Project description
Train a simple convolutional neural network to realize the classification of food pictures.
Data set introduction
The data set used this time is food-11 data set, which has 11 categories in total
Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.
(bread, dairy products, desserts, eggs, fried food, meat, noodles / spaghetti, rice, seafood, soup, vegetables / fruits)
Training set: 9866 sheets
Validation set: 3430 sheets
Testing set: 3347 sheets
data format
After downloading the zip file and decompressing it, there will be three folders: training, validation and testing
The format of photo name in training and validation is [category]_ [No.] Jpg, e.g. 3_100.jpg is the photo of Category 3 (the number is not important)
Decompress data
Run only once!
!unzip -d work data/data76472/food-11.zip # Decompress the food-11 dataset
Introduction environment
import os import paddle import paddle.vision.transforms as T import numpy as np import pandas as pd from PIL import Image import paddle.nn.functional as F
Pretreatment link
#Only run once!!!!
For the naming of pictures, the index file is generated
The format of photo name is [category]_ [No.] Jpg, e.g. 3_100.jpg is the photo of Category 3 (the number is not important)
data_path = '/home/aistudio/work/food-11/' # Set initial file address
character_folders = os.listdir(data_path) # Give absolute address
#Process the training set
for character_folder in character_folders:
with open(f'./training_set.txt', 'a') as f_train:
character_imgs = os.listdir(os.path.join(data_path,character_folder))
#Initialize counter
CNT = 0
for img in character_imgs:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + img[0:img.rfind('_', 1)] + '\n')
CNT += 1
#Processing validation sets
for character_folder in character_folders:
with open(f'./validation_set.txt', 'a') as f_train:
character_imgs = os.listdir(os.path.join(data_path,character_folder))
#Initialize counter
CNT = 0
for img in character_imgs:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + img[0:img.rfind('_', 1)] + '\n')
CNT += 1
#Processing test sets
for character_folder in character_folders:
with open(f'./test_set.txt', 'a') as f_train:
character_imgs = os.listdir(os.path.join(data_path,character_folder))
#Initialize counter
CNT = 0
for img in character_imgs:
f_train.write(os.path.join(data_path,character_folder,img) + '\n')
CNT += 1
print(character_folder,CNT)
training 9866 validation 3430 testing 3347
Verify whether the corresponding relationship is correct
tf="training_set.txt"
with open(tf) as f:
tfl=f.readlines()
#print(tfl)
outlist=[]
for i in tfl:
outlist.append(i[:-1])
print(outlist,'/n')
EDA (Exploratory Data Analysis)
View the data volume and distribution of each category.
pandas is used here for data processing
For txt files without header, you can use read_ The names parameter of table and command it. Refer to this article
For the use of Pandas, please refer to the following articles
pandas learning record
#Read txt text
df = pd.read_table(tf,sep='\t',names=['name','label'])
print(df)
#Then select the data under the label column to draw
d = df['label'].hist().get_figure()
d.savefig("EDA.png")
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2021-04-05 16:06:54,139 - INFO - font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']
name label
0 /home/aistudio/work/food-11/training/3_288.jpg 3
1 /home/aistudio/work/food-11/training/4_36.jpg 4
2 /home/aistudio/work/food-11/training/6_328.jpg 6
3 /home/aistudio/work/food-11/training/10_707.jpg 10
4 /home/aistudio/work/food-11/training/2_957.jpg 2
... ... ...
