2021SC@SDUSC
catalogue
1.1} PP-OCR character recognition strategy
1.2. This paper introduces the strategy
2, PP-OCR identification process
Define label input and super parameters
Instantiate the model and configure the optimization strategy
2.5 preparation before forecast
Define the prediction Reader as you define the training Reader
1, Previous review
1.1} PP-OCR character recognition strategy
The selection of strategy is mainly used to enhance the model capability and reduce the model size. Here are nine strategies adopted by PP-OCR character recognizer:
- Light backbone, mobilenetv3 large x0 5 to weigh accuracy and efficiency;
- Data enhancement, BDA (Base Dataaugmented) and TIA (Luo et al. 2020);
- The cosine learning rate is attenuated to effectively improve the text recognition ability of the model;
- Feature map discrimination, adapt to multi language recognition, and modify the stride of down sampling feature map;
- Regularization parameters, weight attenuation to avoid over fitting;
- Preheating of learning rate is also effective;
- The full connection layer is used to encode the sequence features into prediction characters to reduce the size of the model;
- The pre training model is trained on a large data set such as ImageNet, which can achieve faster convergence and better accuracy;
- PACT quantization, skipping the LSTM layer;
1.2. This paper introduces the strategy
Previously, we introduced the CRNN-CTC model of pad OCR character recognizer again according to the model implementation process.
Based on the previous specific introduction to the overall model selection and the code implementation of various strategies and algorithms, this article will make an overall understanding of the process of pad OCR character recognition in combination with the actual character recognition scene, and analyze the key codes used in the process.
2, PP-OCR identification process
2.1 data set collection
Combined with in ppocr__ init__ And__ getitem__ Method to read a custom dataset.
Code location

Detailed code implementation and analysis:
import os
import PIL.Image as Image
import numpy as np
from paddle.io import Dataset
# Picture information configuration - number of channels, height and width
IMAGE_SHAPE_C = 3
IMAGE_SHAPE_H = 30
IMAGE_SHAPE_W = 70
# Set the maximum label length in the dataset picture - since the pictures are all 4 characters, fill in 4 here
LABEL_MAX_LEN = 4
class Reader(Dataset):
def __init__(self, data_path: str, is_val: bool = False):
"""
data fetch Reader
:param data_path: Dataset route
:param is_val: Is it a validation set
"""
super().__init__()
self.data_path = data_path
# Read Label dictionary
with open(os.path.join(self.data_path, "label_dict.txt"), "r", encoding="utf-8") as f:
self.info = eval(f.read())
# Get a list of file names
self.img_paths = [img_name for img_name in self.info]
# Set the last 1024 pictures in the data set as the verification set when is_ IMG when Val is true_ The path is switched to the last 1024
self.img_paths = self.img_paths[-1024:] if is_val else self.img_paths[:-1024]
def __getitem__(self, index):
# Get the file name and path of the index file
file_name = self.img_paths[index]
file_path = os.path.join(self.data_path, file_name)
# Catch exception - terminate training when an exception occurs
try:
# Use pilot to read image data
img = Image.open(file_path)
# Convert to Numpy array format and divide the whole by 255 for normalization
img = np.array(img, dtype="float32").reshape((IMAGE_SHAPE_C, IMAGE_SHAPE_H, IMAGE_SHAPE_W)) / 255
except Exception as e:
raise Exception(file_name + "\t Failed to open the file. Please check whether the path is accurate and the integrity of the image file. The error information is as follows:\n" + str(e))
# Read the Label string corresponding to the image file and process it
label = self.info[file_name]
label = list(label)
# Convert label to Numpy array format
label = np.array(label, dtype="int32")
return img, label
def __len__(self):
# Returns the number of pictures in each Epoch
return len(self.img_paths)
Data read by instance

