing a connection is to determine the maximum segemet size (MSS) used by both parties. Because UDP is a connectionless protocol, it does not need this step.
The application calls the send or write API of the Linux Socket to send a message to the receiver socket_ Sendmsg is called. It uses socket descriptor to obtain socket struct and create message header and socket control message_sock_sendmsg is called to call the sending function of the corresponding protocol according to the protocol type of socket.
For TCP, call tcp_sendmsg function. For UDP, the userspace application can call any of the three system call s send()/sendto()/sendmsg() to send UDP message s, and they will eventually call UDP in the kernel_ Sendmsg() function.
Let's make a detailed analysis step by step in combination with the Linux kernel source code:
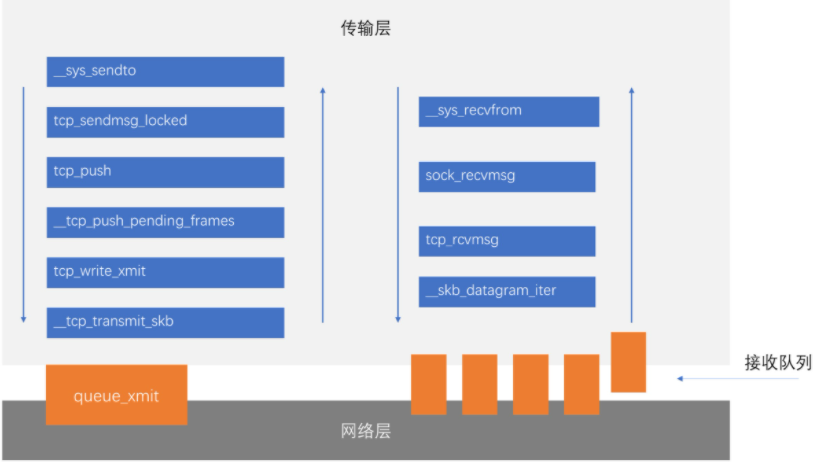
According to the above analysis, the sender first creates a socket, and then sends data through send. Specifically, at the source level, the system calls send, SendTo and sendmsg are used to send data, and the underlying layers of the above three functions call sock_sendmsg. See the figure below:
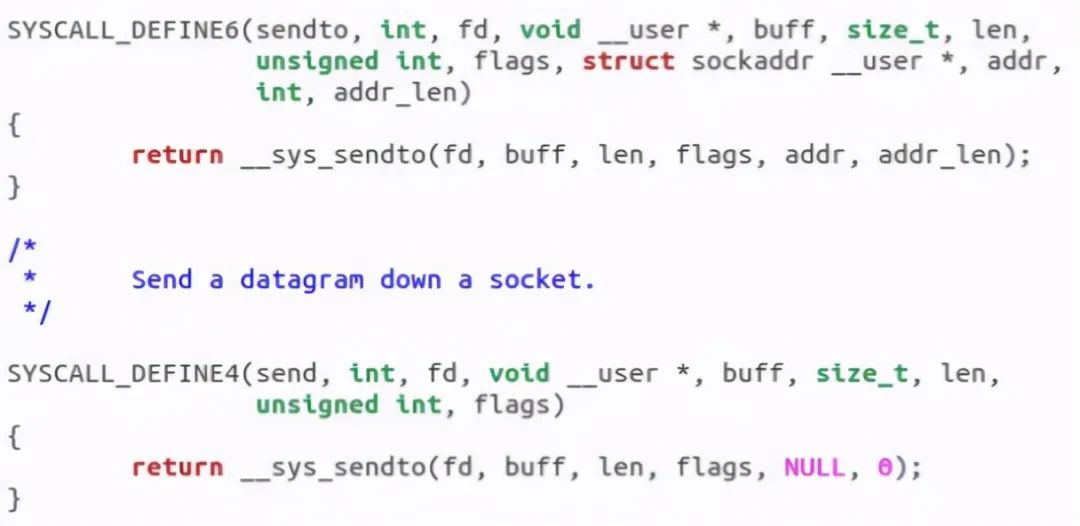
Let's jump to__ sys_sendto see what this function does:
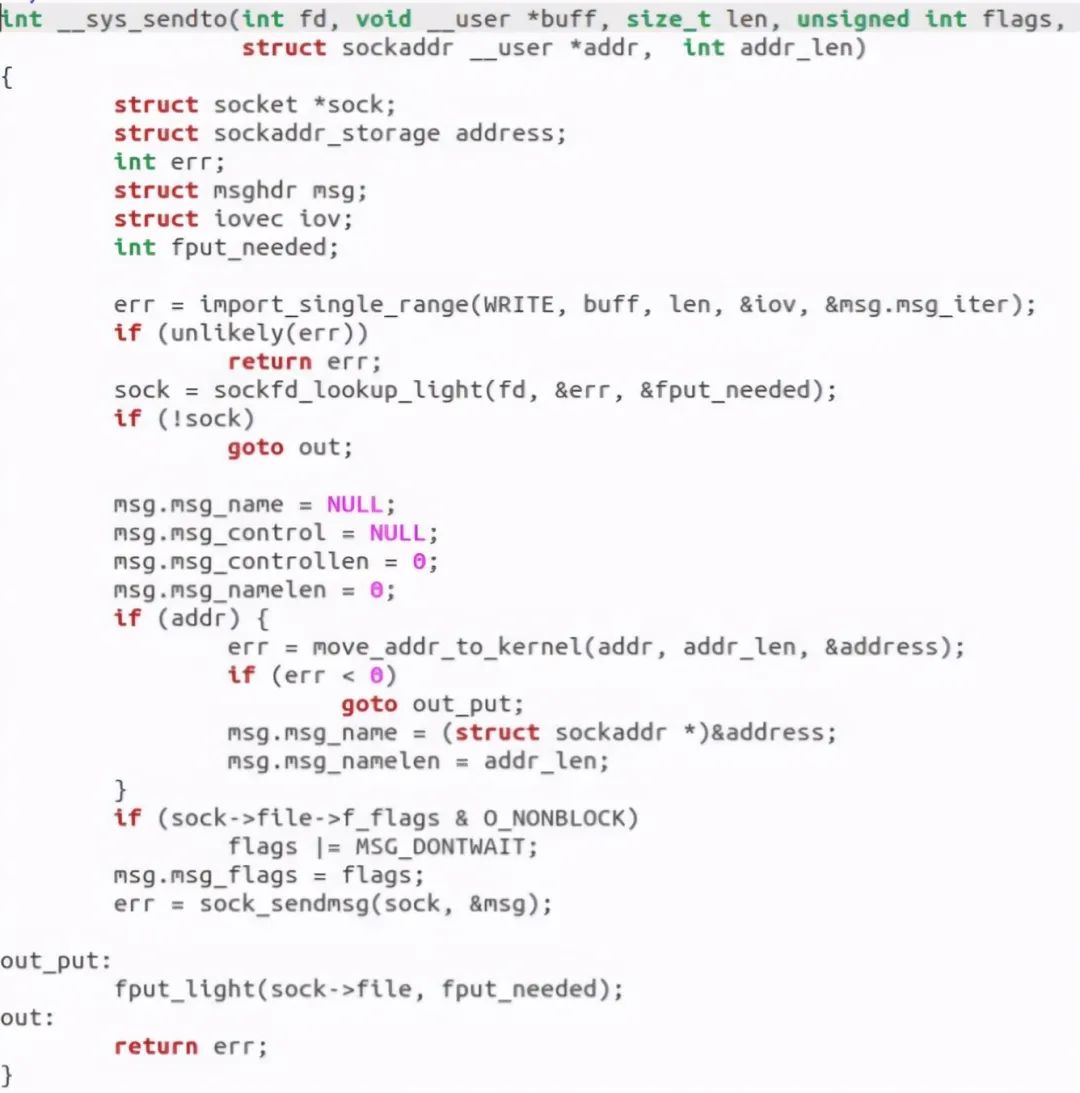
We can find that it creates two structures: struct msghdr msg and struct iovec iov. According to their names, we can roughly guess some information about sending data and io operation, as shown in the following figure:


Let's see again__ sys_ Sock called by SendTo_ What does the sendmsg function do:
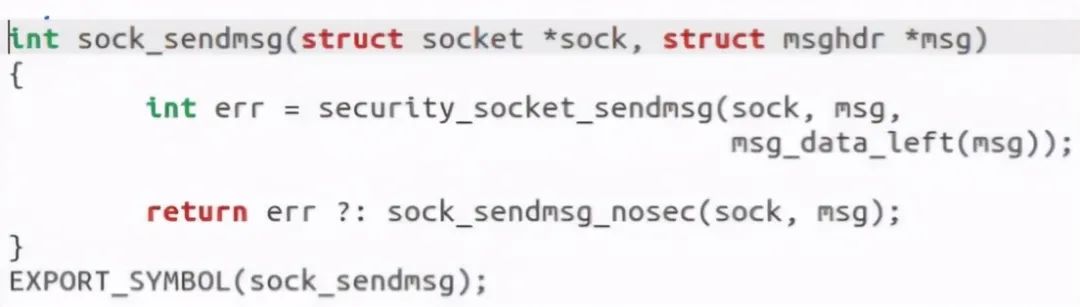
Found a call to the sock_sendmsg_nosec function:
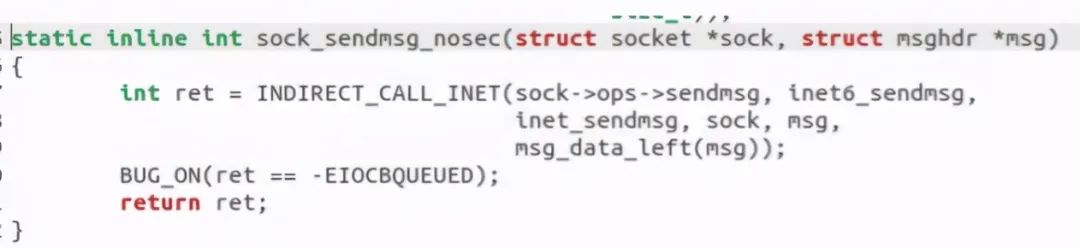
INET was found called_ Sendmsg function:

At this point, the sender call is completed. We can debug and verify through gdb:
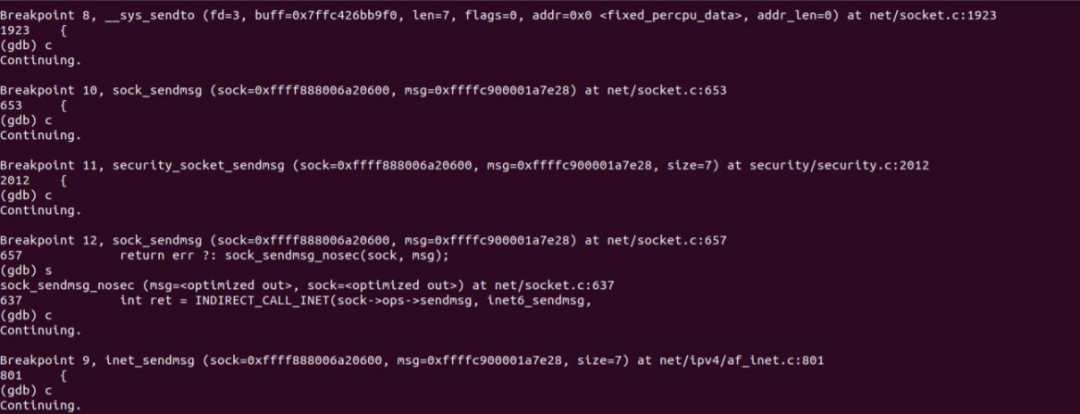
Just in line with our analysis.
3.2 receiving end
Whenever the user application calls read or recvfrom, the call will be mapped to / net / socket Sys in C_ Recv system call and is converted to sys_recvfrom calls, then calls sock_. Recgmsg function.
For INET type socket s, / net / IPv4 / AF INET INET in C_ The recvmsg method will be called, which will call the data receiving method of the relevant protocol.
For TCP, call tcp_recvmsg. This function copies data from socket buffer to user buffer.
For UDP, you can call any of the three system calls recv() / recvfrom() / recvmsg() from user space to receive UDP package. These system calls will eventually call UDP in the kernel_ Recvmsg method.
We carefully analyze the source code:
The receiver calls__ sys_recvfrom function:
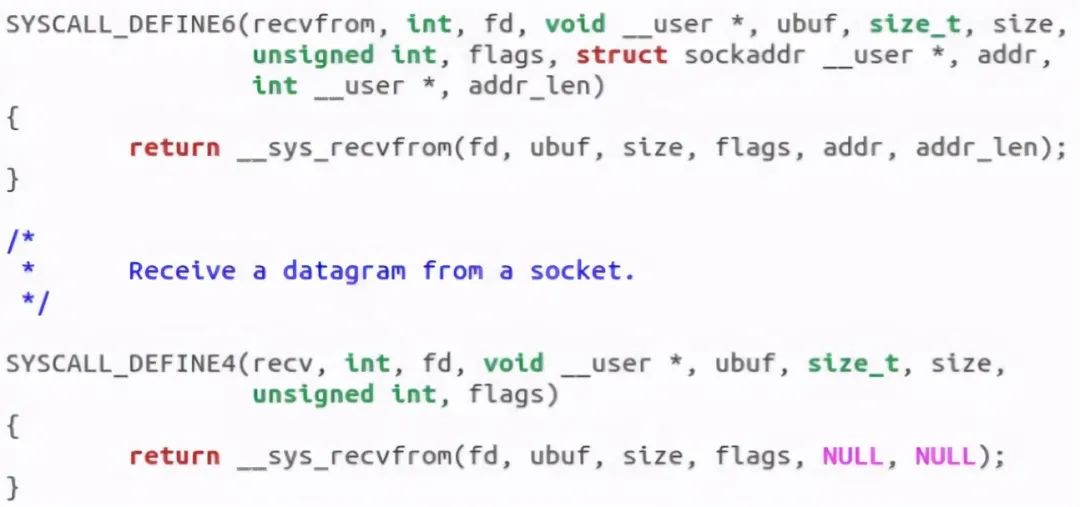
__ sys_ The recvfrom function is as follows:
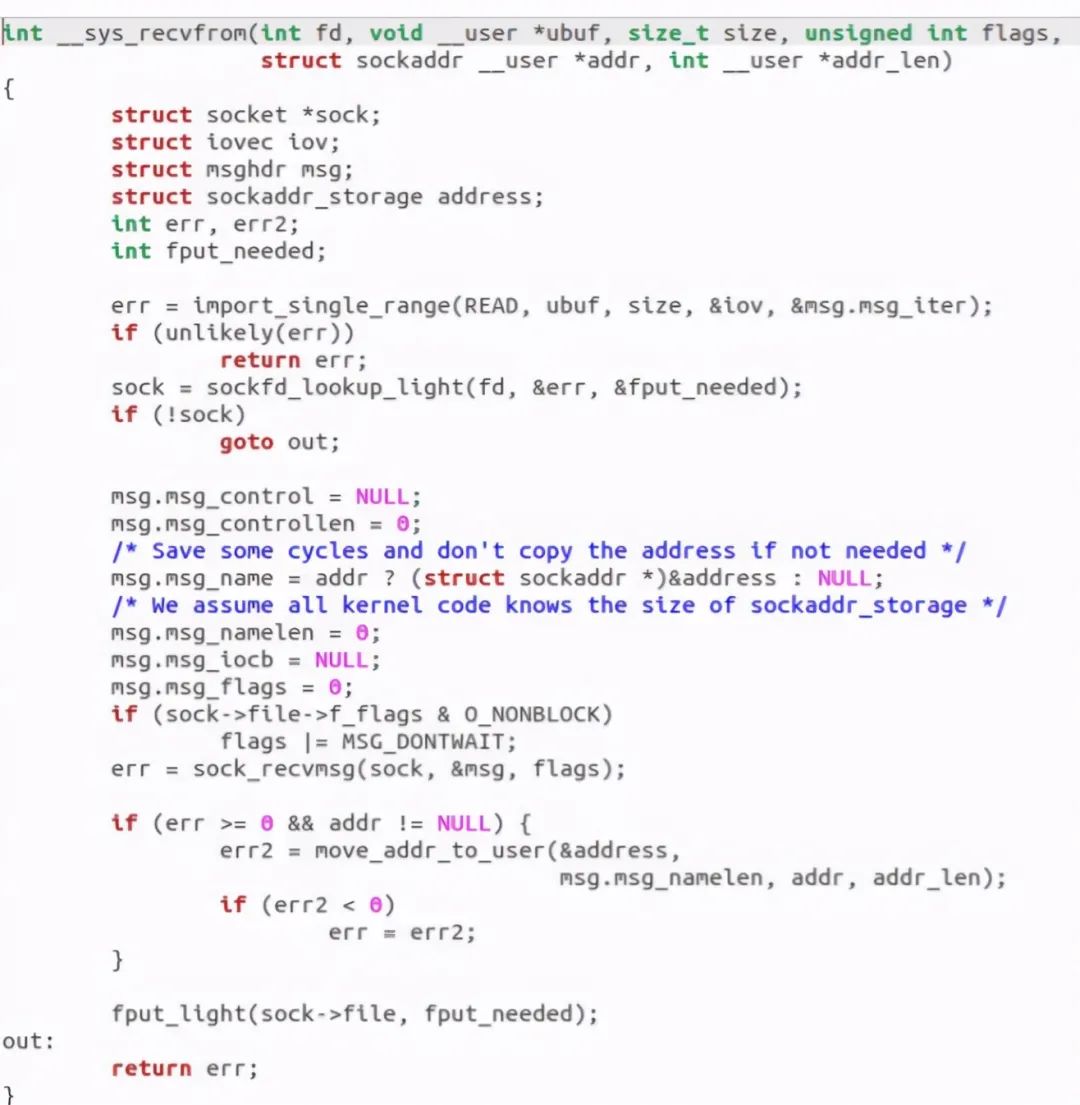
It was found that it called the sock_recvmsg function:

It was found that it called the sock_recvmsg_nosec function:

Found that it called inet_recvmsg function:
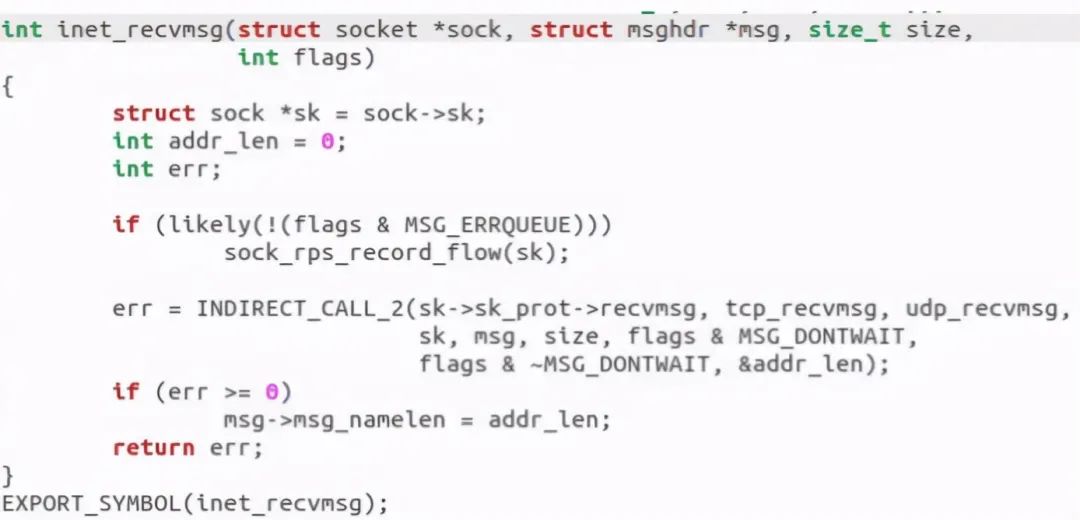
The last call is tcp_. Recvmsg this system call. So far, the receiving end calls the analysis.
The gdb break point is used for verification:
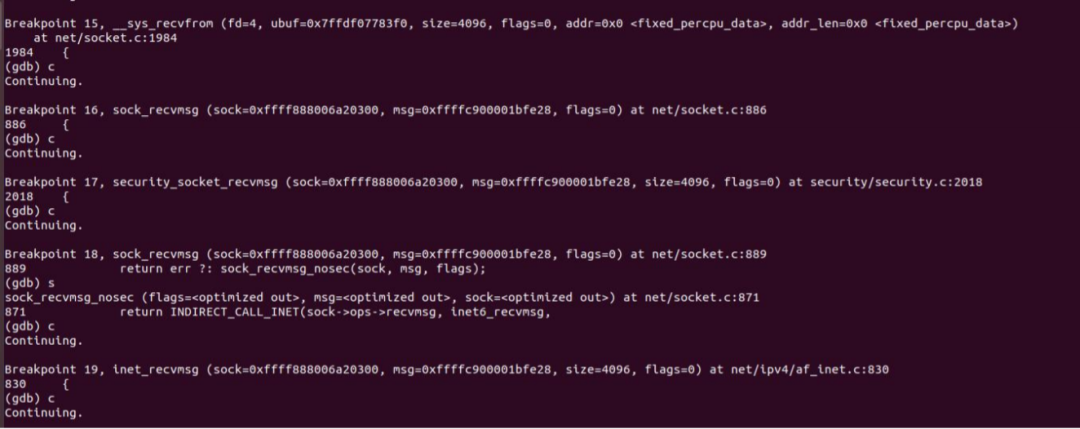
The verification results are just in line with our research.
4 transport layer process
4.1 sender
The ultimate purpose of the transport layer is to provide its users with efficient, reliable and cost-effective data transmission services. Its main functions include (1) constructing TCP segment (2) calculating checksum (3) sending ACK packet (4) sliding window and other reliable operations. The general processing process of TCP protocol stack is shown in the figure below:
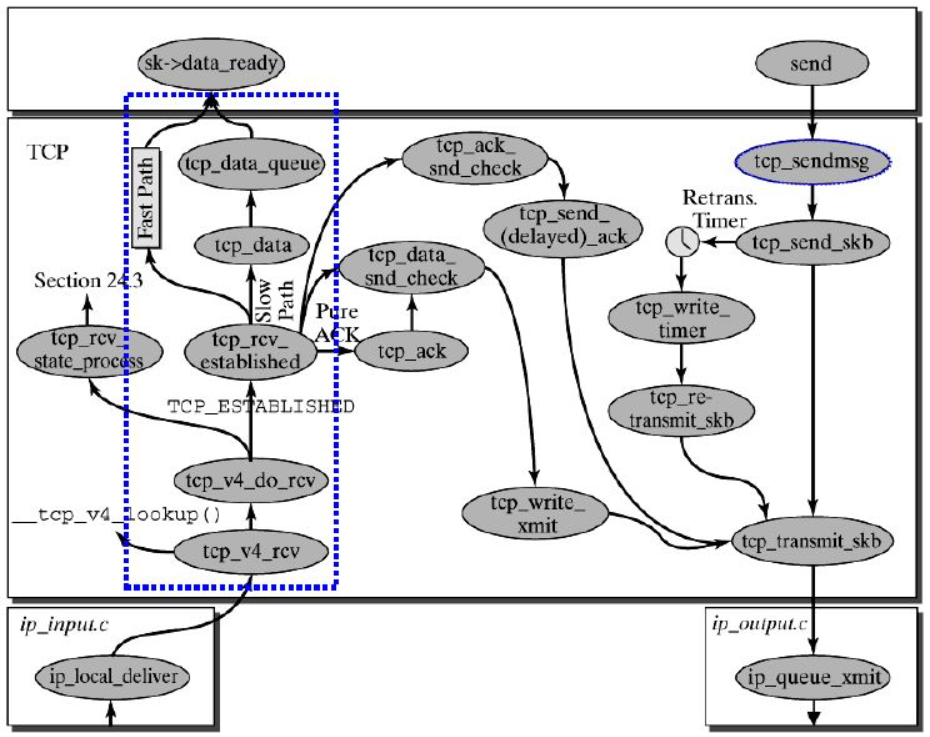
Brief process of TCP stack:
tcp_ The sendmsg function will first check the status of the established TCP connection, then obtain the MSS of the connection and start the segement sending process.
Construct the payload of TCP segment: it creates the sk of the packet in kernel space_ The instance skb of the buffer data structure copies the packet data from the userspace buffer to the skb buffer.
Construct TCP header.
Calculate the TCP checksum and sequence number.
TCP checksum is an end-to-end checksum, which is calculated by the sender and verified by the receiver. Its purpose is to find any changes in the TCP header and data between the sender and the receiver. If the receiver detects an error in the checksum, the TCP segment will be discarded directly. TCP checksum covers TCP header and TCP data.
TCP checksum is required
Send to IP layer for processing: call IP handler handle_ queue_ Xmit, pass skb into the IP processing flow.
UDP stack brief process:
UDP encapsulates message s into UDP datagrams
Call IP_ append_ The data () method sends the packet to the IP layer for processing.
Let's analyze it in sequence in combination with the code:
According to our tracing of the application layer, we can find that the transport layer also calls send () - > SendTo () - > sys first_ sento->sock_ sendmsg->sock_sendmsg_nosec, let's look at the sock_sendmsg_nosec this function:
INET is called in the application layer_ The sendmsg function, which can be known from the following breakpoints at the transport layer, calls the function Sock - > OPS sendmsg. Sendmsg is a macro that calls tcp_sendmsg, as follows;
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
......And tcp_sendmsg actually calls
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
This function is as follows:
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);/*Cast was made*/
struct sk_buff *skb;
flags = msg->msg_flags;
......
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
}In tcp_sendmsg_locked organizes all data into a sending queue, which is a domain SK in the struct sock structure_ write_ Queue, each element of the queue is an skb, which stores the data to be sent. And then called tcp_. Push() function. The structure struct sock is as follows:
struct sock{
...
struct sk_buff_head sk_write_queue;/*Points to the first element of the skb queue*/
...
struct sk_buff *sk_send_head;/*Points to the first element in the queue that has not yet been sent*/
}There are several flag fields in the header of tcp protocol: URG, ACK, RSH, RST, SYN, fin, tcp_ Whether the element of this skb needs to be pushed will be judged in the push. If necessary, set the push of the tcp header field to one. The process of setting one is as follows:
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
__tcp_push_pending_frames(sk, mss_now, nonagle);
}First, struct TCP_ skb_ The cb structure stores the header of TCP, and the control bit of the header is tcp_flags, via tcp_mark_push will convert cb in SKB, that is, 48 byte array, into struct tcp_skb_cb, so cb in SKB becomes the head of TCP. tcp_mark_push as follows:
static inline void tcp_mark_push(struct tcp_sock *tp, struct sk_buff *skb)
{
TCP_SKB_CB(skb)->tcp_flags |= TCPHDR_PSH;
tp->pushed_seq = tp->write_seq;
}
...
#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))
...
struct sk_buff {
...
char cb[48] __aligned(8);
...struct tcp_skb_cb {
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u8 tcp_flags; /* tcp Header flag, in the 13th byte (tcp[13]) */
......
};Then, tcp_push called__ tcp_push_pending_frames(sk, mss_now, nonagle); Function to send data:
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}It was found that it called tcp_write_xmit function to send data:
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
/*Count the total number of messages sent*/
sent_pkts = 0;
......
/*If the sending queue is not full, prepare to send a message*/
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
/* "skb_mstamp_ns" is used as a start point for the retransmit timer */
skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
tcp_init_tso_segs(skb, mss_now);
goto repair; /* Skip network transmission */
}
if (tcp_pacing_check(sk))
break;
tso_segs = tcp_init_tso_segs(skb, mss_now);
BUG_ON(!tso_segs);
/*Check the size of the send window*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else
break;
}
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
is_rwnd_limited = true;
break;
......
limit = mss_now;
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
min_t(unsigned int,
cwnd_quota,
max_segs),
nonagle);
if (skb->len > limit &&
unlikely(tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE,
skb, limit, mss_now, gfp)))
break;
if (tcp_small_queue_check(sk, skb, 0))
break;
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
......tcp_write_xmit is located at tcpoutput In C, it implements TCP congestion control, and then calls tcp_. transmit_ SKB (SK, SKB, 1, GFP) transfers data, which actually calls__ tcp_transmit_skb:
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
......
/* Building TCP headers and checksums */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
tcp_options_write((__be32 *)(th + 1), tp, &opts);
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
......
icsk->icsk_af_ops->send_check(sk, skb);
if (likely(tcb->tcp_flags & TCPHDR_ACK))
tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt);
if (skb->len != tcp_header_size) {
tcp_event_data_sent(tp, sk);
tp->data_segs_out += tcp_skb_pcount(skb);
tp->bytes_sent += skb->len - tcp_header_size;
}
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq)
TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS,
tcp_skb_pcount(skb));
tp->segs_out += tcp_skb_pcount(skb);
/* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */
skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb);
skb_shinfo(skb)->gso_size = tcp_skb_mss(skb);
/* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */
/* Cleanup our debris for IP stacks */
memset(skb->cb, 0, max(sizeof(struct inet_skb_parm),
sizeof(struct inet6_skb_parm)));
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
......
}tcp_transmit_skb is the last step that TCP sends data to the transport layer. First, the header of TCP data segment is processed, then the sending interface icsk->icsk_ provided by the network layer is called. af_ ops->queue_ xmit(sk, skb, &inet->cork.fl); The data transmission is realized. Since then, the data leaves the transport layer, and the task of the transport layer is over.
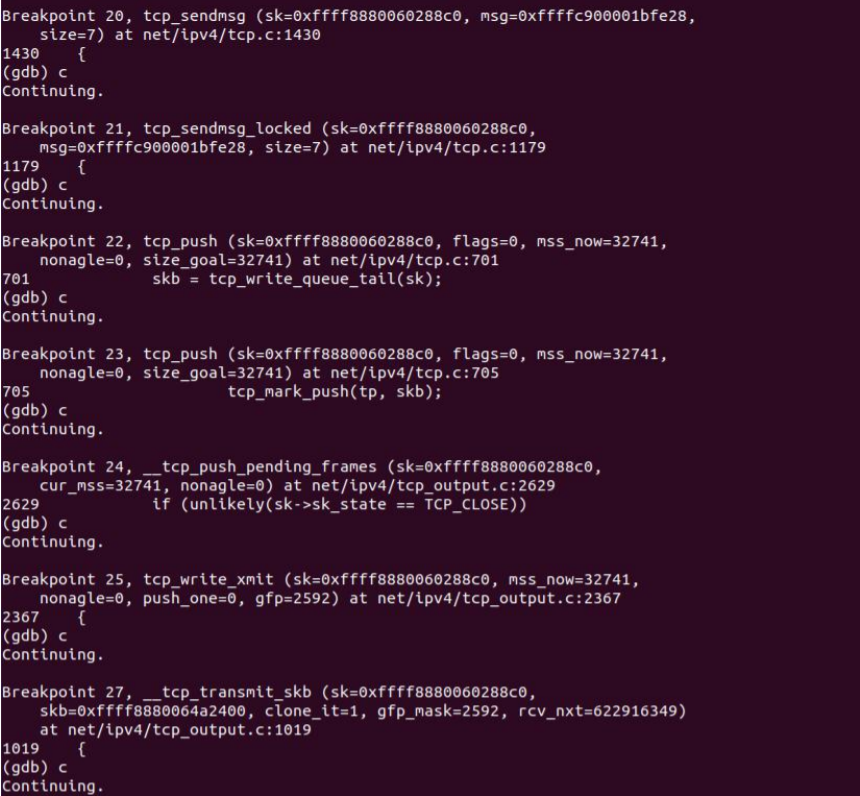
gdb debugging verification is as follows:
4.2 receiving end
Transport layer TCP processing entry_ v4_ RCV function (located in linux/net/ipv4/tcp ipv4.c file), which will perform TCP header check and other processing.
Call_ tcp_v4_lookup to find the open socket of the package. If not found, the package will be discarded. Next, check the status of socket and connection.
If the socket and connection are all normal, call tcp_prequeue enables the package to enter the user space from the kernel and put it into the receive queue of the socket. Then the socket will wake up, call system call, and finally call tcp_recvmsg function to obtain segment from socket receive queue.
For the code phase of the transport layer, we need to analyze the recv function, which is similar to send and calls__ sys_recvfrom, the calling path of the whole function is very similar to send:
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
......
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
.....
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don't copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
.....
}__ sys_recvfrom called the sock_recvmsg to receive data. The whole function actually calls Sock - > Ops - > recvmsg (sock, MSG, msg_data_left (MSG), flags);, Similarly, according to TCP_ The initialization of prot structure actually calls tcp_rcvmsg
The receiving function is much more complex than the sending function, because the data reception is not only the reception, but also the three handshakes of tcp are realized in the receiving function. Therefore, after receiving the data, we should judge the current state, whether the connection is being established, etc., and consider whether the state should be changed according to the sent information. Here, we only consider the data reception after the connection is established.
tcp_ The rcvmsg function is as follows:
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
......
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
.....
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
......
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
......
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
There are three queues maintained here: prequeue, backlog and receive_queue refers to preprocessing queue, backup queue and receiving queue respectively. After the connection is established, if there is no data, the receiving queue is empty and the process will be in sk_busy_loop function waits circularly, knows that the receiving queue is not empty, and calls the function number skb_copy_datagram_msg copies the received data to the user status, and the actual call is__ skb_datagram_iter is also implemented with struct msghdr *msg__ skb_ datagram_ The ITER function is as follows:
int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *, struct iov_iter *),
void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* Copy tcp header */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* Copy data section */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + frag->page_offset +
offset - start, copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}After the copy is completed, the function returns and the whole receiving process is completed.
It can be represented by a mutual call graph between functions:
The verification through gdb debugging is as follows:
Breakpoint 1, __sys_recvfrom (fd=5, ubuf=0x7ffd9428d960, size=1024, flags=0,
addr=0x0 <fixed_percpu_data>, addr_len=0x0 <fixed_percpu_data>)
at net/socket.c:1990
1990 {
(gdb) c
Continuing.
Breakpoint 2, sock_recvmsg (sock=0xffff888006df1900, msg=0xffffc900001f7e28,
flags=0) at net/socket.c:891
891 {
(gdb) c
Continuing.
Breakpoint 3, tcp_recvmsg (sk=0xffff888006479100, msg=0xffffc900001f7e28,
len=1024, nonblock=0, flags=0, addr_len=0xffffc900001f7df4)
at net/ipv4/tcp.c:1933
1933 {
(gdb) cBreakpoint 1, __sys_recvfrom (fd=5, ubuf=0x7ffd9428d960, size=1024, flags=0,
addr=0x0 <fixed_percpu_data>, addr_len=0x0 <fixed_percpu_data>)
at net/socket.c:1990
1990 {
(gdb) c
Continuing.
Breakpoint 2, sock_recvmsg (sock=0xffff888006df1900, msg=0xffffc900001f7e28,
flags=0) at net/socket.c:891
891 {
(gdb) c
Continuing.
Breakpoint 3, tcp_recvmsg (sk=0xffff888006479100, msg=0xffffc900001f7e28,
len=1024, nonblock=0, flags=0, addr_len=0xffffc900001f7df4)
at net/ipv4/tcp.c:1933
1933 {
(gdb) c
Continuing.
Breakpoint 4, __skb_datagram_iter (skb=0xffff8880068714e0, offset=0,
to=0xffffc900001efe38, len=2, fault_short=false,
cb=0xffffffff817ff860 <simple_copy_to_iter>, data=0x0 <fixed_percpu_data>)
at net/core/datagram.c:414
414 {Consistent with our previous analysis.
5 IP layer process
5.1 sender
The task of the network layer is to select the appropriate inter network routing and switching nodes to ensure the timely transmission of data. The network layer forms the frame provided by the data link layer into a data packet, which is encapsulated with the network layer packet header, which contains the logical address information - the network address of the source site and the destination site address. Its main tasks include (1) routing processing, that is, selecting the next hop (2) adding IP header (3) calculating IP header checksum to detect whether there is an error in the propagation process of IP message header (4) IP fragmentation if possible (5) after processing, obtaining the MAC address of the next hop, setting the link layer header, and then transferring to the link layer processing.
IP header:
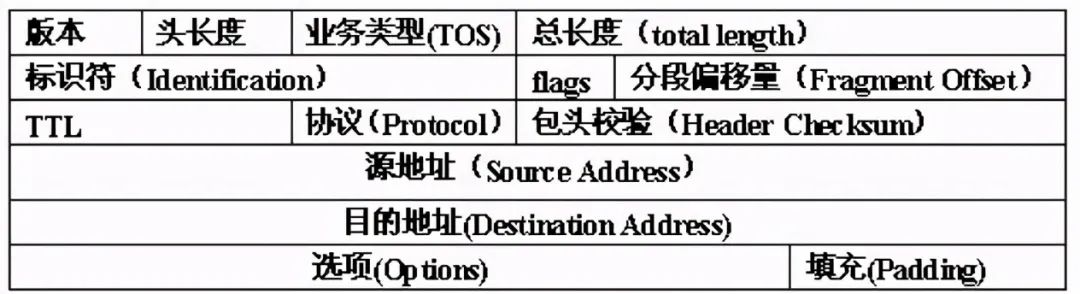
The basic processing process of IP stack is shown in the following figure:
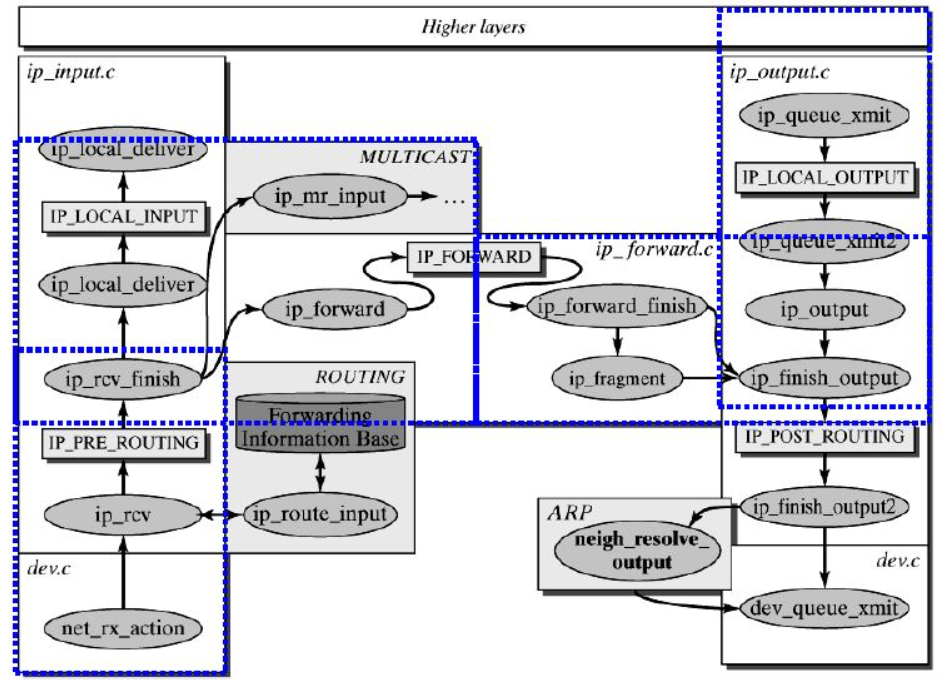
First, ip_queue_xmit(skb) will check SKB - > DST routing information. If not, such as the first packet of the socket, use ip_route_output() selects a route.
Then, fill in various fields of the IP packet, such as version, packet header length, TOS, etc.
For some pieces in the middle, please refer to the relevant documents. The basic idea is that when the length of the message is greater than mtu and the length of gso is not 0, IP will be called_ Fragment, otherwise IP will be called_ finish_ Output2 sends data. ip_ In the fragment function, the IP address is checked_ DF flag bit. If the IP packet to be segmented is prohibited from being segmented, call icmp_send() sends an unreachable ICMP message to the sender for the purpose of setting the no fragmentation flag because it needs fragmentation, and discards the message, that is, set the IP status as fragmentation failure, release skb, and return the message too long error code.
Next, use ip_finish_ouput2 sets the link layer header. If the link layer header cache is (i.e. hh is not empty), copy it to skb. If not, call neigh_resolve_output, obtained using ARP.
The specific code analysis is as follows:
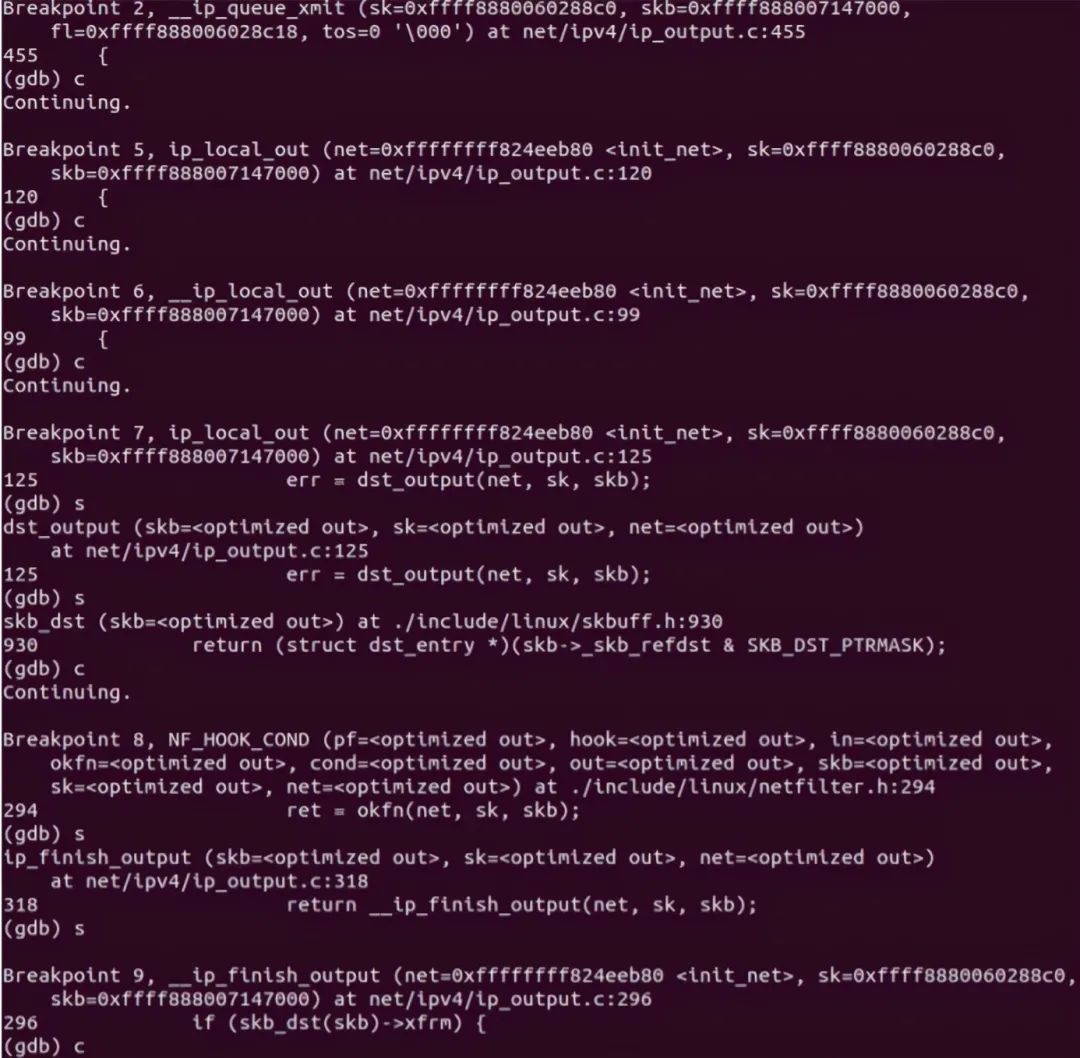
The entry function is ip_queue_xmit, the function is as follows:

Found call__ ip_queue_xmit function:
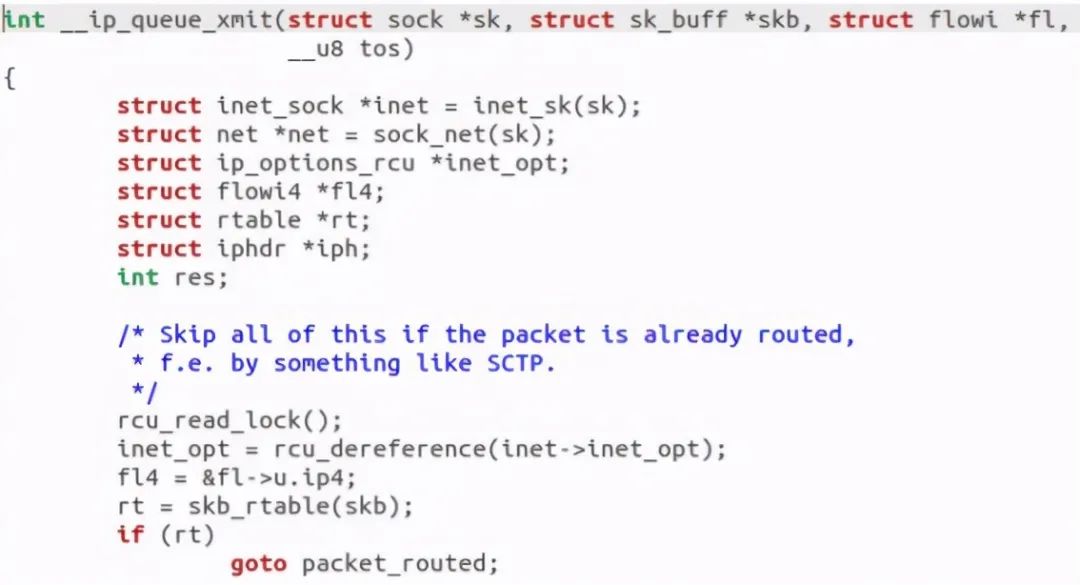
Found calling SKB_ The rtable function actually starts to find the routing cache. Continue:
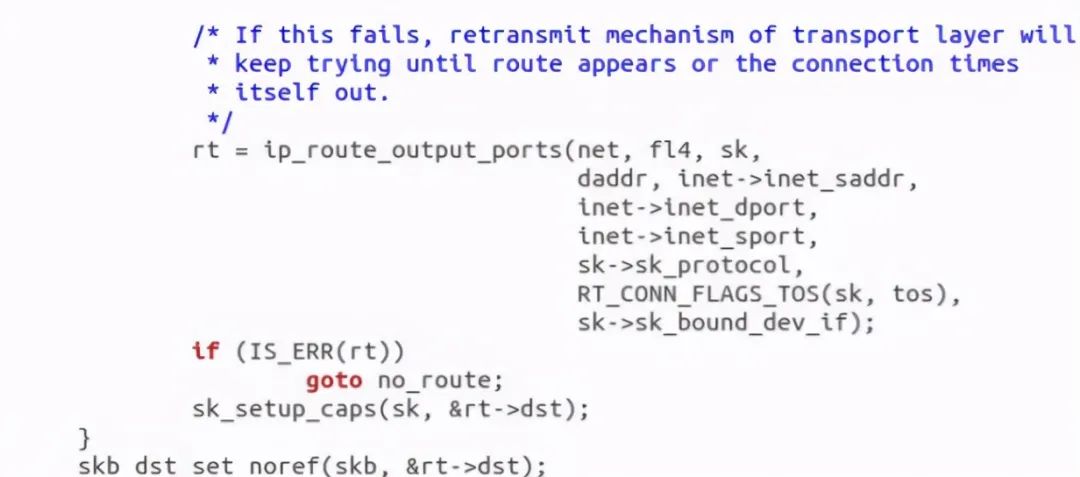
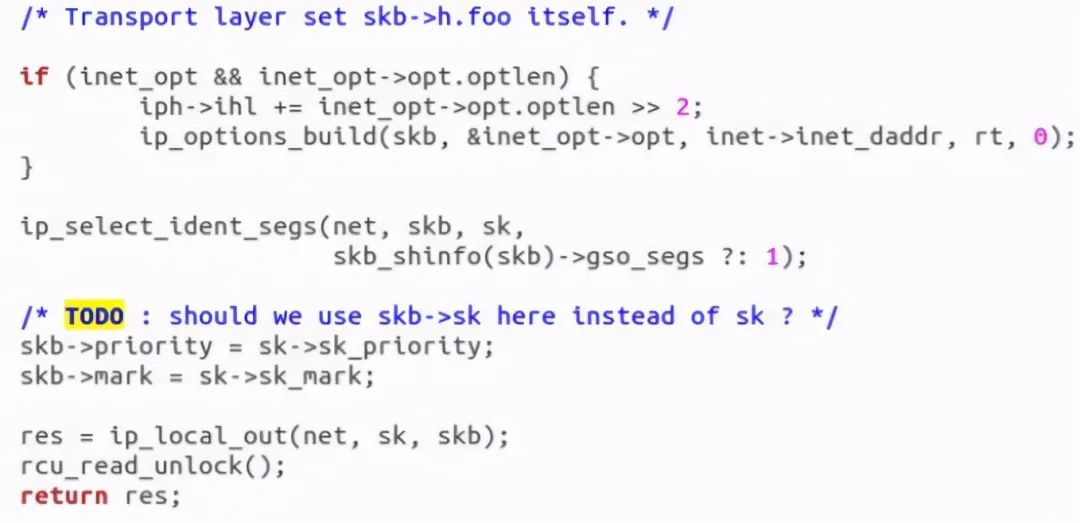
Discovery call ip_local_out to send data:

Discovery call__ ip_local_out function:

An NF was returned after discovery_ Hook function, which calls dst_output, this function essentially calls ip_finish__output function:

Discovery call__ ip_finish_output function:
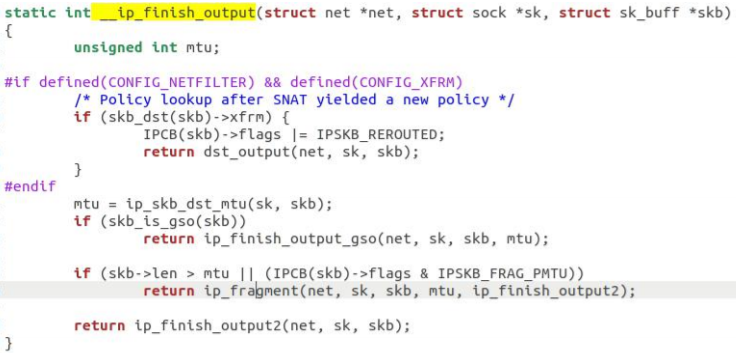
Call IP if slicing_ Fragment, otherwise IP is called_ finish_ Output2 function:

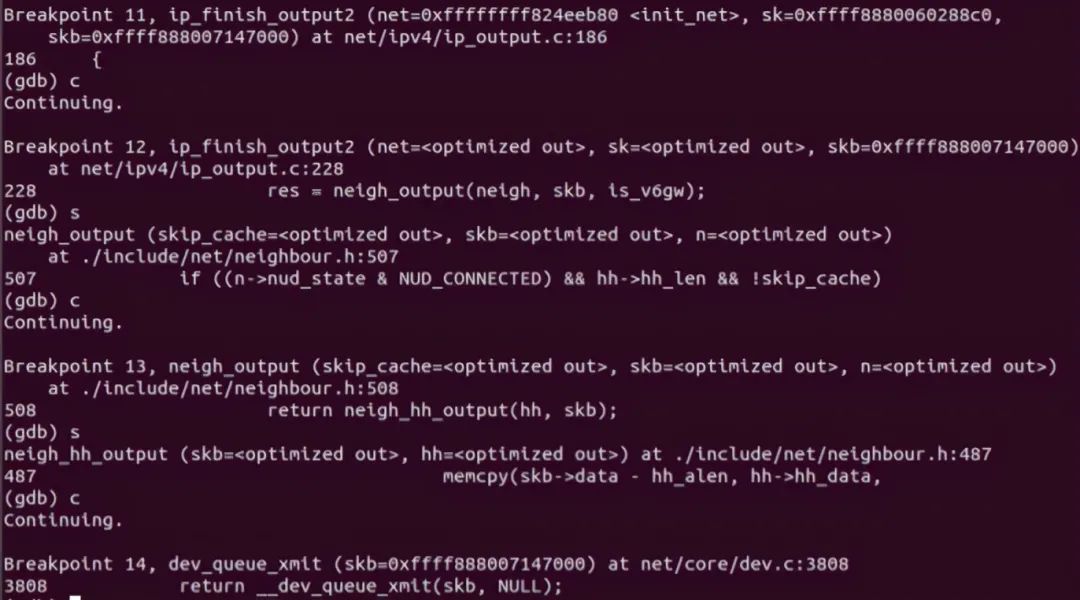
After constructing the ip header and checking the fragmentation, it will call the output function neigh of the neighbor subsystem_ Output. neigh_ The output function is as follows:

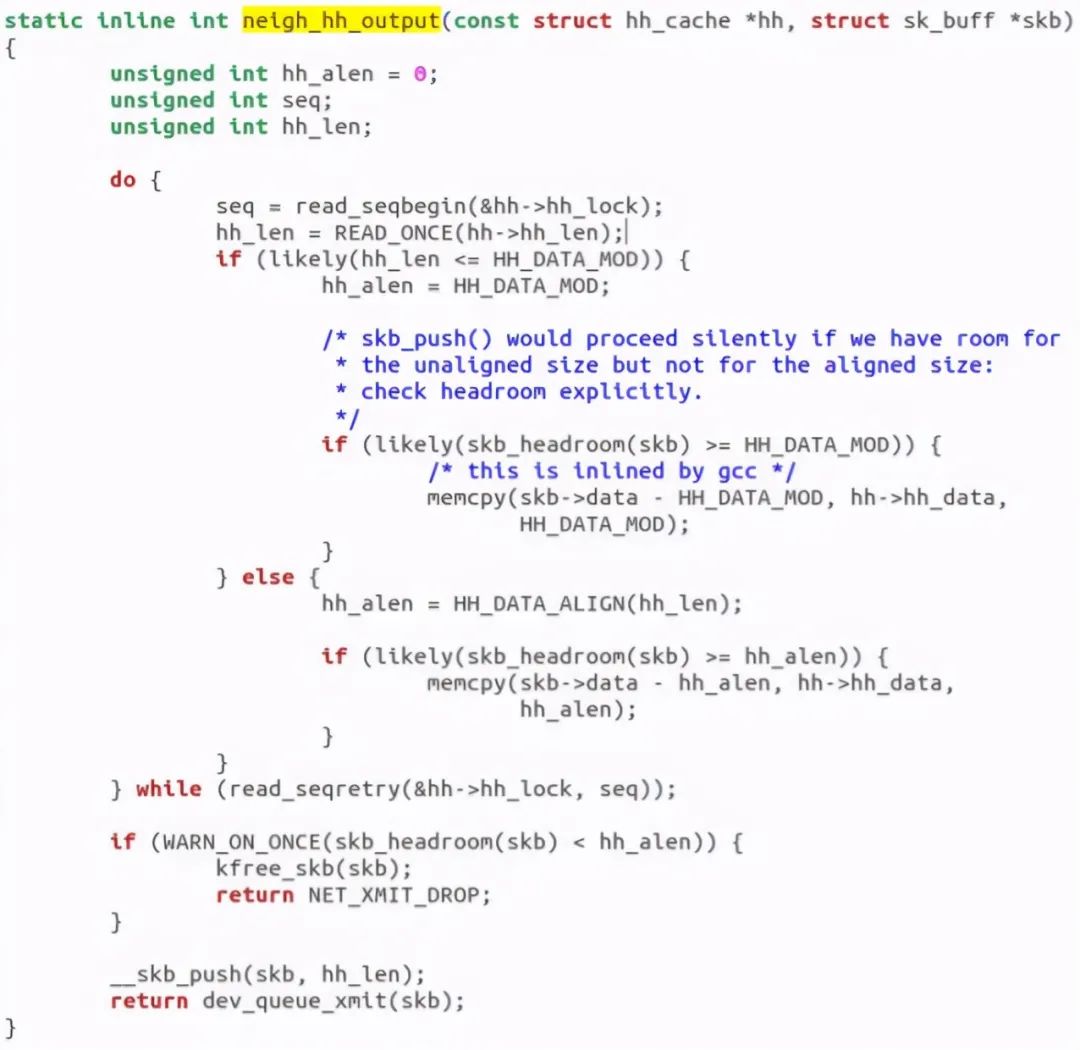
The output can be divided into two cases: with layer-2 header cache and without cache. Call neigh when there is cache_ hh_ Output for fast output. If there is no cache, call the output callback function of the neighbor subsystem for slow output. This function is as follows:
Finally, call dev_. queue_ The Xmit function sends packets to the link layer, which ends here. gdb verification is as follows:
5.2 receiving end
IP layer entry function_ RCV function. This function will first perform various checks including package checksum. If necessary, it will perform IP defragment ation (merging multiple fragments), and then the packet will call the registered pre routing Netfilter hook. After that, it will finally reach the IP address_ rcv_ Finish function.
ip_ rcv_ The finish function calls IP_ router_ The input function enters the route processing link. It first calls ip_route_input to update the route, and then find the route to determine whether the package will be sent to the local machine, forwarded or discarded:
If it is sent to the local machine, call IP_ local_ The deliver function may do de-fragment (merge multiple IP packet), and then invoke ip_. local_ The deliver function. This function calls the next layer interface, including TCP, according to the protocol number of the next processing layer of the package_ v4_ rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP). For TCP, the function TCP_ v4_ The RCV function will be called and the processing flow will enter the TCP stack.
If forward is required, enter the forwarding process. This process needs to process TTL and then call dst_input function. This function will
(1) Handling Netfilter Hook
(2) Perform IP fragmentation
(3) Call dev_queue_xmit, enter the link layer processing flow.
The reception is relatively simple, and the entry is over ip_rcv, this function is as follows:
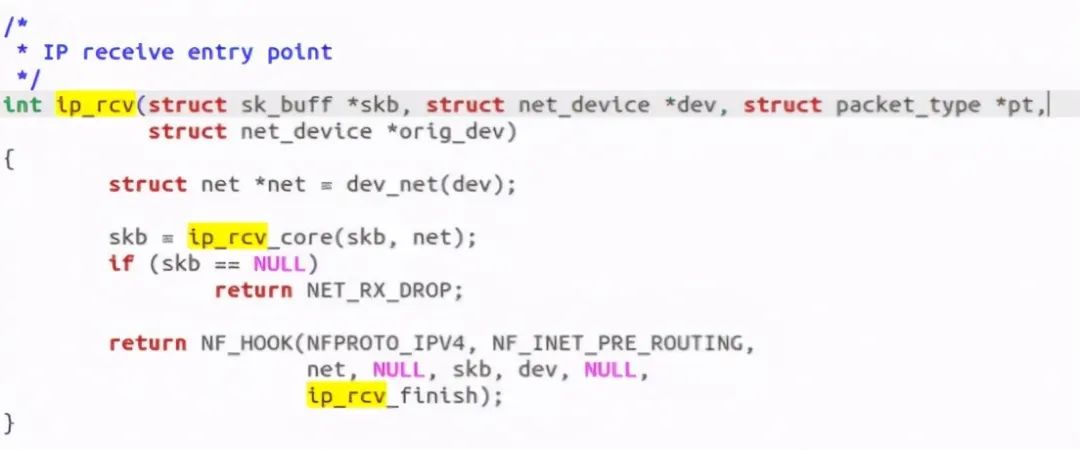
Call IP inside_ rcv_ Finish function:
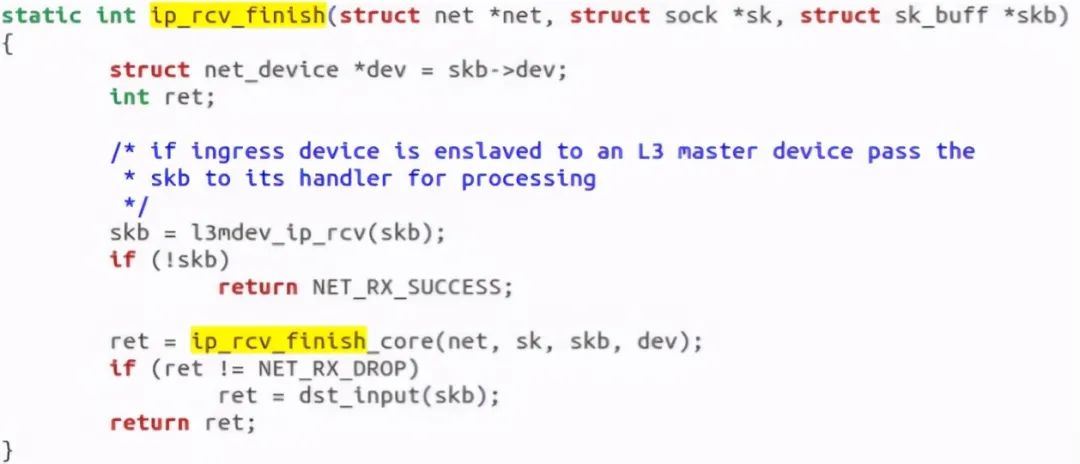
Discovery call DST_ The input function actually calls ip_local_deliver function:

If it is fragmented, IP is called_ Defrag function, if not, call ip_local_deliver_finish function:

Discovery call ip_protocol_deliver_rcu function:

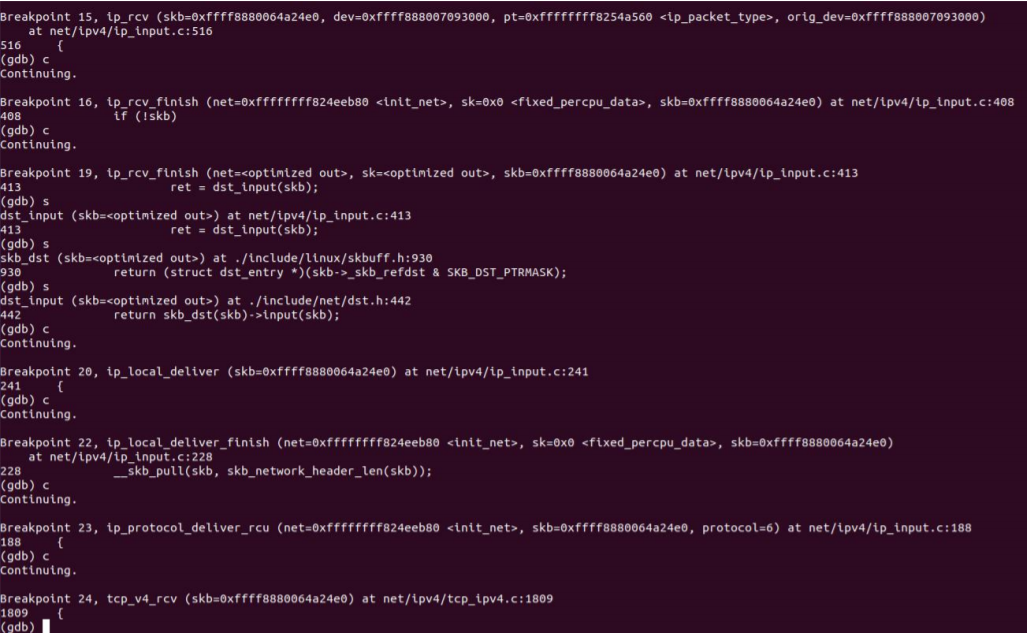
After the call, enter the tcp stack. After the call, it is verified by gdb as follows:
6 data link layer process
6.1 sender
Functionally, based on the bit stream service provided by the physical layer, the data link between adjacent nodes is established, the error free transmission of data Frame on the channel is provided through error control, and the action series on each circuit is carried out.
The data link layer provides reliable transmission on unreliable physical media.
The functions of this layer include: physical address addressing, data framing, flow control, data error detection, retransmission, etc. In this layer, the unit of data is called frame. Representatives of data link layer protocols include: SDLC, HDLC, PPP, STP, frame relay, etc.
In terms of implementation, Linux provides an abstraction layer of Network Device, which is now linux/net/core/dev.c. The specific physical Network Device needs to implement the virtual function in the device driver (driver.c). The Network Device abstraction layer calls the functions of specific network devices.
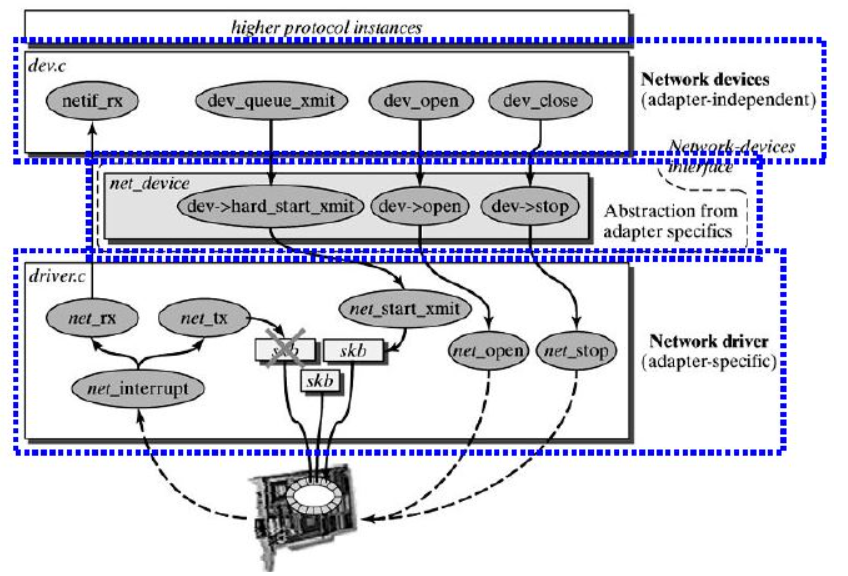
The sender calls dev_queue_xmit, this function actually calls__ dev_queue_xmit:
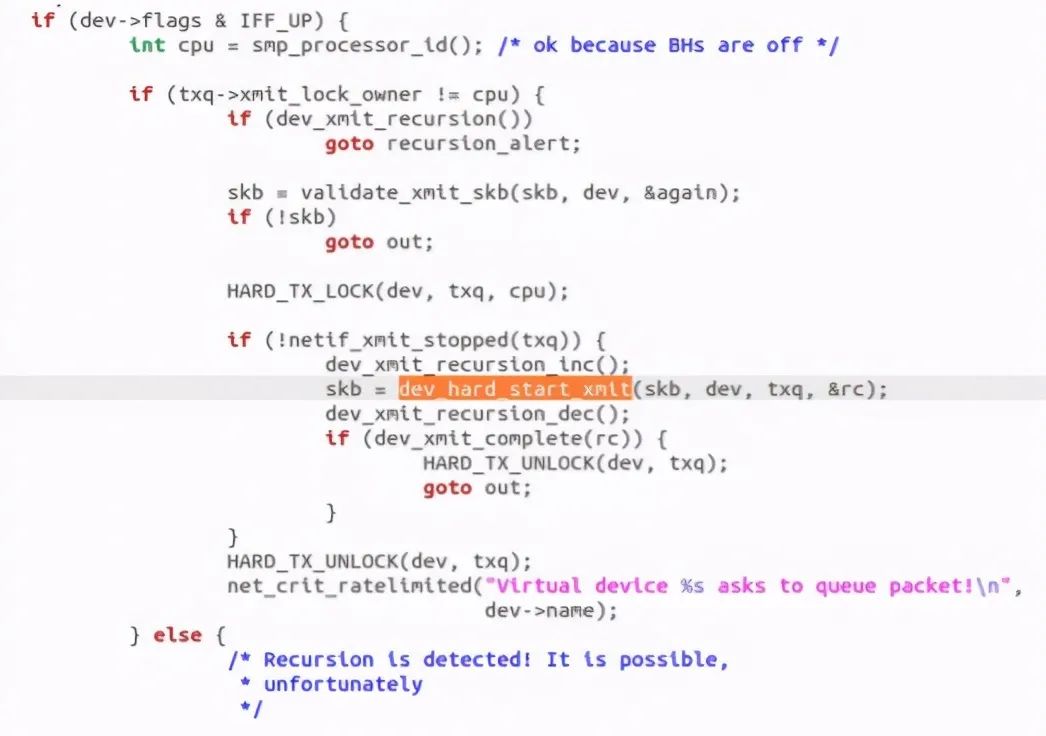
Found that it called dev_hard_start_xmit function:

Call xmit_one:
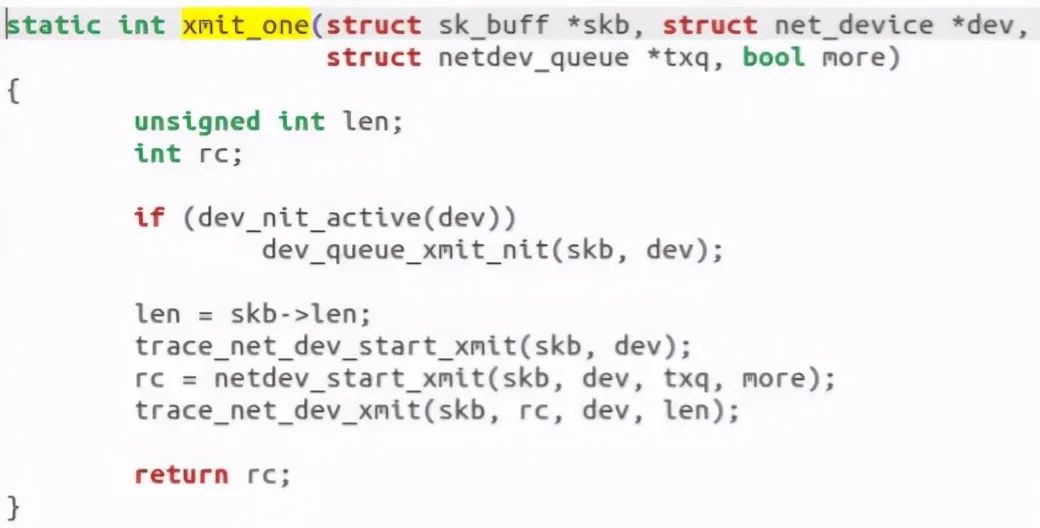
Call trace_net_dev_start_xmit, actually called__ net_dev_start_xmit function:

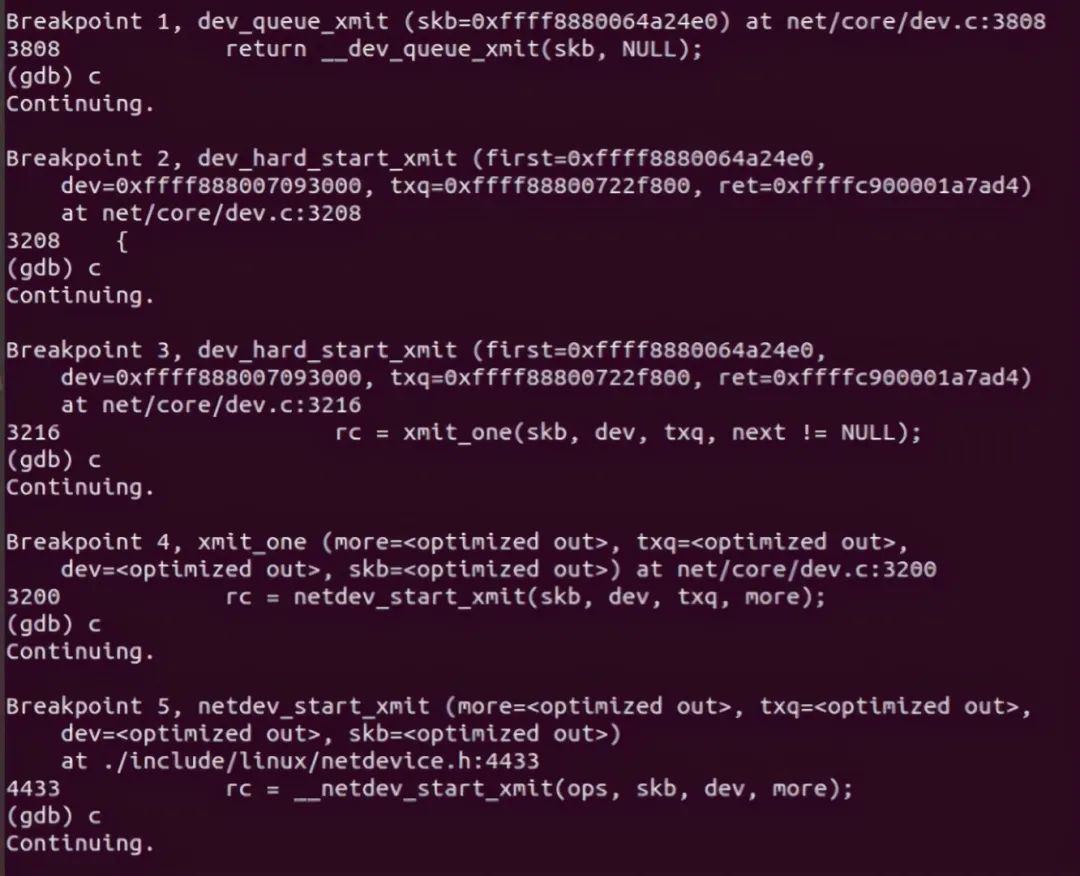
At this point, the call chain ends. gdb debugging is as follows:
6.2 receiving end
Brief process:
A package arrives at the physical network adapter of the machine. When it receives the data frame, it will trigger an interrupt and transfer it to Rx in the linux kernel memory through DMA_ ring.
The network card sends an interrupt to inform the CPU that there is a package that needs to be processed by it. The interrupt handler mainly performs the following operations, including allocating skb_buff data structure, and copy the received data frame from the network adapter I/O port to skb_buff buffer;
Extract some information from the data frame and set skb_buff corresponding parameters, which will be used by the upper layer network protocol, such as SKB - > protocol;
After simple processing, the terminal handler sends a soft interrupt (NET_RX_SOFTIRQ) to notify the kernel of receiving a new data frame.
Kernel 2.5 introduces a new set of API s to process the received data frames, namely NAPI. Therefore, the driver has two ways to notify the kernel: (1) through the previous function netif_rx; (2) Through NAPI mechanism. The interrupt handler calls netif of Network device_ rx_ Schedule function, enter the soft interrupt processing flow, and then call net_rx_action function.
This function closes the interrupt and obtains the RX of each Network device_ All packages in ring, and the final package is from rx_ring is deleted and enters netif_ receive_ SKB processing flow.
netif_receive_skb is the last station in the link layer to receive datagrams. It is based on ptype registered in the global array_ All and ptype_ The network layer datagram type in base, which submits datagrams to the receiving functions of different network layer protocols (mainly ip_rcv and arp_rcv in INET domain). This function is mainly to call the receiving function of the layer 3 protocol to process the skb packet and enter the layer 3 network layer for processing.
The entry function is net_rx_action:
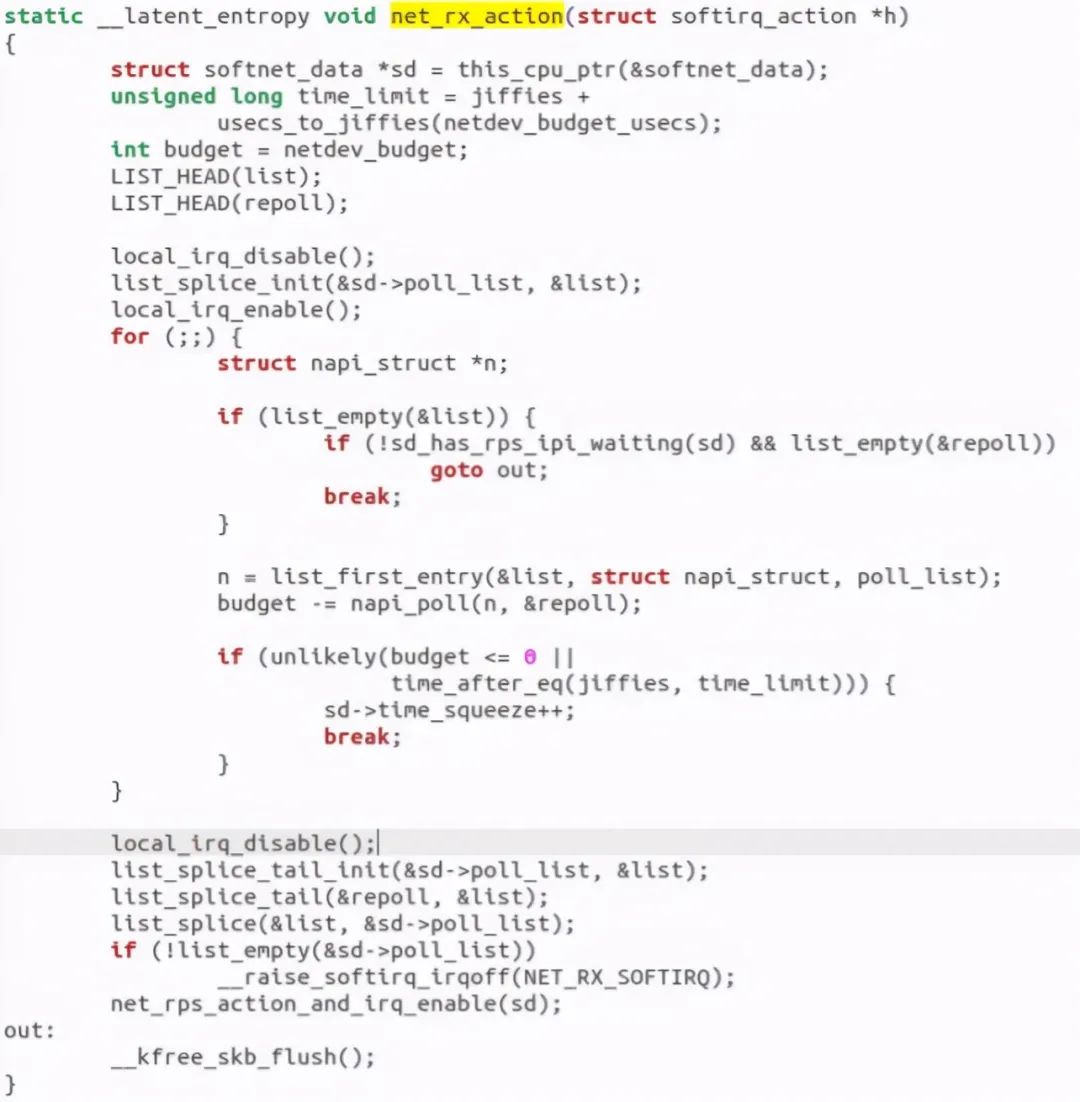
Find and call napi_poll, which essentially calls napi_gro_receive function:
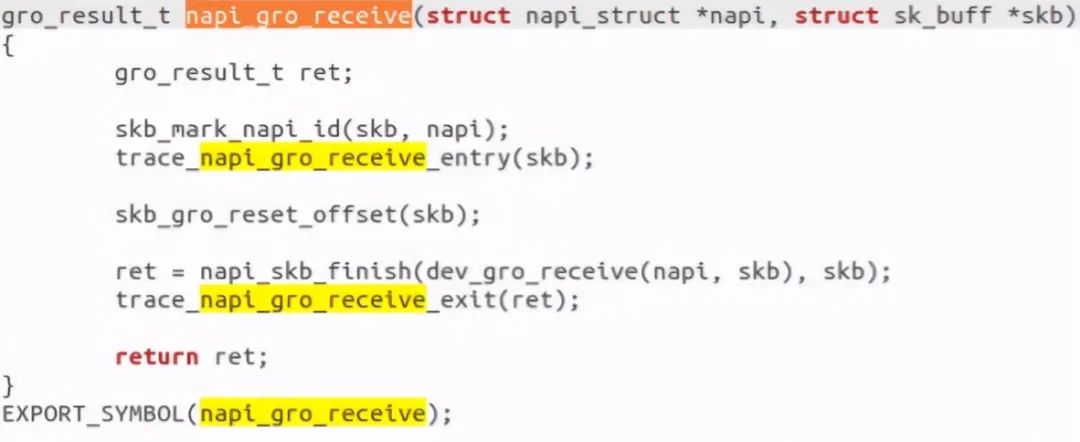
napi_gro_receive will call netif directly_ receive_ skb_ core. And it calls__ netif_receive_skb_one_core, deliver the data packet to the upper ip_rcv for processing.