16638 /home/aistudio/work/food-11/testing/0542.jpg 0542.jp
16639 /home/aistudio/work/food-11/testing/3091.jpg 3091.jp
16640 /home/aistudio/work/food-11/testing/0722.jpg 0722.jp
16641 /home/aistudio/work/food-11/testing/0805.jpg 0805.jp
16642 /home/aistudio/work/food-11/testing/1566.jpg 1566.jp
[16643 rows x 2 columns]
2021-04-05 16:06:54,469 - INFO - generated new fontManager
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
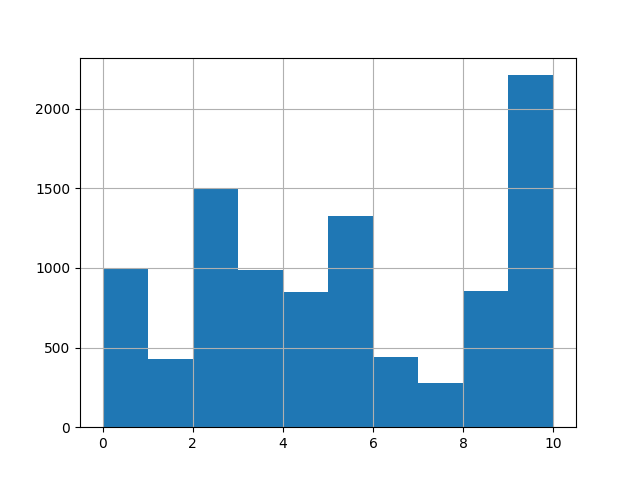
label shuffling
It can be seen from the above figure that there are too many data in category 10, which may lead to over fitting of specific categories in the training process of our deep learning model, resulting in insufficient generalization ability of the model. On this basis, we use the shuffling method
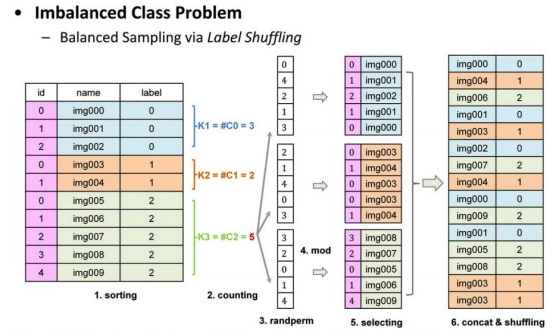
Its principle is as follows
I would like to thank ID: idle people Principle description
Firstly, the original image list is sorted according to the tag order; Then calculate the number of samples in each category and get the number of samples in the category with the most samples. According to the maximum number of samples, a randomly arranged list is generated for each class; Then, the number in the list of each category is used to sum the number of samples of each category to obtain an index value, extract the image from the image of this category, and generate a random list of images of this category; Then connect the random lists of all categories together, make a Random Shuffling, get the final image list, and use this list for training.
#View data format print(df.shape) print(len(df))
#shuffle program
from sklearn.utils import shuffle
def labelShuffling(dataFrame, groupByName='label'):
groupDataFrame = dataFrame.groupby(by=[groupByName])
labels = groupDataFrame.size()
print("length of label is ", len(labels))
maxNum = max(labels)
lst = pd.DataFrame()
for i in range(len(labels)):
print("Processing label :", i)
tmpGroupBy = groupDataFrame.get_group(i)
createdShuffleLabels = np.random.permutation(np.array(range(maxNum))) % labels[i] # Random arrangement and combination
print("Num of the label is : ", labels[i])
lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels], ignore_index=True)
# print("Done")
# lst.to_csv('test1.csv', index=False)
return lst
all_size = len(df)
print("Training set size:", all_size)
# train_image_list = df
df1 = labelShuffling(df)
df1 = shuffle(df1)
print("shuffle Post dataset size:", len(df1))
train_image_path_list = df1['name'].values
label_list = df1['label'].values
label_list = paddle.to_tensor(label_list, dtype='int64')
train_label_list = paddle.nn.functional.one_hot(label_list, num_classes=11)
Training set size: 9866 length of label is 11 Processing label : 0 Num of the label is : 994 Processing label : 1 Num of the label is : 429 Processing label : 2 Num of the label is : 1500 Processing label : 3 Num of the label is : 986 Processing label : 4 Num of the label is : 848 Processing label : 5 Num of the label is : 1325 Processing label : 6 Num of the label is : 440 Processing label : 7 Num of the label is : 280 Processing label : 8 Num of the label is : 855 Processing label : 9 Num of the label is : 1500 Processing label : 10 Num of the label is : 709 shuffle Post dataset size: 16500
#View the data format after shuffling print(df1.shape) print(len(df1)) print(df1)
(16500, 2)
16500
name label
13196 /home/aistudio/work/food-11/training/8_813.jpg 8
3445 /home/aistudio/work/food-11/training/2_783.jpg 2
5117 /home/aistudio/work/food-11/training/3_818.jpg 3
12593 /home/aistudio/work/food-11/training/8_719.jpg 8
15083 /home/aistudio/work/food-11/training/10_655.jpg 10
... ... ...