2.2 model configuration
The model uses the simple method introduced in our last article CRNN-CTC structure.
The input image with the shape of CHW outputs the character probability corresponding to each position in the image after CNN - > flat - > linear - > RNN - > linear. Considering that the CTC decoder cannot align correctly when facing the different number of elements in the image and the repetition of adjacent elements, an additional category representing "separator" is added to improve.
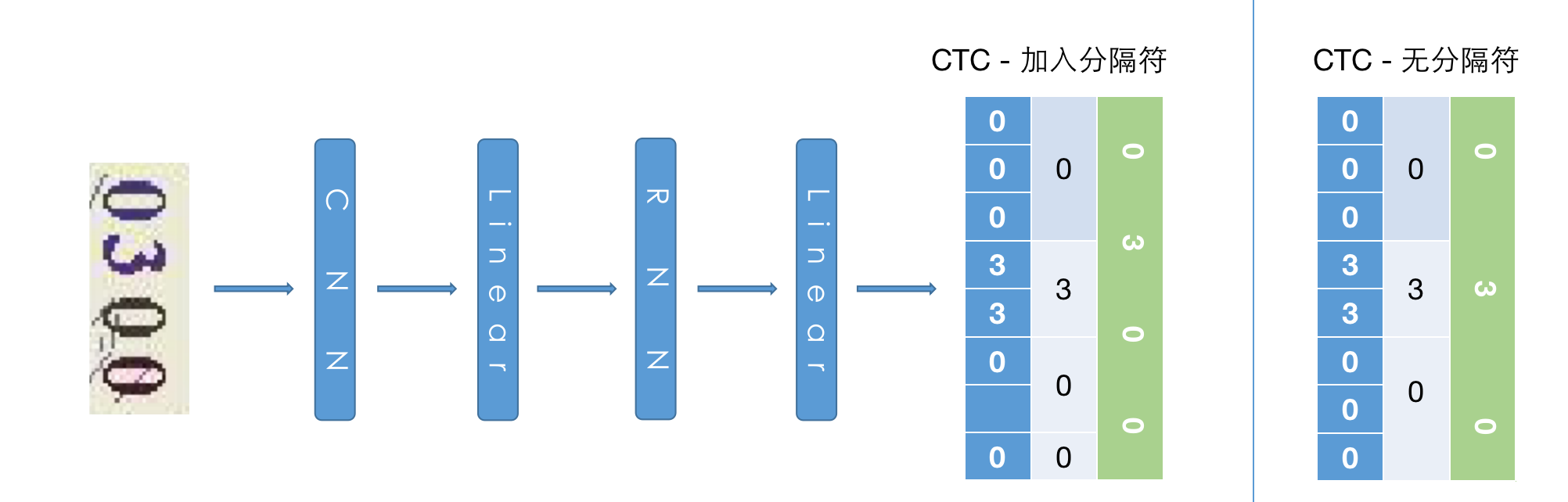
Code location:

Specific code implementation and analysis:
import paddle
# Classification quantity setting - because the dataset contains 10 numbers + separators from 0 to 9, it is an 11 classification task
CLASSIFY_NUM = 11
# Define the input layer. If - 1 is used in the 0th dimension of the shape, the batch size can be adjusted freely during prediction
input_define = paddle.static.InputSpec(shape=[-1, IMAGE_SHAPE_C, IMAGE_SHAPE_H, IMAGE_SHAPE_W],
dtype="float32",
name="img")
# Define network structure
class Net(paddle.nn.Layer):
def __init__(self, is_infer: bool = False):
super().__init__()
self.is_infer = is_infer
# Define a layer of 3x3 convolution + BatchNorm
self.conv1 = paddle.nn.Conv2D(in_channels=IMAGE_SHAPE_C,
out_channels=32,
kernel_size=3)
self.bn1 = paddle.nn.BatchNorm2D(32)
# Define a layer of 3x3 convolution with step size of 2 for down sampling + BatchNorm
self.conv2 = paddle.nn.Conv2D(in_channels=32,
out_channels=64,
kernel_size=3,
stride=2)
self.bn2 = paddle.nn.BatchNorm2D(64)
# Define the number of 1x1 convolution compression channels in one layer, and set the number of output channels to be higher than label_ MAX_ A slightly larger fixed value of len can obtain better results. Of course, it can also be set to LABEL_MAX_LEN
self.conv3 = paddle.nn.Conv2D(in_channels=64,
out_channels=LABEL_MAX_LEN + 4,
kernel_size=1)
# Define fully connected layers, compress and extract features (optional)
self.linear = paddle.nn.Linear(in_features=429,
out_features=128)
# Define RNN layer to better extract sequence features. Here, bidirectional LSTM output is 2 x hidden_size, try to replace it with RNN structures such as GRU
self.lstm = paddle.nn.LSTM(input_size=128,
hidden_size=64,
direction="bidirectional")
# Define the output layer, and the output size is the number of categories
self.linear2 = paddle.nn.Linear(in_features=64 * 2,
out_features=CLASSIFY_NUM)
def forward(self, ipt):
# Convolution + ReLU + BN
x = self.conv1(ipt)
x = paddle.nn.functional.relu(x)
x = self.bn1(x)
# Convolution + ReLU + BN
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.bn2(x)
# Convolution + ReLU
x = self.conv3(x)
x = paddle.nn.functional.relu(x)
# Convert 3D features to 2D features - you can use reshape instead
x = paddle.tensor.flatten(x, 2)
# Full connection + ReLU
x = self.linear(x)
x = paddle.nn.functional.relu(x)
# Two way LSTM - [0] represents two-way result, [1] [0] represents forward result, [1] [1] represents backward result. For details, you can search 'LSTM' in the official document
x = self.lstm(x)[0]
# Output layer - shape = (batch size, Max label, len, signal)
x = self.linear2(x)
# When calculating the loss, CTC loss will automatically perform softmax, so in the prediction mode, softmax needs to be added to obtain the tag probability
if self.is_infer:
# Output layer - shape = (batch size, Max label, len, prob)
x = paddle.nn.functional.softmax(x)
# Convert to label
x = paddle.argmax(x, axis=-1)
return x
2.3 training preparation
Define label input and super parameters
Code location:

Code and analysis during use:
# Dataset path settings
DATA_PATH = "./data/OCR_Dataset"
# Number of training rounds
EPOCH = 10
# Data size per batch
BATCH_SIZE = 16
label_define = paddle.static.InputSpec(shape=[-1, LABEL_MAX_LEN],
dtype="int32",
name="label")
Define CTC Loss
We have introduced the loss function in detail in the previous article.
Code location:

Code implementation and analysis:
class CTCLoss(paddle.nn.Layer):
def __init__(self):
"""
definition CTCLoss
"""
super().__init__()
def forward(self, ipt, label):
input_lengths = paddle.full(shape=[BATCH_SIZE],fill_value=LABEL_MAX_LEN + 4,dtype= "int64")
label_lengths = paddle.full(shape=[BATCH_SIZE],fill_value=LABEL_MAX_LEN,dtype= "int64")
# Convert dim order according to document requirements
ipt = paddle.tensor.transpose(ipt, [1, 0, 2])
# Calculate loss
loss = paddle.nn.functional.ctc_loss(ipt, label, input_lengths, label_lengths, blank=10)
return loss
Instantiate the model and configure the optimization strategy
We have also introduced the optimizer of PP-OCR character recognizer one by one before.
Code location:

Code implementation and analysis:
# Define optimizer
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
# Configure the running environment for the model and set the optimization policy
model.prepare(optimizer=optimizer,
loss=CTCLoss())
2.4 training
Specific code of training part:
# Executive Training
model.fit(train_data=Reader(DATA_PATH),
eval_data=Reader(DATA_PATH, is_val=True),
batch_size=BATCH_SIZE,
epochs=EPOCH,
save_dir="output/",
save_freq=1,
verbose=1,
drop_last=True)
2.5 preparation before forecast
Define the prediction Reader as you define the training Reader
# Similar to training, but excluding Label
class InferReader(Dataset):
def __init__(self, dir_path=None, img_path=None):
"""
data fetch Reader(forecast)
:param dir_path: Forecast corresponding folder (one out of two)
:param img_path: Forecast single picture (one out of two)
"""
super().__init__()
if dir_path:
# Get the path of all pictures in the folder
self.img_names = [i for i in os.listdir(dir_path) if os.path.splitext(i)[1] == ".jpg"]
self.img_paths = [os.path.join(dir_path, i) for i in self.img_names]
elif img_path:
self.img_names = [os.path.split(img_path)[1]]
self.img_paths = [img_path]
else:
raise Exception("Please specify the folder or corresponding picture path to be predicted")
def get_names(self):
"""
Get prediction file name order
"""
return self.img_names
def __getitem__(self, index):
# Get image path
file_path = self.img_paths[index]
# Use pilot to read image data and convert it to Numpy format
img = Image.open(file_path)
img = np.array(img, dtype="float32").reshape((IMAGE_SHAPE_C, IMAGE_SHAPE_H, IMAGE_SHAPE_W)) / 255
return img
def __len__(self):
return len(self.img_paths)
Forecast data

2.6 forecast
Forecast usage code
# Write simple version decoder
def ctc_decode(text, blank=10):
"""
simple and easy CTC decoder
:param text: Data to be decoded
:param blank: Separator index value
:return: Decoded data
"""
result = []
cache_idx = -1
for char in text:
if char != blank and char != cache_idx:
result.append(char)
cache_idx = char
return result
# Instantiation reasoning model
model = paddle.Model(Net(is_infer=True), inputs=input_define)
# Load the trained parameter model
model.load(CHECKPOINT_PATH)
# Set up the running environment
model.prepare()
# Load forecast Reader
infer_reader = InferReader(INFER_DATA_PATH)
img_names = infer_reader.get_names()
results = model.predict(infer_reader, batch_size=BATCH_SIZE)
index = 0
for text_batch in results[0]:
for prob in text_batch:
out = ctc_decode(prob, blank=10)
print(f"File name:{img_names[index]},The reasoning result is:{out}")
index += 1
result
Consistent with the data to be measured.

summary
Combined with the actual character recognition scene, this paper makes an overall understanding of the character recognition process of pad OCR, and analyzes the key codes used in the process.