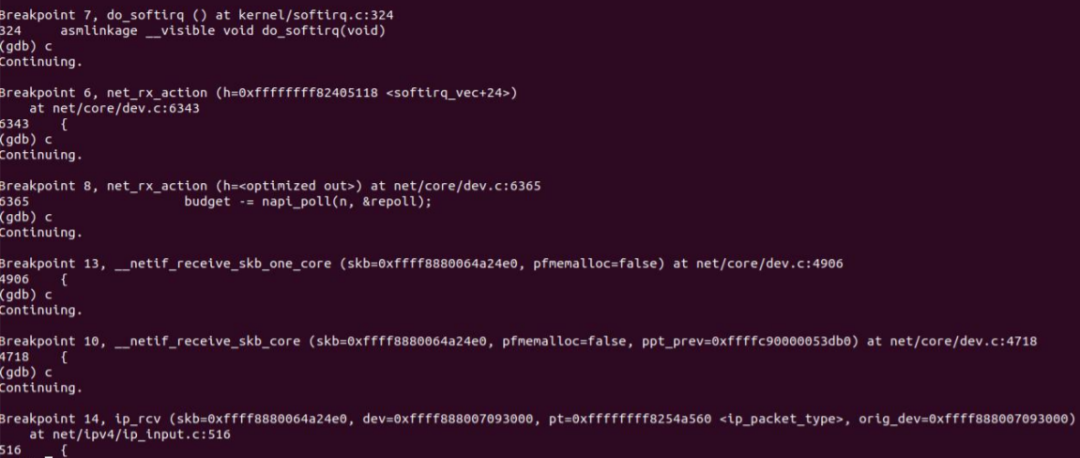
After the call is completed, the CPU is notified through soft interrupt. At this point, the call chain ends. gdb verification is as follows:
7 physical layer process
7.1 sender
After receiving the transmission request, the physical layer copies the data in the main memory to the internal RAM (buffer) through DMA. In the data copy, relevant header s, IFG, preamble and CRC conforming to Ethernet Protocol shall be added at the same time. For Ethernet networks, CSMA/CD is used for physical layer transmission, that is, to listen for link conflicts during transmission.
Once the network card completes the message sending, an interrupt notification will be generated to the CPU, and then the interrupt handler in the driver layer can delete the saved skb.
7.2 receiving end
A package arrives at the physical network adapter of the machine. When it receives the data frame, it will trigger an interrupt and transfer it to Rx in the linux kernel memory through DMA_ ring.
The network card sends an interrupt to inform the CPU that there is a package that needs to be processed by it. The interrupt handler mainly performs the following operations, including allocating skb_buff data structure, and copy the received data frame from the network adapter I/O port to skb_buff buffer; Extract some information from the data frame and set skb_buff corresponding parameters, which will be used by the upper layer network protocol, such as SKB - > protocol;
After simple processing, the terminal handler sends a soft interrupt (NET_RX_SOFTIRQ) to notify the kernel of receiving a new data frame.
Kernel 2.5 introduces a new set of API s to process the received data frames, namely NAPI. Therefore, the driver has two ways to notify the kernel: (1) through the previous function netif_rx; (2) Through NAPI mechanism. The interrupt handler calls netif of Network device_ rx_ Schedule function, enter the soft interrupt processing flow, and then call net_rx_action function.
This function closes the interrupt and obtains the RX of each Network device_ All packages in ring, and the final package is from rx_ring is deleted and enters netif_ receive_ SKB processing flow.
netif_receive_skb is the last station in the link layer to receive datagrams. It is based on ptype registered in the global array_ All and ptype_ The network layer datagram type in base, which submits datagrams to the receiving functions of different network layer protocols (mainly ip_rcv and arp_rcv in INET domain). This function is mainly to call the receiving function of the layer 3 protocol to process the skb packet and enter the layer 3 network layer for processing.
8 sequence diagram display and summary
The sequence diagram is as follows:
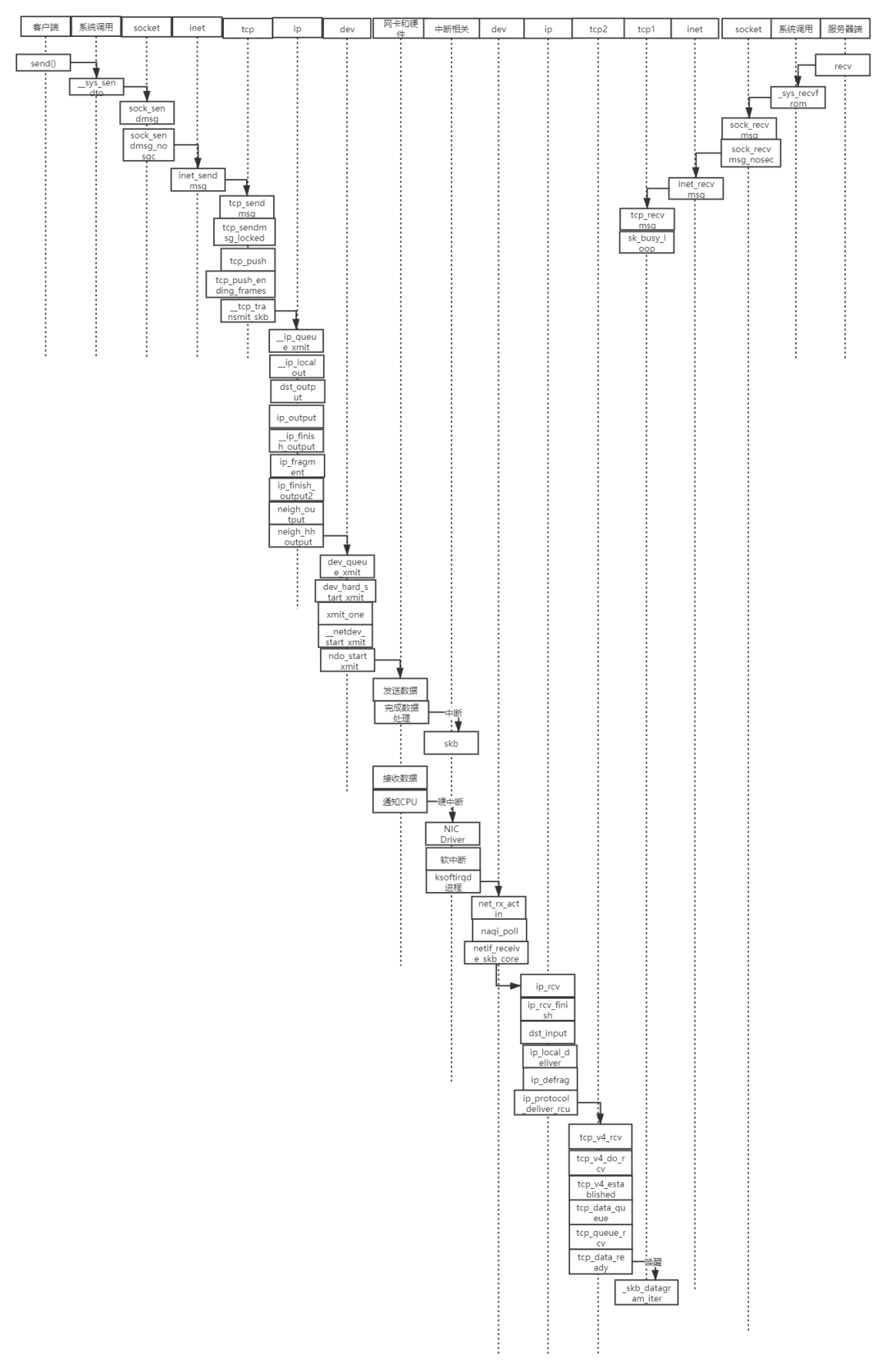
This experiment mainly analyzes the source code of Linux kernel, debugs the function call chain step by step through gdb, and finally understands the call process of tcp/ip protocol stack. Because time is limited, some details may be wrong. I hope readers can make more corrections.