7211 /home/aistudio/work/food-11/training/4_139.jpg 4
3078 /home/aistudio/work/food-11/training/2_328.jpg 2
9574 /home/aistudio/work/food-11/training/6_199.jpg 6
9338 /home/aistudio/work/food-11/training/6_205.jpg 6
1035 /home/aistudio/work/food-11/training/0_32.jpg 0
[16500 rows x 2 columns]
#Convert the shuffled list into txt and save it
with open('./t1.txt','a') as f:
for i in range(len(df1)):
f.write(str(df1.iloc[i]))
#Processing validation sets
#Read txt text
vsf = pd.read_table('./validation_set.txt',sep='\t',names=['name','label'])
print(vsf)
val_image_list=vsf
val_image_path_list = val_image_list['name'].values
val_label_list = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list, dtype='int64')
val_label_list = paddle.nn.functional.one_hot(val_label_list, num_classes=11)
name label 0 /home/aistudio/work/food-11/validation/3_316.jpg 3 1 /home/aistudio/work/food-11/validation/2_314.jpg 2 2 /home/aistudio/work/food-11/validation/3_167.jpg 3 3 /home/aistudio/work/food-11/validation/8_73.jpg 8 4 /home/aistudio/work/food-11/validation/1_56.jpg 1 ... ... ... 3425 /home/aistudio/work/food-11/validation/3_212.jpg 3 3426 /home/aistudio/work/food-11/validation/6_115.jpg 6 3427 /home/aistudio/work/food-11/validation/4_264.jpg 4 3428 /home/aistudio/work/food-11/validation/5_148.jpg 5 3429 /home/aistudio/work/food-11/validation/2_105.jpg 2 [3430 rows x 2 columns]
#For testing print(train_label_list[1]) print(train_label_list[2]) print(train_label_list[3]) print(train_label_list[4]) print(train_label_list[5]) print(train_label_list[6])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])
Tensor(shape=[11], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.])
Create dataset
# # Define data preprocessing # data_transforms = T.Compose([ # T.RandomResizedCrop(224, scale=(0.8, 1.2), ratio=(3. / 4, 4. / 3), interpolation='bilinear'), # T.RandomHorizontalFlip(), # T.RandomVerticalFlip(), # T.RandomRotation(15), # T.Transpose(), # HWC -> CHW # T.Normalize( # mean=[127.5, 127.5, 127.5], # normalization # std=[127.5, 127.5, 127.5], # to_rgb=True) # ])
# Build Dataset
class MyDataset(paddle.io.Dataset):
"""
Step 1: inherit paddle.io.Dataset class
"""
def __init__(self, train_img_list, val_img_list, train_label_list, val_label_list, mode='train'):
"""
Step 2: implement the constructor, define the data reading method, and divide the training and test data sets
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
# Reading csv library with pandas
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
if mode == 'train':
# Read train_images data
for img,la in zip(self.train_images, self.train_label):
self.img.append(img)
self.label.append(la)
else:
# Read test_images data
for img,la in zip(self.test_images, self.test_label):
self.img.append(img)
self.label.append(la)
def load_img(self, image_path):
# In actual use, you can use the pilot related library to read pictures. Here, let's simulate the data first
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
Step 3: Implement__getitem__Method, defining and specifying index How to obtain the corresponding data of the training tag and return it
"""
image = self.load_img(self.img[index])
label = self.label[index]
## label = paddle.to_tensor(label)
img=image.resize((100, 100), Image.ANTIALIAS) # Image size style normalization
img = np.array(img).astype('float32') # Convert to array type floating-point 32-bit
img = img.transpose((2, 0, 1)) #The image read out is rgb,rgb,rbg, Transpose to RRR, ggg..., bbb...
img = img/255.0 # The data is scaled to the range of 0-1
label=np.argmax(label)#Switch back label from ONE HOT
return img, label
#return data_transforms(image), paddle.nn.functional.label_smooth(label)
def __len__(self):
"""
Step 4: Implement__len__Method to return the total number of data sets
"""
return len(self.img)
BATCH_SIZE = 128
PLACE = paddle.CUDAPlace(0)
# train_loader
train_dataset = MyDataset(
train_img_list=train_image_path_list,
val_img_list=val_image_path_list,
train_label_list=train_label_list,
val_label_list=val_label_list,
mode='train')
train_loader = paddle.io.DataLoader(
train_dataset,
places=PLACE,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0)
# val_loader
val_dataset = MyDataset(
train_img_list=train_image_path_list,
val_img_list=val_image_path_list,
train_label_list=train_label_list,
val_label_list=val_label_list,
mode='test')
val_loader = paddle.io.DataLoader(
val_dataset,
places=PLACE,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=0)
print('train size:', train_dataset.__len__())
print('val size:', val_dataset.__len__())
# View picture data, size and label
for data, label in train_dataset:
print(data)
print(np.array(data).shape)
print(label)
break
train Size: 16500 val Size: 3430 (3, 100, 100) 5
Build network
The network refers to the ID: three-year-old Public project , I would like to express my thanks
class MyCNN(paddle.nn.Layer):
def __init__(self):
super(MyCNN,self).__init__()
self.conv0 = paddle.nn.Conv2D(in_channels=3, out_channels=20, kernel_size=5, padding=0) # Two dimensional convolution
self.pool0 = paddle.nn.MaxPool2D(kernel_size =2, stride =2) # Maximum pool layer
self._batch_norm_0 = paddle.nn.BatchNorm2D(num_features = 20) # Return to one level
self.conv1 = paddle.nn.Conv2D(in_channels=20, out_channels=50, kernel_size=5, padding=0)
self.pool1 = paddle.nn.MaxPool2D(kernel_size =2, stride =2)
self._batch_norm_1 = paddle.nn.BatchNorm2D(num_features = 50)
self.conv2 = paddle.nn.Conv2D(in_channels=50, out_channels=50, kernel_size=5, padding=0)
self.pool2 = paddle.nn.MaxPool2D(kernel_size =2, stride =2)
self.fc1 = paddle.nn.Linear(in_features=4050, out_features=218) # Linear layer
self.fc2 = paddle.nn.Linear(in_features=218, out_features=100)
self.fc3 = paddle.nn.Linear(in_features=100, out_features=11)
def forward(self,input):
input = paddle.reshape(input,shape=[-1,3,100,100]) # Conversion dimension reading
# print(input.shape)
x = self.conv0(input) #Data input convolution
x = F.relu(x) # Active layer
x = self.pool0(x) # Pool layer
x = self._batch_norm_0(x) # Return to one level
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self._batch_norm_1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = paddle.reshape(x, [x.shape[0], -1])
# print(x.shape)
x = self.fc1(x) # Linear layer
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
y = F.softmax(x) # classifier
return y
network = MyCNN() # Model instantiation paddle.summary(network, (1,3,100,100)) # Model structure view
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 100, 100]] [1, 20, 96, 96] 1,520
MaxPool2D-1 [[1, 20, 96, 96]] [1, 20, 48, 48] 0
BatchNorm2D-1 [[1, 20, 48, 48]] [1, 20, 48, 48] 80
Conv2D-2 [[1, 20, 48, 48]] [1, 50, 44, 44] 25,050
MaxPool2D-2 [[1, 50, 44, 44]] [1, 50, 22, 22] 0
BatchNorm2D-2 [[1, 50, 22, 22]] [1, 50, 22, 22] 200
Conv2D-3 [[1, 50, 22, 22]] [1, 50, 18, 18] 62,550
MaxPool2D-3 [[1, 50, 18, 18]] [1, 50, 9, 9] 0
Linear-1 [[1, 4050]] [1, 218] 883,118
Linear-2 [[1, 218]] [1, 100] 21,900
Linear-3 [[1, 100]] [1, 11] 1,111
===========================================================================
Total params: 995,529
Trainable params: 995,249
Non-trainable params: 280
---------------------------------------------------------------------------
Input size (MB): 0.11
Forward/backward pass size (MB): 3.37
Params size (MB): 3.80
Estimated Total Size (MB): 7.29
---------------------------------------------------------------------------
{'total_params': 995529, 'trainable_params': 995249}
train
Because the training set adopts shuffle, the training set is too large, which can improve batch_size
model = paddle.Model(network) # Model encapsulation
# Configure optimizer, loss function and evaluation index
model.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# Start the whole process training of the model
model.fit(train_dataset, # Training data set
val_dataset, # Evaluation data set
epochs=5, # Total rounds of training
batch_size=64, # Batch size for training
verbose=1 # Log display form
)
The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/5 /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.") step 258/258 [==============================] - loss: 2.1116 - acc: 0.2521 - 3s/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 54/54 [==============================] - loss: 2.4477 - acc: 0.0469 - 775ms/step Eval samples: 3430 Epoch 2/5 step 258/258 [==============================] - loss: 2.1425 - acc: 0.3990 - 3s/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 54/54 [==============================] - loss: 2.5067 - acc: 0.0207 - 825ms/step Eval samples: 3430 Epoch 3/5 step 258/258 [==============================] - loss: 2.0256 - acc: 0.4742 - 3s/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 54/54 [==============================] - loss: 2.4263 - acc: 0.0825 - 776ms/step Eval samples: 3430 Epoch 4/5 step 258/258 [==============================] - loss: 1.9744 - acc: 0.5348 - 3s/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 54/54 [==============================] - loss: 2.4410 - acc: 0.0985 - 809ms/step Eval samples: 3430 Epoch 5/5 step 258/258 [==============================] - loss: 1.8584 - acc: 0.5815 - 3s/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 54/54 [==============================] - loss: 2.3978 - acc: 0.1087 - 792ms/step Eval samples: 3430
model.save('finetuning/mnist') # Save model
def openimg(): # Read picture function
with open(f'test_set.txt') as f: #Read folder
test_img = []
txt = []
for line in f.readlines(): # Cycle through each line
img = Image.open(line[:-1]) # Open picture
img = img.resize((100, 100), Image.ANTIALIAS) # Size normalization
img = np.array(img).astype('float32') # Convert to array
img = img.transpose((2, 0, 1)) #The image read out is rgb,rgb,rbg, Transpose to RRR, ggg..., bbb...
img = img/255.0 # zoom
txt.append(line[:-1]) # Generate list
test_img.append(img)
return txt,test_img
img_path, img = openimg() # Read list
forecast
Establish a query list and finally display it with Chinese tags
from PIL import Image
labal_name=['bread','dairy','Dessert','egg','fried food','meat','noodle/pasta','rice','seafood','soup','Vegetables/Fruits']
site = 255 # Read picture location
model_state_dict = paddle.load('finetuning/mnist.pdparams') # Read model
model = MyCNN() # Instantiation model
model.set_state_dict(model_state_dict)
model.eval()
ceshi = model(paddle.to_tensor(img[site])) # test
print('label:',np.argmax(ceshi.numpy()))
print('The predicted result is:', labal_name[np.argmax(ceshi.numpy())]) # Get value
t.pdparams') # Read model
model = MyCNN() # Instantiation model
model.set_state_dict(model_state_dict)
model.eval()
ceshi = model(paddle.to_tensor(img[site])) # test
print('label:',np.argmax(ceshi.numpy()))
print('The predicted result is:', labal_name[np.argmax(ceshi.numpy())]) # Get value
Image.open(img_path[site]) # display picture
label: 10 The predicted result is: Vegetables/Fruits

[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-Nd8C6HZE-1618979172332)(output_30_1.png)]